嵌入式与微机原理总复习
嵌入式与微机原理总复习复习大纲1. 概述1.1. 计算机的发展简史1.1.1. 计算机的诞生1.1.2. 现代计算机发展历程1.1.3. 计算机的类型1.2. 计算机系统的组成1.2.1. 计算机硬件1.2.1.1. 存储器1.2.1.2. 运算器1.2.1.3. 控制器1.2.1.4. 输入设备1.2.1.5. 输入设备1.2.1.6. 适配器1.2.1.7. 总线1.2.2. 计算机软件1.2.2.1. 计算机软件分类1.2.2.2. 计算机软件的发展1.3. 计算机中数的表示方法1.3.1. 进位计数制1.3.2. 有符号数的原码、反码和补码表示1.3.3. 定点数和浮点数1.3.4. 其他信息编码1.4. 嵌入式系统简介1.4.1. 嵌入式系统的基本概念1.4.2. 嵌入式系统的硬件1.4.3. 嵌入式系统软件1.4.4. 嵌入式系统的发展概况1.4.5. 典型嵌入式处理器简介2. 计算机系统的基本结构与工作原理2.1. 计算机系统的基本结构与组成2.1.1. 计算机的层次模型2.1.2. 基于冯诺依曼架构的模型机系统结构2.2. 模型机存储器子系统2.2.1. 存储器的组织和地址2.2.2. 字的对齐——对准存放2.2.3. 小端格式和大端格式2.2.4. 存储器操作2.2.5. 存储器的分级2.3. 模型机CPU子系统2.3.1. 运算器2.4.2. 控制器2.4.3. 寄存器阵列2.4.4. 地址与数据缓冲器2.4.5. 数据通道2.4. 模型机指令集和指令执行过程2.4.1. 模型机指令集2.4.2. 指令周期2.4.3. 模型机指令执行流程2.5. 计算机体系结构的改进2.5.1. CISC和RISC2.5.1. 流水线技术2.5.3. 超标量处理器和多发射技术2.5.4. 超线程处理器2.5.5. 多处理器计算机和多计算机系统2.5.6. 多核处理器2.6. Intel x86典型微处理器简介2.6.1. Intel 8086处理器2.6.2. Intel Pentium处理器2.7. ARM嵌入式处理器简介2.7.1. ARM体系结构、ARM处理器和ARM内核2.7.2. ARM处理器的特点2.7.3. 典型ARM内核的基本结构2.8. 计算机性能评测2.8.1. 定性描述指标2.8.2. 定量指标描述3. 存储器系统3.1. 概述3.1.1. 存储器的类型及特点3.1.1.1. 半导体存储器3.1.1.2. 磁介质存储器3.1.1.3. 光存储器3.1.2. 微机系统的存储体系架构3.1.3. 辅助存储器主要接口标准3.2. 半导体存储芯片的基本结构和性能指标3.2.1. 随机存取存储器RAM3.2.2. 只读存储器ROM3.2.3. 存储芯片的性能指标3.3. 内存条性能的改进3.3.1. 内存条的组成3.3.2. 内存条的演变3.4. 存储系统的层次架构3.4.1. 存储系统的分层管理3.4.2. 虚拟存储器与地址映射3.5. 高速缓冲存储器Cache3.5.1. 高速缓冲存储器Cache的原理3.5.2. 高速缓冲存储器Cache的基本结构3.5.3. 地址映射与转换3.5.4. Cache更新与替换策略3.5.5. 影响Cache性能的因素3.6. 存储器系统设计3.6.1. 主存储器系统设计技术3.6.2. 存储器系统扩展方式3.6.3. 嵌入式存储器系统设计4. 总线和接口4.1. 总线技术4.1.1. 总线技术概述4.1.1.1. 总线的概念4.1.1.2. 总线的分类4.1.1.3. 总线的结构4.1.2. 总线仲裁4.1.2.1. 集中式仲裁4.1.2.2. 分布式仲裁4.1.3. 总线操作与时序4.1.3.1. 同步总线时序4.1.3.2. 异步总线时序4.1.3.3. 半同步总线时序4.1.3.4. 周期分裂式时序4.2. 片内总线AMBA4.2.1. AMBA总线概述4.2.2. AHB总线4.2.2.1. AHB系统的构成4.2.2.2. AHB信号定义4.2.2.3. AHB的数据传输过程及“流水线”4.2.2.4. AHB的突发传输4.2.2.5. AHB的译码4.2.2.6. AHB的仲裁4.2.2.7. AHB主机接口及时序参数4.2.2.8. AHB从机接口及流水线分离4.2.3. AXI总线4.3. 系统总线/外部总线4.3.1. PCI4.3.2. PCI Express4.3.3. USB4.3.4. 典型的计算机总线系统4.4. 输入/输出接口4.4.1. 输入/输出接口概述4.4.1.1. I/O接口的功能4.4.1.2. I/O接口的分类4.4.1.3. I/O接口规范的常规内容4.4.1.4. I/O接口的结构4.4.1.5. I/O端口编址4.4.2. 输入/输出接口的数据传送方式4.4.2.1. 无条件传送方式4.4.2.2. 查询传送方式4.4.2.3. 中断传送方式4.4.2.4. 直接存储器访问(DMA)方式4.4.3. 并行接口4.4.3.1. 无握手信号的并行接口4.4.3.2. 带握手信号的并行接口4.4.3.3. 可编程并行接口(GPIO)4.4.4. 串行接口4.4.4.1. 串行接口概述4.4.4.2. 异步串行接口4.4.4.3. I2C接口及总线4.4.4.4. SPI接口及总线5. ARM处理器体系结构和编程模型5.1. ARM体系结构与ARM处理器概述5.1.1. 