附录:Lazy Allocation 与 Copy-on-Write 在 LLM 推理系统中的应用¶
1. 从 OS 内存管理到 LLM Serving 显存管理¶
1.1 传统 OS 中的核心问题¶
简要回顾本次实验中的两个问题:
sbrk()扩大地址空间时,是否要立刻分配物理页?fork()创建子进程时,是否要立刻复制父进程的所有物理页?
对应的优化思想是:
| 场景 | 朴素做法 | 优化做法 |
|---|---|---|
sbrk() |
立即分配物理页 | Lazy Allocation,首次访问时分配 |
fork() |
立即复制所有页 | COW,首次写入时复制 |
这两种机制的共同点是:先让用户程序看到一个合法的逻辑状态,但暂时不完成全部物理工作。只有当访问真正发生时,内核才通过 Page Fault 或 copyout() 路径补上缺失的物理页、复制私有页或恢复写权限。
1.2 LLM 推理中的类似问题¶
LLM 推理过程中也会遇到类似问题:
- 每个请求都需要 KV Cache;
- 请求输出长度不可预测;
- 有些请求很短,另一些请求可能生成很长;
- 并行采样可能为同一个 prompt 产生多个候选分支;
- 多个分支前缀相同,但后续 token 可能不同;
- GPU 显存是非常昂贵且有限的资源。
因此,LLM 推理系统也需要回答类似问题:
这正好对应 Lazy Allocation 和 Copy-on-Write 的思想:
| OS 实验中的问题 | LLM Serving 中的类比问题 |
|---|---|
| 堆空间逻辑上变大,但用户不一定会访问每一页 | 请求声明最大长度,但不一定真的生成到最大长度 |
fork() 后父子进程大部分页面内容相同 |
多个候选分支共享同一个 prompt prefix |
| 物理内存有限,不能浪费在未访问页面上 | 显存有限,不能浪费在未生成 token 的 KV Cache 上 |
| 写共享页时才复制 | 分支真正写入共享 KV block 时才复制或拆分 |
2. LLM 推理系统中的显存管理核心:KV Cache¶
2.1 什么是 KV Cache¶
在 Transformer 的自回归推理中,模型每生成一个新的 token,都需要在 attention 计算中关注前面已经出现过的 token。对于每一层 attention,前面 token 对应的 key/value 向量在后续生成过程中会被反复使用。
如果每生成一个新 token 都重新计算所有历史 token 的 key/value,会引入大量的计算冗余。因此,推理系统通常会把已经计算出的 key/value 保存下来,供后续 decode step 直接复用。这部分缓存就称为 KV Cache。
可以从 Prefill 和 Decode 两个阶段理解它:
Prefill处理整段 prompt,把 prompt 中每个 token 的 key/value 写入 KV Cache;Decode每次生成一个新 token,同时读取前面所有 token 的 KV Cache,并把新 token 的 key/value 追加进去。
随着上下文长度增加,需要保存的 key/value 也会增加。因此,每条请求的 KV Cache 大小通常随序列长度 sequence length 近似线性增长。
2.2 KV Cache 的存储压力¶
LLM 推理的主要显存占用分为三部分:模型权重、KV Cache和激活值。而模型权重与激活值大小相对固定,因此管理起来较为容易。而 KV Cache 具备高度动态性:每条请求的 KV Cache 会随着请求 decode 生成而增长,同时当一条请求完成后,其占用的 KV Cache 空间又会释放。因此,频繁动态变化且不具备可预测性的 KV Cache 管理是推理系统面临的主要显存管理难题。
如果只是这样说,大家可能对 KV Cache 的存储压力没有直观概念,这里给出一个概念性的估算公式:
KV Cache bytes
≈ 2 × num_layers × sequence_length
