概率论与数理统计
回顾
反函数的导数
设函数
亦即
变限积分函数的可微性
逐点可导:若函数
在点
复合函数求导:设函数
在
含参变量积分
含参变量常义积分
设二元函数
为含参变量常义积分,其中
若积分限也依赖于参变量,有变限含参常义积分
含参变量常义积分的可微性
如果函数
即可以交换求导运算与积分运算的顺序,或称在积分号下求导;
如果函数
含参变量积分的应用
几个重要的广义积分
狄利克雷(Dirichlet)积分
概率积分
拉普拉斯(Laplace)积分
菲涅耳(Fresnel)积分
欧拉(Euler)积分
定义:
连续性:
递推公式:
当
余元公式:
定义:
称为
连续性:
递推公式:
勒让德(Legendre)加倍公式:
特别地,有
第一章 事件及其概率

1.1 概率论简史
一些基本概念:
概率(probability),又称或然率、几率,是表示某个事件出现的可能性大小的一种数量指标,介于
和 之间. 赌博问题中的赢率(odds).
1.2 随机试验和随机事件
基本概念
定义1.1 随机试验

定义1.2 样本空间与事件
随机事件(简称 事件),用英文大写字母
表示; 样本空间(sample space):随机试验中所有基本事件构成的集合,用
或 表示; 样本点:样本空间的元素,即基本事件,用
表示.

一个随机试验的样本空间
是由该试验所有可能结果所组成的集合. 根据样本空间
的大小,可以将其分为三类:
有限样本空间(仅含有有限个样本点);
可数无穷样本空间(含有无穷且可数个样本点);
不可数样本空间(含有无穷且不可数个样本点).
事件的运算
对事件
定义1.3 必然事件和不可能事件
习惯上,将必然事件发生的概率设置为
,将不可能事件发生的概率设置为 . 但发生概率为
的事件未必是必然事件,发生概率为 的时间未必是不可能事件.

定义事件运算中的几个基本概念.
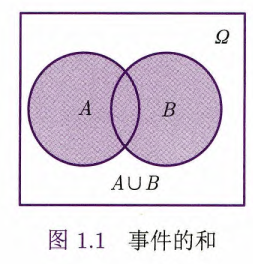
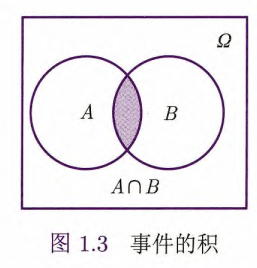
定义1.4 事件的和
事件
和事件 中至少有一个发生,称为 与 的和,记为 . 下面的维恩图(Venn diagram)中阴影部分表示了
.
定义1.5 事件的差
事件
发生而事件 不发生,称为 与 的差,记为 或 .
定义1.6 事件的积
事件
和事件 同时发生,称为 与 的积,记为 , 或 .
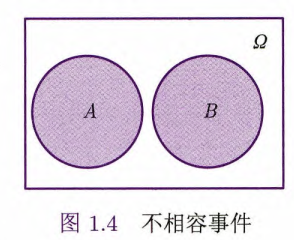
定义1.7 不相容事件
事件
和事件 不能同时发生(即 ),称为事件 和事件 不相容(incompatible)或互斥(mutually exclusive).
特别,当事件两两不相容时,可以把“并”运算符号改写为通常的加号.
定义1.8 对立事件
这一事件称为 的对立事件(或余事件),记为 或 .


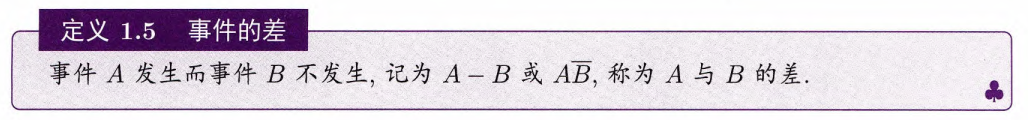


事件运算的公式
, ;
;
;
; 德摩根(A. De Morgan)对偶法则
;
.
证明两个事件
, 相同: ; .

1.3 概率的定义和性质
定义1.9 概率的直观定义
概率是事件的函数,也可以视为是集合的函数. 设
为一个事件,用 表示事件 发生的概率,则由概率定义,
;、
;
.

1.3.1 古典概型
在有限性和等可能性下定义概率的模型称为古典概型.

一般涉及排列、组合的知识,以及事件的运算. 常用的排列、组合知识归纳如下.
1. 计数原理
加法原理

乘法原理

结论:
从
从
种,称为选排列. 特别,当
从
从
这个数称为重复组合数
2. 盒子模型

结论:
球可辨,每个盒子中不限球的个数. 此为重复排列,不同的放法个数为
球可辨,每个盒子中至多放一个球,此为选排列,不同的放法个数为
球不可辨,每个盒中不限球的个数. 隔板法(
球不可辨,每个盒子中至多放一个球. 此为一般的组合,不同的放法个数为
3. 多组组合

4. 不尽相异元素的排列

1.3.2 概率的统计定义
几何概型:对古典概型去掉有限性、保留基本事件的等可能性.
几何概型相当于把样本空间视为一块质量为
的均匀木块,事件 视为木块中的某部分,则 就是该部分的质量.
(去掉等可能性,保留有限性,从另一个角度定义概率)
定义1.10 概率的统计定义
意义:
提供了一种估计概率的方法(如:得出
的近似值,破译密码); 提供了理论是否正确的标准(如:验证硬币均匀性).

1.3.3 主观概率的定义
人们常常用一个数字去估计某些概率的大小,而心目中并不把它与频率相连,这种概率称为主观概率.
定义1.11 主观概率定义
作用:
管理科学(经济投资决策);
数据分析,尤其是人工智能的算法(贝叶斯(T. Bayes)学派,与传统的统计学派即频率学派区别)

研究主观概率,以这种观点来处理统计问题,有着非常重要的现实意义.
1.3.4 概率的公理化定义
定义1.12 概率的公理化定义

由概率的公理化定义得到概率的一些性质. 以下讨论的事件均为同一样本空间
中的可测事件.
(有限可加性)若
两两不相容,则 (可减性)若
,则 ; (单调性)若
,则 ;
; (加法原理/容斥原理(inclusion-exclusion principle))对任意的事件
,有
例:
(次可加性)对任意的事件列
,有 *(下连续性) 若事件列满足
,则 *(上连续性) 若事件列满足
,则
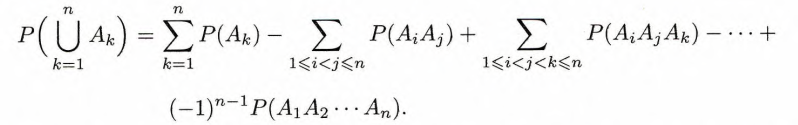
1.4 条件概率
1.4.1 条件概率的定义
条件概率,指在试验中在附加一定条件下,感兴趣事件发生的概率,其形式总可归结为“事件
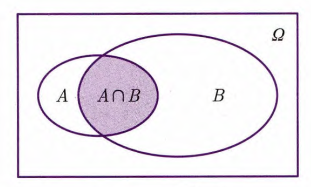
定义1.13 条件概率
某部分的概率就是该部分面积与总面积的比值,图中总面积(
的面积)为一个单位. 现在知道 发生了,只考虑 而不考虑 ,则 就是 在 中的面积 与 的面积 的比值,即