指令集体系结构与微架构5.1.2. ARM处理器体系结构简介5.1.3. ARM处理器主要产品系列简介5.1.3.1. ARM处理器的特点5.1.3.2. ARM处理器相关产品的层次关系5.1.3.3. ARM处理器产品命名规则5.1.3.4. ARM7系列5.1.3.5. ARM9系列5.1.3.6. ARM11系列5.1.3.7. Cortex-A5.1.3.8. Cortex-R5.1.3.9. Cortex-M5.2. Cortex-M3/M4处理器结构5.2.1. Cortex-M3/M4处理器概述及指令集架构5.2.1.1. Cortex-M3/M4主要特性5.2.1.2. Cortex-M3/M4所支持的指令集5.2.2. Cortex-M3/M4处理器结构5.2.2.1. 内核5.2.2.2. 处理器5.2.2.3. 处理器系统5.2.3. 存储器管理5.2.3.1. 存储器管理特性5.2.3.2. 存储器映射5.2.4. 总线系统5.2.4.1. 总线系统结构5.2.4.2. 各类总线的连接对象5.2.5. 异常与中断处理5.2.5.1. 嵌套向量中断控制器NVIC5.2.5.2. 中断向量表5.2.5.3. 系统节拍定时器SysTick5.3. Cortex-M3/M4的编程模型5.3.1. 操作状态与操作模式5.3.1.1. 操作状态5.3.1.2. 操作模式和特权等级5.3.2. 常规寄存器5.3.2.1. 通用寄存器:R0~R125.3.2.2. 栈指针:R135.3.2.3. 链接寄存器:R145.3.2.4. 程序计数器:R155.3.3. 特殊寄存器5.3.3.1. 程序状态寄存器5.3.3.2. 三个中断屏蔽寄存器5.3.3.3. CONTROL寄存器5.3.3.4. 系统控制块SCB5.3.4. 堆栈结构5.3.4.1. 堆栈的作用和堆栈类型5.3.4.2. Cortex-M处理器的堆栈模型5.3.4.3. Cortex-M3/M4处理器中的双堆栈5.4. Cortex-M处理器存储系统5.4.1. 存储器映射5.4.2. 连接存储器和外设5.4.3. 存储器的端模式5.4.4. 非对齐数据的访问5.4.5. 位段操作5.4.5.1. 位段与位段别名5.4.5.2. 位段操作的优点5.4.5.3. C程序实现位段操作5.4.6. 存储器访问权限5.4.7. 存储器访问属性5.4.8. 排他访问5.4.9. 存储器屏障5.4.10. MCU中的存储器系统5.5. Cortex-M处理器的异常处理5.5.1. Cortex-M异常管理模型5.5.1.1. 异常类型5.5.1.2. 异常状态5.5.1.3. 异常处理程序5.5.1.4. 异常向量表5.5.1.5. 异常的优先级5.5.1.6. 中断优先级分组5.5.1.7. 异常流程5.5.2. 向量表重定位机制5.5.3. 中断请求和挂起5.5.4. NVIC寄存器5.5.4.1. 中断的使能和禁止5.5.4.2. 中断挂起和中断清除5.5.5. SCB寄存器6. ARM指令系统6.1. ARM处理器指令集概述6.1.1. ARM的不同指令集6.1.2. ARM指令集扩展6.2. T32指令格式6.2.1. 16比特指令二进制格式6.2.2. 32比特指令二进制格式6.2.3. T32指令的汇编语法6.2.4. T32的条件执行指令6.2.5. T32指令格式示例6.3. T32指令集寻址方式6.3.1. 立即数寻址6.3.2. 寄存器寻址6.3.3. 寄存器间接寻址6.3.4. 寄存器移位寻址6.3.5. 寄存器偏移寻址6.3.6. 前变址寻址6.3.7. 后变址寻址6.3.8. 多寄存器寻址6.3.9. 堆栈寻址6.3.10. PC相对寻址6.4. Cortex-M3/M4指令集6.4.1. 处理器内的数据传送指令6.4.2. 存储器访问指令6.4.3. 算术运算指令6.4.4. 逻辑运算指令6.4.5. 移位运算6.4.6. 数据格式转换6.4.7. 位域处理指令6.4.8. 比较和测试指令6.4.9. 程序流控制指令6.4.9.1. 无条件跳转和函数调用指令6.4.9.2. 条件跳转6.4.9.3. 比较和跳转6.4.9.4. 条件执行6.4.9.5. 按跳转表跳转6.4.10. 饱和运算6.4.11. 其他杂项指令6.4.11.1. 休眠模式指令6.4.11.2. 异常相关指令6.4.11.3. 空指令和断电指令6.4.12. Cortex-M4特有指令7. ARM程序设计7.1. ARM程序开发环境7.1.1. 常用ARM程序开发环境7.1.2. MDK开发环境简介7.2. ARM汇编程序中的伪指令7.2.1. 符号定义伪指令7.2.2. 数据定义伪指令7.2.3. 汇编控制伪指令7.2.4. 其他常用的伪指令7.2.5. 汇编语言中常用的符号7.2.6. 汇编语言中常用运算符和表达式 7.3. ARM汇编语言程序设计7.3.1. ARM汇编语言的语句格式7.3.2. ARM汇编语言程序结构7.3.3. ARM汇编程序设计实例7.4. ARM汇编语言与C/C++的混合编程7.4.1. C语言与汇编语言之间的函数调用7.4.2. C/C++语言与汇编语言的混合编程8. 基于ARM微处理器硬件与软件系统设计开发8.1. 嵌入式硬件与软件系统设计与开发综述8.1.1. 概述8.1.2. 嵌入式生态系统8.1.3. 开发环境、开发工具和调试方式8.1.4. 嵌入式系统开发过程8.2. ARM内核常用微处理器8.2.1. 三星S3C2440A8.2.2. 恩智浦LPC21328.2.3. 意法半导体STM328.3. 最小硬件系统8.3.1. 微处理器最小硬件系统8.3.2. S3C2440A最小硬件系统8.3.3. STM32最小硬件系统8.3.4. MCU及其周围电路设计8.3.4.1. 电源电路8.3.4.2. 复位电路8.3.4.3. 时钟电路8.3.4.4. 调试和下载电路8.3.4.5. 启动电路8.3.4.6. 启动代码和启动过程8.4. 嵌入式软件系统设计8.4.1. 