× num_kv_heads × head_dim
× bytes_per_element × batch_size
其中开头的 2 表示 key 和 value 两部分。这个公式不要求大家精确计算,重点是看出 KV Cache 会随 sequence_length、并发请求数和采样分支数线性增长。以 Qwen3-32B 模型同时服务 32 条长度为 2048 的请求为例,这些请求的 KV Cache 占用会达到 16GB,对 GPU 显存带来巨大压力。因此,LLM Serving 系统对于 KV Cache 管理优化有着迫切的需求。
2.3 优化 KV Cache 管理对于 LLM Serving 的重要性¶
优化 KV Cache 管理并不只是为了“省一点内存”。在 LLM Serving 场景中,它会直接影响系统吞吐和延迟:
- 并发能力: 同样大小的显存下,KV Cache 越节省,系统能同时接收的请求越多。
- Batch 大小: 更多请求可以被调度到同一轮推理中,硬件利用率通常更高。
- 长短请求混合: 短请求不应该因为系统按最大长度预留而占住大量显存。
- 提前结束: 请求遇到结束符或达到停止条件后,应只释放实际用过的缓存块。
- 调度稳定性: 如果 KV Cache 管理粗糙,系统更容易在高并发或长上下文场景下出现显存不足。
这和本实验中的 Lazy Allocation 非常接近:如果程序只是 sbrk() 了很大的地址空间,却只访问其中一小部分,立即分配所有物理页就是浪费;如果 LLM 请求预留了最大上下文长度的显存空间,却实际只生成很短,这就会造成严重的显存浪费。
3. Lazy Allocation 与 KV Cache 按需分配¶
3.1 朴素做法:按最大可能生成长度预留 KV Cache¶
在早期,LLM Serving 系统采用的是一种朴素 KV Cache 管理方式:在请求到来时,按照最大上下文长度直接为该条请求预留完整 KV Cache 空间。
例如:
这样会带来明显浪费:
- 短上下文的请求浪费大量空间;
- 提前结束的请求浪费空间;
- 多并发时显存压力很大;
- 调度器更容易拒绝新请求;
- 系统可同时服务的请求数量下降。
为什么不能精确预测输出长度
看到这里,可能有的同学会疑问:为什么不能按照实际生成长度来精确预留 KV Cache 空间呢?
原因在于,LLM 的输出长度在生成开始前通常无法确定。LLM 采用自回归式生成机制,每一步只根据当前上下文预测下一个 token,并不会在一开始就确定完整回答的长度。例如,你提交一段代码让 LLM 实现某个功能,模型需要逐 token 生成代码和解释,直到生成结束符、达到 max_new_tokens 限制,或被外部停止条件中断。因此,推理系统无法提前精确知道最终会生成多少 token。所以最朴素的实现只能按照最大生成长度为每条请求分配 KV Cache 空间。
这和 eager sbrk() 的问题很像:逻辑上可能需要很多空间,不等于现在就应该分配所有物理资源。
3.2 一个小例子:KV Cache 显存碎片化¶
假设推理系统采用朴素的连续预分配策略:每个请求进入系统时,都会按照最大长度提前分配一整段连续的 KV Cache 空间。
例如下图中有两个请求:
-
请求 A:
- 最大长度:2048 tokens
- Prompt 长度:7 tokens
- 当前已生成:1 token
- 后续实际只会再生成:2 tokens
-
请求 B:
- 最大长度:512 tokens
- Prompt 长度:3 tokens
- 当前已生成:1 token
- 后续实际只会再生成:1 token
对于请求 A,真正会用到的 KV Cache slot 只有:7 + 1 + 2 = 10 slots
但系统提前为它分配了 2048 个 slots,因此有:2048 - 10 = 2038 slots
这部分空间已经属于请求 A,其他请求不能使用,但它最终也不会被真正用到,这就是 内部碎片f。
