Space-Time Video Super-Resolution Using Temporal Profiles
Abstract
In this paper, we propose a novel space-time video super-resolution method, which aims to recover a high-frame-rate and high-resolution video from its low-frame-rate and low-resolution observation. Existing solutions seldom consider the spatial-temporal correlation and the long-term temporal context simultaneously and thus are limited in the restoration performance. Inspired by the epipolar-plane image used in multi-view computer vision tasks, we first propose the concept of temporal-profile super-resolution to directly exploit the spatial-temporal correlation in the long-term temporal context. Then, we specifically design a feature shuffling module for spatial retargeting and spatial-temporal information fusion, which is followed by a refining module for artifacts alleviation and detail enhancement. Different from existing solutions, our method does not require any explicit or implicit motion estimation, making it lightweight and flexible to handle any number of input frames. Comprehensive experimental results demonstrate that our method not only generates superior space-time video super-resolution results but also retains competitive implementation efficiency.
Contributions
- We introduce a new perspective for STVSR by exploiting the spatial-temporal correlation in the form of Temporal Profiles. To the best of our knowledge, this is the first effort to solve STVSR in a transformed domain inspired by multi-view computer vision tasks.
- We propose a TP-based STVSR network to simultaneously address video frame interpolation and video super-resolution, which consists of three elaborately designed modules. The proposed network has the advantages of end-to-end training, high computational efficiency, and lightweight architecture.
- Compared with existing solutions including the state-of-the-art, our method generates superior results both quantitatively and qualitatively. It also has better generalization ability and can be readily applied to real-world scenarios such as old movie restoration.


Temporal Profile (TP) and Our Method
1. What is Temporal Profile?
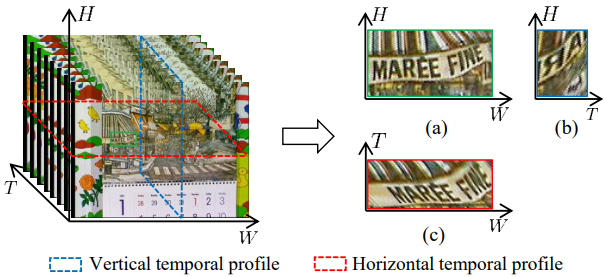
Example of how video frames are converted to TPs. We show (a) a patch of the frame, (b) vertical TP of the patch and (c) horizontal TP of the patch. Both horizontal and vertical TPs maintain similar structures to those in the spatial domain.
There are several benefits for doing so: (1) STVSR can be effectively modeled as a learning-based restoration task focusing on the specific 2D structure of TPs; (2) since TPs contain both space and time dimensions, spatial-temporal correlation can be better exploited; and (3) compared with existing methods relying on multi-frame alignment, long-term temporal context can be integrated by TPs in a more flexible way.
2. Overview of Our Method
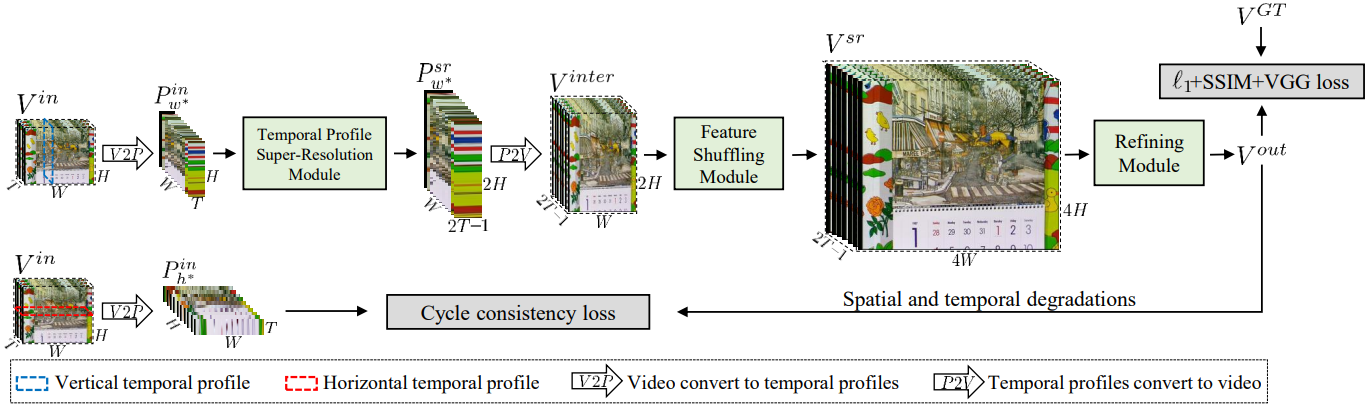
Our network consists of three parts: Temporal-Profile Super-Resolution Module (TPSRM), Feature Shuffling Module (FSM) and Refining Module (RM). In general, we first convert the LFR and LR video clip into TPs and send them to TPSRM to generate the super-resolved TPs with the target frame rate. Then, we convert the super-resolved TPs back to the video domain and send them to FSM to generate the video clip with the target spatial resolution. Finally, to obtain temporally-smooth and spatially-clear sequences, we further utilize RM for artifacts alleviation and detail enhancement.