系统结构及工作流程8.4.2. 嵌入式操作系统8.4.3. 程序开发模式8.4.4. 软件开发流程8.5. ARM中的GPIO8.5.1. 概述8.5.2. 工作原理8.5.2.1. 内部结构8.5.2.2. 工作模式8.5.2.3. 输出速度8.5.2.4. 复用功能重映射8.5.2.5. 外部中断映射和事件输出8.5.2.6. STM32F10x的GPIO主要特性8.5.3. 相关库函数及寄存器8.5.3.1. 库函数8.5.3.2. 常用寄存器8.5.3.3. AFIO寄存器8.5.4. 应用与举例8.6. 定时器8.6.1. 概述8.6.2. 基本定时器TIM6和TIM78.6.2.1. 内部结构8.6.2.2. 时钟源8.6.2.3. 计数模式8.6.2.4. 基本工作原理8.6.2.5. 主要特性8.6.3. 通用定时器TIM2~TIM58.6.3.1. 内部结构8.6.3.2. 时钟源8.6.3.3. 计数模式8.6.3.4. 普通输入捕获模式8.6.3.5. PWM输入捕获模式8.6.3.6. 比较输出模式8.6.4. 高级定时器TIM1和TIM88.6.5. 主从模式、触发与同步8.6.5.1. 主从模式8.6.5.2. 触发8.6.5.3. 从模式下的工作模式8.6.5.4. 定时器级联及同步8.6.6. 相关库函数及寄存器8.6.6.1. 库函数8.6.6.2. 常用寄存器8.6.7. 小结及应用要点8.6.7.1. 定时器配置要点8.6.7.2. PWM程序实现步骤8.6.7.3. PWM程序实现的3个要点8.7. 中断控制器8.7.1. 中断系统综述8.7.1.1. 嵌套向量中断控制器NVIC8.7.1.2. 中断优先级8.7.1.3. 中断向量表8.7.1.4. 中断服务函数ISR8.7.1.5. 中断设置过程8.7.2. 外部中断/事件控制器EXTI8.7.2.1. 内部结构8.7.2.2. 工作原理8.7.3. 相关库函数及寄存器8.7.3.1. 库函数8.7.3.2. 常用寄存器8.7.4. 小结及应用要点8.8. USART8.8.1. 主要特性8.8.2. 内部结构8.8.3. USART中断8.8.4. 相关库函数及寄存器8.8.4.1. 库函数8.8.4.2. 常用寄存器8.8.5. 小结及应用要点8.8.5.1. 库函数开发STM32F103外设过程8.8.5.2. STM32F10x标准外设库函数的分类和命名8.8.5.3. USART配置的一般步骤8.8.5.4. 注意事项8.9. SPI8.9.1. SPI工作原理8.9.1.1. 主要特性8.9.1.2. 内部结构8.9.1.3. SPI主模式8.9.1.4. SPI从模式8.9.1.5. SPI状态标志和中断8.9.1.6. SPI发送/接收数据8.9.2. SPI相关库函数及寄存器8.9.2.1. 库函数8.9.2.2. 常用寄存器8.9.3. SPI小结与应用要点8.10. I2C8.10.1. I2C工作原理8.10.1.1 主要特性8.10.1.2. 内部结构8.10.1.3. I2C主/从模式8.10.1.4. I2C中断8.10.2. I2C相关库函数及寄存器8.10.2.1. 常用库函数8.10.2.2. 初始化结构体8.10.2.3. 典型库函数8.10.3. I2C小结及应用要点附录中英文术语对照表
复习大纲
概述
计算机系统的基本结构与工作原理
存储器系统
总线和接口
ARM处理器体系结构
ARM处理器指令系统
ARM程序设计
基于ARM微处理器硬件与软件系统设计开发
附录
中英文术语对照表
1. 概述
1.1. 计算机的发展简史
1.1.1. 计算机的诞生
布莱兹·帕斯卡(Blaise Pasca):基于齿轮结构的机械加减法器
莱布尼茨(Gottfried Wilhelm Leibniz):可进行乘法、除法和自乘运算的机械计算器
查尔斯·巴贝奇(Charles Babbage):基于齿轮结构的差分机和分析机
阿兰·图灵(Alan Turing):图灵机
莫克利(John Mauchly)、艾克特(Eckert)团队:ENIAC(电子数字积分器和计算器)
- 世界上第一台数字式电子计算机
冯诺依曼(Von Neumanm):EDVAC(离散变量自动电子计算机)
确定计算机五个构成部分:运算器,控制器,存储器,输入设备,输出设备
三方面重大改进
- 二进制
- 存储程序
- 程序执行顺序可通过“条件转移”指令自动完成
莫里斯·威尔克斯(Maurice Wilkes):EDSAC
- 第一台存储程序式电子计算机
1.1.2. 现代计算机发展历程
第一阶段: 电子管阶段 (1946至20世纪50年代中期)
- 计算机体积庞大,功耗大,可靠性低,售价昂贵
- 主要用在重要场合的科学计算和数据处理
第二阶段: 晶体管时代 (1955至20世纪六十年代中期)
- 内存采用磁芯,外存采用磁带或磁鼓,减小体积,降低功耗,提高可靠性,降低成本
- 运算速度提高,出现了高级程序设计语言(FORTRAN, Algol),计算机开始进入工业过程控制领域
第三阶段: 集成电路时代 (1965至20世纪七十年代初期)
- 计算机体积进一步减小,可靠性进一步提高,成本进一步降低,速度大大提高(IBM 360系列计算机)
- 操作系统逐渐成熟,应用扩大
第四阶段: LSI & VLSI时 (1972~1990)
- LSI和VLSI得到广泛使用,内存普遍采用半导体存储器,外存采用磁盘、磁带和光盘
- 体积进一步缩小,性能和可靠性进一步提高,成本进一步降低
- 应用日益广泛,PC机成为办公和娱乐设备
第五阶段: ULSI & GSI时代 (1991年至今)