定理1.1 乘法公式
; 若
,则 (不依赖脚标顺序).
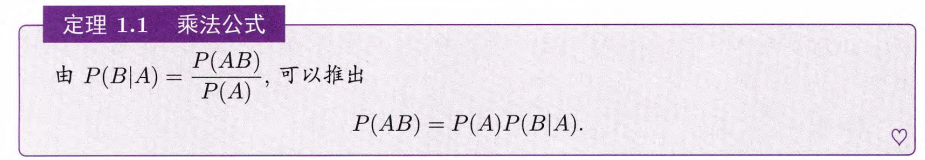

1.4.2 全概率公式
定义1.14 完备事件群
设
是样本空间 中的一组概率大于 的事件,满足
,
, 则称
是样本空间 的一个完备事件群(划分(partition)).

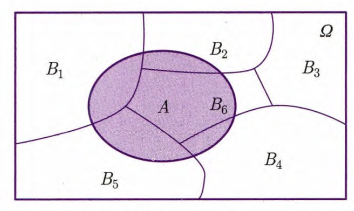
定理1.2 全概率公式(law of total probability)
设
是样本空间 的一个划分, 为 中任一事件,则

1.4.3 贝叶斯公式
定理1.3 贝叶斯公式
设
是样本空间 的一个划分, 为 中任一事件, ,则 特别,以
和 构成划分,则

如果把条件视为“原因”,事件
1.5 独立性
相互独立
定义1.15 两个事件相互独立
如果事件
和事件 的发生互不影响,那么两事件是独立的.

推论1.1
两个事件
, 相互独立,实质是一个事件发生的概率与另外一个事件是否发生没有关系,但这并不意味着事件 , 本身完全无关.

定理1.4
设
和 是样本空间 中的两个事件,则下述四个陈述相互等价:
与 独立;
与 相互独立;
与 相互独立;
与 相互独立.

定义1.16
个事件相互独立
个事件的相互独立蕴涵了其中任意一部分事件相互独立; 即使其中任意
个事件都相互独立,也不能保证 个事件在整体上相互独立. 定义1.17 等价定义


小概率原理:即使事件
是小概率事件,即事件 在一次试验中不易发生,但是随着实验次数 的增加,事件 发生的概率接近于 .
两两独立
定义1.18
个事件两两独立
相互独立的事件列一定是两两独立的,反之则未必.
定义1.19 独立事件列



第二章 随机变量及其分布

2.1 随机变量的概念
取一个样本空间到直线
直观上,随机变量是取值随实验结果而定且有一定概率分布的变量;
数学角度上的严格定义(定义2.1 随机变量):
通常我们用大写的英文字母
等表示随机变量,而用小写的字母 等表示实数.
随机变量取哪些值以及取这些值的概率,称为随机变量的分布(distribution).
2.2 离散型随机变量的分布
离散型随机变量,就是取值为离散值的随机变量.
定义2.2 离散型随机变量和分布律
如果随机变量
只取有限多个或可数多个值,那么称 为离散型随机变量. 设
取的一切可能值为 ,则 其中
式称为离散型随机变量 的分布律或概率质量函数(probability mass function, pmf).


2.2.1 0-1 分布
定义2.3
分布

服从 分布/伯努利(Bernoulli)分布/两点分布. 其分布函数也可以写为
一般在试验中仅考虑事件
是否发生时,引入示性函数 则
为 分布的随机变量.
2.2.2 离散均匀分布
定义2.4 离散均匀分布
古典概型就是离散均匀分布.

分布
称为参数为
的超几何分布(hypergeometric distribution).
服从参数为 的超几何分布记为 .

2.2.3 二项分布
设
如果把该试验在相同条件下独立重复
定义2.5 二项分布
若
的分布律为 那么称
服从二项分布(binomial distribution),记为 ,而 常记为 .

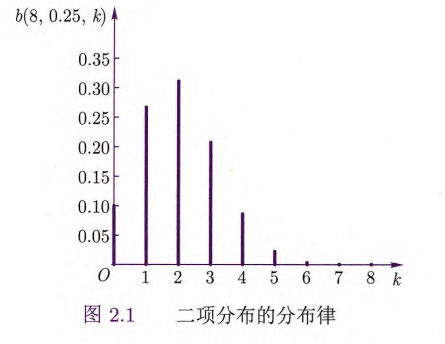
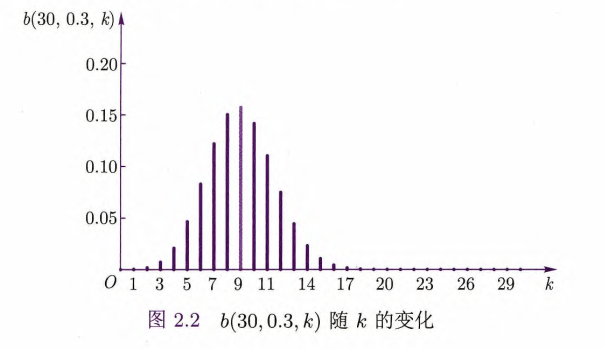
随机变量服从二项分布的条件:
各次试验的条件稳定(保证事件
发生的概率 在各次试验中保持不变); 各次试验之间相互独立.
2.2.4 负二项分布
如果将伯努利试验一直独立地重复下去,以
且
定义2.6 负二项分布
设随机变量
取正整数值,其分布律为 其中
为正整数, ,则称 服从参数为 的负二项分布或帕斯卡分布(Pascal distribution),记为 , 则记为 .

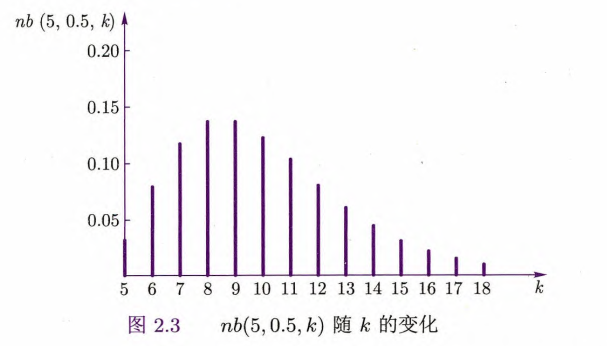
在负二项分布中,若
定理2.1 无记忆性
以所有正整数为取值集合的随机变量
服从几何分布 ,当且仅当的对任何正整数 和 ,都有 这个性质称为几何分布的无记忆性(memoryless property).

