OP2 DSL
OP2 DSL 调研
徐炜烨
数据类型模式
Mike 在文章 OP2 Developers Guide 中提到,他个人更倾向于用 AoS.
For this reason, I have chosen to use the AoS format.
AoS and SoA 介绍
- AoS: for each set element, store all of the components together as a small contiguous block.
- SoA: for each component, store the data for all of the set elements as a contiguous block.
SoA 简单来说就是 a struct of arrays , AoS 是 array of structs.
举个实际例子,现在有一个“粒子在重力场运动”的模拟场景. 而粒子是有多种属性:位置,速度,质量等,要计算多个时间段后粒子的位置.
对于 SoA 来说,就是将所有粒子的位置存储成一个连续的数组,将所有粒子的位置存储成一个数组,质量也是,然后将这些数组组合成一个结构体.
对于 AoS 来说,就是将每个粒子的位置,速度,质量等信息存储成一个结构体之内,然后将这些结构体组成数组.
Fermi 结构的 cache 行大小是 128 bits(32 Bytes)
OP2 的并行策略
多核CPU上,尽量使得每个线程使用SEE/AVX 这类的指令扩展集.
在GPU上,尽量使得每个block都有多线程.
CPU计算中减少高速缓存和主存之间的数据交换.
GPU上减少 host 和 device 之间的数据交换.
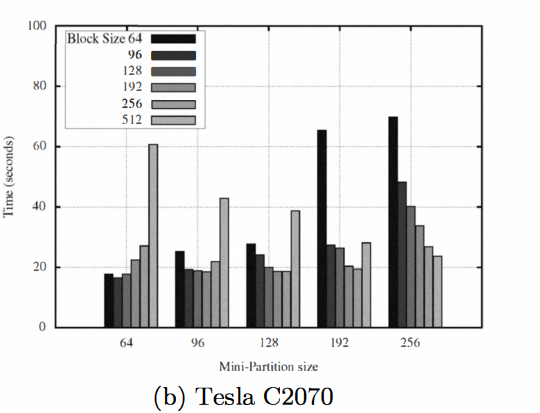
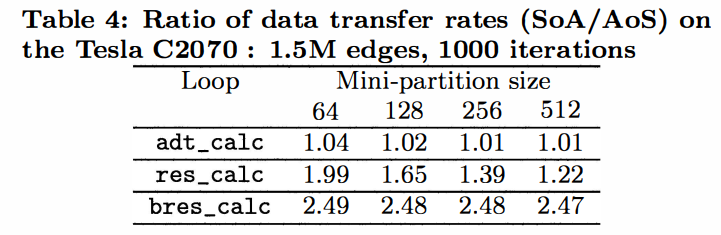
在CPU上,OP2 会用op_plan 为每个par loop 构建一个分块和线程块都定制的执行计划,分块大小可以在在编译阶段调节也可以在运行时用命令行参数调节.
The thread-block and mini-partition sizes for the overall application can be set at run-time using command-line arguments or a different value for each individual loop could be set at compile time.