Please read our paper for more details.
Results
1. Visual Results
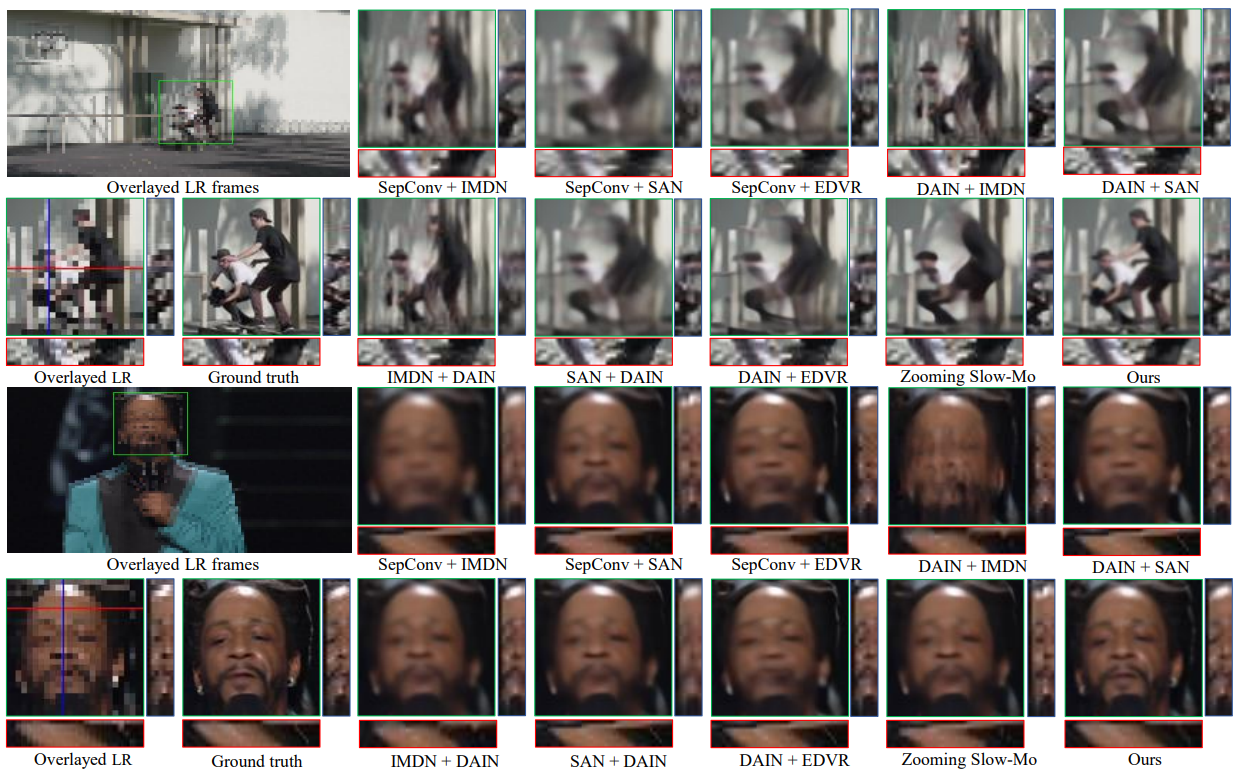
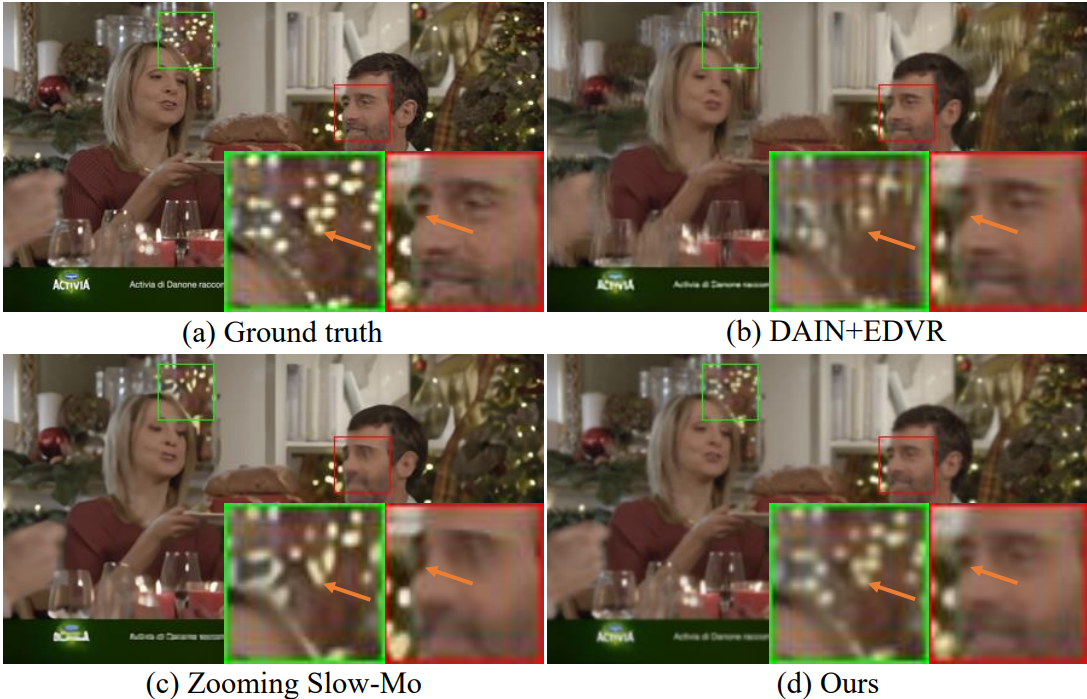
Visual comparisons of different methods on video frames from Vimeo90K dataset. To visualize the temporal consistency in 2D, we plot the transition of red horizontal and blue vertical scanlines over time (horizontal and vertical TPs).
Exemplar visual results of different methods are shown in the figure, where our method achieves notable visual improvements over its competitors. Affected by the cumulative errors, the results generated by the two-stage solutions are generally of poor quality