2.2.5 泊松分布

定义2.7 泊松分布
若随机变量
的分布律为 则称
服从参数为 的泊松分布(Poisson distribution),记为 .
泊松分布的一个重要应用是可以近似计算
定义2.2 泊松逼近定理
设一族随机变量
,若当 时, ,则 实际应用中,
, 时即可应用. 当 时, 情况下仍有较高的精度.

负二项分布也可以用泊松分布近似.
如果
其中
为正常数,那么 由负二项分布的分布律,令
及 为固定数,得到 即在负二项分布试验中,如果失败次数固定为
,那么第 次成功的概率在 时近似为服从泊松分布的变量取 的概率.
2.3 连续型随机变量的分布
2.3.1 随机变量的分布函数
定义2.8 分布函数
设
为随机变量, 为任一实数,称 为随机变量
的(累积)分布函数.
的值等于随机变量不超过 所取值的概率之和,故又称为累积分布函数(cumulative distribution function,简称 cdf).

根据分布函数的定义,可以看出
显然,分布函数的定义适用于一切类型的随机变量,当然包括离散型随机变量.
定理2.3
离散型随机变量的分布函数为阶梯函数,其不连续点为所有取值点,每个跳跃的高度即为取该点值的概率.

分布函数的性质
(非降性)
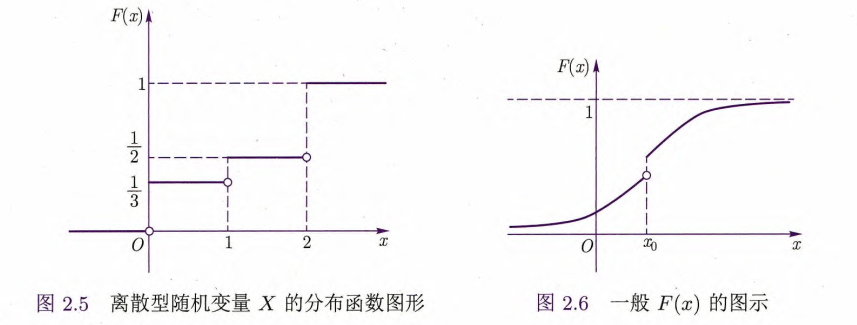
(规范性)对任意
(右连续性)
证明:
非降性:当
时, 规范性:记
,由于对任意 ,有 ,由概率的连续性知 类似可证
右连续性:

2.3.2 概率密度函数
定义2.9 连续型随机变量和概率密度函数
设随机变量
的分布函数为 ,若存在非负函数 ,使得 , 则称
为连续型随机变量, 称为分布函数的概率密度函数(probability density function,简称 pdf),记为 . 对连续型随机变量,其分布函数
一定是一个绝对连续函数(因而也是连续函数),因此连续型随机变量 也常称为是绝对连续随机变量.

概率密度函数的性质:设随机变量
特别,对任意(可测)集合
若
2.3.3 几种重要的连续型分布
1. 均匀分布
定义2.10 均匀分布
随机变量
在有限区间 内取值( ),且概率密度函数为 则称
服从区间 上的均匀分布(uniform distribution),记为 .

性质:均匀分布随机变量
区间
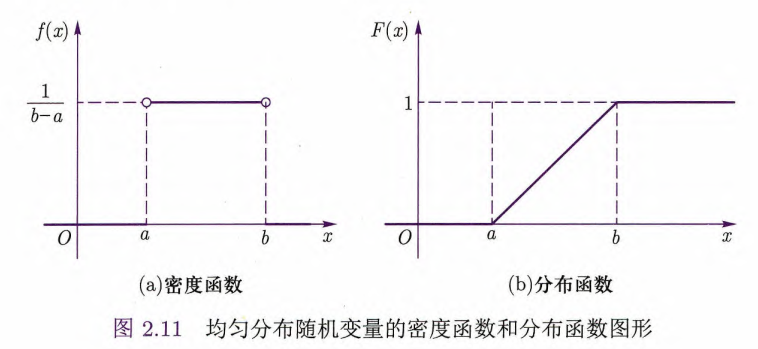
2. 指数分布
定义2.11 指数分布
若随机变量
的密度函数为 其中
为参数,则称 服从参数为 的指数分布(exponential distribution),记为 .

分布函数为
性质:设
这一性质称为无记忆性. 可以证明,一个非负连续型随机变量,如果具有该性质,那么其分布必为指数分布.
证明:注意到
,故

3. 正态分布
定义2.12 正态分布
随机变量
的密度函数为 其中
为参数,则称 服从参数为 的正态分布(normal distribution)或高斯分布(Gaussian Distribution),记为 .

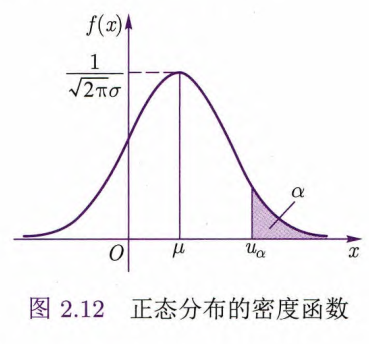
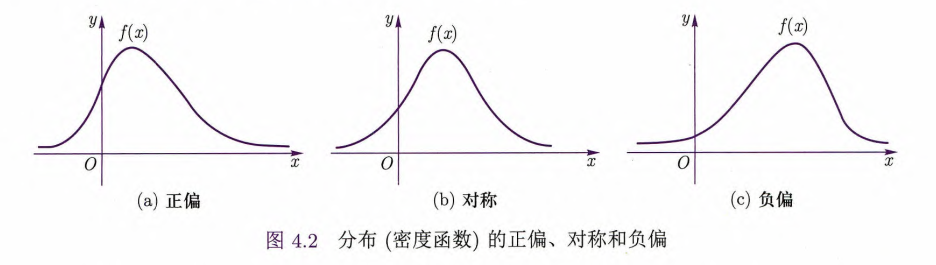
性质:
“钟形曲线”,两头小,中间大,关于
最大值在对称轴
固定
固定
这里
其对应的分布函数称为标准正态分布函数,记为
由图形对称性,易见
设
在实际处理数据中,可以把一个取值在整条直线上服从标准正态分布的随机变量近似为取值在
设
此时,有
2.4 随机变量函数的分布
设随机变量
2.4.1 离散型随机变量函数的分布
设随机变量
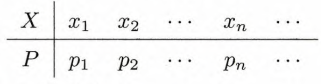
其中
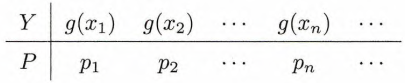
其中
特别地,如果
2.4.2 连续型随机变量函数的分布
命题2.1 随机变量函数的分布函数

显然,连续型随机变量的函数未必是连续型随机变量. 当变换
推论2.1 密度函数变换公式
若
是严格单调的且反函数可导,则随机变量 仍为连续型随机变量,且有概率密度函数 , 其中
为 的反函数, , .

