CUDA 调研 运行环境 1 2 3 4 5 6 acsaxwy@snode6:~$ nvcc -V
查看 GPU 信息:
1 acsaxwy@snode6:~$ nvidia-smi
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 Wed Dec 15 14:58:22 2021
如果想看实时信息(但是通过 htop 这个命令,发现它CPU占用率比较高)
1 acsaxwy@snode6:~$watch -n 2 -d nvidia-smi
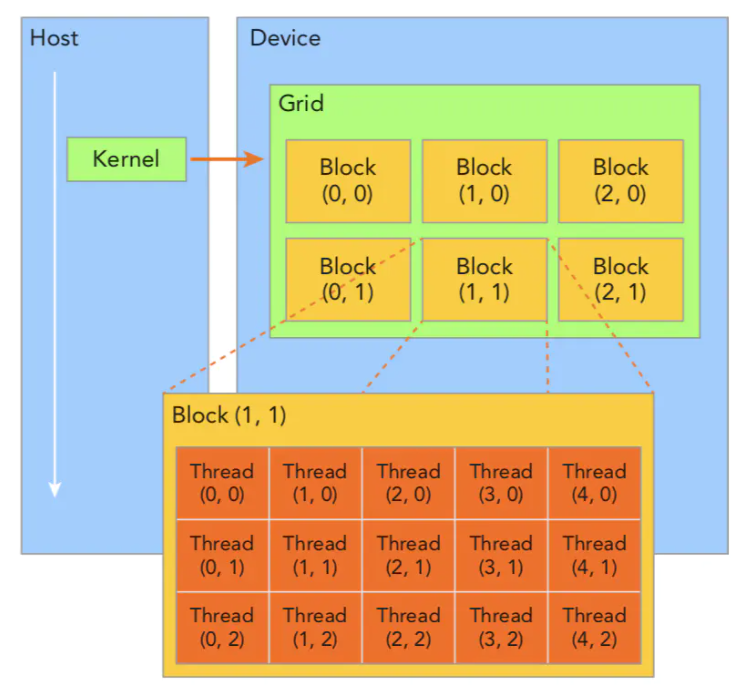
基本概念 CUDA 程序执行的逻辑空间结构:
上图中的 “(2,1)” 是索引,图片没有完全展示全部情况,索引可以是一维,二维或者三维,一般block的索引会是二维,thread的索引会是三维的
thread 是最小结构,没有大小概念,只有索引
cuda 的设备概念:
Host 指“CPU和CPU直接调用的内存”两部分的集合
Device 指“GPU和GPU直接调用的内存”两部分的集合
由于两部分通信开销比较大,所以程序中要特意分开
cuda程序中的函数有如下的修饰(前缀):
由于下划线自动转义,下用“下划线”+”空格”的方式,实际上没有空格
函数前缀名称
作用
__ global __
指定函数是Host上调用,Device上执行
__ device __
指定函数是Device上调用,Device上执行
__ host __
指定函数是Host上调用,Host上执行(最正常的函数,平常就省略不写)
device 和 global 函数不支持递归 。device 和 global 函数的函数体内无法声明静态变量 。device 和 global 函数不得有数量可变的参数 。device 函数的地址无法获取,但支持 global 函数的函数指针。global 和 host 限定符无法一起使用 。global 函数的返回类型必须为空 。对 global 函数的任何调用都必须按规定指定其执行配置。
global 函数的调用是异步 的,也就是说它会在设备执行完成之前返回,如果想要阻等待同步可以使用 cudaDeviceSynchronize() global 函数参数将同时通过共享存储器传递给设备,且限制为 256 字节 。global 和 host 可以一起修饰一个函数,表示函数在Device端和Host端一起编译.
cuda 程序中的变量修饰
变量修饰符
作用
__ device __
数据存放在显存中,所有的线程都可以访问,而且主机也可以通过运行时库访问
__ shared __
数据存放在共享存储器在,只有在所在的块内的线程可以访问,其它块内的线程不能访问
__ constant __
数据存放在常量存储器中,可以被所有的线程访问,也可以被主机通过运行时库访问
Texture
纹理内存(Texture Memory)也是一种只读内存。
/
没有限定符,那表示它存放在寄存器或者本地存储器中,在寄存器中的数据只归线程所有,其它线程不可见。
配置运算符
执行配置运算符<<< >>>,用来传递内核函数的执行参数。执行配置有四个参数,第一个参数声明网格的大小,第二个参数声明块的大小,第三个参数声明动态分配的共享存储器大小,默认为 0,最后一个参数声明执行的流,默认为 0.
1 add<<<grid,block>>>(a,b);
CUDA内置变量
变量
意义
gridDim
gridDim 是一个包含三个元素 x,y,z 的结构体,分别表示网格在x,y,z 三个方向上的尺寸(一般只有2维度)
blockDim
blockDim 也是一个包含三个元素 x,y,z 的结构体,分别表示块在x,y,z 三个方向上的尺寸
blockIdx
blockIdx 也是一个包含三个元素 x,y,z 的结构体,分别表示当前线程块在网格中 x,y,z 三个方向上的索引
threadIdx
是一个包含三个元素 x,y,z 的结构体,分别表示当前线程在其所在块中 x,y,z 三个方向上的索引
warpSize
在计算能力为 1.0 的设备中,这个值是24,在 1.0 以上的设备中,这个值是 32
细节补充
内联函数:
在函数定义 处(注意不是声明),返回类型前加上 inline ,编译器遇到内联函数调用时,将函数用“宏展开”的方式替换代码。作用是对于简短的函数,减少“实参、局部变量、返回地址以及若干寄存器都压入栈中,结束后清除出栈”带来的时空开销.