同理,请求 B 真正会用到的 KV Cache slot 只有:3 + 1 + 1 = 5 slots
但系统提前为它分配了 512 个 slots,因此有:512 - 5 = 507 slots
这部分未使用的预分配空间同样属于 内部碎片。
此外,请求 A 和请求 B 的 KV Cache 区域之间,还可能因为释放、对齐或连续分配失败而留下小块空闲空间。如果这块空闲空间太小,无法分配给新的请求,那么它虽然是空闲显存,却无法被有效利用,这就是 外部碎片。
因此,朴素的连续 KV Cache 预分配会带来两类显存浪费:
- 内部碎片:请求内部被预留但最终没有使用的 KV Cache 空间
- 外部碎片:请求之间空闲但无法被有效分配的小块显存空间

3.3 Lazy Allocation 思想的迁移¶
对应本实验中的 sbrk():
LLM 推理系统中也可以类似处理:
换句话说,系统可以先记录请求的最大长度、当前长度和逻辑页列表,但只有当生成过程真正推进到某个逻辑页时,才从显存池中真正分配物理 KV 页。
这相当于把“堆地址空间的按需分配”迁移成“推理状态的按需分配”。
3.4 按页分配 KV Cache 的好处¶
按页或按 block 管理 KV Cache 以后,系统可以获得几个直接好处:
- 降低显存预留浪费;
- 支持更高并发;
- 更适合长度差异大的请求;
- 请求提前结束时,只释放实际分配的页面;
- 调度器可以更灵活地管理空闲 KV Cache page;
- 不要求单个请求的 KV Cache 在显存中物理连续;
- 可以把不同请求的 KV page 统一放入池化分配器中复用。
这和虚拟内存中的页式管理非常类似:用户看到的是连续地址空间,但内核可以在底层用不连续的物理页承载它。
3.5 在 NexOS 中体验 Lazy Allocation 对 KV Cache 管理的效果¶
前面的讨论是概念性的。为了让大家直观看到“只预留最大空间”和“实际按需分配”的差异,助教分支中提供了一个小 demo:smolprobe。
smolprobe 会做一次很短的 SmolLM 推理,并在推理前后读取当前进程的内存页统计。它的关键行为是:
先用 sbrk() 预留完整 KV Cache 所需的最大虚拟地址范围
但不主动 memset() 整个 KV Cache
随后只运行一小段 prompt / decode
最后统计这次真正被映射出来的用户页数量
因此,这个 demo 验证的不是模型输出质量,而是 Lazy Allocation 是否把“逻辑上预留的 KV Cache 空间”和“物理上真正分配的页”区分开了。
说明
这个 demo 只用于观察效果,不属于实验评分项目。为了单独观察 Lazy Allocation,建议运行时先关闭 COW:COW_ALLOC=0。smolprobe 不会调用 fork(),所以 COW 对这个 demo 的结论没有影响。
运行方式¶
在 2026Spring-Kernel-Base 目录下重新构建带 LLM 文件系统的镜像:
进入 NexOS shell 后运行:
其中:
--prompt-tokens 1,2,3表示手动指定 3 个 prompt token;--gen-len 10表示最多生成 10 个 token;- 两个参数都需要带双横线
--; - 如果镜像中提供了
smol_probe别名,也可以运行smol_probe --prompt-tokens 1,2,3 --gen-len 10。
观察输出¶
开启 Lazy Allocation 后,输出中最重要的是最后几行:
$ smolprobe --prompt-tokens 1,2,3 --gen-len 10
[smolprobe] loading LLM assets...
[smolprobe] request prompt_tokens=3 gen_tokens=10
[smolprobe] kv_capacity max_pages=2880 active_pages_est=180
[smolprobe] running decode...