设
特别,取
则
即
注:
逐段单调时的密度变换公式

第三章 多维随机变量及其分布

3.1 多维随机变量及其分布
3.1.1 多维随机变量
定义3.1 多维随机变量

定义3.2 二维分布函数
设
是二维随机变量, ,称二元函数 为
的分布函数或联合分布函数(joint cumulative distribution function, joint cdf).

二维随机变量的联合分布函数
定义3.3 二维离散型随机变量
设
的可能取值为 . 记 称其为二维离散型随机变量的联合概率质量函数(joint probability mass function, joint pmf)或联合分布律.

性质:

推广:
定义3.4
维离散型随机变量

性质:
例3.3 多项分布

3.1.2 连续型多维随机变量的联合密度函数
定义3.5 二维连续型随机变量
设
,若存在可积的非负函数 ,使得对于 ,有 则称
为二维连续型随机变量, 称为其联合分布函数,称 为其联合概率密度函数(joint probability density function, joint pdf),简称联合密度函数.

性质:
对任意的
若
由此知
设
例3.5 二元正态分布

例3.6 均匀分布

3.2 边缘(际)分布
定义3.6 边缘(际)分布
设
的联合分布函数为 ,则其分量 和 的分布函数 和 称为 或 的边缘(际)分布(marginal distribution).

3.2.1 二维离散型随机变量的边缘(际)分布


3.2.2 二维连续型随机变量的边缘分布
定义3.7 边缘概率密度函数
设二维连续型随机变量
,则
和 的概率密度函数 和 称为二维随机变量 或者联合概率密度函数 的边缘概率密度函数(marginal probability density function, marginal pdf),简称边缘密度函数.

3.3 条件分布
一个随机变量(或向量)的条件概率分布,就是在给定(或已知)某种条件(某种信息)下该随机变量(向量)的概率分布.
当
若
同理若
当
其中
定义3.8 条件概率密度函数
如果
的概率密度函数在 处的值 ,那么称 为给定
下随机变量 的条件概率密度函数(conditional probability density function, conditional pdf),简称条件密度函数. 同理,给定 下随机变量 的条件概率密度函数 为

给定
连续型随机变量密度函数形式的
乘法公式:
贝叶斯公式:
3.4 相互独立的随机变量
定义3.9 随机变量相互独立
设随机变量
的联合分布为 ,边缘分布为 . 若 ,都有 则称随机变量
相互独立.

等价定义:
若
若
上式等价于密度函数
其中
定义3.10 多维随机变量的相互独立性

3.5 随机向量函数的分布
设
特别当
若
特别当
若
对
特别地,当随机变量
例3.19 设随机变量
相互独立,分别具有概率密度函数 ,求 的概率密度函数. 在积分号下对
求导,得 这里
称为 和 的卷积(convolution). 令
, ,函数 对 的 Jacobi 行列式为 ,故
由密度函数的定义,
当
相互独立时, ,从而 这里不需要在积分号下求导.
例3.20(指数分布随机变量的和与差)设
和 独立,均服从指数分布 ,求 的概率密度函数. 由于
进一步,如果
为相互独立且服从相同的指数分布 ,那么 的概率密度函数为 该分布称为参数是
的 分布,记为 . (特别,
.) 如果相互独立的两个同类型随机变量之和仍服从同一类型的分布,那么称此分布类型具有再生性. 因此,
分布对参数 具有再生性. 类似地,
的概率密度函数为 该分布称为拉普拉斯分布(Laplace distribution). 即,独立指数分布的差是拉普拉斯分布.
例3.22(正态分布随机变量的和)设
和 互相独立,分别服从 和 ,求 的分布. 由于
即
,即正态分布 对参数 具有再生性.
例3.23(独立随机变量商的分布)设
和 相互独立, , ,求 的分布. 令
,则当 时,函数 对 的 Jacobi 行列式的绝对值为 所以
由此得
由密度函数的定义知,
例如,设
和 是独立的随机变量,均服从 , ,则 该分布称为柯西分布(Cauchy distribution),即独立正态分布随机变量的商服从柯西分布.
例3.26(最大值和最小值的分布)设
和 相互独立, ,求 和 的分布. 首先注意
和 均为随机变量. 由于 和 相互独立, 如果
,那么
第四章 随机变量的数字特征和极限定理

4.1 数学期望和中位数
前面讨论的随机变量的概率分布是对随机变量概率特性的最完整和全面的刻画,而本章要讨论的数字特征是对随机变量(或它的分布)某一方面特性的刻画.
4.1.1 数学期望
数学上,离散型随机变量的数学期望的定义为取值的“加权平均”:
定义4.1 离散型随机变量的期望
设随机变量
为离散型随机变量,其分布律为 . 如果 那么称
为随机变量
的数学期望,简称期望(expectation).

注:
如果随机变量
绝对收敛条件
对连续型随机变量,加权平均等价为加权积分:
定义4.2 连续型随机变量的期望
设
,如果 (常表示为
),那么称 为连续型随机变量的数学期望,简称期望. 否则,称不存在数学期望. 这里绝对可积条件
是保证期望有确定的值,即存在,的条件.
注:如果随机变量
例4.4 设
,则 .
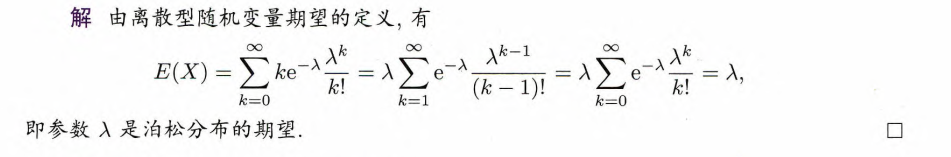
例4.5 设
,则 .
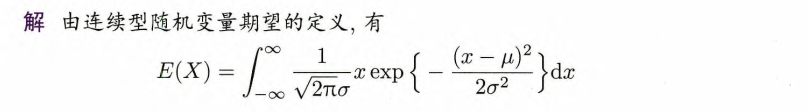
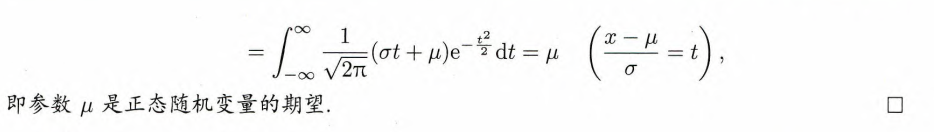
例4.6 设
,其中 称为柯西分布. 证明:柯西分布的期望不存在.
数学期望的性质:
容易看出,常数
(期望的线性性)若干个随机变量和的期望等于每个随机变量期望的和. 即,若
且期望的线性性质不需要对随机变量之间的关联附加任何限制,具有很好的普适性.