- 流水线、超标量、多线程、多内核、多CPU和新型高速总线技术使得普通PC机的速度可达每秒数十亿次
- 更加注重多媒体信息和并行数据处理能力
- 单片机和嵌入式系统性能不断提高,应用领域不断扩大
- 现代计算机是云计算、大数据、物联网、移动互联网和人工智能等技术发展的最重要基础
1.1.3. 计算机的类型
微型计算机
- 台式计算机
- 个人工作站
- 笔记本电脑
- 平板电脑
服务器
具有较强大计算能力,可通过网络为大量用户提供计算、信息处理和数据存储服务,用于大型企事业单位和政府机构的信息处理服务。可分为:
采用Unix操作系统的小型机(服务器)
- 具有高可靠性和高可用性,数据处理能力较强
- 多为基于RISC架构的国外品牌
采用Intel架构的x86服务器
- 支持Linux或者微软视窗操作系统
- 出色的性价比,国产化程度高
嵌入式计算机
- 集成到应用对象中的专用计算机,以自动监测与控制应用对象的物理过程
- 服务与特定目的,不属于通用计算机
- 典型应用:工业自动化、智能家居、通信设备、数码产品、交通工具、安防、军工等
超级计算机
- 提供最高的计算性能,最昂贵、物理上最大型的计算机
- 广泛用于复杂过程仿真等科学计算领域
1.2. 计算机系统的组成
计算机硬件: 构成计算机的物理部件
计算机软件: 按特定顺序组织的指令和数据集合
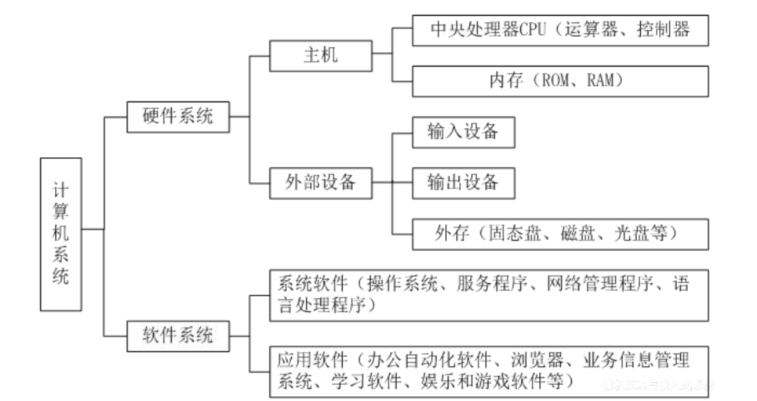
1.2.1. 计算机硬件
1.2.1.1. 存储器
主存储器
- 简称主存或内存,由半导体材料构成,每个单元存储1位二进制信息,单位为1个比特(bit)
- 8bit组成1个字节(Byte)
- 字节是存储器存储和读取数据的基本单位,每个字节都有唯一的物理地址(PA)
- 若干字节构成一个字,每个字所包含的位数称为计算机的字长
- 典型的字长有16位、32位和64位
辅助存储器
主存特点:读写速度相对较快,价格高、容量受限、掉电后RAM存储的信息消失
辅存特点:读写速度慢,价格低,容量大、具有非易失性,又称为外存
常见外存包括:
- 基于磁介质极化的磁盘和磁带
- 基于表面几何微观形状的光盘 (CD, DVD, BD)
- 基于半导体的闪存
1.2.1.2. 运算器
主要功能: 完成各种数据运算和处理
核心构成: 算术逻辑单元ALU和寄存器阵列
ALU:在控制信号的作用下完成任意的算术或逻辑运算 (加、减、乘、除、移位或比较大小等)
寄存器: 运算器内部的高速存储单元,访问速度最快
- 受芯片面积限制,寄存器的数量不会很多
- 运算器工作时,需要处理的数据(操作数)先被送到某个寄存器中暂存
- 运算过程中的临时数据或者处理后的结果也暂存在特定的寄存器中
1.2.1.3. 控制器
计算机的指挥控制中心
主要功能: 根据指令对计算机各部件进行操控,协调各部件有序工作
主要构成:
- 指令寄存器IR
- 指令译码器ID
- 操作控制器OC
VLSI出现后,运算器和控制器被集成到CPU中
CPU与主存是计算机的核心部分
1.2.1.4. 输入设备
主要功能:将信息进行编码后输入计算机
最常见输入设备: 键盘和鼠标
用于人机交互的输入设备:
- 触摸屏、操纵杆、轨迹球、麦克风、游戏机手柄……
其他输入设备
- 扫描仪、证件读卡器、摄像头等
1.2.1.5. 输入设备
- 主要功能: 向外界输出计算机处理后的结果
- 有些兼具输入和输出功能,如触摸屏和计算机通信设备,简称I/O设备,外存也可以看作是一种I/O设备
- 特点: 种类繁多、信息格式各异、速度快慢不一
- 慢速设备:打印机、绘图机、扬声器、……
- 高速设备:外存、数据通信设备、超高清显示器、数字波形合成器、……
1.2.1.6. 适配器
主要功能: 在计算机与和外设之间进行桥接和匹配,解决种类繁多、速度快慢不一、信息编码格式各异的输入输出设备的互连问题
- 数据缓冲,解决速度不匹配问题
- 信息转换,解决编码格式不同的问题
- 电平转换,解决电平不一致问题
- 状态监测,收发双方的相互沟通
- 时序控制,协调外设和主机并行工作
适配器又称I/O接口
多个不同种类的外设,需要多个接口
常见的外设接口:并行接口、I2C接口、串行接口和USB接口
1.2.1.7. 总线
主要功能: 实现各部件之间的信息传输和交换
按用途分三类:
- 数据总线DB:双向
- 地址总线AB:单向
- 控制总线CB:有些单向有些双向

1.2.2. 计算机软件
1.2.2.1. 计算机软件分类
按特定顺序组织的计算机数据和指令的集合,可分为:
系统软件
- 控制和管理计算机工作并且无需用户干预的各种程序集合。主要功能是调度、监控和维护计算机运行,管理各种部件,协调各种资源
- 系统软件的核心是操作系统,负责管理硬件与软件资源、控制I/O设备和网络、维护文件系统、提供用户接口UI
应用软件
- 利用计算机解决特定问题而编程开发的各种程序
中间件软件
- 处于计算机系统软件与用户应用软件之间,是分布式应用系统的基础软件
- 为上层应用软件提供开发、集成和运行环境,并实现应用软件之间的互操作
- 通过网络通信功能解决分布式环境下数据传输、数据访问、应用调度、系统构建、系统集成和流程管理等问题,是分布式环境下支撑应用开发、运行和集成的平台
- 核心思想:抽取分布式系统对于数据传输、信息系统构建与集成等问题的共性要求,封装共性问题的解决方法,对外提供简单统一的接口,从而减少系统开发难度,优化系统结构和提高系统的开发效率
1.2.2.2. 计算机软件的发展
第一代 1846~1953
- 机器语言
- 汇编语言
第二代 1954~1964
- 算法语言
- Fortran
- LISP
- ALGOL
- BASIC
第三代 1965~1970
- 多用户多任务操作系统
