|
I am an Assistant Professor at the College of Info Science & Technology, Eastern Institute of Technology (EIT), Ningbo where I cooperated with professor Wenjun Zeng (IEEE Fellow). Our group is to engage in state of the art research in deep learning, computer vision and multimedia. Previously, I was a Visiting Scholar of Learning and Vision (LV) Lab at the National University of Singapore where I was guided by professor Xinchao Wang, professor Jiashi Feng and professor Shuicheng Yan. I received Ph.D. degree from University of Science and Technology of China (USTC), under the supervision of Zhibo Chen. From Jan. 2019 to Jul. 2020, I also worked at Intelligent Multimedia Group (IMG) in MSRA under the supervision of Cuiling Lan. From Sep. 2018 to Jan. 2019, I worked at KDDI Research, Inc. in Japan under the supervision of Jianfeng Xu. If you are highly creative, have top research/coding skill and interested in joining us, please do not hesitate to send me (jinxin@eitech.edu.cn) your CV. |

|
|
|
|
In CVPR 2024 and ECCV 2024, we organized two tutorial sessions related to “Visual Disentanglement and Compositionality”. In VCIP 2024, we also build up a special session about “Generative AI for Image/Video Coding”. |
|
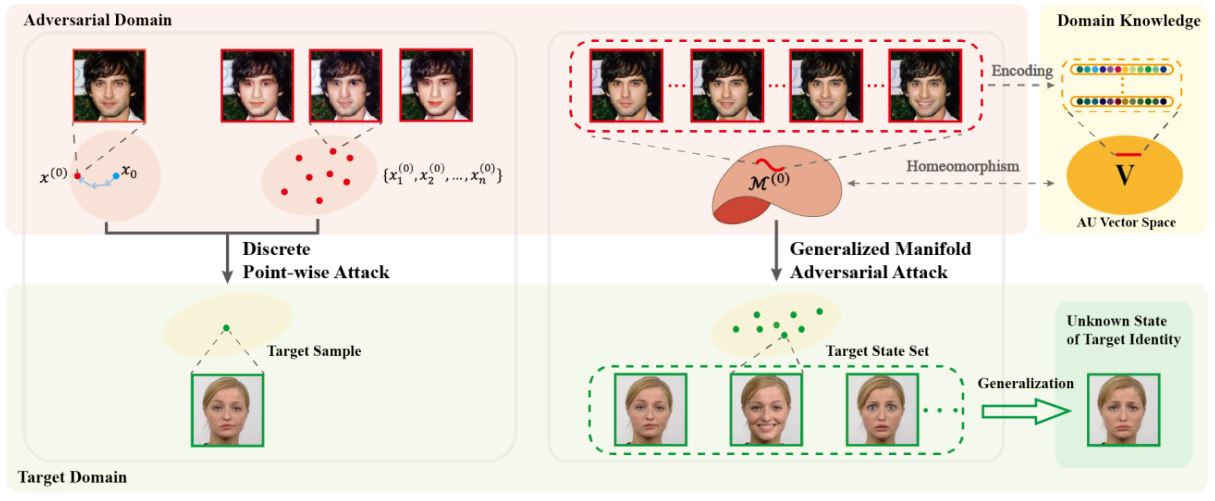
Qian Li*, Yuxiao Hu*, Ye Liu, Dongxiao Zhang, Xin Jin†, Yuntian Chen† CVPR, 2023 arxiv / In this work, by rethinking the inherent relationship between the face of target identity and its variants, we introduce a new pipeline of Generalized Manifold Adversarial Attack (GMAA) to achieve a better attack performance by expanding the attack range. |
|
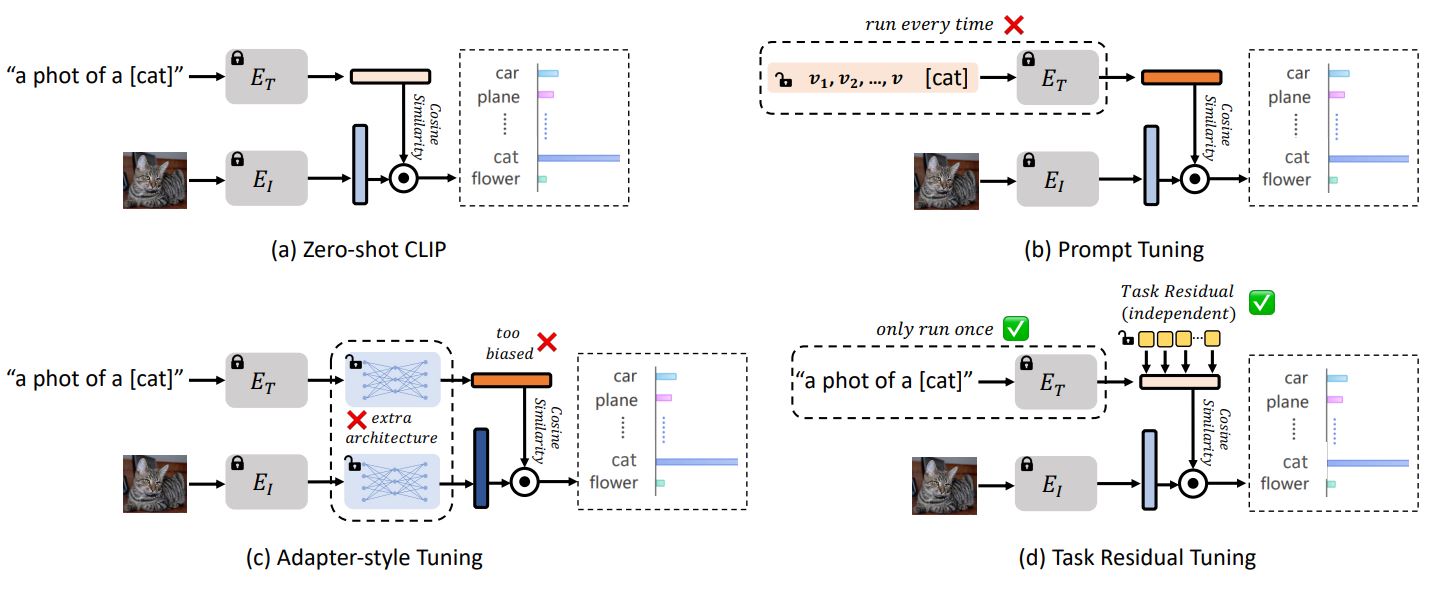
Tao Yu*, Zhihe Lu*, Xin Jin, Zhibo Chen, Xinchao Wang CVPR, 2023 arxiv / code / In this work, we propose a new efficient tuning approach for VLMs named Task Residual Tuning (TaskRes), which performs directly on the text-based classifier and explicitly decouples the prior knowledge of the pre-trained models and new knowledge regarding a target task. |
|
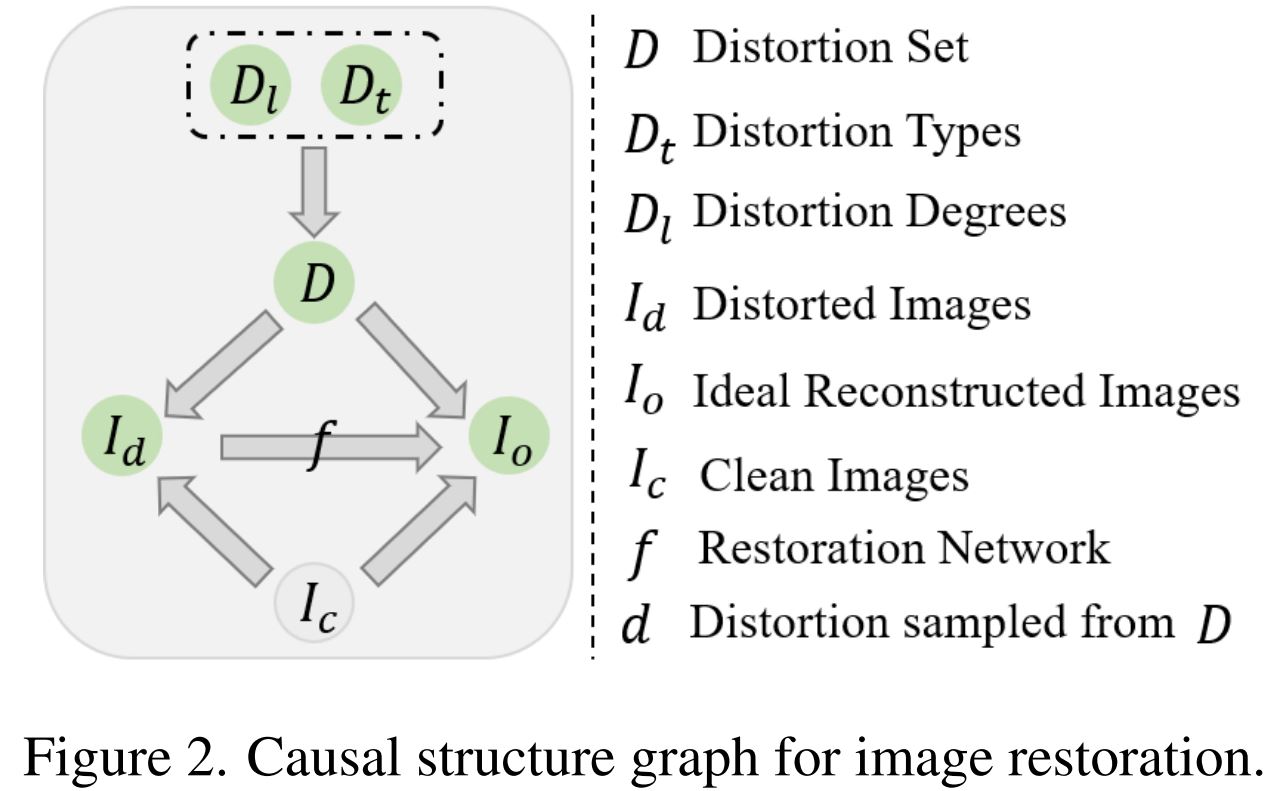
Xin Li*, Bingchen Li*, Xin Jin, Cuiling Lan, Zhibo Chen CVPR, 2023 arxiv / code / In this work, we are the first to propose a novel training strategy for image restoration from the causality perspective, to improve the generalization ability of DNNs for unknown degradations. |
|
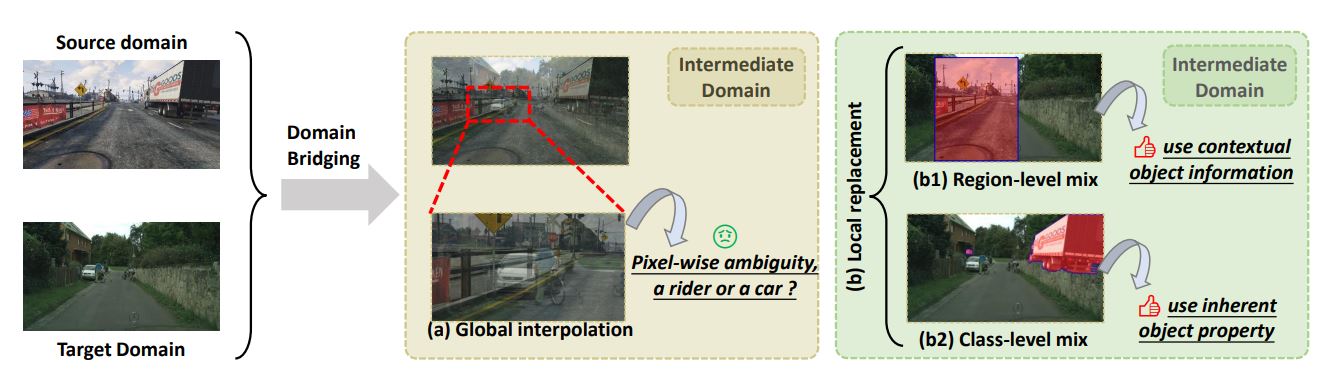