[smolprobe] SUMMARY max_kv_pages=2880 actual_mapped_pages=179 saved_pages=2701 saved_percent=93%
[smolprobe] reserve_phase virtual_pages=2880 mapped_pages=0 used_pages=0
[smolprobe] decode_phase mapped_pages=179 used_pages=185 active_pages_est=180
[smolprobe] verdict=LAZY_STYLE reserve kept KV pages unmapped; decode allocated on demand
这些字段的含义如下:
| 字段 | 含义 |
|---|---|
max_kv_pages |
如果按照最大 runtime_seq_len 为 KV Cache 一次性分配,需要的页数 |
active_pages_est |
这次短推理实际会触碰到的 KV Cache 页数估计值 |
actual_mapped_pages |
从预留 KV Cache 到推理结束,当前进程实际新增的有效用户映射页数 |
saved_pages |
相比一次性分配最大 KV Cache,少映射的页数 |
saved_percent |
节省比例,近似等于 saved_pages / max_kv_pages |
reserve_phase virtual_pages |
sbrk() 让进程逻辑地址空间增长的页数 |
reserve_phase mapped_pages |
仅执行 KV Cache 预留时实际新增的映射页数 |
decode_phase mapped_pages |
推理过程中因为真正访问 KV Cache 而新增的映射页数 |
used_pages |
全局物理页使用量变化,可能包含页表页等额外开销 |
对 Lazy Allocation 来说,应该重点看两点:
这说明:sbrk() 预留了最大 KV Cache 的虚拟地址范围,但没有立刻分配所有物理页;真正运行推理、写入某些 KV Cache 位置时,内核才通过 Page Fault 按需补页。
对比未开启 Lazy Allocation 的结果¶
为了对比朴素做法,可以重新构建一个未开启 Lazy Allocation 的内核:
然后在 NexOS shell 中运行相同命令:
此时预期现象是:
$ smolprobe --prompt-tokens 1,2,3 --gen-len 10
[smolprobe] loading LLM assets...
[smolprobe] request prompt_tokens=3 gen_tokens=10[smolprobe] kv_capacity max_pages=2880 active_pages_est=180
[smolprobe] running decode...
[smolprobe] SUMMARY max_kv_pages=2880 actual_mapped_pages=2880 saved_pages=0 saved_percent=0%
[smolprobe] reserve_phase virtual_pages=2880 mapped_pages=2880 used_pages=2886
[smolprobe] decode_phase mapped_pages=0 used_pages=0 active_pages_est=180
[smolprobe] verdict=EAGER_STYLE reserve mapped most KV pages immediately
也就是说,不开启 Lazy Allocation 时,sbrk() 预留 KV Cache 的时候就已经把最大长度对应的物理页分配出来了;后续短推理虽然只使用了其中一小部分,但大部分页已经被提前占用。
这两个实验结果的对比,充分说明了 Lazy Allocation 思想在 LLM Serving 中的重要价值。
4. Copy-on-Write 与 Parallel Sampling¶
4.1 什么是 Parallel Sampling¶
Parallel Sampling 指的是:对同一个 prompt 同时生成多个候选输出。例如,一个系统可能希望一次性生成多个回答,再从中选择质量最高的一个,或者把多个候选都返回给用户。
这些候选分支有一个重要特征:
- 它们最开始共享同一个 prompt;
- 因此 prompt 对应的 KV Cache 完全相同;