- 数据库技术
- 软件工程
第四代 1971~1989
- 结构化程序设计思想
- PASCAL
- C语言
- 多媒体技术
第五代 1990~至今
- GUI和OA软件
- 面向对象技术
- 万维网
- 分布式架构
- API
- 软件定义一切
1.3. 计算机中数的表示方法
1.3.1. 进位计数制
10进制
- 后缀为D
- 基数为10
二进制
- 后缀为B
- 基数为2
16进制 (两位16进制表示1字节)
- 后缀为H或h
- 基数为16
位、字节、字和字长
- 位=比特,计算机存储数据的最小单位
- 字节Byte,用B表示,一个字节=8个二进制位 (1 Byte=8 bit),字节是计算机存储和读取数据的基本单位
- 字:计算机进行数据处理时一次存取、加工和传送的数据长度,一个字=多个字节
- n 位计算机的字长为n bit (位)
1.3.2. 有符号数的原码、反码和补码表示
原码
约定: 数值的原码记为,若机器(处理器)字长为位,那么数值的原码定义为:
最高位为符号位:0为正数,1为负数,其余为绝对值
n bit原码可表示的数值范围是:
例:8位有符号二进制数:
原码表示的0有正负之分,习惯上将0用+0表示
原码存在的问题:原码表示的有符号数在运算时会出现错误 (原因:在运算过程中,符号位也参与了运算)
反码
约定:数值的反码记为,若机器(处理器)字长为位,那么数值的反码定义为:
n bit反码可表示的数值范围为:
整数的反码与原码相同;负数的反码符号位为1,其余各位与原码相反
反码表示的0有正负之分,习惯上将0用+0表示
使用反码表示数据,在运算时符号位也参与运算,故计算机未采用反码
补码
约定:数值的补码记为,若机器(处理器)字长为位,那么数值的补码定义如下:
正数的补码与原码完全相同
负数的补码用模的补数的二进制编码表示
- 求一个负数的补码时,可先求出该负数的反码,然后加1即可
- 另一种方法,求负数绝对值的原码,然后从低位向高位扫描,将遇到的首个1以及之前的0保持不变,对之后的各位按位取反
补码运算
对于有符号数和有:
采用补码运算的前提:结果不能发生溢出(结果超出了补码所能表示的范围)
结论:若记符号位向前进位为CP,次高位向前进位为CF,当且仅当时,结果发生溢出
推论:
- 若参加运算的二进制数被看成无符号数,没有符号位,加减运算结果可能会有进位或借位,没有溢出问题
- 若参加运算的二进制数被看成有符号数,运算结果受到最大表示范围的限制,超出则出现溢出,结果错误
- 有符号数运算必须判断是否出现溢出,如果出现溢出只能重新设计算法
1.3.3. 定点数和浮点数
定点数:采用定点格式表示的数据,能够表示的数值范围较小,所需的硬件电路较简单
- 定点格式:小数点位置固定不变,无需再用符号表示
- 现代计算机中多采用定点纯整数,定点数称为整数
浮点数:采用浮点格式表示的数据,可以表示的数值范围很大,所需的硬件电路较复杂
浮点格式:有效数字和数值范围(比例因子)分别表示,小数点位置将随比例因子不同在一定范围内浮动
任意一个二进制数也可以表示为:
- —浮点数尾数,—浮点数阶码
IEEE-754规定的浮点数格式

1.3.4. 其他信息编码
BCD编码
4位二进制表示1位十进制数,最常用的是8421 BCD码,简称BCD码
例如:10进制数135,其BCD码位0001 0011 0101
计算机以字节为基本存储单位,有两种BCD码表示方法
压缩BCD码:一个字节表示2位十进制数
- 例如:十进制数89D的压缩BCD码为:1000 1001B
非压缩BCD码:一个字节仅用来表示一位BCD码,其中低4位表示0~9,高4位为0
- 例如:十进制数89D的非压缩BCD码需要使用两个字节:0000 1000B和0000 1001B
存在的问题
每4位二进制数可以表示成16种状态,但是BCD码只使用其中的10个,二进制数状态空间利用率低
计算机对数据运算均按照二进制运算规则将带来问题
例如:7+5用非压缩BCD码计算
错误原因:使用二进制运算法则计算BCD码
解决方法:BCD码运算后必须对结果进行调整
ASCII码——美国信息交换标准代码
ASCII等同于国际标准的7单位制IRA码
用于给西文字符编码,由7位二进制数组合而成,可以表示128种字符
在ASCII码中,按其作用可分为
- 34个控制字符
- 10个阿拉伯数字
- 52个英文大小写字母
- 32个专用符号
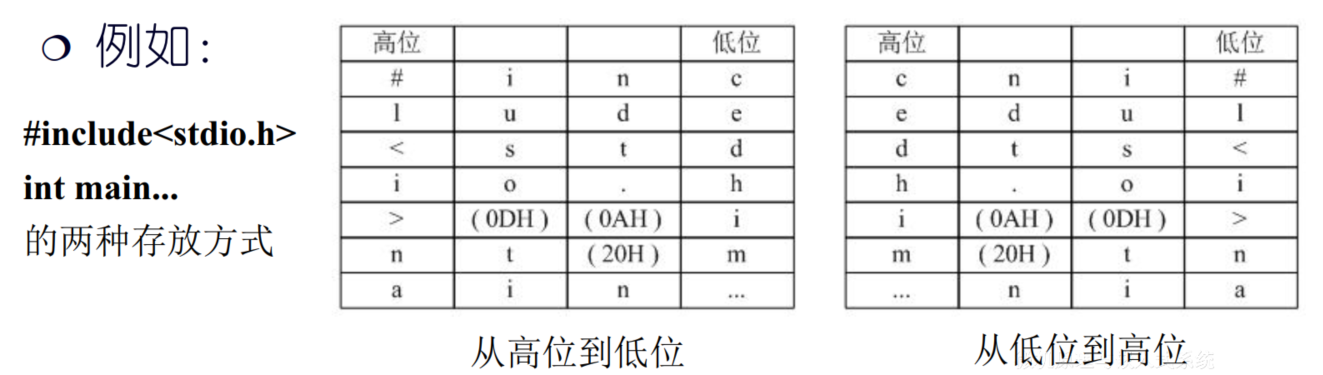
字符串表示方法
字符串:一串连续字符,在内存中占用连续多个字节,每个字节存放一个字符
字长为多字节的计算机,一个字可存放多个字符
不同类型的计算机,一个字有两种字符存放顺序
- 第一种:从高位字节向低位字节顺序存放
- 第二种:从低位字节向高位字节顺序存放
1.4. 嵌入式系统简介
1.4.1. 嵌入式系统的基本概念
Embedded System:嵌入式计算机系统的简称
IEEE定义:嵌入式系统是用于控制、监视或者辅助设备、机器和车间运行的装置
中国大陆定义:以应用为中心、以计算机技术为基础,软件硬件可裁剪,适应应用系统对功能、可靠性、成本、体积、功耗严格要求的专用计算机系统
三个特点:嵌入性、专用性和计算机系统
嵌入性的两层含义:
- 本系统是嵌入另一个目标大系统中,成为目标系统的一个组成部分,并为实现目标系统的功能提供特定服务
- 提供特定服务的软件代码也嵌入目标系统中
1.4.2. 嵌入式系统的硬件
主要包括:
嵌入式微处理器(核心)
- 有MPU,MCU,DSP和SOC之分
存储器(外存多采用半导体非易失存储器,如flash)
嵌入式外围设备
I/O接口
嵌入式微处理器 (EMPU)
原理和功能和通用微处理器相同