Lin Chen*, Zhixiang Wei*, Xin Jin*(equal), Huaian Chen, Kai Chen, Yi Jin NeurIPS, 2022 arxiv / code / In this work, we resort to data mixing to establish a deliberated domain bridging (DDB) for domain adaptive semantic segmentation. The joint distributions of source and target domains are aligned and interacted with each other in the intermediate space. |
|
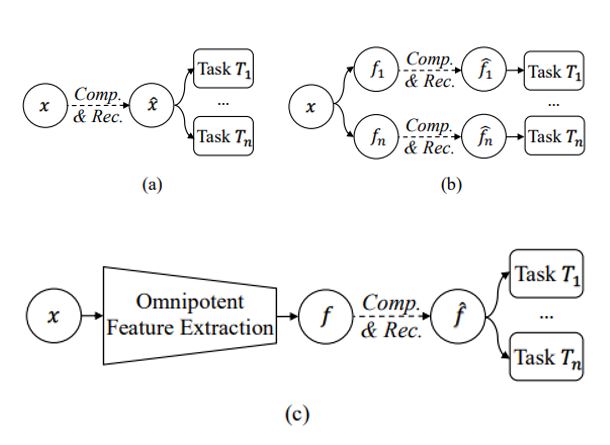
Ruoyu Feng*, Xin Jin*(equal), Zongyu Guo, Runsen Feng, Yixin Gao , Tianyu He , Zhizheng Zhang , Simeng Sun , Zhibo Chen ECCV, 2022 arxiv / In this paper, we attempt to learn a kind of omnipotent feature that is both general (for AI tasks) and compact (for compression) for Image Coding for Machines (ICM). Considering self-supervised learning (SSL) improves feature generalization, we integrate it with the compression task to learn such features. |
|
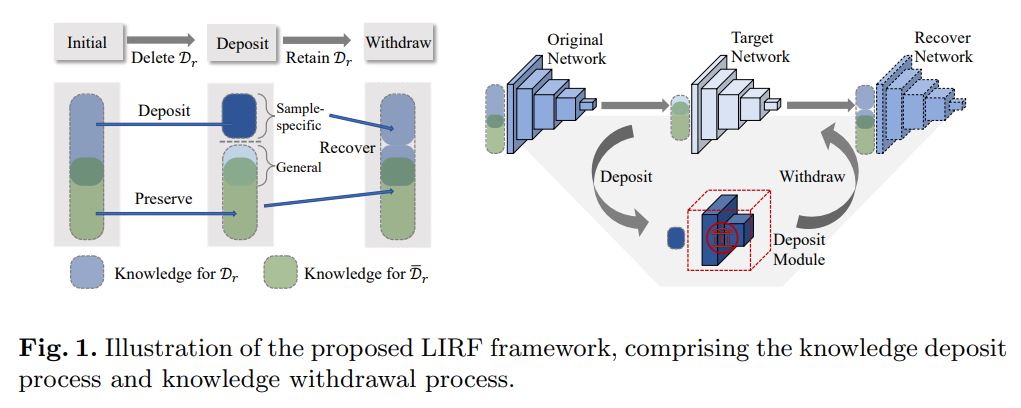
Jingwen Ye, Yifang Fu, Jie Song, Xingyi Yang, Songhua Liu, Xin Jin, Mingli Song, Xinchao Wang ECCV, 2022 arxiv / In this paper, we explore a novel learning scheme, termed as Learning wIth Recoverable Forgetting (LIRF), that explicitly handles the task- or sample-specific knowledge removal and recovery. |
|
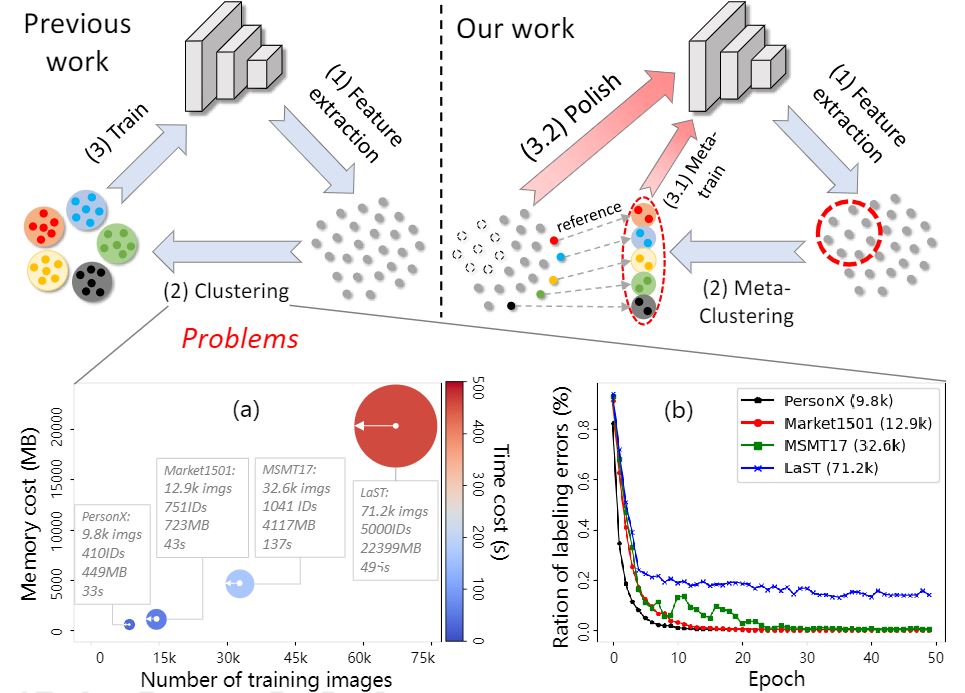