- 随着 top-k、top-p、temperature 等采样策略产生不同 token,分支可能逐渐分歧;
- 分歧点之后,不同分支的后续 KV Cache 不能再简单视为同一份状态。
这和 fork() 后父子进程的关系很像:刚 fork() 时,父子进程的大部分用户页内容相同;只有当其中一方写入某页时,才需要把共享页拆成私有页。
4.2 朴素做法:为每个分支复制 KV Cache¶
朴素实现可能会让每个采样分支都维护一份完整 KV Cache:
问题是:多个分支的 prompt prefix 完全相同,重复保存这些 KV Cache 会造成显存浪费。
例如:
prompt 长度 = 2048 tokens
parallel sampling = 4
朴素做法:
4 个分支各自保存一份 prompt KV Cache
实际情况:
这 4 个分支的 prompt KV Cache 完全相同
如果 prompt 很长,这种复制会非常昂贵。分支数量越多,重复存储越明显;上下文越长,复制成本越高。
4.3 COW 思想的迁移¶
对应本实验中的 COW fork:
Parallel Sampling 中也可以类似处理:
对于 KV Cache 来说,已经写好的历史 token 的 K/V 通常不会被修改,真正需要特别小心的是“共享 block 中还存在可继续追加的位置”的情况。
例如,一个 KV block 可以保存 16 个 token,而 prompt 最后一个 block 只用了其中 10 个位置。此时多个分支共享这个未填满的 block。如果某个分支继续生成新 token,并直接把新 K/V 写进这个共享 block,其他分支就会错误地看到它的后续状态。正确做法是:当写入目标 block 的引用计数大于 1 时,先为当前分支复制出私有 block,再写入新的 K/V。
这就是 COW 在 KV Cache 管理中的价值:共享相同前缀,避免一开始复制;真正写入共享块时,再把共享状态拆开。
4.4 一个小例子:Copy-on-Write 共享 KV Block¶
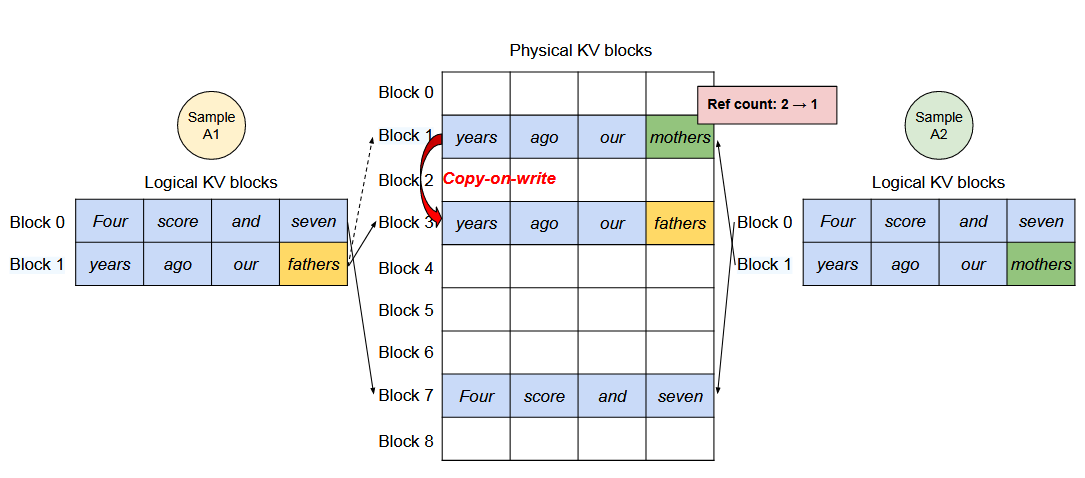
假设 KV block 大小为 4 个 token,两个采样分支 A1 和 A2 来自同一个前缀:
此时,A1 和 A2 的逻辑 KV block 都包含两个 block:
其中 Block 0 的内容完全相同,因此 A1 和 A2 可以共享同一个物理 KV block:
这样,Four / score / and / seven 对应的 KV Cache 只需要保存一份。
接下来,A1 和 A2 在第二个 block 的最后一个 token 上发生分歧:
在发生分歧之前,这个 block 可能还是共享的,引用计数为 2:
如果 A1 要把最后一个 token 写成 fathers,系统不能直接修改这个共享的物理 block。否则,A2 看到的内容也会被错误改掉。
因此,系统会触发 Copy-on-Write:
- 为
A1复制一份新的物理 KV block; - 在新 block 中写入
fathers; A1的 logicalBlock 1指向新 block;A2继续指向原来的 block;- 原 block 的
ref_count从 2 变成 1。
最终的映射关系变成:
A1 logical Block 1 ──> physical Block 3
years / ago / our / fathers
A2 logical Block 1 ──> physical Block 1
years / ago / our / [empty]
当 A2 之后也写入自己的下一个 token 时,它可以直接写入已经只属于自己的 physical Block 1:
这个例子说明,Copy-on-Write 的核心作用是:
相同的 prefix block 可以共享; 只有当某个分支需要写入不同 token 时,才复制对应的 KV block。
因此,COW 可以避免为每个采样分支重复保存完整的 KV Cache,同时又能保证不同分支在发生分歧后互不影响。
5. 小结¶
Lazy Allocation 和 Copy-on-Write 本质上都是在回答同一个问题:
Lazy Allocation 的回答是:
Copy-on-Write 的回答是:
在传统 OS 中,这些资源是物理页;在 LLM 推理系统中,这些资源可能是 KV Cache page、显存块。理解这层对应关系后,就能看出本实验和 AIOS 的联系:我们在 NexOS 中实现的是小而具体的内存机制,但它背后的思想可以迁移到更大的推理系统和服务系统中。