若
若
设
随机向量
这一性质在应用中非常方便. 利用该性质,可以在
若
例4.7 设
,求 .

例4.9(负二项分布的期望)设随机变量
服从参数为 的负二项分布,求 的期望.

例4.10 设
,求 .
4.1.2 条件数学期望(条件期望)
与条件分布的定义类似,随机变量的条件期望就是在给定某种附加条件下的数学期望. 对统计学和随机过程来说,最重要的情况就是在随机向量
对离散型随机变量
这个条件分布中包含了
对连续型随机变量
定义4.3 连续型随机变量的条件期望
设
,称 为给定
时随机变量 的条件期望.
在统计学上,常把条件期望
如果不固定
这称为条件期望的平滑公式或全期望公式.
4.1.3 中位数和众数
定义4.4 中位数
设随机变量
,若存在常数 满足 其中
,则常数 称为随机变量 的中位数(median).
中位数可能不唯一. 记连续型随机变量
定义4.5 众数
若
为离散型随机变量,则其概率质量函数最大值对应的随机变量的取值称为众数(mode),记为 ; 若
为连续型随机变量, ,则使 达到最大值的 称为众数,记为 .
众数可能不唯一. 若
数学期望、中位数和众数称为随机变量的位置参数,它们刻画了随机变量的数学期望、一半概率值和密度函数最大值的位置.
中位数的定义是如下
定义4.6
分位数 设
,称 是随机变量 的 分位数,是指
称分位数
4.2 方差和矩
4.2.1 方差和标准差
定义4.7 方差和标准差
设随机变量
是平方可积的,即满足 ,则 分别称为随机变量
的方差(variance)和标准差(standard deviation). 也可以称为随机变量分布的方差和标准差.
方差的性质:
由期望的线性性质,
同时可得
设
独立随机变量和的方差等于随机变量方差的和,即若
当
特别,有
当
例4.18
设
. 记 则
这称为随机变量
的标准化,它的特点是没有量纲.
定理4.1 马尔可夫不等式
若随机变量
,则 ,有
设
4.2.2 矩
定义4.8 矩
设
为随机变量,满足 , 为正整数,则 称为 关于 的 阶矩(moment),其中 为常数. 称
为随机变量 的 阶原点矩,称 为 的 阶中心矩.
由定义知,
在计算与正态分布有关的矩的时候,可以用
应用:
用
设
则
特别,对正态分布,
称
为随机变量
用
易见,若
称
为随机变量
特别,若
定义4.9 矩母函数
随机变量
的矩母函数或者矩生成函数(moment generating function, MGF) 定义为 如果存在正常数
,使得 对所有 是有限的,那么称 的矩母函数 存在.
根据
我们有
只要我们有
例4.24 设
,求 . 令
,则
矩母函数
定理4.2
假设存在正常数
使得随机变量 和 的矩母函数对所有 均有限且相等,则它们的分布相同. 即,
如果
4.2.3 协方差和相关系数
设
即
定义4.10 协方差
设随机变量
和 均平方可积,即 ,则称 为随机变量
的协方差(covariance).
性质:
对任意实数
即协方差是双线性函数. 特别,
若
(随机变量场合的柯西-施瓦茨(Cauchy-Schwarz)不等式)
定义4.11 相关系数
设随机变量
和 均平方可积,即 ,则称 为随机变量
的相关系数(correlation coefficient). 如果不混淆的话,就简记为 .
当
当
当
例4.27 设
,则 .
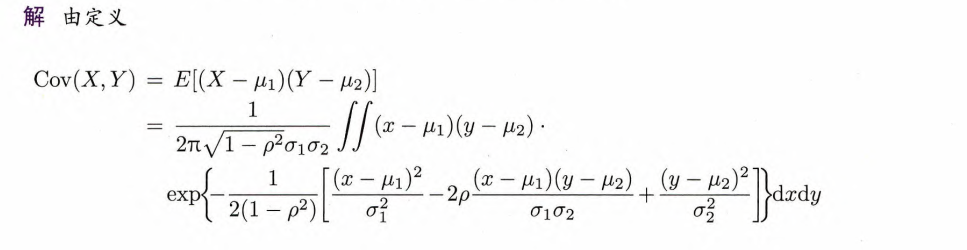

命题4.1 正态分布随机变量的独立与不相关
若
相互独立,则 ,反之不必成立. 但若 ,则 相互独立 .
定理4.3
对任何非退化的随机变量
存在方差,如下四个命题相互等价:
与 不相关;
;
;
.
4.3 熵的基本概念
熵是随机变量最重要的数字特征之一,度量了随机变量中所含有的信息量的大小. 换言之,熵体现的是随机变量的不确定性程度,熵越大,不确定性就越大.
定义4.12 熵
设
为离散型随机变量,分布律为 则其熵(entropy)定义为
如果
为连续型随机变量,概率密度函数为 ,那么其熵定义为 在离散型随机变量的熵的定义中,除使用以
为底的对数外,也常使用以 或 为底的对数.
离散型随机变量
如果取有限个值的随机变量
当且仅当
4.4 大数定律和中心极限定理
在概率论中习惯于把随机变量和的分布收敛于正态分布的那一类定理称为中心极限定理(central limit theorem, CLT). 大数定律(law of large numbers, LLN)则是“频率趋于概率”的引申.
定义4.13 依概率收敛
设
是一随机变量序列, 为随机变量,如果 ,有 那么称随机变量序列
依概率收敛(converge in probability)于随机变量 ,记为 或 .
定理4.4 (弱)大数定律
设
是一 i.i.d. 随机变量序列,记它们相同的期望和方差分别为 和 . 记 ,则对 , 也就是说
用切比雪夫不等式立得.
大数定律就是说 i.i.d. 随机变量序列的前
我们可以不知道数据来自什么总体分布,也不知道总体期望是多少,但是我们常常用样本均值来近似总体均值,其理论依据就是大数定律.
例4.35(伯努利大数定律)
设
为独立的 分布随机变量序列, 那么有
. 所以由大数定律, ,我们有 即有
在大数定律的条件下,理论上我们还可以得到更强的结论,即随机变量序列的前
定义4.14 依分布收敛
设
为一列实值随机变量, 为随机变量, 和 分别为随机变量 和 的分布函数. 如果对 的所有连续点 有 那么称
弱收敛(converge weakly)于 ,也称 依分布收敛(converge in distribution)于 ,常记为 或 .
定理4.5 依概率收敛与依分布收敛的关系
设
为一列实值随机变量, 为另一随机变量.
若
,则 ; 若
,则 ,其中 为一个常数.
依分布收敛的一个重要应用场合是关于独立随机变量部分和的分布收敛性,称为中心极限定理,在数理统计的大样本理论中有重要的应用.
定理4.6 林德伯格-莱维中心极限定理
设
是一列 i.i.d. 随机变量序列,记它们相同的期望和方差分别为 . 记 ,则 有 也常常表示为
其中
.
中心极限定理就是说,部分和
对一列独立同分布的伯努利分布(
定理4.7 棣莫弗-拉普拉斯中心极限定理
设
是一列 i.i.d. 随机变量序列, 且 ,则 ,有
注意到
当
当
一般而言,当
中心极限定理也指出了大数定律中
一个稍稍弱一点的是不要求
第五章 统计学基本概念