Xin Jin, Tianyu He, Xu Shen, Tongliang Liu, Xinchao Wang , Jianqiang Huang , Zhibo Chen, Xian-Sheng Hua ACMMM, 2022 arxiv / In this paper, we make attempt to the large-scale Unsupervised ReID and propose a “small data for big task” paradigm dubbed Meta Clustering Learning (MCL), which our method significantly saves computational cost while achieving a comparable or even better performance compared to prior works. |

|
Zizheng Yang, Xin Jin, Kecheng Zheng, Feng Zhao CVPR, 2022 arxiv / code / We design an Unsupervised Pre-training framework for ReID based on the contrastive learning (CL) pipeline, dubbed UP-ReID. |

|
Xin Jin, Tianyu He, Kecheng Zheng, Zhiheng Ying, Xu Shen, Zhen Huang , Ruoyu Feng , Jianqiang Huang , Xian-Sheng Hua , Zhibo Chen CVPR, 2022 arxiv / code / We focus on handling well the Cloth-Changing ReID problem under a more challenging setting, i.e., just from a single image, which enables high-efficiency and latency-free pedestrian identify for real-time surveillance applications. |
|
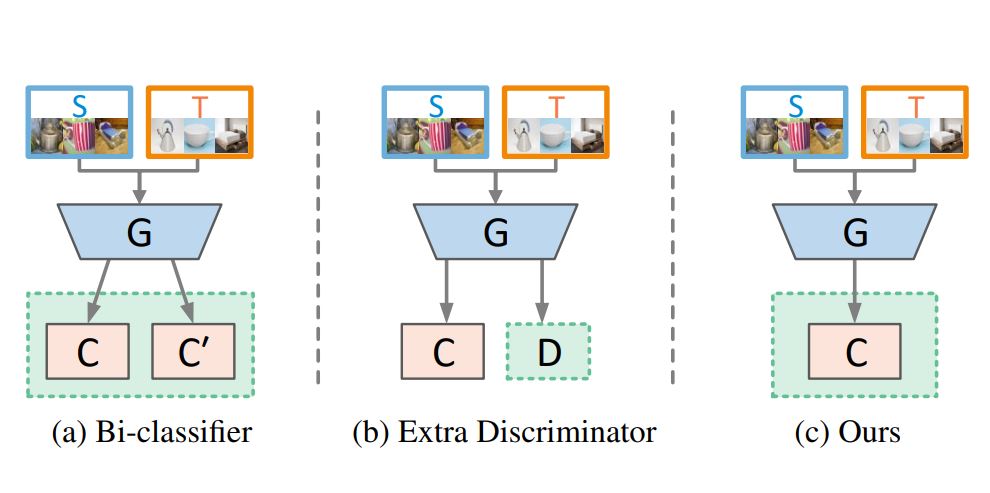