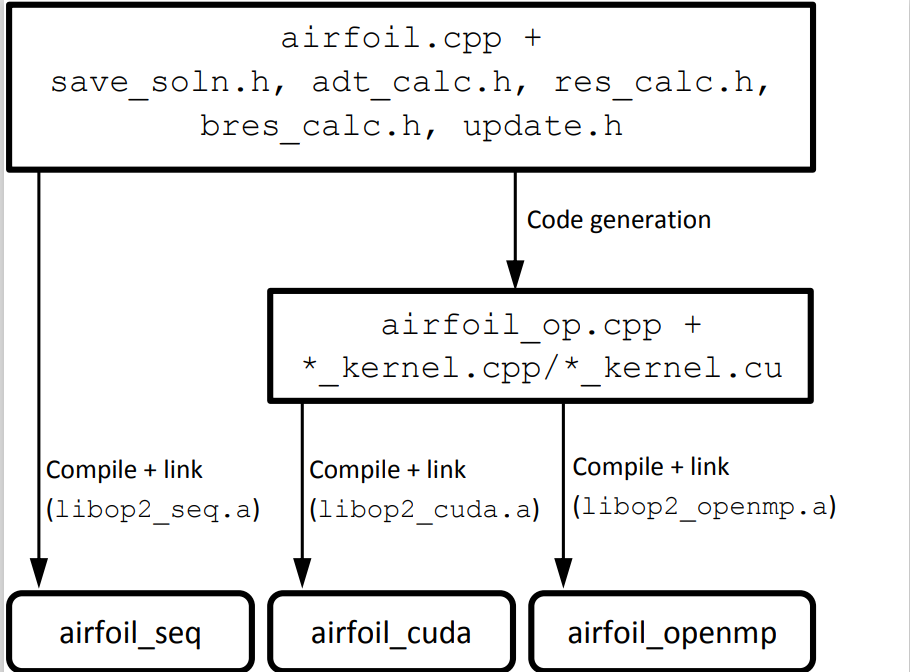
例子 Airfoil
OP2 概述
OP 2 的是一种 Domain Specific Language (DSL) ,这种领域特定语言的就是帮助开发者生成可以并行的 C/Fortran的代码,它并不是一个编译器.
从另外一个视角来看,它的 Domain Specific Language 还体现在特定的数据结构模式. OP2 是处理的物理背景是使用非结构网格中,相比结构化网格来说. 非结构化网格更加灵活,结构化网格比如所是只能是矩形,而且是井字形网格,这种方式更加传统,简单来说就是用大小完全相同的矩形格子(或者方块)的拼接来描述一个所需物理区域,而非结构网格就更加灵活,举二维区域来说,其中的面可以是三角形,四边形等等,而且边的大小和权重也可以改变,但随之而来的表示的困难,而且不利于计算机的顺序处理,但是它在 PDE,CFD,CME等领域出色的表现,OP2 对于这种非结构化网格的并行处理进行了处理.
OP2 因为是只处理非结构化网格,那么其中的就会有一些特定的概念
- 集合 set: 可以是边集合,点集合,块集合,这里的集合是一个抽象概念.
- 数据 data:是指各个集合中元素所对应的数据.
- 映射 map : 是指不同集合元素之间的映射,可以确定相邻关系.
举个例子
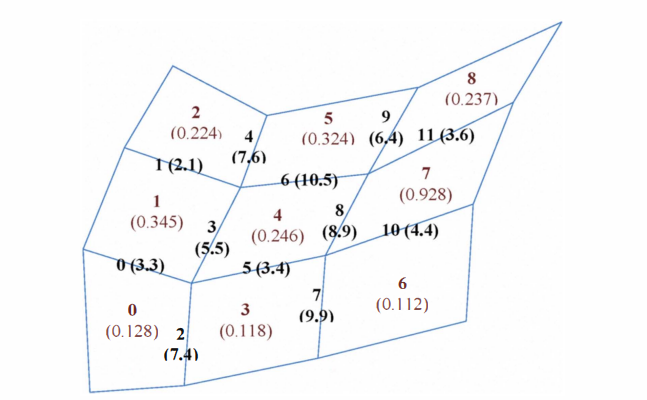
内部边数量有 12 条,块数量有 9 个 ,边界边有 12 条. OP2 用以下的 API 来定义集合.
1 | |
定义完集合之后就要定义不同集合之间的关系,比如定义块和边之间的相邻关系.
从外部读取相邻关系
1 | |
然后使用
1 | |
定义内部边和块之间的关系.
定义映射关系的目的一方面是要描述非结构化网格的相邻属性,另外一方面是为了之后分成 partition 的时候调取数据方便.
然后就是定义元素的数据.
