Authors: Shiming Wang, Zhenhua Ling, Ruibo Fu, Jiangyan Yi, Jianhua Tao
Email: wsmzzz@mail.ustc.edu.cn, zhling@ustc.edu.cn, {ruibo.fu, jiangyan.yi,jhtao}@nlpr.ia.ac.cn
Code: We will release our code later... ( Before 2021/7/1 )
Abstract: Aiming at efficiently predicting acoustic features with high naturalness and robustness, this paper proposes PATNet, a neural acoustic model for speech synthesis using phoneme-level autoregression. PATNet accepts phoneme sequences as input and is built based on Transformer structure. PATNet adopts a duration model instead of attention mechanism for sequence alignment. The decoder of PATNet predicts multi-frame spectra within one phoneme in parallel given the predicted spectra of previous phonemes. Such phonemelevel autoregression enables PATNet to achieve higher inference efficiency than the models with frame-level autoregression, such as Transformer-TTS, and improves the robustness of acoustic feature prediction by utilizing phoneme boundaries explicitly. Experimental results show that the speech synthesized by PATNet obtained lower character error rate (CER) than Tacotron, Transfomer-TTS and FastSpeech when evaluated by a speech recognition engine. Besides, PATNet achieved 10 times faster inference speed than Transformer- TTS and significantly better naturalness than FastSpeech.
Comparison among PATNet and other TTS models
Chinese demo
| PATNet | FastSpeech2 | Tacotron | Transformer-TTS | Ground Truth | |
|---|---|---|---|---|---|
| 1: 至于当初报考南科大,他也只是想逃避高考,随便考着玩玩。 | |||||
| 2: 不好判断具体时间。 | |||||
| 3: 什么时候给我换个彩屏手机? | |||||
| 4: 一个人哭坐在阴暗的角落里,揪着大腿问自己怎么办? | |||||
| 5: 他穿上潜水衣,身上栓了根绳子,一狠心跳了下去。 | |||||
English demo
| PATNet | FastSpeech2 | Tacotron | Transformer-TTS | Ground Truth | |
|---|---|---|---|---|---|
| 1: General Supervision of the Secret Service. | |||||
| 2: Have made it difficult for the Treasury to maintain close and continuing supervision. | |||||
| 3: Daily supervision of the operations of the Secret Service within the Department of the Treasury should be improved. | |||||
| 4: The Chief of the Service now reports to the Secretary of the Treasury. | |||||
| 5: The incumbent has no technical qualifications in the area of Presidential protection. | |||||
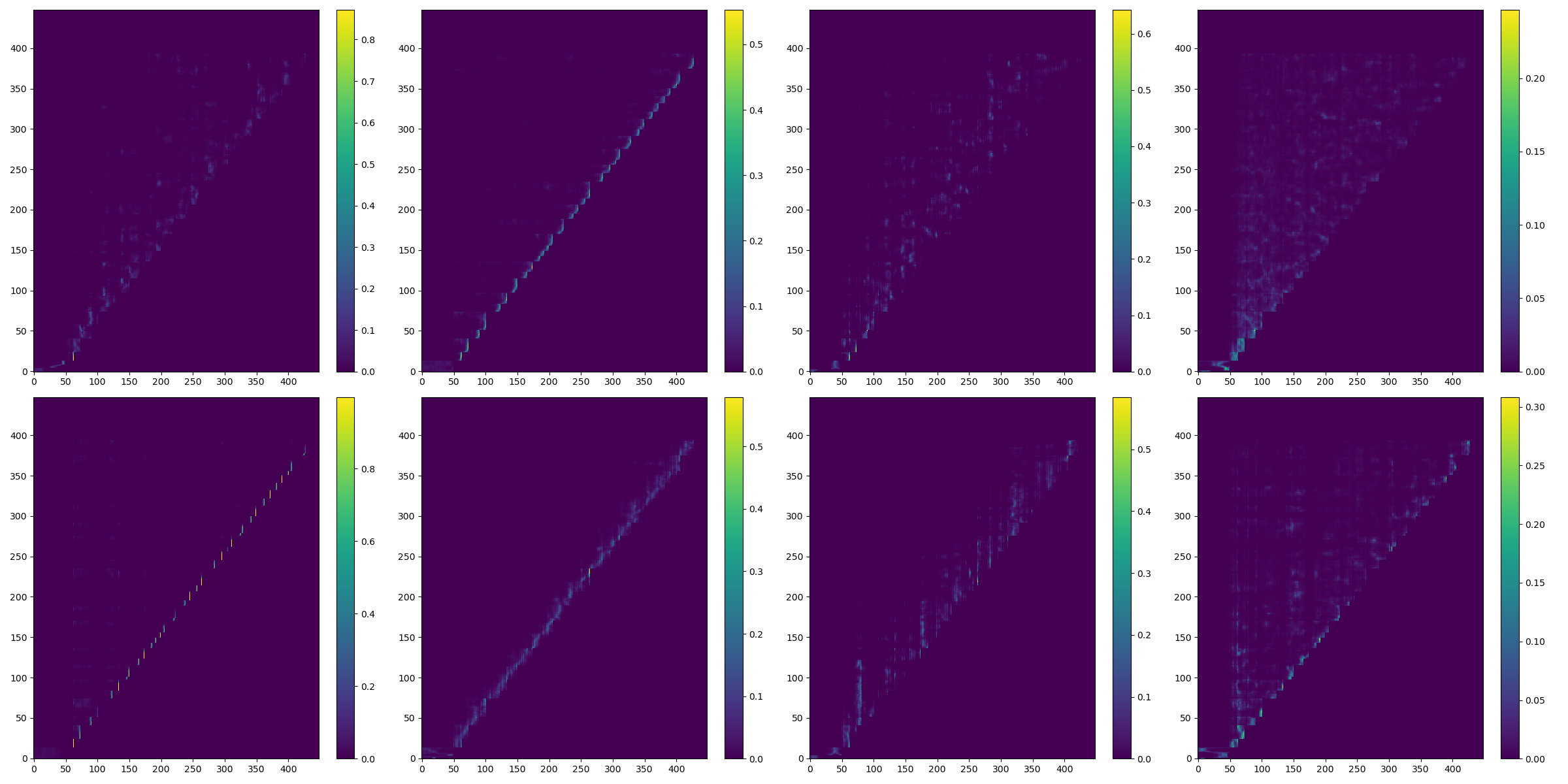
Pre-transformer Block
Pre-Transformer block is utilized to align the melspectrograms after padding a feature buffer (50 frames) at the beginning. The structure of the pre-Transformer block is the same as the Transformer blocks in the decoder. The only differences are that the pre-Transformer block removes the residual connection of the multi-head attention layer considering the purpose of shifting input sequences here and using different causal attention masks at training stage. The multi-head attention is demonstrated in figure below. (The main energy of alignment is expected to deviate 50 frames from the main diagonal)