文件属性系统¶
定位
本文是实验4:语义文件系统的 Part2 阅读材料,内容包括语义文件系统的背景、作用、其在本实验中的简单实现以及实验任务。由于本实验针对基础的 FAT16 文件系统做了相应改动,请同学们在实现 Part2 之前先阅读本实验关于文件属性系统的设计,另外对于要选做 Bonus 的同学请仔细阅读本文档关于 B+ 树的介绍。
1. 语义文件系统¶
在实验2 中,同学们已经初步了解让操作系统管理一个大语言模型服务的流程(下文称 AI Service),用户可以在进程中向后台请求大模型服务,这其实已经是 AIOS 的雏形;在实验3 中,同学们又亲身实现了 Lazy Allocation 与 Copy on Write 这两项传统的内存管理技术,并了解其在大模型推理语境下的新作用。前面的工作都已十分扎实,实验2 已经提供了一个大模型服务作为系统调用的框架,但在实验过程中我们并没有看到大模型服务具象的用途。如何真正让大模型运用起操作系统呢?又如何让大模型效率更高地服务呢?
让我们先看下图:
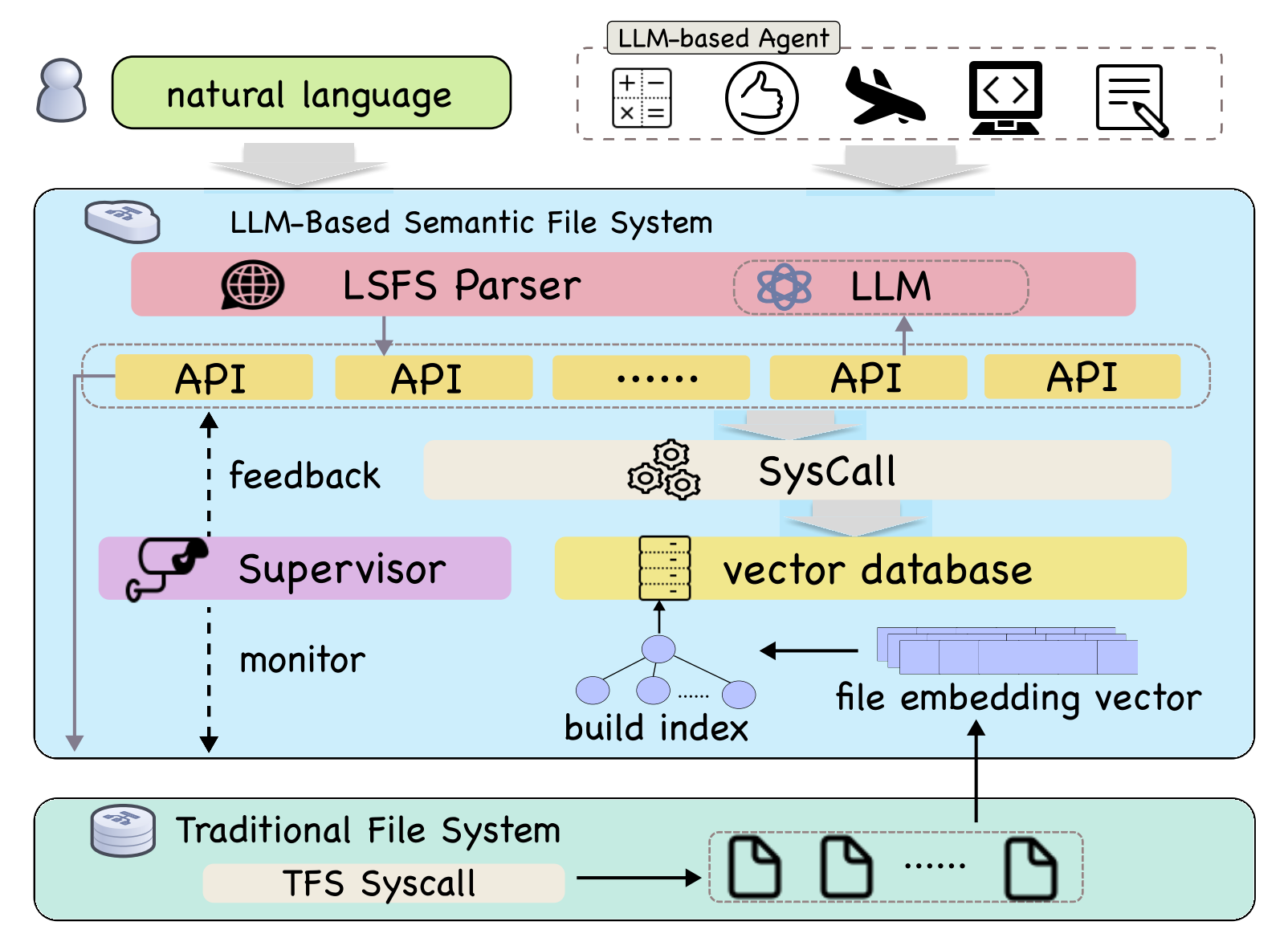
最上层的用户输入自然语言,然后大模型对其进行处理,输出特定信号调用语义文件系统提供的 API,这可能是创建、修改、删除文件等等。最理想的情况下,我们希望实验4 能挂载一个真正的 AIOS,但在虚拟机资源极致受限的情况下难以实现,加之复杂度和难度本身极高,因此,实验4 从结合传统的文件系统设计一个对 AI Service “友好”的工具切入,帮助大家继续深入。
