Part 1 阅读材料:理解 LLM 推理生命周期¶
阅读目标¶
- 作为
Hw2与实验二的配套阅读材料,帮助你从系统实现的角度理解一次 LLM 推理的完整生命周期; - 建立“程序读了什么、算了什么、输出了什么”这条主线,而不是只停留在名词记忆;
- 理解
Model Loading Time、TTFT、TPOT与Prefill、Decode、KV Cache、冷启动之间的关系; - 为完成
Hw2中与性能测量、资源瓶颈分析相关的书面作业,以及实验二中的后续代码阅读与实现做好准备。
阅读前提¶
- 已具备基本的 C 语言代码阅读能力,能看懂函数调用、结构体和简单循环;
- 已理解用户态 / 内核态、系统调用、进程创建与等待等基础操作系统概念;
- 下文中出现的
tools/、user/、kernel/、docs/等路径,均默认是相对于课程代码仓库根目录而言; - 若你此前已经完成
Lab0与Lab1的基础环境配置和代码阅读,本页内容会更容易理解。
与实验二的关系
本文是 Hw2 与实验二的配套阅读材料。本文不以完整展开 Transformer 的数学细节为目标,而是从系统实现的角度说明课程代码中的一次 LLM 推理过程。
阅读主线
阅读本页时,请始终围绕下面三个问题:
- 程序读了什么?
- 程序算了什么?
- 程序输出了什么?
注意事项
当前课程仓库中的实现是一个教学版推理服务,而不是通用的LLM推理系统。
- 基础实验默认以
llmrun_smol为主; llmrun_qwen主要是附加实验相关。
1. 什么是大语言模型(LLM)与 Transformer 架构?¶
在讨论底层系统调用、内存分配与文件装载之前,有必要先给出大语言模型(Large Language Model, LLM)在系统实现层面的基本定义。对于本实验而言,重点不在于讨论模型是否“理解”语言,而在于明确它接收什么输入、执行什么计算以及产生什么输出。
1.1 大语言模型(LLM)的数学本质:自回归预测¶
从计算机系统的角度看,LLM 可以抽象为一个规模很大的参数化函数。它的基本任务是自回归预测(Autoregressive Prediction)。
给定一段由离散整数表示的历史上下文,即一串 token id,模型通过多层线性变换、非线性变换与归一化运算,输出下一个位置上的概率分布。系统再依据这一分布选取一个新的 token,将其追加到序列末尾,并继续进行下一轮预测。
因此,从实现角度看,LLM 推理的核心过程可以概括为:输入历史 token 序列,计算下一个 token 的分布,并迭代生成后续结果。
1.2 Transformer:现代 LLM 的统一底层引擎¶
实现上述预测机制的模型架构曾有多种,例如早期的 RNN 和 LSTM。但在当前主流生成式大模型中,更常见的选择是 Transformer 架构。本实验中使用的 Smol 与 Qwen 模型也属于这一范畴。
Transformer 架构(如图1所示)最初由 Google 于 2017 年提出。为了适应自回归生成任务,现代生成式大模型通常采用仅保留 Decoder(解码器)的变体。
因此,当我们讨论 LLM 推理过程中的计算密度、访存压力、I/O 成本和缓存组织时,本质上是在分析 Transformer Decoder 在具体软件栈与硬件环境中的执行特征。
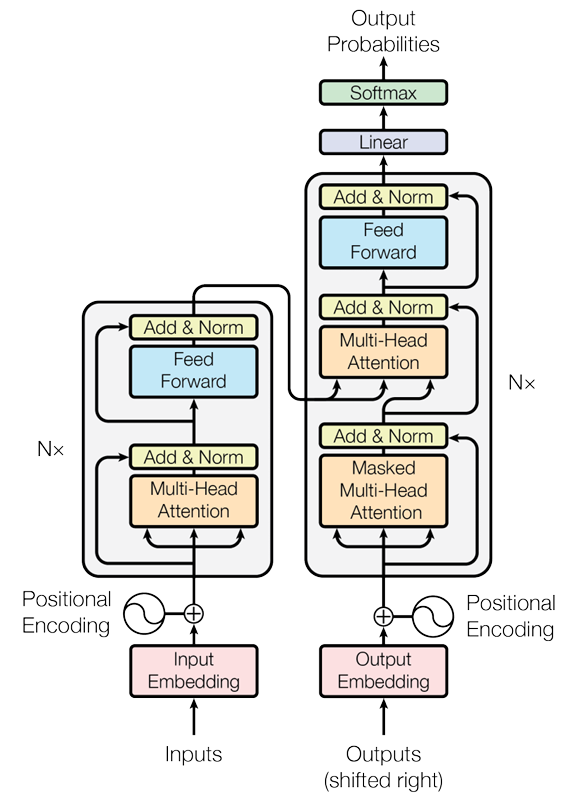
1.3 系统视角下的 Transformer 计算图¶