MPU没有存储器和外设接口 (MPU的特征)
使用MPU构建嵌入式系统需要外接存储器和I/O接口芯片
如果所有器件安装在一块主板上—单板机
单板机特点:
- 与传统工控机相比,集成度高、成本低、功耗小和可靠性高
- 板上芯片、总线、结构呈裸露状态,技术保密性差
嵌入式微控制器 (EMCU)
- 将计算机的主要部件,如ROM、RAM、总线控制逻辑和中断控制器,以及可能需要的定时/计数器,并/串接口、看门狗、ADC和DAC等集成在一块芯片上,构成一个功能相对完整的计算机系统,又称为单片机
- 特点:集成度高,产品开发周期短,成本低廉,功能丰富,功耗小和可靠性高
数字信号处理器 (DSP)
通过内部硬件电路和专门的DSP指令,快速实现各种高强度数字信号处理,广泛用于数字滤波、信号特征分析、电子对抗、音视频编/解码等领域
有非嵌入式和嵌入式、定点和浮点之分
- 非嵌入式:独立的芯片,需要与其他处理器通过总线互连,具有较高的处理能力
- 嵌入式:作为一个功能部件,被集成到MCP中
- 定点DSP的运算精度稍差,但是功耗小,成本低
- 浮点DSP的运算精度高,但是功耗大,成本高
片上系统 (SOC)
- 将一个复杂系统集成在一块硅片上
- 如果将设计后的系统下载到FPGA上,就形成了SOC的另一种形式SOPC
- 特点:应用系统集成度高,技术保密性强,功耗低,工作可靠
1.4.3. 嵌入式系统软件
分为嵌入式操作系统和嵌入式应用软件
嵌入式操作系统
- 实时性:在规定的时间内准确地完成应该执行地操作
- 可靠性:也称为可依赖性或者可信任性
- 可裁剪:可根据需求进行功能模块配置
应用软件
- 围绕特定应用需求开发,许多简单应用无需操作系统
- 复杂应用软件需要嵌入式操作系统支持
- 逻辑准确、时间确定、运行可靠、减少硬件资源开销
1.4.4. 嵌入式系统的发展概况
第一个嵌入式处理器:Intel 4004
嵌入式系统发展的四个阶段:
- 以MPU为核心的可编程控制器,无操作系统
- 以MCU为核心的嵌入式系统,出现了简单的操作系统
- 32位高性能MCU大量涌现,嵌入式操作系统开始成熟,内核精致,效率高,兼容性较好,可提供文件管理、多任务支持和网络接口等功能
- 与Internet深度融合,嵌入式系统是物联网的主要基础
1.4.5. 典型嵌入式处理器简介
ARM
Advanced RISC Machines:全球最大的IP供应商
体系架构版本先后有ARMv1~v8,从v4开始成熟,从v8开始升级到64位,版本号与产品名称之间的关系较为复杂
早期产品:ARM7、ARM9和ARM11等系列
v7版本以后产品名称改用Cortex,有CortexA、M和R三大系列,分别适用不同的应用需求
- A系列:Application,高性能处理器
- M系列:MCU,针对价格和功耗敏感应用
- R系列:RealTime,针对有实时性要求的应用
MIPS
- Microprocessor without Interlocked piped stages:第二大IP供应商
- 设计理念:强调软硬件协同提高性能,简化硬件设计
- 嵌入式处理器非常小巧
2. 计算机系统的基本结构与工作原理
2.1. 计算机系统的基本结构与组成
2.1.1. 计算机的层次模型
分层目的:分析计算机各个部件之间的逻辑关系
层次模型发展历程:
最初阶段:只有两层
- 硬件层:逻辑电路
- 软件层:指令系统

第二阶段:微程序 vs RISC
微程序设计思想 → 三层模型
- 一条指令可以分解为多个微操作
- 微操作可以用微指令实现
- 多条微指令组成微程序实现指令功能
- 微程序存储在控制ROM中,执行时逐条读出完成微操作

微程序
微程序简化了控制器硬件,并可实现复杂指令
增加新指令,引入新的寻址方式,导致
- 芯片中的器件数量增加
- 芯片功耗不断增大
- 而计算机性能与电路规模不成比例
RISC
二八定律
- 80%的时间运行的是占总量不到20%的简单指令
- 80%的任务是由占总量不到20%的电路完成的
为提高性能,应该:
- 减少指令数量,一条复杂指令用多条简单指令替代
- 取消微程序,指令功能由硬件电路(硬核)实现
第三阶段:操作系统
- 早期计算机没有操作系统,必须“手工”对计算机进行管理,如任务调度、内存管理、I/O控制等
- 第一个真正的操作系统:1964年可运行在不同规格的IBM System/360系列大型机的OS/360
- 操作系统负责管理计算机硬件资源和用户作业,提供了人机交互界面、多条用户命令和多种子程序调用接口,极大简化了计算机操作、管理的复杂性
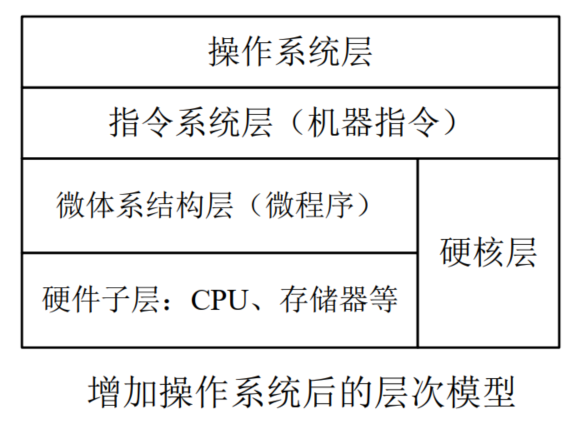
第四阶段:编程语言
- 使用各种语言编写的程序,必须经过相应的编译(或解释)程序进行处理后,计算机才能识别和执行
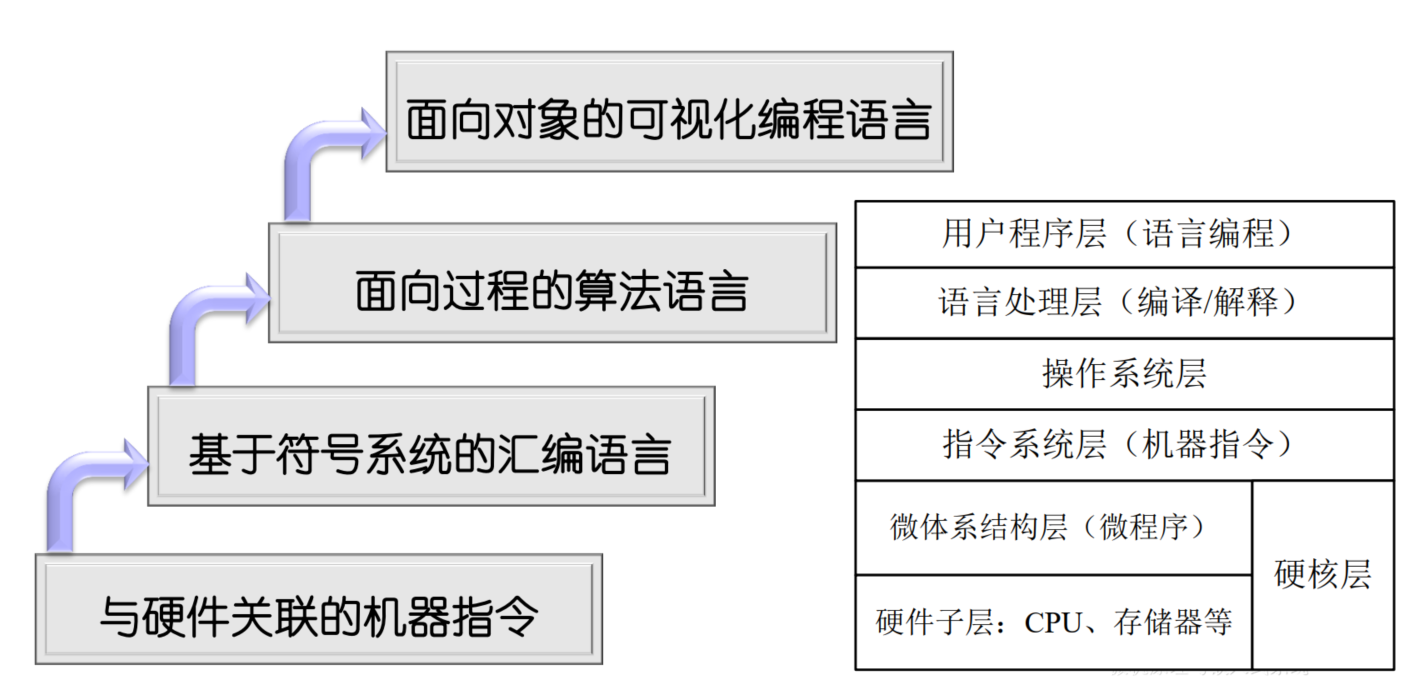
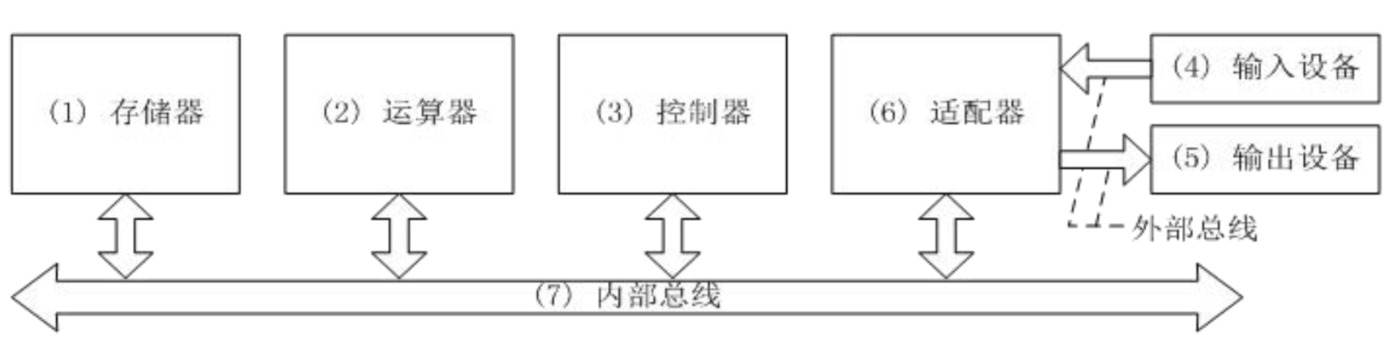
2.1.2. 基于冯诺依曼架构的模型机系统结构
结构特点:
- 以CPU为核心(现代计算机逐步转化为以存储器为核心)
- 单总线系统(类似于快慢车道不分的混合式交通)
- 指令和数据使用同一条总线(冯诺依曼架构的主要缺陷)
2.2. 模型机存储器子系统
2.2.1. 存储器的组织和地址
每个字节拥有一个独一无二的物理地址(PA),字节是计算机可访问的最小存储单元
字节寻址存储器:按照字节组织存储器,连续地址对应于连续的字节单元(存储器按照字节组织)
- 如果计算机的字长是8位,总线宽度也为8位,CPU访问存储器时,总线一次可以传送一个字节数据
- 字节单元地址有n, n+1, n+2, ...