同学们可能已经接触过 AI Agent 工具了,它能够在项目下根据你的指令完成相关的文档阅读、实验测试等任务。我们知道大模型能够输出文本,但是大模型要如何能帮助用户实现执行命令行命令、阅读文档乃至修改文件呢?大模型本身不直接具备这些功能,但是大模型可以通过输出特定的信号告知调度器调用既有的工具来实现大模型要做的工作。比如说,用户 A 是一名计算机专业的学生,A 向大模型输入:阅读并总结路径为 ./papers/Speculative_Decoding.pdf 的论文。大模型则可以直接生成能够实现如下命令的信息:
这种情况自然是最省事的,大模型不用推断应该打开哪个文件。而如果用户 B 觉得输入路径太麻烦,他也可以输入:阅读并总结项目下端侧 Speculative Decoding 相关的论文,那么大模型就会生成如下的调用链(示例,实际上比下面的调用复杂):
这种情况也并不麻烦,只需要找到名字与用户输入匹配的文件就行。但是实际运行中,还有第三种情况,即文件的名字不能很好展示文件的语义信息,比如说用户给上述论文起了个名字叫 paper1.pdf,再如 AI Service 本身运行时产生了一些没有良好命名的持久化信息,见以下目录树:
AI_Service_Data/
├── memory/
│ ├── mem_202605_123456.bin
│ └── social_13f9.dat
├── cache/
│ └── 9f3ab2.tmp
└── logs/
└── a94f2c1.log
如果不去读它们的内容,没有人/大模型能够知道里面到底保存了什么,因此此时 AI Service 的调用链(仍然以读论文为例)是:
ls ./papers
read("./papers/paper1.pdf", O_RDONLY)
read("./papers/paper2.pdf", O_RDONLY)
read("./papers/paper3.pdf", O_RDONLY)
...