从系统工程的视角看,Transformer 可以理解为一个高度结构化的静态计算图(Computational Graph)。输入数据在这张计算图中按照固定顺序流经各个算子,因此其计算与存储访问模式具有较强的规律性。
正因为其执行路径相对固定,我们可以较为清晰地分析不同阶段的资源消耗特征,并将这些特征与课程代码中的实现对应起来。
2. LLM 推理过程介绍¶
在阅读运行时代码之前,还需要进一步明确模型处理对象的表示形式以及基本处理步骤。采用这一视角,有助于把“输入数据、中间状态、输出结果”对应到具体文件、缓冲区和函数调用。
从抽象流程看,一次推理大致可以表示为:
2.1 文本是如何变成机器可计算数据的¶
模型不能直接以字符串作为计算对象。对于机器而言,文本首先会被切分为若干 token,每个 token 对应词表中的一个整数编号,即 token id。
随后,模型通过嵌入表将这些离散编号映射为定长向量,这一步称为 embedding。因此,Transformer 直接处理的并不是原始文本本身,而是:
- 一串
token id; - 一串由
token id查表得到的向量。
从系统角度看,这一步完成了从文本表示到数值表示的转换。
2.2 Attention 层在做什么¶
Attention 的主要作用是根据当前位置与历史位置之间的相关性,对上下文信息进行加权聚合。
在计算当前 token 的表示时,模型不仅使用当前位置的向量,还会访问先前各个位置的表示,并根据相关性选择性地整合这些历史信息。
从系统实现的角度看,Attention 更值得关注的是它的数据依赖关系:
- 它必须访问历史位置的数据;
- 它必须比较当前信息与历史信息;
- 它必须把取回的结果重新组合成当前位置的输出。
因此,可以先将 Attention 理解为:读取历史上下文状态,并据此构造当前位置的上下文表示。
2.3 FFN 层在做什么¶
FFN(前馈网络)负责对当前位置的向量表示进行进一步变换。
与 Attention 不同,FFN 不再沿序列维度访问历史位置,而是仅针对当前位置的表示执行逐位置的非线性变换。它的典型作用包括:
- 重组当前位置的特征;
- 放大有用信息;
- 抑制无用信息;
- 为下一层提供更合适的表示。
因此,FFN 可以概括为:对当前位置的表示进行非线性特征变换。
2.4 从整体上看,LLM 在做什么¶
综合上述步骤,LLM 在推理阶段的宏观行为可以概括为:
- 输入一串
token; - 把
token变成向量; - 经过多层
Attention + FFN反复处理; - 对整个词表打分;
- 选出一个“下一个 token”;
- 把这个 token 接到序列末尾,再继续下一轮。
因此,本实验中最需要把握的基本结论是:
LLM 推理的核心任务,是在给定历史 token 序列的条件下预测下一个 token。
3. LLM 推理的生命周期:Tokenization、Prefill 与 Decode¶
理解了宏观流程以后,下一步要建立“生命周期”视角。一次完整的推理过程,通常可以分成下面几个阶段:
TokenizationPrefillDecodeDetokenization
课程代码中的边界划分
在当前课程代码中,Guest 运行时并不负责完整的 tokenization 与 detokenization。这两部分被有意放在 Guest runtime 之外,以便突出系统路径本身的实现逻辑。
3.1 Tokenization 与 Detokenization 在当前课程代码中的位置¶