5.1 统计学发展简史
统计学(statistics),统计学家(statistician).
5.2 基本概念
定义5.1

5.2.1 总体
定义5.2 统计总体
研究对象某个指标取值的全体以及取这些值的概率分布,称为统计总体,简称总体(population).
5.2.2 样本
定义5.3 样本
从总体中按一定的方式抽取的
个个体 ,称为是样本量(sample size)为 的一个样本(sample).
最常用的一种抽样方法叫做“简单随机抽样”,它要求满足下列两条:
代表性. 总体中的每一个体都有同等机会被抽入样本,样本中每个个体与所考察的总体具有相同分布. 因此,任一样本中的个体都具有代表性.
独立性. 样本中每一个体取什么值并不影响其他个体取什么值. 这意味着,样本中各个体
由简单随机抽样获得的样本
性质:设
由简单随机抽样的定义,有放回抽样得到的样本是简单随机样本.
设总体为
若
注:
一般而言,抽样方案实施之前,由于不能确定抽到哪个个体,确定不了样本指标的具体取值,所以样本视为随机向量,用大写的英文字母
5.2.3 统计量
定义5.4 统计量
完全由样本
决定的量称为统计量(statistic).
注:由定义,统计量是样本的函数.
”完全“是指统计量中不能有其他未知参数,例如当
由于样本有二重性,统计量也有二重性,既可以视为随机变量也可以视为具体数值.
统计量不是认为随意造出来的,它们是为了解决种种统计推断问题而产生的.
设
样本均值(sample mean)
它反映了总体均值的信息.
样本方差(sample variance)
它反映总体方差的信息.
样本矩(sample moment)
称为样本
称为样本
当样本为简单随机样本时,由大数定律知
样本偏度系数(sample skewness coefficient)
它反映了总体偏度的信息.
样本峰度系数(sample kurtosis coefficient)
它反映了总体峰度的信息.
样本相关系数(sample coefficient of correlation)
设
为样本相关系数,也称为皮尔逊相关系数. 它反映总体相关系数的信息.
次序统计量(order statistics)及其有关统计量
把样本按大小排列为
则称
样本中位数(sample median)
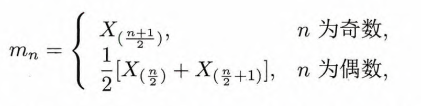
它反映总体中位数的信息. 当总体分布关于某点对称时,对称中心既是总体中位数又是总体均值,故此时
极值
称为极差(range).
样本
其中
常见样本分位数包括样本四分位数
经验分布函数(empirical distribution function)
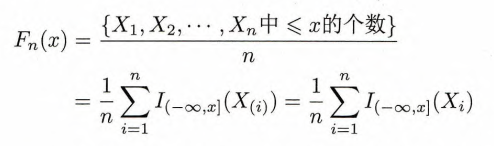
称为样本
5.3 抽样分布
定义5.5 抽样分布
设
为一个样本,统计量 的分布称为抽样分布(sampling distribution).
1.
定义5.6
分布 设样本
为来自标准正态总体的一个简单随机样本,称 服从自由度为
的 分布,记为 .
其概率密度函数为
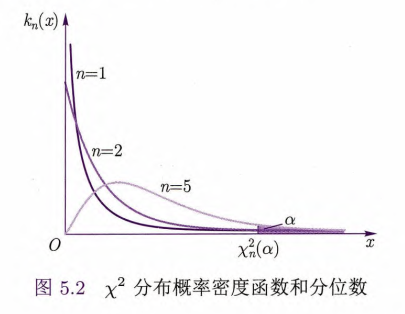
当自由度
性质:
若
若
注:若
则自由度为
另一方面,若
2.
定义5.7
分布 设
,且 相互独立,称 服从自由度为
的 分布,记为 .
其概率密度函数为
性质:
当
若
当
3.
定义5.8
分布 设
,且 相互独立,称 服从自由度为
的 分布,记为 .
注意其自由度
性质:
若
若
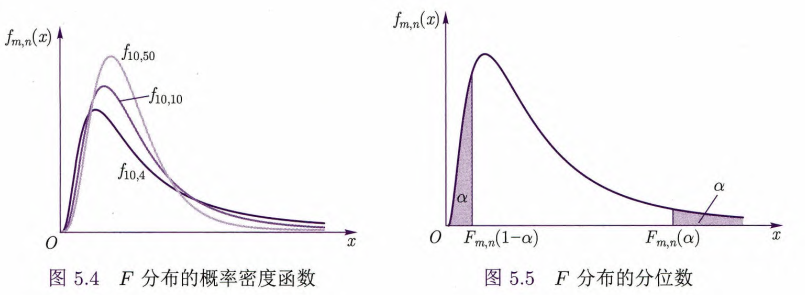
定理5.1
设随机变量
, 是不全为零的常数,则有
独立的正态随机变量线性组合服从正态分布,即
特别,当
,即 为样本均值时,有
为样本方差,则
和 相互独立; 进而,
推论5.1