open("./papers/paper1.pdf", O_RDONLY)
阅读大量、冗长的文档十分让人类头疼,同样地,大模型阅读文档也绝非易事,token 便是一大开销。另外从上述调用链的对比可以看出,第三种情况比第一、二种情况多了许多从磁盘加载数据、大模型本身阅读文件的时间,造成一定的时延。如何解决此问题呢,一个直接的想法就是将文件的语义信息存储起来,然后提供一个工具给大模型,使得大模型无需阅读文件内容就能得知文件语义,这个系统就是本文所说的语义文件系统。
语义的内涵是十分丰富的,它可以是一组向量,也可以是 (key, value) 对,出于简化实验的目的,本实验采用的语义实际上是文件的关键词。假设某文件已经有关键词 Speculative_Decoding,那么系统提供的工具就应该支持大模型如下调用:
本文的语义文件系统受到 ICLR'25 的一篇文章 From Commands to Prompts: LLM-based Semantic File System for AIOS 启发而设计,感兴趣的同学可以去阅读此论文。当然,不读也没关系,实验4 关于语义文件系统的设计并不像论文中描述的完善,结构十分简单,功能也较为有限,通过阅读本文档同学们就能完成实验4 的语义文件系统了。
2. 文件属性系统与 B+ 树¶
上一节提到,本实验中的语义信息被简化为关键词。也就是说,一个文件除了文件名、文件大小、文件内容之外,还可以额外携带一段关键词字符串。用户可以通过设置关键词把文件与语义信息关联起来,也可以通过查询关键词快速找到相关文件。我们只需要在 FAT16 文件系统之上提供一个较小的属性系统,使得下面这类使用方式能够成立:
此时,query 应该能够返回带有 Speculative_Decoding 关键词的文件路径。
2.1 文件属性与普通文件内容的关系¶
关键词是文件的属性,不会放到文件内容中。
例如,paper1.pdf 的文件内容是完整论文,而它的关键词可能只有:
读取文件内容时,用户得到的仍然是 paper1.pdf 原本的数据;查询关键词时,文件系统只根据关键词属性判断这个文件是否匹配。二者的逻辑关系如下:
这样的设计可以避免为了语义查询反复读取大文件。尤其是当文件内容很大、文件名又不能反映真实语义时,关键词属性可以作为更轻量的检索入口。
2.2 关键词在目录中的组织方式¶
FAT16 的标准目录项大小固定为 32 字节,普通文件和目录都通过目录项记录自己的名字、属性、首簇号和文件大小等信息。本实验不能破坏 FAT16 标准目录项的基本格式,因此关键词不会直接塞进普通文件的标准目录项中。
本实验采用的思路是:把关键词保存为文件目录项附近的特殊属性记录,并让这些属性记录紧挨着目标文件的标准目录项。如下图所示:
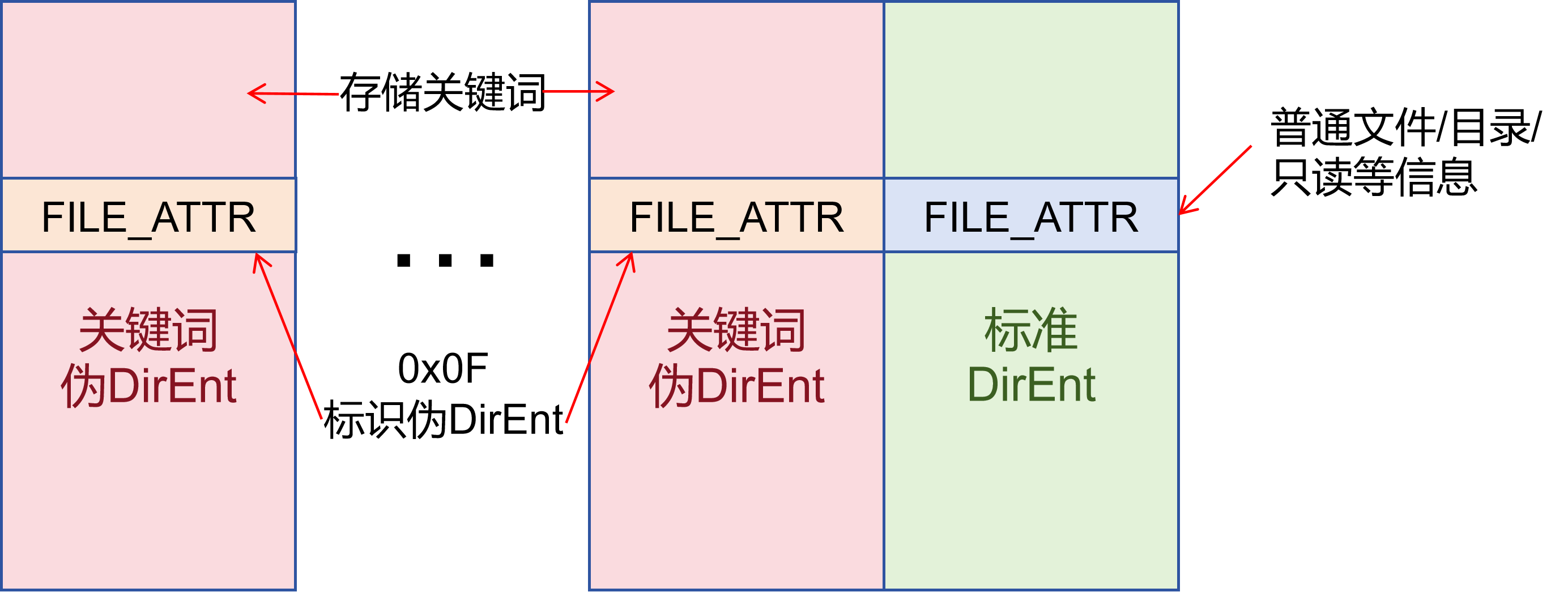
对于每个关键词伪目录项,除了 0x00 与 0x0B 两处偏移保留外,其余全部字节保存关键词字符串,以空格为分隔,以 '\0' 为结尾。
关键词伪目录项的结构
0x00 对应的值固定为 byte[7 : 4] = 0x9 及 byte[3 : 0] = kw_index,前者是关键词伪目录项的标识符,与 0x0B 的值 0x0F 共同判断一个目录项是不是关键词伪目录项;后者标识这个目录项是对应文件的第几个关键词伪目录项。
由于将这些目录项的 attr 字段定义成了 0x0F(按照 FAT16 目录项语义,这代表着一个文件只读、隐藏、属于系统核心文件、是卷标,这显然是不可能的,所以文件系统不会将其视为一个正常的可见的文件),对于上层用户来说,这些属性记录不是普通文件,也不会作为普通目录内容展示。
可以把一个目录中的物理组织理解成下面这样:
[Dirent A][KW 0][KW 1]...[KW N-1][Dirent B][Dirent C]
上层的调用只会看到 A、B、C 三个文件,不会看到中间的伪目录项。
这种设计有两个好处:
- 不需要修改普通文件的数据区,设置关键词不会改动文件内容;
- 不需要重新设计一个复杂的元数据区域,关键词可以跟随目录项一起保存。
同时,它也带来了一个需要同学们在实验中处理的问题:当关键词变长或变短时,文件目录项前面需要的属性记录数量可能发生变化。如果原来的位置放不下新的关键词,就需要为属性记录和标准文件目录项重新寻找一段连续空间。
设计来源
本设计借鉴了 FAT16 系统支持的 LFN 技术,这是将文件名扩展到可支持 255 个字符的技术。同学们可能会问:那所谓的为 AI Service 查询优化就相当于把文件名字改的更有语义?从结果上来看确实如此,但这是本实验为简化设计所做出的妥协,同学们可以回忆上文及语义文件系统架构图,我们还可以通过修改设计存储其他数据,包括更精确的 (key, value) 键值对,也可以存储大模型更能“看懂”的向量,这些所带来的语义信息远大于修改文件名字。
{kind=link}
2.3 全盘扫描查询¶
本实验必做部分中的查询采用全盘扫描方式。它的基本过程是:
- 从根目录开始遍历可见文件;
- 对每个普通文件读取它的关键词属性;
- 判断该文件是否包含查询请求中的所有关键词;
- 如果匹配,就把文件路径加入查询结果。
全盘扫描的优点是实现比较直接,不需要额外维护索引结构。只要关键词属性能够正确保存和读取,查询功能就可以工作。
它的缺点也很明显:每次查询都需要遍历目录树。文件数量较少时问题不大,文件数量很多时,查询开销会随文件数量增长。
本实验中,多个查询关键词表示同时匹配。例如:
表示查询同时带有 os 和 fs 这两个关键词的文件。top_k 参数用于限制最多返回多少条结果。
2.4 B+ 树索引¶
本实验包含了 B+ 树的实现,助教提供了一个 B+ 树操作演示的网页,同学们可以使用 B+ 树演示 来了解本实验采用的 B+ 树操作流程。下面对 B+ 树做简要介绍,本实验只用到 B+ 树的插入和查询操作,因此不赘述删除操作,感兴趣的同学可以自行探索。
阅读提醒
下面所述的 B+ 树是简化版本,只大致描述 B+ 树的特点,实验实现的 B+ 树结构不完全等同于下述结构,请同学们在做 Bonus 时仔细阅读 kernel/fs/bptree.c 及 kernel/include/bptree.h 文件。
2.4.1 B+ 树整体结构¶
为避免歧义,下文称 (key, value) 对中 key 的数值为索引键,value 的数值为值。
B+ 树的结点主要包括两部分:
- 叶子结点:用于存放
(key, value)对,注意这里的值并不一定直接存储数据,可能是指向数据的结构; - 内部结点:仅存放索引键和子结点,不存储数据,一个典型的内部结点结构如
[P1, K1, P2, K2, ..., Pn-1, Kn-1, Pn],其中Pi是指向子结点的指针,而Ki是索引键。其中Pi指向的索引键都小于Ki,Pi+1指向的索引键都大于或者等于Ki,基于这个结构,如果要查询一个键的值,那么只需要根据这个键的大小就可以形成一条直下的查询路径。
2.4.2 B+ 树的性质(定义)¶
对于一颗 m 阶 B+ 树,它满足:
-
子结点数量
- 每个结点最多有
m个子结点(代码中允许临时溢出 1 个,但之后随即进行分裂); - 除根节点外,每个结点最少有
round_up(m / 2)个子结点; - 根结点如果不是叶子,则至少有 2 个子结点。
- 每个结点最多有
-
键的数量
- 内部结点如果有
n个子结点,就有n - 1个键; - 叶子结点最多有
m - 1个键值对,至少round_up(m / 2) - 1个。
- 内部结点如果有
-
其他性质
- 只有叶子结点存储值;
- 所有的叶子结点在一条链表上;
- 所有叶子结点到根的距离相同。
2.4.3 B+ 树的操作¶
对于查询键 key:
1. 如果当前结点不是叶子,找到第一个大于 key 的键 Ki,向下探到 Pi(Pi 保存的键都严格小于 Ki),直到达到叶子结点;