with motion blur. The results from Zooming Slow-Mo are better than the two-stage solutions, however, it tends to produce over-smooth results sometimes. In contrast, our method generates visually appealing video frames with more accurate details and less blurs. As can be seen from the accompanied vertical and horizontal TPs, other comparison methods incur obvious temporal discontinuity, while our method is able to reconstruct temporally consistent results.
2. Quantitative Comparison
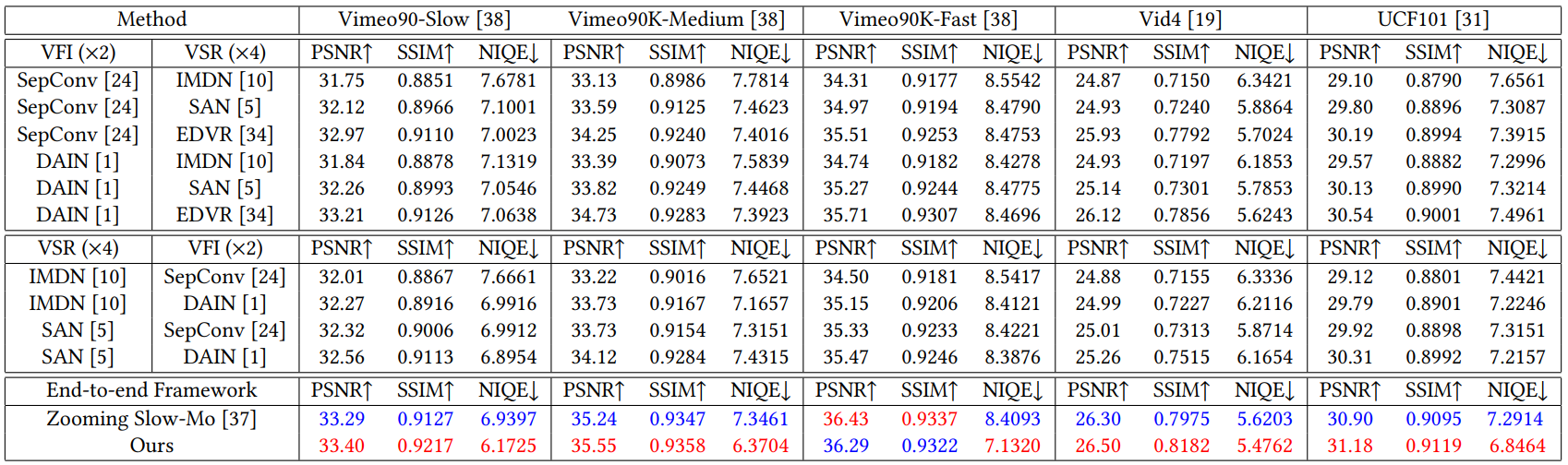
Quantitative comparison of different methods. The best and second results are highlighted in red and blue.
