Self-Adaptively Learning to Demoiré from Focused and Defocused Image Pairs (NeurIPS 2020)
Lin Liu1, Shanxin Yuan2, Jianzhuang Liu2, Liping Bao1, Gregory Slabaugh2, Qi Tian3
1EEIS Department, University of Science and Technology of China
2Noah's Ark Lab, Huawei Technologies
3Huawei Cloud BU
{ll0825, baoliping}mail.ustc.edu.cn {shanxin.yuan, liu.jianzhuang, gregory.slabaugh, tian.qi1}@huawei.com
Note: The non-official code reimplemented by Liping Bao is released.
Abstract
Moire artifacts are common in digital photography, resulting from the interference between high-frequency scene content and the color filter array of the camera. Existing deep learning-based demoireing methods trained on large scale datasets are limited in handling various complex moire patterns, and mainly focus on demoireing of photos taken of digital displays. Moreover, obtaining moire-free ground-truth in natural scenes is difficult but needed for training. In this paper, we propose a self-adaptive learning method for demoireing a high-frequency image, with the help of an additional defocused moire-free blur image. Given an image degraded with moire artifacts and a moire-free blur image, our network predicts a moire-free clean image and a blur kernel with a self-adaptive strategy that does not require an explicit training stage, instead performing test-time adaptation. Our model has two sub-networks and works iteratively. During each iteration, one sub-network takes the moire image as input, removing moiré patterns and restoring image details, and the other sub-network estimates the blur kernel from the blur image. The two sub-networks are jointly optimized. Extensive experiments demonstrate that our method outperforms state-of-the-art methods and can produce high-quality demoired results. It can generalize well to the task of removing moire artifacts caused by display screens. In addition, we build a new moire dataset, including images with screen and texture moire artifacts. As far as we know, this is the first dataset with real texture moire patterns.
Framework Overview
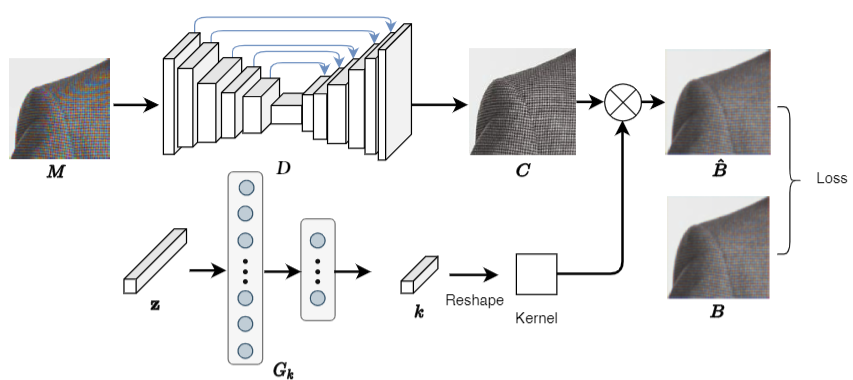
The input of D is a focused image with moire patterns. D is a U-Net-like network where its first 5 layers of the encoder are connected via skip-connections to the 5 layers of the decoder. A convolutional output layer with the sigmoid function is used to generate the moire-free image C. U-Net-like structures have been shown to work well in many low-level computer vision tasks. For the network G_{k}, a blur kernel usually contains much less information than an image, and can be well estimated by a simpler generative network. Thus, we adopt a 3-layer fully-connected network (FCN) to serve as G_{k}. It takes a 200-dimentional vector (noise) z as the input. The hidden layer and the output layer have 1,000 nodes and K^{2} nodes, respectively, and the blur kernel size is K x K. A softmax layer is applied to the output layer of G_{k} to ensure the constraints in Eqns 5 and 6.
Comparison

The result of DIP has obvious moiré artifacts left, and DoubleDIP has a global color shift from the original input and over-smoothed details. These two deep image prior methods cannot effectively remove moiré patterns, perhaps because the low-frequency characteristics and the color diversity of moiré patterns are difficult to learn by them. Moire patterns and noise are different; the former are prevalent more in low and mid-frequencies. DIP relies on the spectral bias of the CNN to learn lower frequencies first. So before DIP learns the high-frequency details of the image, moire patterns have appeared in the results of DIP. The demoiréing only methods (DMCNN, CFNet and MopNet) cannot effectively remove the moiré patterns. In addition, the joint filtering methods (GF and MSJF) tend to blur the high-frequency regions and cannot remove the moiré patterns well with the guidance of the blur image. In contrast, our method FDNet eliminates the moiré patterns more effectively, benefiting from the accurate prediction of the blur kernel. In addition, FDNet retains the original textures in the images with moiré patterns removed instead ofover-smoothing the high-frequency regions. More results are provided in the supplementary material.
Result on the real scene

We also test our model on a smartphone HUAWEI P30 PRO. We collect some focused and defocused image pairs from natural scenes, where the focused images have texture moire patterns, as shown in the Figure. To test on the real world examples, we do some preprocessing, e.g., alignment. We keep the areas where the moire is produced at the same depth. FDNet generalizes well to images taken from natural scenes (not from screens), as the results are moire-free and the details are retained from the focused moire image.
Contact
Lin Liu, BSc University of Science and Technology of China (USTC),MSc University of Science and Technology of China (USTC).
West campus of USTC, Huangshan Road, Shu shan district, Hefei, AnHui Province, China, 230027
Huawei E1, Bantian, Longgang district, Shenzhen, Guangdong Provice, China.
If you have any question, feel free to contact me with Email.
Acknowledgments
A big thanks to Liping Bao for capturing the images for our dataset.
This study was done when Lin Liu was a student research intern in Huawei Noah`s Ark Lab.