2. 从该叶子结点的起点查询链表找到 key 对应的 value 并返回。
对于插入键值对 (key, value):
1. 找到键应插入的叶子结点 L;
2. 若 L 未满,直接插入并保持链表有序;
3. 若 L 已满,分裂当前叶子结点为两个叶子结点,前者保留前 round_up(m / 2) 个键值对,后者保存剩下的键值对;
4. 将后者的指针及最小的键添加到父节点中;
5. 若父节点也满,也将父节点分为两部分,但是,将中间键提升至祖父结点,父结点这一层不再保有此键作为索引;
6. 循环 5 直至根节点分裂则新建根结点。
思考题
内部结点和叶子结点的分裂有何不同,为什么?
2.4.4 语义文件系统中的 B+ 树¶
为了避免每次查询都全盘扫描,可以建立一个从关键词到文件集合的索引。对应上本节上文提到的 B+ 树索引,语义文件系统将 (key, value) 对中的 key 设置为文件的属性(本实验简化为关键词),而 value 代表的就是具有这个关键词的文件链表(具体 value 是如何映射到文件的,请详见 kernel/fs/fat16fs.c)。例如:
keywords -> files linked list
os -> /doc/a.txt, /doc/c.txt
fs -> /doc/a.txt, /doc/b.txt
tree -> /doc/b.txt
这样,当用户查询 fs 时,文件系统不需要遍历所有文件的目录项,只需要在索引中找到 fs 对应的文件列表即可。
为简化实验,本实验实现的 B+ 树索引是每次打开 NexOS 后文件系统初始化时构建在内存中的,并未将其持久化到磁盘中。
3. Part2 必做实验任务¶
本节说明本次实验 Part2 需要补全的函数。同学们可以参考以下顺序完成实验4 Part2。如果对某个辅助函数的参数含义不清楚,可以参考 实验4补充材料:辅助函数与宏定义速查。
Part 2 的目标是让文件能够保存关键词,并支持根据关键词查询文件。完成这一部分后,setkeywords()、query_file() 等接口应当可以正常工作。
实现注意
注意:待实现函数中存在为通过编译器检查的 return -1 和 return 0 等命令以及提示未实现的 panic 命令,请同学们在实现后记得注释掉这些代码,以免测试失败。
3.1.1 读取文件关键词¶
static int fat16_keyword_count_before(struct inode *dp, uint std_index);
static int fat16_read_keywords_before(struct inode *dp, uint std_index,
char *buf, int max);
实现流程如下:
-
在
fat16_keyword_count_before()中,从std_index - 1开始,反复调用fat16_slot_by_index()读取前一个目录项,再用fat16_dirent_is_keyword()判断它是否是关键词属性记录。 -
如果遇到非关键词属性记录,或者达到关键词属性记录数量上限,就停止扫描并返回数量。
-
在
fat16_read_keywords_before()中,先调用fat16_keyword_count_before()得到关键词属性记录数量。如果数量为 0,说明该文件没有关键词,直接返回 0。 -
如果存在关键词属性记录,就从最前面的关键词属性记录开始,依次调用
fat16_slot_by_index()读取目录项,并用fat16_kw_get_data_byte()取出其中保存的关键词字节。 -
读到字符串结尾后,把结果写入
buf并返回实际读取的长度,buf的有效字符串之后一位填\0。写入buf时必须检查max,不能越界。
3.1.2 寻找连续空槽¶
static int fat16_find_free_run(struct inode *dp, uint need,