Our method outperforms the two-stage solutions by a large margin in terms of all the three metrics. In comparison with the one-stage method Zooming Slow-Mo, our method achieves overall superior results except on Vimeo90K-Fast. While our PSNR and SSIM values are slightly lower on this testset, we still achieve a notably better NIQE result, which indicates that our method achieves better visual quality.
3. Real-World Application: Old Movie Restoration

Due to the limited resolution of camera equipments, old movies often suffer from severe temporal and spatial degradations. In addition, preservation under different compression degrees further impacts the watching experience. Therefore, there is a large demand to convert these LFR and LR videos into HFR and HR ones with temporally-smooth and spatially-clear watching experience to satisfy the needs of modern displays.
As shown in the figure, both methods produce certain spatial artifacts. This is mainly because we do not explicitly address the compression issue in the network training, which is inconsistent with the real degradation process. Still, our method generates decent results in the background areas with movements, while Zooming Slow-Mo only generates spatially blurred results. It demonstrates that our model has better generalization ability.
Ablations
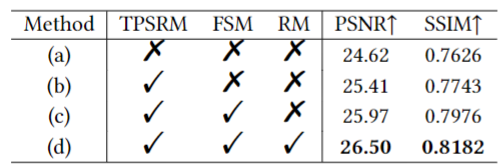
1. Investigation of Different Modules
 |
 |
We use linear interpolation for VFI and bicubic interpolation for VSR as the baseline in our ablation study. The ablation results are shown in the table, with an exemplar visual comparison in the above figure. Since TPSRM uses only vertical TPs and the spatial-temporal information has not been fully explored yet, the output of TPSRM are less detailed. After adding FSM for spatial-temporal information fusion, the details become richer. But there still exists certain motion blur, which is further addressed after RM. By cascading all the three modules, we can obtain a continuous improvement in visual quality. The above observation is in accordance with the numerical results in the table.

We also provide another observation of visual results in terms of error maps of the reconstructed video frames with respect to the ground truth. Note that the intermediate results of our method are also included for comparison. As can be seen, the output of RM is with less errors than the result of Zooming Slow-Mo, which demonstrates the effectiveness by exploiting the spatial-temporal correlation in the longer-term temporal context with TPs. On the other hand, we can see that the errors of outputs from the three modules of our method continue to decrease, which justifies the effectiveness of each module.
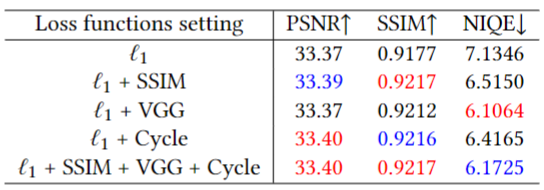
2. Investigation of Different Losses
 |
 |
We investigate the contribution of different loss terms by adjusting the weighting factors in Equation 10, and the results are shown in the table. When SSIM loss is adopted together with L1 loss, we can obtain the highest SSIM value. Since VGG loss is optimized at the feature level, the best result can be achieved in terms of the perceptual metric NIQE. Adding cycle consistency loss reinforces the consistency between the reconstructed frames and the LFR and LR inputs, which thus gives the highest PSNR value. Combining all of the four loss terms achieves an elegant overall performance. The figure shows a visual comparison and it is clear that using only L1 loss produces over-smooth results. In contrast, the combination of L1 loss and SSIM loss helps improve the detailed structure of the reconstructed frame. The joint usage of L1 loss and VGG loss generates perception-oriented results, while using cycle consistency loss for network optimization avoids over-enhancement and alleviates possible artifacts. Based on the above observation, it is reasonable to use all the four loss terms to train our network.
Limitations

Citation
@inproceedings{xiao2020spacetime,
author = {Xiao, Zeyu and Xiong, Zhiwei and Fu, Xueyang and Liu, Dong and Zha, Zheng-Jun},
title = {Space-Time Video Super-Resolution Using Temporal Profiles},
year = {2020},
address = {New York, NY, USA},
booktitle = {Proceedings of the 28th ACM International Conference on Multimedia},
pages = {664–672},
numpages = {9},
series = {MM '20}
}
Acknowledgement
Our project page are from RankSRGAN.
Contact
If you have any question, please contact Zeyu Xiao at zeyuxiao1997@163.com or zeyuxiao@mail.ustc.edu.cn.