推论5.2

推论5.3
设
服从指数分布 则有
第六章 参数点估计

6.1 参数点估计的概念
参数估计问题的一般提法是,在有了从总体中抽取的样本
点估计常用的构造方法有矩估计(moment estimate)和最大似然估计(maximum likelihood estimate, MLE).
6.2 矩估计法
总体分布的
由大数定律,样本矩依概率收敛到总体矩,所以可以用样本矩来近似总体矩,即
取
在应用中,一般我们用样本方差
注:
在合理的优劣准则下,可以证明低阶矩优于高阶矩,所以在矩估计中,能用低阶矩的就尽量用低阶矩来估计参数. 另外,矩估计方法需要总体相应的矩存在,对一些不存在矩的问题(如柯西分布)就不适用了.
6.3 最大似然估计
定义6.1 似然函数
设样本
有联合概率密度函数或联合概率质量函数 这里参数
为样本 的一个样本值. 当固定 时把 看成为 的函数,称为似然函数(likelihood function),常记为 或 .
用似然程度最大的那个点
的
若似然函数是严格单调的,则似然函数的最大值在边界处达到,从而得到最大似然估计;若似然函数是光滑的,且样本是简单随机样本,则似然函数是
若该方程组在
注:似然函数的最大值点可能会在边界上达到,所以要和边界值作比较. 当似然函数不可导时,要用定义来求出最大似然估计.
6.4 优良性准则
优劣性的比较问题要从整体性能考虑. 所谓“整体性能”有两个含义,一是指估计量的某个特性,具有这个特性就是优良的,下文的“无偏性”就属于此类;其二是指估计量的某种具体的数量指标,两个估计量中指标小的为优,如下文的“均方误差”.
6.4.1 点估计的无偏性
设总体分布函数为
定义6.2 偏差与无偏性
设
是 的一个估计量,称 为估计量
的偏差. 若对任一可能的 ,都有 则称
是 的一个无偏估计量.
6.4.2 最小方差无偏估计
均方误差(误差平方的平均)
兼顾了偏差和波动.
平均绝对误差
也可作为标准,但不如均方误差在计算上易于处理.
注意均方误差
由两部分组成,第一部分是波动,第二部分是偏差. 对于无偏估计,第二部分为
定义6.3 有效性
设
都是总体参数 的无偏估计,方差存在,若 且至少存在一个
使上式不等号成立,则称 比 更有效.
定义6.4 最小方差无偏估计
设
是 的一个无偏估计,若对 的任一无偏估计 ,都有 则称
是 的一个最小方差无偏估计(minimum variance unbiased estimate, MVUE).
6.4.3 克拉默-拉奥方差下界
6.5 点估计量的大样本理论
当样本量
定义6.5 相合性
设
是参数 的一个点估计,若当样本量 时有 则称
是 的一个(弱)相合估计量(consistent estimator).
相合性是对一个估计量的基本要求. 若一个估计量没有相合性,则无论样本量多大,我们也不能把未知参数估计到任意精度. 这种估计量显然是不可取的.
可以证明,矩估计是总体矩的相合估计. 一般而言,最大似然估计也是代估参数的相合估计.
另一个重要的准则是其分布极限的特点,称为渐进正态性.
定义6.6 渐进正态性
设
是参数 的一个点估计,设它的方差存在,记 若当样本量
时有 则称估计量
有渐进正态性.
渐进正态性提供了估计量
在一般条件下,矩估计和最大似然估计都有渐进正态性.
第七章 区间估计

7.1 基本概念
定义7.1 置信区间和置信系数
设
是从总体中抽取的一个简单随机样本, 为未知参数, 为两个统计量. 给定一个小的正数 ,若 则称区间
为参数 的置信区间(confidence interval)估计,置信系数为 .
7.2 枢轴变量法
基本概念和对正态总体均值的区间估计
例如对正态总体
而正态密度函数有对称性,所以一个合理的置信区间应该有形式
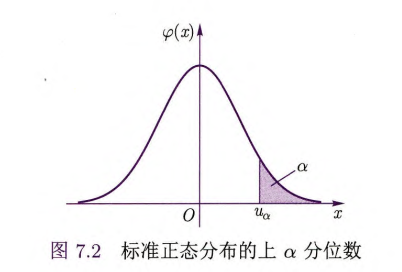
从附表 1 中可以查出
即误差界限
所以
一种找区间估计的一般方法,即枢轴变量法如下:
设感兴趣的参数为
(1) 找一个
(2) 构造一个函数
(3) 枢轴变量必须满足如下条件:
(4) 取分布
根据 (3),不等式
例7.2 设
是从正态总体 中抽取的一个样本,参数 未知,求 的置信系数为 的置信区间.
根据枢轴变量法,
是 的 MVUE,由于 未知,所以 不是枢轴变量. 直观上,
未知时用样本方差 代替,但是 不是正态分布,而是
分布(why?).
分布与参数无关,完全已知,所以 是枢轴变量. 设 的上 分位数为 ,注意到 分布概率密度函数是对称的,容易得到 的置信系数为 的置信区间为
在给定置信系数下,标准差越大,精度越低;样本量越大,精度越高. 同时也看出,
总结:正态总体均值
对正态总体方差的区间估计
例7.5 考虑均值方差都未知时正态总体方差
的置信区间估计.
方差
的优良点估计为样本方差 . 枢轴变量为 它服从自由度为
的 分布. 所以方差
的置信系数为 的置信区间为 枢轴变量服从
分布,其概率密度函数不是对称的. 为了应用上方便,对这种情形习惯上仍然采用类似于对称分布的做法,即两边各取 概率.
对两个正态总体均值差的区间估计
例7.6 设有两个独立正态总体,分别服从
和 ,其中 都已知. 求均值差 的置信系数为 的置信区间. 如果 都未知时如何给出置信区间? 设
生产线的平均产量为 , 生产线的平均产量为 ,则 由于两者独立,
枢轴变量及其分布为
从而均值差
的置信系数为 的置信区间为 方差未知时,若
,则可以用中心极限定理得到;当样本量较小时,需要加一个条件 此时可以用两个样本方差
和 分别估计 . 由上知
可以估计 ,从而 可以估计
. 因为 分布有可加性,所以 可以验证
可以得到
的置信系数为 的置信区间为
对两个正态总体方差比的区间估计
设总体
设
即上式为方差比
7.3 大样本方法
构造置信区间的关键是要知道枢轴变量的分布. 大样本方法就是利用极限定理,特别是中心极限定理,来建立枢轴变量
7.3.1 比例
设事件
所以
可以作为构造
解得
其中
称此置信区间为得分区间(score interval).
注:由于构造的置信区间是基于枢轴变量的极限分布,其近似程度既依赖于
区间是
在实际中还经常使用一个更简单的公式:当
这是以
如果要求得分区间的宽度为
得到样本量应满足
其中
即当瓦尔德置信区间宽度为
这两个确定样本量的方法都包含了
若试验者基于其他试验可以给出一个先验估计
另外一种常见做法是保守法,即注意到这两个式子右边都是在
7.3.2 一般总体均值
设
若
其可以作为
由于用了中心极限定理,它的置信系数只是近似为
7.4 自助法置信区间
自助法(bootstrap method).
7.5 置信限
在实际问题中,有时候我们只对参数
若要求找出这样的一个统计量
若要求找出这样的一个统计量
定义7.4
设
是从总体 中抽取的一个简单随机样本, 为两个统计量.
若对
的一切可取的值,有 则称
为 的一个置信系数为 的置信上限; 若对
的一切可取的值,有 则称
为 的一个置信系数为 的置信下限.
置信上限和置信下限无非是一种特殊的置信区间,其一段为
正态总体均值:置信下限、置信上限分别为
正态总体方差:置信下限、置信上限分别为
对非正态总体,在样本量较大时候可以使用大样本方法寻求置信限.
第八章 假设检验