uint old_start, uint old_count,
struct fat16_slot *first_slot,
uint *first_index);
设置关键词时,一个文件可能需要连续的多个目录槽:前面若干个槽保存关键词属性记录,最后一个槽保存标准文件目录项。这个函数的任务就是在目录中寻找一段长度为 need 的连续可用槽。
实现流程如下:
-
先用
fat16_dir_slot_count()得到当前目录可以容纳的目录项数量,然后在当前目录存放目录项的数据区从 0 号槽位开始向后扫描。 -
扫描每个位置时,用
fat16_slot_available_for_run()判断该位置是否可以作为新连续区域的一部分,注意:旧范围内的槽位认为是可以复用的。 -
连续可用槽达到
need后,用fat16_slot_by_index()读出并写入first_slot,同时写入first_index。 -
如果当前目录没有足够长的连续空槽,普通子目录可以调用
fat16_grow_dir()扩大目录后继续查找。 -
根目录位于固定根目录区,不能增长,因此根目录空间不足时应返回
-1。
3.1.3 设置或更新文件关键词¶
实验给出的函数已经完成了路径查找、文件类型检查、新关键词长度检查、旧关键词读取、旧关键词位置计算等工作。你需要根据新关键词需要的属性记录数量,分别处理三种情况。
实现流程如下:
-
如果新关键词为空,不需要移动标准文件目录项。调用
fat16_mark_range_deleted_except()删除旧关键词属性记录,再调用fat16_kw_index_update_file()同步内存中的关键词索引状态,最后释放 inode 并返回成功。 -
如果新关键词需要的属性记录数量不超过旧数量,标准文件目录项仍然可以留在原位置。先计算新的关键词属性记录起始位置,再调用
fat16_write_keywords_at()把新关键词写入旧范围的后半段。注意调用fat16_mark_range_deleted_except()删除多余槽位。完成后调用fat16_kw_index_update_file()更新索引,释放 inode 并返回成功。 -
如果新关键词需要更多属性记录,原位置放不下,需要调用
fat16_find_free_run()找到一段能够同时容纳新关键词属性记录和标准文件目录项的连续空间,注意:旧范围(包括标准目录项)的槽位可以复用。 -
找到新位置后,先调用
fat16_write_keywords_at()写入新关键词属性记录,再用fat16_slot_by_index()定位新的标准目录项位置,并调用fat16_write_entry()把原标准目录项复制过去。 -
旧位置上的关键词属性记录和标准目录项需要调用
fat16_mark_range_deleted_except()标记为删除。 -
如果被移动的文件 inode 已经在内存 inode 表中,还需要在持有
itable.lock时调用fat16_find_loaded()找到它,并更新它的inum、目录项所在扇区和目录项偏移。否则,内存中的 inode 会继续指向旧目录项位置,后续写回可能覆盖错误的目录项。 -
完成移动后,函数末尾已有的代码会调用
fat16_kw_index_update_file()同步关键词索引,并释放目录 inode。
4. Bonus:B+ 树关键词索引¶
Bonus 的目标是实现 query_file_indexed() 需要使用的 B+ 树索引。
本节说明本次实验 Bonus 需要补全的函数,但不再提供详细流程,只提供可能使用到的辅助函数和大致思路。同学们可以参考以下顺序完成实验4 Bonus。如果对某个辅助函数的参数含义不清楚,可以参考 实验4补充材料:辅助函数与宏定义速查。
Bonus 检查