在完整的推理系统中,用户输入的文本通常首先由 tokenizer 编码为 token id 序列,模型生成的 token id 再由 detokenizer 还原为自然语言字符串。
但在当前 Kernel 中,Guest 侧边界又进一步做了简化:
- 仓库直接提供助教预导出的模型资产包,如
models/smol.zip与models/qwen.zip; Makefile会将这些资产解压并打包进 Guest 文件系统中的/AI/SMOL、/AI/QWEN;INFO.TXT会保留面向人类阅读的元数据,例如示例prompt_tokens、expected_tokens与decoded_expected;- Guest 侧的
llmrun_smol/llmrun_qwen接口直接接收token id,来源是命令行参数或--stdin输入,而不是原始文本。
这意味着:当前 Guest 侧的核心任务不是做文本分词,而是装载模型资产、读取 token id 请求并完成前向计算。
3.2 Prefill:先把历史上下文状态建立起来¶
Prefill 阶段处理的是整段 prompt。它的关键任务在于:
- 并行处理 'prompt' 中的所有
token; - 生成第一个输出
token; - 为每一层建立可复用的历史状态;
- 把这些状态写进
KV Cache,避免后续冗余计算。
因此,Prefill 的作用可以概括为:
将原始 prompt 转换为后续生成阶段可以直接复用的上下文状态。
3.3 Decode:每次只生成一个新 token¶
当 Prefill 完成后,系统进入 Decode 阶段。这个阶段的特点是:
- 根据请求的所有历史缓存,生成一个新的
token; - 下一轮计算仍然要依赖之前所有历史状态。
虽然每一步通常只新增一个 token,但随着序列长度增加,每一步需要访问的历史 K/V 状态也会增加,因此访存成本会逐步上升。
3.4 为什么 Prefill 更像 Compute-bound,Decode 更像 Memory-bound¶
从系统资源消耗模式看,这两个阶段并不相同:
| 阶段 | 主要任务 | 典型特征 | 更容易遇到的瓶颈 |
|---|---|---|---|
Prefill |
处理整段 prompt,建立 KV Cache |
层计算密集,权重复用高 | Compute-bound |
Decode |
每次生成一个新 token,并读取历史状态 |
新计算少,但历史缓存读取越来越重 | Memory-bound |
其原因可以概括为:
Prefill需要对整段输入执行完整的层计算,因此主要受计算吞吐限制;Decode每一步新增计算较少,但需要持续读取越来越长的历史状态,因此更容易受到内存访问与数据搬运的限制。
4. 回到当前 Kernel Base:输入、计算与输出的实现分工¶
在概念层面完成基本划分之后,下一步需要回到当前我们的实验仓库本身。接下来,我们将沿着“程序读了什么、算了什么、输出了什么”这条主线,来分析当前代码中一次 LLM 推理的完整生命周期。
4.1 先看整条调用链¶
在当前仓库中,一次最小 LLM 调用链可以概括为:
models/smol.zip / models/qwen.zip
-> Makefile: smol-assets / qwen-assets
-> models/SMOL / models/QWEN
-> Makefile: fsimg-smol / fsimg-qwen / fsimg-llm
-> tools/mkfsimg.py --add-dir AI/SMOL=... / AI/QWEN=...