8.1 问题的提法和基本概念
8.1.1 例子和问题提法
对统计总体(即总体分布)的性质所作的假设称为统计假设. 使用样本对所作出的统计假设进行检查的方法和过程称为假设检验(hypothesis test). 如果总体分布的类型是已知的,要检验的假设是有关总体参数的某个取值范围,就称为参数假设检验问题;如果总体分布类型完全未知,就不再是参数问题了,我们称之为非参数假设检验问题.
8.1.2 假设检验中的几个基本概念
1. 原假设和备择假设
在统计学中,我们把关于总体分布的某个特征的假设命题称为一个“假设”或“统计假设”,例如假设总体分布为正态分布等,或者假设二项分布总体中成功概率
一般我们把认为是正确的命题称为原假设(null hypothesis),记为
一般地,记
其中
2. 简单假设和复杂假设
不论是原假设还是备择假设,其中的假设只有一个参数值,就称为简单假设,否则称为复合假设.
例如,
,其中参数 只能取一个值,所以是简单假设;而 中,参数 可以取不止一个值,所以是复合假设.
记感兴趣的参数为
其中
3. 检验统计量、接受域、拒绝域和临界值
在检验一个假设时用到的统计量称为检验统计量.
使原假设得到接受的样本所在区域
上述检验中,常数
来表示,称
8.1.3 功效函数
对于同一个原假设,可以有不同的检验方法,哪一种更好一点?这就有一个标准问题.
定义8.1 功效函数
设总体为
,其中 为参数, 是关于参数 的一个原假设,设 是根据样本 对假设 所作的一个检验,则称
为检验
的功效函数(power function).
功效函数是假设检验中最重要的概念之一. 若真实的参数
定义8.2 检验水平
设
是假设 的一个检验,
为其功效函数, 为常数, . 若 则称
为 的一个水平 的检验,或者说,检验 的水平为 (或检验 有水平 ).
显然,检验的水平是检验
8.1.4 两类错误
由于我们是根据样本作检验的,而样本有随机性,所以检验
根据接受域
对给定的样本,在选择检验
注:所谓显著性检验是指原假设在水平
显著性检验方法的一般步骤如下:
求出未知参数
以
以检验统计量
当原假设成立时,犯第一类错误的概率小于或等于给定的显著性水平
若给出样本值,则可算出检验统计量的值. 若落在拒绝域中,则可拒绝原假设,否则不能拒绝原假设.
根据具体问题和给定的显著性水平
例8.3
解 记
为均值,根据题设需要考虑的假设为 因为
为 的无偏估计,其应靠近 的值,因此基于统计量 ,我们采用标准化过的检验统计量 当
成立时, 的值倾向于小,因此检验的拒绝域取形如 ,其中 为待定常数. 下面我们用控制犯第一类错误的概率等于 来确定 ,即 由于
成立时 服从标准正态分布,易知上面关于 的方程的解为 ,其中 表示标准正态分布的上 分位数,即检验的拒绝域为 . 现在取显著性水平为
,则临界值 . 另一方面,样本均值 ,样本量 ,故检验统计量 的观测值等于 ,小于临界值 ,即样本落在拒绝域中,从而可以在显著性水平 下拒绝原假设,认为饮料的平均容量确实减小为 .

8.2 正态总体参数检验
8.2.1 单个正态总体均值的检验
关于单个正态总体均值
其中
设
1.
假设检验问题 1
若备择假设成立,则
由于
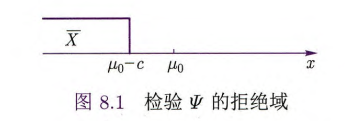
要确定常数
当
由于
从而得到
一个好的检验应该在控制犯第一类错误的情况下犯第二类错误的概率越小越好,在这里就是当
如果一个检验在控制犯第一类错误不超过
由于
由于
得
不难得出
即样本量要达到一定的要求.
假设检验问题 2
一个基于
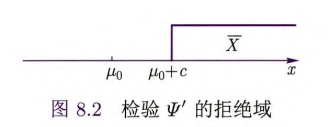
此检验的水平为
假设检验问题 3
直观上一个合理的检验为
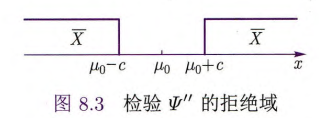
要确定常数
上述检验中确定临界值均使用标准正态分布,因此称它们为(一样本)
例8.4
解 这是正态总体在方差已知时关于均值
的假设检验问题, 取检验统计量为
检验的拒绝域为
. 由样本算得检验统计量的值为 ,如显著性水平为 ,则临界值为 ,不能拒绝原假设;如果显著性水平为 时,临界值为 ,此时可以拒绝原假设,认为铁钉平均长度不等于 . 这个例子说明结论可能跟显著性水平的选择有关:显著性水平越小,原假设被保护得越好,从而更不容易被拒绝.

2.
注意到样本方差
注意到在正态总体下,当
对检验问题 1,
检验为
其功效函数
是
对检验问题 2,
检验为
对检验问题 3,
检验为
这三类检验称为一样本
例8.5(例8.4续)设方差未知,则在显著性水平
和 下能否认为铁钉平均长度为 ? 解 这是正态总体在方差未知时关于均值
的假设检验问题, 取检验统计量
检验的拒绝域为
. 由样本算得检验统计量的值为
,与显著性水平 对应临界值 比较,不能拒绝原假设;而与显著性水平 对应临界值 比较,可以拒绝原假设. 即在显著性水平 下不能拒绝铁钉平均长度为 的假定,而在显著性水平 下可以认为铁钉平均长度不等于 .
当样本量
显著性检验方法仅控制犯第一类错误的概率. 由于设定的犯第一类错误的概率上限
根据以上分析,我们给出设立原假设和备择假设的两条原则:
把已有的经过考验的结论或事实作为原假设
把你希望得到的结论放在备择假设
8.2.2 两个正态总体均值差的检验
1. 成组比较
设
从统计学的角度看,就是如下的检验问题:设
在应用中常见的情况是
在
如果
其中
注意在
这三个检验统称为两样本