同学们完成 Bonus 并不只是需要实现 B+ 树即可,还应当了解本实验是如何运用 B+ 树到文件属性查询的,助教在线下提问时可能会问到相关问题。你需要自行编写 Bonus 脚本验证正确性并且使用你实现的 B+ 树的查询速度要快于全盘查询,无需显式地展示查询用时,只要能肉眼观察到区别即可,即使细微。
4.1 分裂叶子节点¶
static int bptree_split_leaf(struct bptree *tree, struct bptree_node *node,
char **promoted, struct bptree_node **right);
大致流程:将溢出的叶子结点分为两部分,注意中间键的处理。
参数:
tree:目标 B+ 树。node:溢出的叶子节点。promoted:输出参数,写入复制到父节点的 key。right:输出参数,写入新右叶子节点。
返回值:
- 成功返回
0。 - 分配失败返回
-1。
你可能使用到:
bptree_new_node()。
Tips
本实验设置的每结点最大键数为 15,但是使用结点中的键数组却占用了 16 个键的空间,这是为插入一条记录时做的缓冲处理。
4.2 分裂内部节点¶
static int bptree_split_internal(struct bptree *tree,
struct bptree_node *node,
char **promoted,
struct bptree_node **right);
大致流程:将溢出的内部结点分为两部分,注意中间键的处理。
参数:
tree:目标 B+ 树。node:溢出的叶子节点。promoted:输出参数,写入提升到父节点的 key。right:输出参数,写入新右子节点。
返回值:
- 成功返回
0。 - 分配失败返回
-1。
你可能使用到:
bptree_new_node()。
4.3 递归插入关键词¶
static int bptree_insert_rec(struct bptree *tree, struct bptree_node *node,
const char *key, int len, void *value,
char **promoted,
struct bptree_node **right);
大致流程:递归下降插入记录并上升处理插入一条记录时可能出现的结点分裂等问题,请注意区分叶子结点与内部结点。
参数:
tree:目标 B+ 树。node:溢出的叶子结点。key、len、value:需要插入的(key, value)对与key的长度,注意这里的value是key对应的值块链表的最小单位。promoted:输出参数,如果发生了分裂则写入需要提升/复制的 key,否则为 0。right:输出参数,如果发生分裂则写入新的右子结点。
返回值:
- 插入成功返回
0。 - 插入失败返回
-1。
你可能需要用到:
bptree_keycmp_token()bptree_values_add()bptree_strdup_key()bptree_split_leaf()bptree_insert_rec(),递归调用bptree_split_internal()
4.4 插入入口与根节点变化¶
大致流程:插入一条记录,注意树空情况和可能会发生根节点分裂的情况。
参数:
tree:目标 B+ 树。key、len、value:需要插入的(key, value)对与key的长度。
返回值:
- 插入成功返回
0。 - 插入失败返回
-1。
你可能需要用到:
bptree_new_node()bptree_insert_rec()
4.5 查找关键词¶
大致流程:从根结点开始向下探找键为 key 的键值对,如果找到则返回对应的值块链表,否则为 0。
参数:
tree:目标 B+ 树。key、len:需要查询的key与key的长度。
返回值:
- 找到记录则返回对应的值块链表,否则返回 0。
你可能需要用到:
bptree_keycmp_token()