1 | |
对于循环 OP2 也定义了自己的循环API,为了能够后续处理成并行方式.(对于编写科学程序的人来说就是串行程序,比较友善)
比如原来想写的串行程序
1 | |
可以写成
1 | |
相当于调用 op_par_loop 来代替 for, 当然需要传入函数指针和函数的参数,原来函数的参数,在 op_par_loop 里会变成 op_arg 使用映射来定义原理的数据,而这个映射就是第一个参数到其他参数的对应关系,然后再从元素找到元素对应的数据.
这里再介绍一下 OP2 的并行策略,上面说到使用 op_par_loop 来进行循环,而 op2 会将这个循环进行分区(partition).
对于在多核CPU上使用 MPI 运行程序. 比如使用两个进程(X,Y)举例
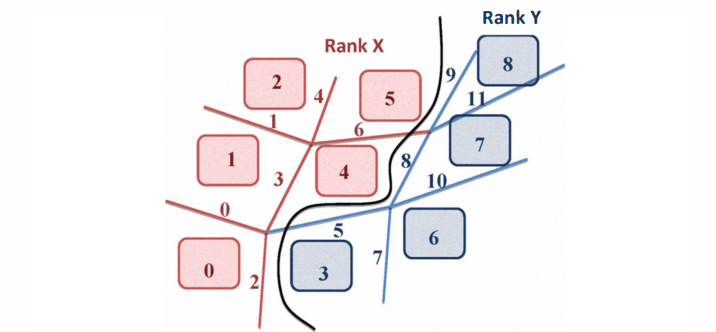
在边界地方数据,两个进程会进行通信来交换数据(halo exchange)
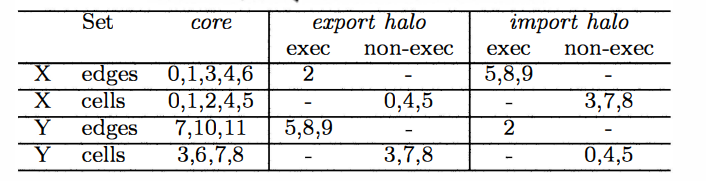
有一个问题就是,为了更新 cell ,我们可能需要对 cell 周围的 edge 进行计算,每个进程有不同的cell ,但是有可能进程 A和 进程B 有两个 cell 是相邻的,这样会导致它们需要计算相同的 edge,这就会导致重复计算,对于多核 CPU 来所可能问题不大,因为数据量非常庞大,对于一个进程不相邻的cell 和与别的进程相邻的cell 的比例非常大所以基本可以忽略重复计算带来的计算开销.
当然对于 GPU 来说就不一样了,因为它每个 thread 所能直接访问的高速缓存大小非常有限,这就导致了需要分成更多区(mini-partition)
更小的分区意味着每个分区更大的边界比例,更多 halo exchange, 所以分区的时候需要更加谨慎,尽量使得分区内部的cell 都是相邻的.这里 OP2 使用了一种叫做 coloring 的技术,大致意思就是使得同一种颜色的边不会对应相同的 cell, 这样分区的时候避免在一个 mini-partition 中使用相同颜色的边,可以一定程度上减少对 edge 的重复计算.
在 CPU 上
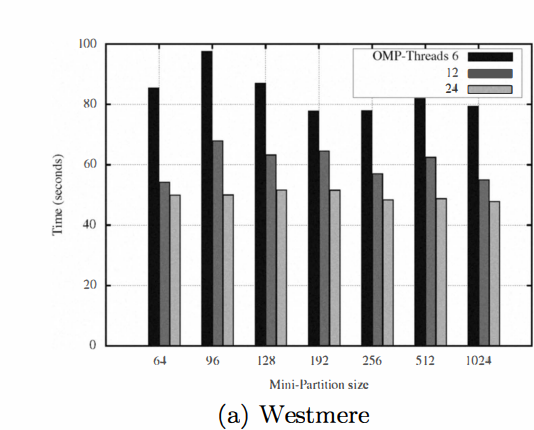
在 GPU 上 ,