这只是对编译器的建议,实际编译器可能会有别的优化方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <iostream> using namespace std;inline void swap (int *a, int *b) int temp;int main () int m, n;", " <<n<<endl;swap (&m, &n);", " <<n<<endl;return 0 ;
C++语法补充
const: 是指接下来的变量是只读不能被修改.
volatile: 是指每次需要引用某个变量的数据时,都必须从原地址读取,而不是编译器优化后间接读取.(阅读代码的时候不影响逻辑,可以当作没有;写代码的时候要注意)
重载运算符:
operator 可以重载运算符,比如在代码
1 /home/acsaxwy/Program/Learn/cuda_program/project/cudahandbook-master/reduction/reduction_Sumf_fsq.h
有这么一段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 struct CReduction_Sumf_fsq {public :CReduction_Sumf_fsq ();float sum;float sumsq;operator +=( float a );volatile CReduction_Sumf_fsq& operator +=( float a ) volatile ;operator +=( const CReduction_Sumf_fsq& a );volatile CReduction_Sumf_fsq& operator +=( volatile CReduction_Sumf_fsq& a ) volatile ;inline __device__ __host__volatile CReduction_Sumf_fsq&operator +=( volatile CReduction_Sumf_fsq& a ) volatile return *this ;
上面的代码段(不看volatile)
1 2 3 4 5 6 7 CReduction_Sumf_fsq&operator +=( volatile CReduction_Sumf_fsq& a )return *this ;
就是重新定义 “+=“ 这个运算符,每次隐式或者显示调用”+=“的时候,相当于给结构体”CReduction_Sumf_fsq“ 的变量 sum和sumsq分别加上操作符号”+=“后的数和其平方.
C++模板概念:
函数模板 :
作用就是使得”对于不同数据类型进行相同操作的代码“能够重用.比如下面swap函数对于double,int都是一样的逻辑,所以用typename进行代替
1 2 3 4 5 6 7 8 template <typename T>void swap (T& t1, T& t2)
调用的时候可以直接使用
1 2 3 int a =1 ,b=2 ;swap <int >(a,b);swap (a,b);
类模板:
和函数模板差不多,对于类中,可以仅仅对成员函数进行模板化.
extern “C” :提醒编译器按照 C 语言的方式翻译函数,实现C++和 C 的混合编程.
C++支持函数重载,比如
1 void swap (int a, int a)
会被编译器翻译成
1 void _swap_int_int(int a,int b)
以便重载区分不同函数
阅读CUDA 程序 检查线程块和索引 对于一个我们需要处理的矩阵,比如大小是 (8,6)
1 2 3 4 5 6 7 Matrix: (8.6)
我们如果想让一个GPU运行,那么可以让一个thread对应一个数据,最简单的办法就是可以将block 和 thread 组织成都是二维的结构,这样就可以直接使用一个大的二维索引来指向一个thread.
我们在思考上述thread的逻辑结构时,可以现象如下的图

1 2 ix = threadIdx.x+blockIdx.x*blockDim.x
当然我们申请block数量的时候肯定不一定整数, 所以可以用如下计算方式申请:
dim3 是三维结构的一种数据结构,是 grid 和 block 大小的标准数据结构,这里之所以不是二维的,是因为编译器会自动将没有初始化的维度置为 1 .
1 dim3 grid ((nx + block.x - 1 ) / block.x, (ny + block.y - 1 ) / block.y) ;
代码在
1 /home/acsaxwy/Program/Learn/cuda_program/project/professional-cuda-c-programming-master/examples/chapter02/checkThreadIndex.cu
归约算法 归约问题(reduction):
给多个数相加进行并行加速, 也可以推广到满足交换律结合律的其他运算.
程序在(还没写makefile)
1 /home/acsaxwy/Program/Learn/cuda_program/project/example/reduction
1 $nvcc Reduction1.cu -o Reduction1
采用两遍归约的方式
part1:
先将数据分成多个block,每个block里面进行第一遍归约,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 __global__ void Reduction1_kernel ( int *out, const int *in, size_t N ) extern __shared__ int sPartials[];int sum = 0 ;const int tid = threadIdx.x;for ( size_t i = blockIdx.x*blockDim.x + tid;for ( int activeThreads = blockDim.x>>1 ; 1 ) {if ( tid < activeThreads ) {if ( tid == 0 ) {0 ];
首先需要将数组 in 中的数据通过整合成一个block的尺寸,也就是第一个for的作用 ,然后对block内的thread进行同步
然后进行的是真正的归约算法,即第二个for的作用
for 循环中的算法就是将数组的后一半加到前一半上去,然后再在前一半中的后一半加到前一半的前一半中…
这中被称为“对数归约”,循环完成后一个block 中的和是sPartials[0]的值.
接着,将这个值导出到out中.
part2:
整个main 函数的意思就是将先将每个block中的和计算出来,然后放到out中,然后在将这个out作为输入再次进入 Reduction1_kernel函数,这样就第二次归约得到最终的和.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void Reduction1 ( int *answer, int *partial, const int *in, size_t N, int numBlocks, int numThreads ) unsigned int sharedSize = numThreads*sizeof (int );1 , numThreads, sharedSize>>>(
整体的输出效果就是(文件的输入参数m是总数 N 的大小,$N = 2^m$)
1 2 3 acsaxwy@snode6:~/Program/Learn/cuda_program/project/example/reduction$ ./Reduction1 25