Lin Chen, Huaian Chen, Zhixiang Wei, Xin Jin, Xiao Tan, Yi Jin, Enhong Chen CVPR, 2022 arxiv / code / We address the adversarial-based DA problem from a different perspective and design a simple yet effective adversarial paradigm in the form of a discriminator-free adversarial learning network (DALN), wherein the category classifier is reused as a discriminator. |
|
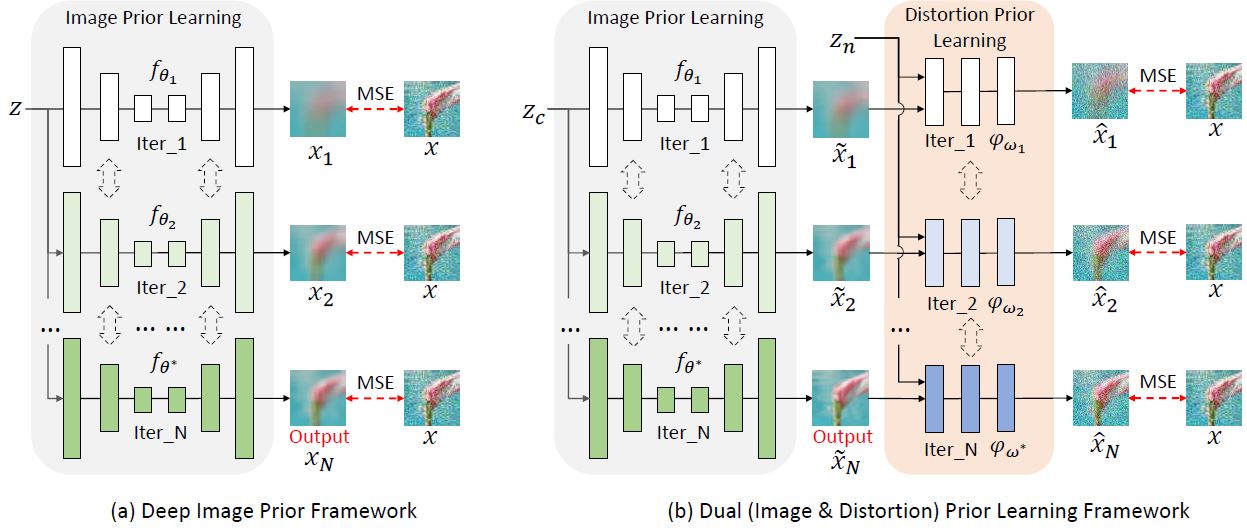
Xin Jin, Li Zhang, Chaowei Shan, Xin Li, Zhibo Chen IEEE TIP, 2021 paper / We propose the Dual Prior Learning (DPL) method for blind image restoration by taking both image and distortion priors into account. DPL goes beyond DIP (deep image prior) by considering an additional step to explicitly learn the blended distortion prior. |
|
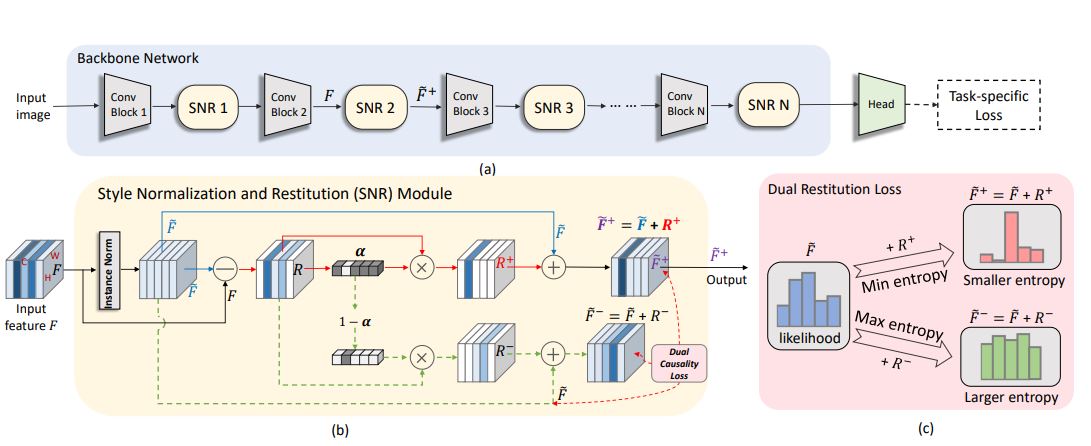
Xin Jin, Cuiling Lan, Wenjun Zeng, Zhibo Chen IEEE TMM, 2021 paper / code / We design a novel Style Normalization and Restitution module (SNR) to simultaneously ensure both high generalization and discrimination capability of the networks, and evaluate it on multiple vision tasks of classification, detection, segmentation, etc. |
|
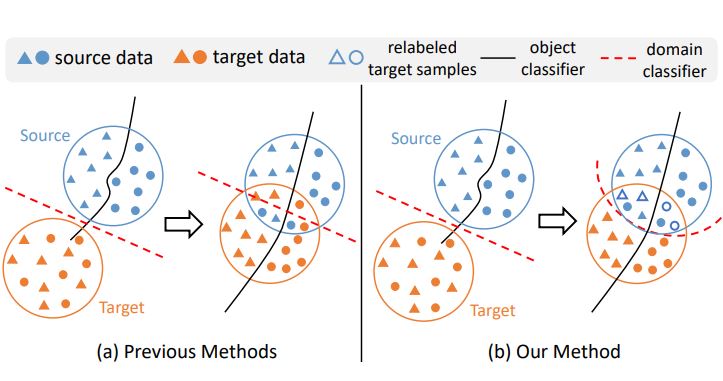
Xin Jin, Cuiling Lan, Wenjun Zeng, Zhibo Chen ICCV, 2021 paper / We propose an efficient optimization strategy named Re-enforceable Adversarial Domain Adaptation (RADA) which aims to re-energize the domain discriminator during the training by using dynamic domain labels. |