- 若模型机字长为32位,一个字有4个字节,连续的字被分配到n, n+4, n+8, ...中
计算机的分体结构:
问题描述:若总线宽度为16位、32位或64位,CPU访问存储器时,为一次能够传输一个完整的字(2/4/8字节),或根据需要一次传送这个字中的一部分字节,应如何组织存储器和连接存储器与总线?
以32位模型机为例,总容量为232的存储器分成4个存储体,每个存储体为230,分别与32位数据总线按下图连接,每个存储体只需30条地址线,用字节选择信号进行选择

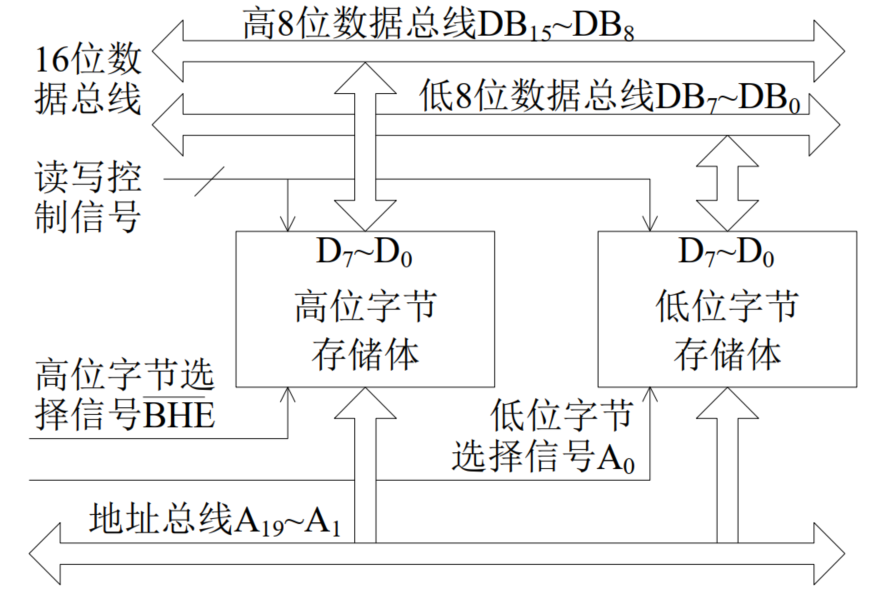
Intel 8086系统存储器的分体结构
Intel 8086数据总线位宽为16位,地址总线位宽为20位
- 总容量为1MB的存储系统分成2个512KB的存储体
- 高位和低位字节存储体分别连接DB的高8位和低8位
- 和为存储体选择信号
- 有效(低电平)选中高字节存储体;选择低字节存储体;都有效同时选中两个存储体
2.2.2. 字的对齐——对准存放
8位计算机没有对准存放问题
对准存放:
- 16位机的字起始地址应该是2的倍数,如0、2、4……
- 32位机的字起始地址应该是4的倍数,如0、4、8……
- 64位机的字起始地址应该是8的倍数,如0、8、16……
对准存放不是必须的,但如果采用对准存放,存取一个字只需要一次总线操作即可完成
2.2.3. 小端格式和大端格式
假设由,,和组成,是最高字节,是最低字节,存储需使用4个地址连续的内存单元
对于地址依次为、、和的连续4个存储单元,单元地址最小,称为尾部;单元地址最大,称为头部

有两种存放格式:
- Intel x86采用小尾或小端格式
- Motorola采用大尾或大端格式
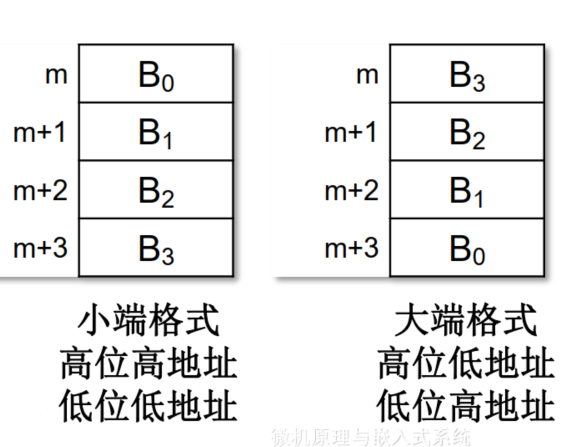
如果采用对准存放,是整个字的地址
现代许多CPU兼容大端格式和小端格式,如:ARM处理器默认小端格式,但可通过硬件引脚或者指令选择大端格式
2.2.4. 存储器操作
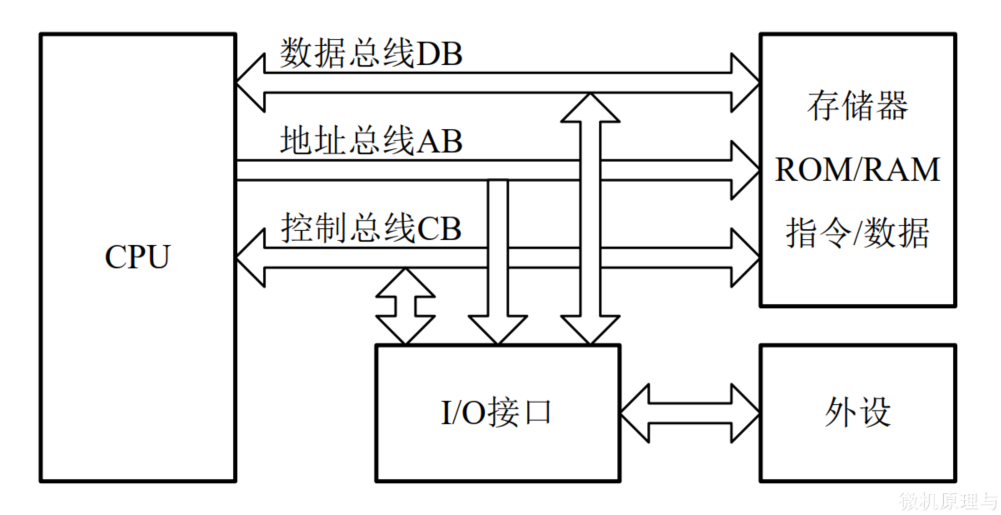
计算机运行时所需的指令和数据都存放在存储器中。一条指令在执行之前必须将这条指令完整地从存储器取出并传送到CPU中;指令执行时所需的操作数和操作结果有时也需要在CPU和存储器之间进行传送
两个最基本操作:读出和写入
读操作
作用:将一个指定内存单元的内容读出并传送到CPU中