-> QEMU 中的 /AI/SMOL 或 /AI/QWEN
-> sh 启动 llmrun_smol 或 llmrun_qwen
-> chdir("/AI/SMOL") / chdir("/AI/QWEN")
-> llm_runtime_init()
-> 读取 CFG.BIN / EMB.BIN / NRM.BIN / Lxx.BIN / ROP.BIN (/LTY.BIN)
-> llm_session_run()
-> llm_drive_decode()
-> token_forward()
-> stdout 输出生成出的 token id
如果进一步阅读进阶实验,则 Guest 侧主程序会切换为 user/llmrun_qwen.c;它复用同一套共享 runtime 框架,但会根据 LTY.BIN 区分不同层类型。
默认 fsimg 不会自动带上模型资产
当前 make fsimg 只会打包用户程序本身;若希望 Guest 真正看到 /AI/SMOL 或 /AI/QWEN,需要使用 make fsimg-smol、make fsimg-qwen、make fsimg-llm 或对应的 qemu-smol、qemu-qwen、qemu-llm 目标。
4.2 当前 Guest 内核在做什么¶
由于当前 base 中没有专门的 ai_service,内核扮演的是通用操作系统支撑层,而不是 LLM 业务编排层。llmrun_* 依赖内核提供的主要能力包括:
exec/wait/ shell 启动流程:让sh能像启动普通用户程序一样启动llmrun_*;chdir/stat/open/read:让用户态程序能够进入/AI/...目录并读取模型资产;sbrk:为权重、cache 和 workspace 申请堆内存;uptime:记录一次前向的大致 tick 开销;- 控制台输出:把生成结果打印到标准输出。
因此,在当前实现里,内核并不理解 prompt 的语义,也不解析模型格式,更不会把结果写到某个专门的 AI 输出文件中。所有与 LLM 相关的特定逻辑,都放在用户态 llmrun_* 和共享 runtime 中。
4.3 Guest 用户态 runtime 读了什么¶
user/llmrun_smol.c 和 user/llmrun_qwen.c 的主程序本身都比较薄。真正的共享装载与执行框架主要位于:
user/llmrun_support.huser/llmrun_support.c
其中,session_init() 先通过 chdir() 进入资产目录,再调用 llm_runtime_init()。后者会依次完成:
load_model_cfg():读取并校验CFG.BIN;load_layer_kinds():在Qwen路径下解析LTY.BIN;load_file("EMB.BIN"):装入 embedding;load_file("NRM.BIN"):装入最终归一化参数;- 循环读取
Lxx.BIN,再通过parse_layer_blob()解析每层权重; load_file("ROP.BIN"):装入 RoPE 表;- 为
rt->seq申请运行期序列缓冲区。
在此之后,程序还会继续分配:
K/V cache;Qwen额外需要的linear_conv_cache与linear_state_cache;- 一次前向所需的 workspace。
当前 runtime 的装载策略依旧较为直接:通过 open + read_full + xmalloc 将资产整体读入用户态堆内存。它的优点是实现简单、透明、便于调试;代价则是冷启动 I/O 成本明显,而且权重与 cache 都驻留在单个用户进程地址空间中。
如果你想打印 Model Loading Time,应该看哪里
对当前代码框架而言,最自然的埋点位置有两种:
- 若你想测“模型资产装入内存”本身的时间,建议围绕
llm_runtime_init()附近打印,因为CFG.BIN、EMB.BIN、NRM.BIN、Lxx.BIN、ROP.BIN等加载逻辑都集中在这里; - 若你想测“程序启动后,为一次可运行会话完成初始化”的时间,建议围绕
session_init()附近打印,因为它除了调用llm_runtime_init(),还会继续分配K/V cache、workspace,以及Qwen额外需要的 cache。
简单理解就是:
llm_runtime_init()更接近纯粹的Model Loading Time;session_init()更接近“运行前准备完成”为止的总初始化时间。
需要注意的是,当前请求 token 不来自某个固定输入文件。llmrun_* 接收的输入来自:
- 命令行参数,例如
llmrun_smol --predict 1 504 3575 282 4649 314; - 或
--stdin服务模式下的一行请求,格式为<predict> <token0> <token1> ...。