|
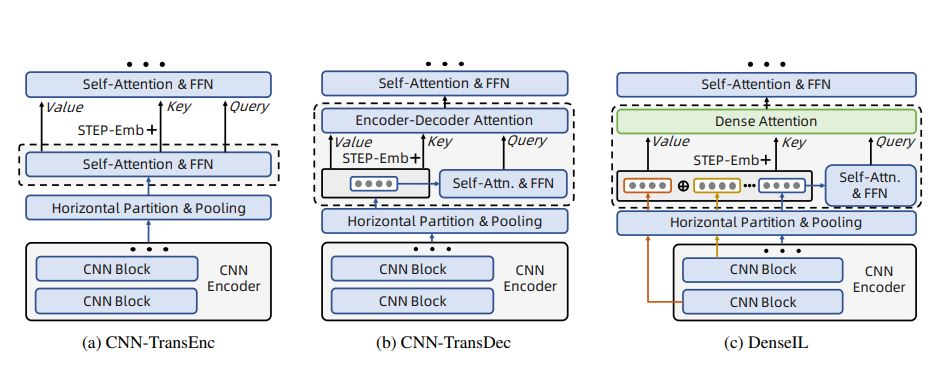
Tianyu He, Xin Jin, Xu Shen, Jianqiang Huang, Zhibo Chen, Xian-Sheng Hua ICCV, 2021 (Oral) paper / This paper proposes a hybrid framework, Dense Interaction Learning (DenseIL), that takes the principal advantages of both CNN-based and Attention-based architectures to tackle video-based person re-ID difficulties. |
|
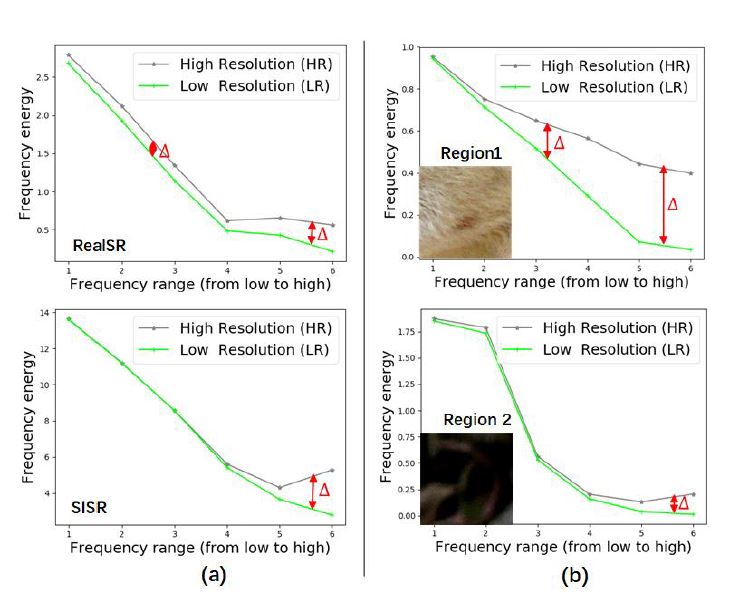
Xin Li*, Xin Jin*, Tao Yu, Yingxue Pang, Simeng Sun, Zhizheng Zhang, Zhibo Chen *Equal Contribution AAAI, 2021 arxiv / The key to solving this more challenging real image super-resolution (RealSR) problem lies in learning feature representations that are both informative and content-aware. We propose an Omni-frequency Region-adaptive Network (OR-Net), here we call features of all low, middle and high frequencies omni-frequency features. |
|
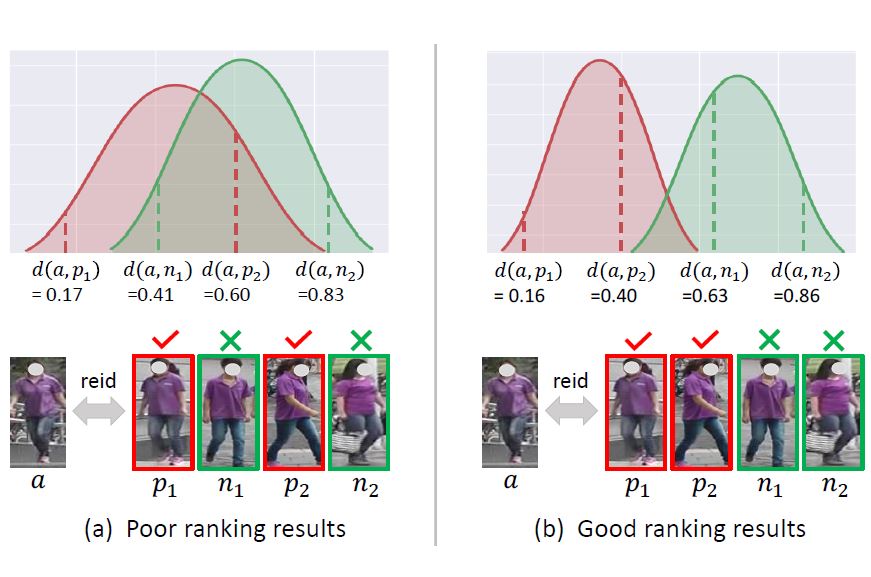
Xin Jin, Jiawei Liu, Cuiling Lan, Wenjun Zeng, Zhibo Chen ECCV, 2020 paper / We introduce a global distance-distributions separation (GDS) constraint over the two distributions to encourage the clear separation of positive and negative samples from a global view. |
|
