SoundNet : Learning Sound Representations from Unlabeled Video
wangjiawei@mail.ustc.edu.cn
SoundNet : Learning Sound Representations from Unlabeled Video写在前面SoundNet : IntroductionSoundNet : FrameworkSoundNet : Student-TeacherSoundNet :End
写在前面
经过一段时间的休整,又要开启新的征途了。这篇论文是我阅读的Cross Modal Knowledge Distillation相关的第一篇论文,主要的方法和思想会在下面几部分介绍。接下来我将阅读整理出来的近几年的Cross Modal Knowledge Distillation相关论文,主要是阅读intro和method,实验部分碰到感兴趣的我会去仔细看一下或者动手实践一下。在阅读过程中如果碰到有意思的引用文献,可能也会阅读。这个小天地就是我的私人领域了,如果有幸被路过的你们阅读,那我将非常开心,也非常欢迎和我联系交流🤭
SoundNet : Introduction
尽管object recognition, speech recognition, machine translation等任务由于大规模有标签的数据集的出现已经发生了革命性的变化,但是在natural sound understanding的任务上没有相应的进步。部分原因是没有这么多有标签的数据集。这篇论文使用了大规模无标签video,根据sound和video的同步性,把visual knowledge迁移到sound。同时,文章中提出一种student-teacher training procedure,用来将训练好的模型知识迁移到新的模型中,使得新的模型具有原来训练好的模型的性能或者能力。
SoundNet : Framework
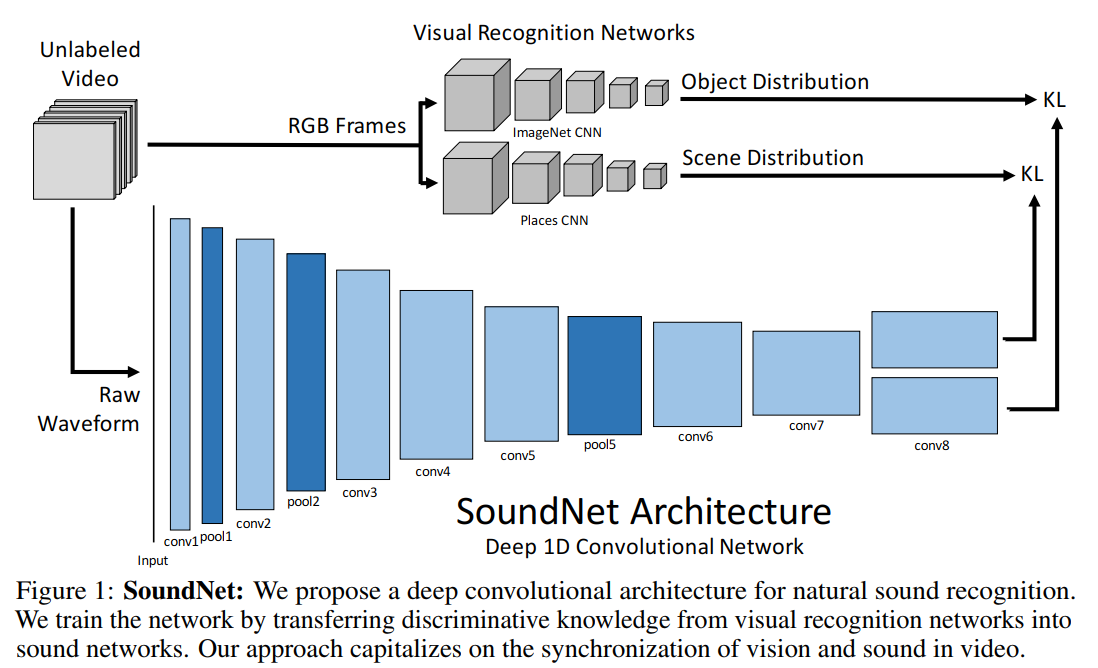
由上图可以看到整体的框架,输入是无标签video,包含视频和音频,对于每一帧,通过训练好的ImageNet CNN, Places CNN进行Object Distribution和Scene Distribution,利用得到的最后一层特征或者logits用作sound部分的target;而在sound部分,输入没有用人工制作的语音特征(MFCCs, Spectrogram ),而是直接用Raw Waveform,输入到1D CNN后经过一系列conv和pooling,得到两个输出,用于与video部分的输出进行metrics learning,使用KL-divergence作为度量函数 。Loss Function如下
其实这里有一个问题是如何处理变长输入输出。因为每个audio的长度不定,因此文章使用全卷积网络,可以看到框架中sound部分没有全连接层。由于卷积层与位置不可变,我们可以根据输入的长度对每个层进行卷积。因此,在我们的体系结构中,我们只使用卷积层和池层。由于表示形式适应输入长度,因此我们必须设计输出层以处理可变长度输入。虽然本可以使用全局池策略对固定维度矢量的可变长度输入进行低采样,但此类策略可能会不必要地丢弃对高级表示有用的信息。由于我们最终的目标是使用视频(长度也是可变长度)来训练此网络,因此我们转而使用卷积输出层在视频中的多个时间步长中生成输出。此策略类似于图像中的空间损失[Fully convolutional networks for semantic segmentation. In CVPR, 2015. ],不过是时间上的。
SoundNet : Student-Teacher
这个训练方法属于transfer learning部分,手法在于利用已有模型得到的预测结果作为student模型的弱标签,使得student去拟合teacher的复杂函数, 以此来达到迁移的目的。Do Deep Nets Really Need to be Deep?以及Distilling the Knowledge in a Neural Network都是和这种方法相关的早期文献,值得阅读。在这篇文章中,作者将此技巧用到,利用已经训练好的场景分类和目标分类的CNN模型得到video对应的logits。然后将对应audio输入到audio CNN,在最后的输出部分学习一个logits,从audio角度去拟合video的输出,达到通过声音理解场景。
SoundNet :End
这个文章的主要思想是student-teacher的方法,还有对sound和video跨模态的处理手段。它的实现我没有仔细看,感觉还挺复杂的,等到以后需要用的时候再回来看叭。