后续如果在 Part 2 中讨论“为什么要进一步引入 ai_submit、后台 worker 与请求队列”,默认已经以本节为前提,不再重复介绍 session_init() 或各类资产文件的加载顺序。
4.4 token_forward() 中究竟算了什么¶
在基础实验的 user/llmrun_smol.c 中,核心前向函数是 token_forward()。若只保留主干路径,它的工作可以概括为:
读 embedding -> 跑层计算 -> 更新状态 -> 扫描词表 -> 选出下一个 token
更具体地说,其主要流程是:
- 从
rt->seq[pos]取出当前token id; - 在
EMB.BIN对应的量化 embedding 表中取出这一行向量; - 对
Smol路径,逐层执行llm_apply_full_layer()与llm_apply_ffn(); - 对
Qwen路径,按LTY.BIN指定的层类型在llm_apply_full_layer()与apply_linear_layer()之间切换,再执行FFN; - 把新的状态写入
K/V cache,并按需读取历史状态; - 做最终归一化;
- 通过
argmax_embed()在 embedding 矩阵上扫描整个词表,得到下一个token id。
从系统角度看,token_forward() 本质上是在反复执行以下几类操作:
- 读 embedding;
- 读层权重;
- 读写 cache;
- 做矩阵乘加与归一化;
- 生成下一个
token id。
4.5 Prefill 和 Decode 在代码中的对应位置¶
在当前代码中,Prefill 和 Decode 并没有被拆成两个完全独立的主循环,而是统一放在 llm_drive_decode() 中:
for (int pos = 0; pos < total_steps; pos++) {
int next = token_forward(rt, kcache, vcache, linear_conv_cache, linear_state_cache, pos, ws);
if (pos >= token_count - 1) {
int gen_idx = pos - (token_count - 1);
rt->seq[token_count + gen_idx] = (uint32)next;
}
}
这里需要注意的是:
- 当
pos < token_count - 1时,系统还在消费用户提供的输入 token,并为整段上下文建立历史状态,这一段就是Prefill; - 当
pos >= token_count - 1时,系统开始把next token回写到rt->seq,这一段就是Decode。
因此,Prefill 与 Decode 的区别不在于是否被写成两个独立函数,而在于当前迭代是在“消化已有输入”,还是在“追加新生成结果”。
如果你想打印 TTFT 和 TPOT,应该看哪里
当前代码里,最适合做 TTFT / TPOT 埋点的位置就是 llm_drive_decode() 附近,而不是更底层的矩阵乘函数里。原因很简单:这里同时看得到“本次请求何时开始真正进入前向循环”以及“第几个生成 token 何时写回 rt->seq”。
你可以按下面的思路理解:
TTFT:在llm_drive_decode()开始处记录起点时间;当分支if (pos >= token_count - 1)第一次成立、也就是第一个生成 token 即将写回rt->seq时打印时间差;TPOT:也放在同一个分支附近观察。最直接的办法是每次生成一个 token 就打印一次与上一个生成 token 的时间差;如果你只想看平均值,也可以在第一个生成 token 之后开始累计,到循环结束后再除以后续生成 token 的数量。
如果你希望把“请求校验 + cache 清空”这部分也算进首 token 延迟,那么起点可以再往外挪到 llm_session_run() 附近;如果你只想突出 Prefill / Decode 主循环本身,那么直接以 llm_drive_decode() 作为起点会更清晰。
4.6 最终输出了什么¶
在当前实验中,Guest llmrun 的直接输出并不是自然语言字符串,也不是写入某个 /AI.<pid>.OUT 文件,而是直接打印到标准输出的一行文本。其内容是:
- 生成出的
token id; - 多个
token之间用空格分隔; printf("%s\\n", result)在末尾补一个换行。
这段输出由 llm_format_generated_tokens() 负责格式化,因此从系统边界的角度看,更准确的描述是:
当前 Guest runtime 输出的是十进制 token id 序列,而不是已经 detokenize 完成的自然语言句子。
面向人类阅读的文字说明,仍然主要保留在宿主机准备的 INFO.TXT 中;若需要把生成结果还原为自然语言,还需要在 Guest 之外再做一次 detokenization。