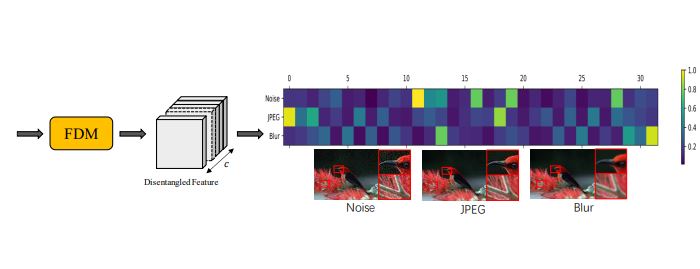
Xin Li , Xin Jin, Jianxin Lin, Tao Yu, Sen Liu , Yaojun Wu , Wei Zhou, Zhibo Chen ECCV, 2020 paper / We introduce the concept of Disentangled Feature Learning to achieve the feature-level divide-and-conquer of hybrid distortions for low-level enhancement. |
|
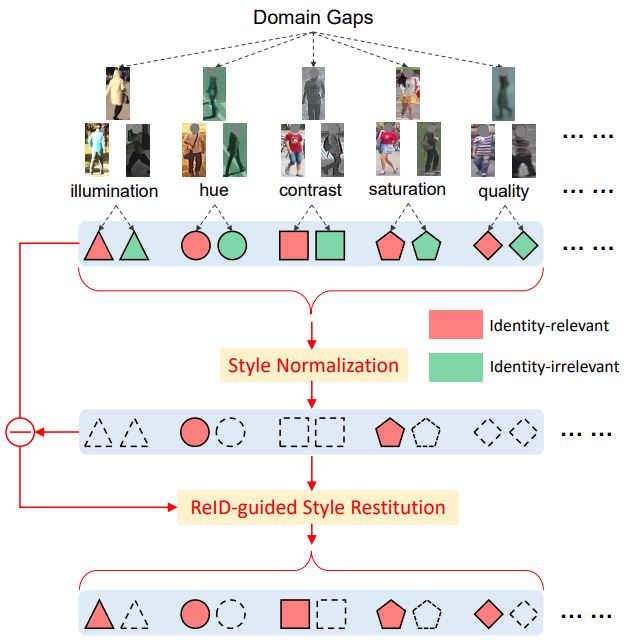
Xin Jin, Cuiling Lan, Wenjun Zeng, Zhibo Chen, Li Zhang CVPR, 2020 paper / code / We propose a simple yet effective Style Normalization and Restitution (SNR) module. Specifically, we filter out style variations (eg, illumination, color contrast) by Instance Normalization (IN). However, such a process inevitably removes discriminative information. We propose to distill identity-relevant feature from the removed information and restitute it to the network to ensure high discrimination. |
|
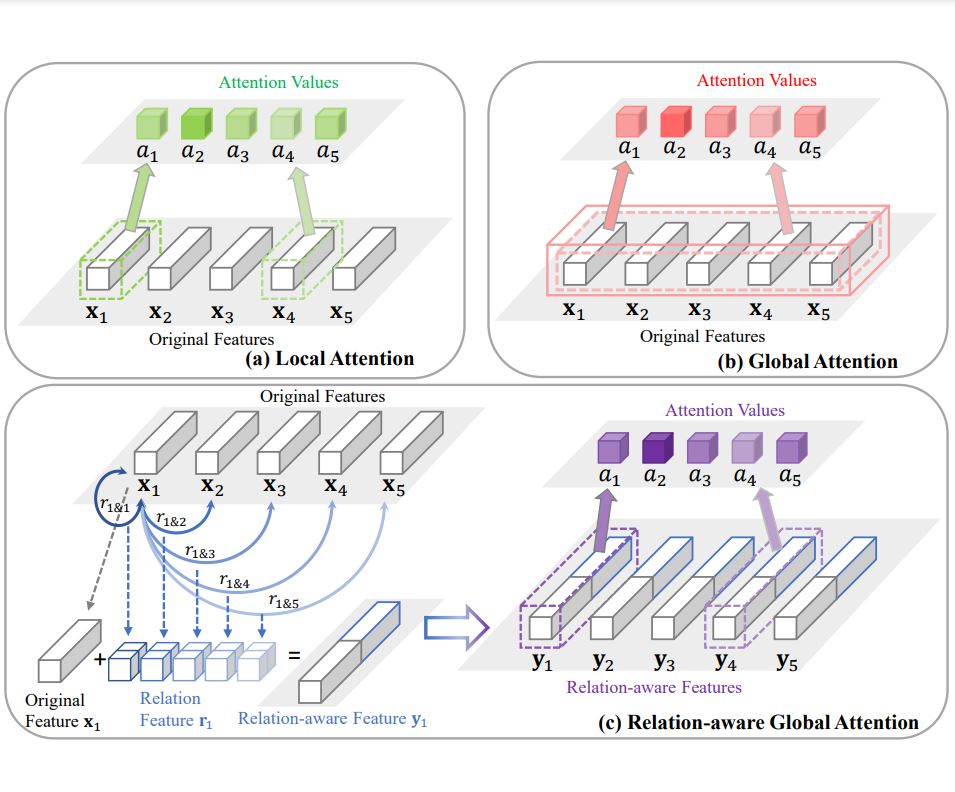
Zhizheng Zhang, Cuiling Lan, Wenjun Zeng, Xin Jin, Zhibo Chen CVPR, 2020 paper / code / We propose an effective Relation-Aware Global Attention (RGA) module which captures the global structural information for better attention learning. |
|
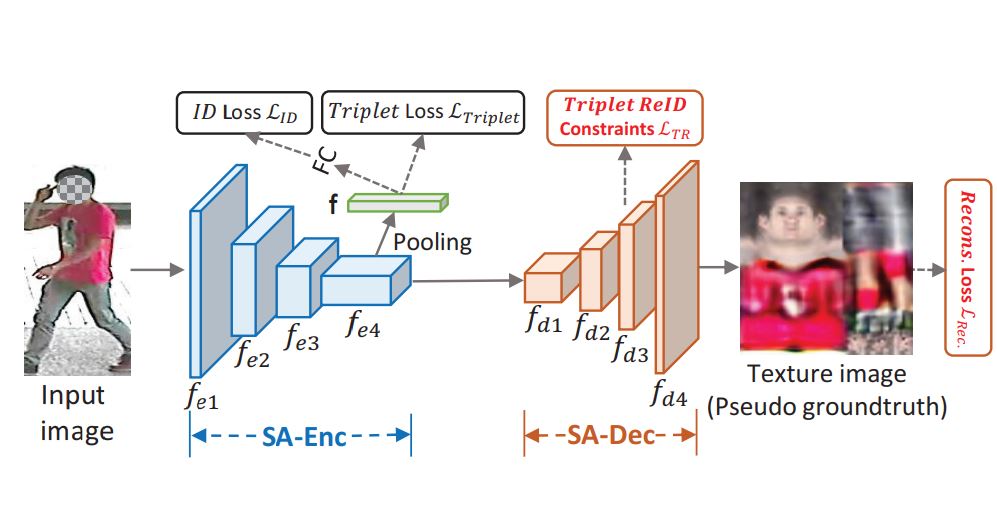
Xin Jin, Cuiling Lan, Wenjun Zeng, Guoqiang Wei, Zhibo Chen AAAI, 2020 paper / code / We build a Semantics Aligning Network (SAN) which consists of a base network as encoder (SA-Enc) for re-ID, and a decoder (SA-Dec) for reconstructing the densely semantics aligned full texture image. |
|
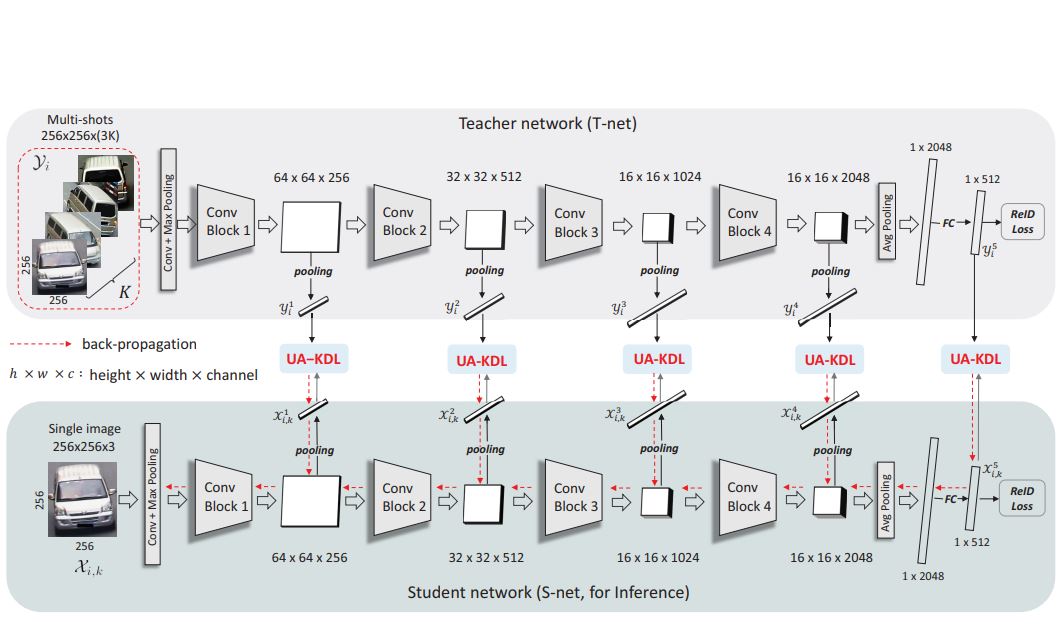
Xin Jin, Cuiling Lan, Wenjun Zeng, Zhibo Chen AAAI, 2020 paper / We propose exploiting the multi-shots of the same identity to guide the feature learning of each individual image. Specifically, we design an Uncertainty-aware Multi-shot Teacher-Student (UMTS) Network. |
|
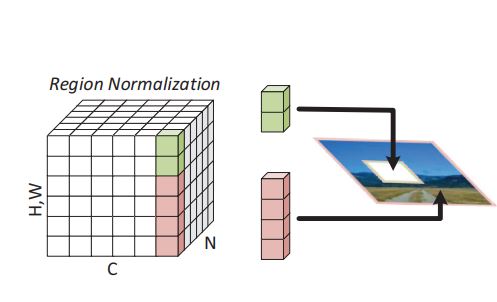
Tao Yu, Zongyu Guo, Xin Jin, Shilin Wu, Zhibo Chen, Weiping Li, Zhizheng Zhang, Sen Liu AAAI, 2020 paper / code We show that the mean and variance shifts caused by full-spatial FN limit the image inpainting network training and we propose a spatial region-wise normalization named Region Normalization (RN) to overcome the limitation. |
|
|
|
Invited Reviewer for IEEE TIP, IEEE TNNLS, IEEE TIP, IEEE TCSVT, Pattern Recognition
Invited Reviewer for NeurIPS-2022, ECCV-2022, ACMMM-2022, CVPR-2022, AAAI-2022 (PC), ICCV-2021, CVPR-2021, AAAI-2021, ACMMM-2020, VCIP-2020, etc. |
|
Feel free to steal this website's source code.
|