特点:读操作之后存储单元的内容保持不变
过程:
- 读操作开始时,CPU通过地址总线AB向存储器发送指定存储单元的地址,并通过控制总线CB向存储器发出读命令
- 被选中的存储单元的内容则被读出并送上数据总线DB
- CPU在时序信号的控制下,采样DB上的数据并存入内部,完成一次读操作
写操作
作用:从CPU中向一个指定存储单元传送一条数据
特点:传送的数据将覆盖目的单元中原有的内容
过程:
- 写操作开始时,CPU通过地址总线向存储器发送目的存储单元的地址,通过数据总线传送所需写入的内容
- 通过控制总线向存储器发送写命令
- 数据总线上的数据被写入存储器指定单元,完成一次写操作
连续数据读写
- 只需在第一次读写时发送地址
- 对于地址连续的数据块,只需告知存储器本次传送是数据块传送、一次读写的字节数和地址修改的方向,存储器即可推断出下一次读写操作的地址,无需CPU再次重复发送
2.2.5. 存储器的分级
对存储器的要求:速度快、容量大、成本低
分级存储体系结构
使用外存满足大容量、低成本和非易失的要求
使用DRAM型内存,兼顾容量、速度和成本
使用高速缓存,减少CPU访问内存的开销
- 高速缓存(Cache):位于CPU与内存之间,SRAM型小容量快速存储器,用于存放CPU最近使用过或者可能要使用的指令和数据

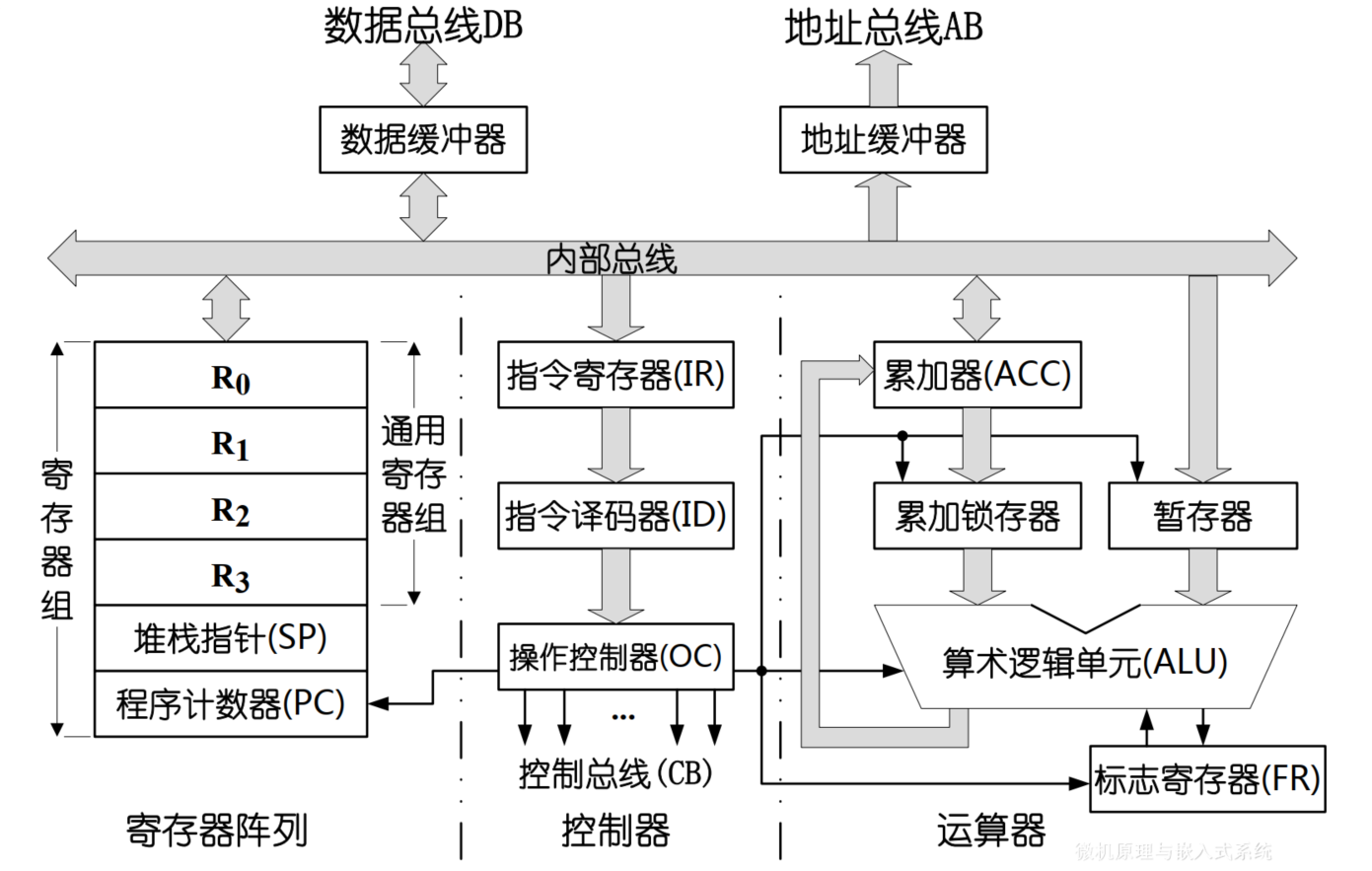
2.3. 模型机CPU子系统
模型机CPU内部结构:
2.3.1. 运算器
基本组成
- 算术逻辑单元 (ALU)
- 累加器 (ACC)
- 标志寄存器 (FR)
- 暂存寄存器
算术逻辑单元ALU:运算器的核心
- 作用:负责运算,也是数据传送的一条重要途径
- 组成:带有先行进位功能的全加器(简称加法器)、移位寄存器以及相应的控制逻辑
- 加法器是ALU最主要的部件,所有二进制算术运算都可通过加法和移位来实现
累加器ACC:特殊寄存器
- 提供需要送入ALU的操作数,存储ALU的计算结果
- 早期的CPU只有一个ACC,因ACC与ALU之间密不可分,常被划分到运算器中,不属于通用寄存器组
- 现代CPU中有很多通用寄存器都可以当作累加器来使用
- ACC下方的累加锁存器:其作用是防止ALU的输出经ACC再反馈到ALU的输入端
暂存器
- 暂时存放需要送入ALU的操作数,但不存放计算结果
- 暂存器是透明的,程序员不可见
标志寄存器:也称为程序状态寄存器
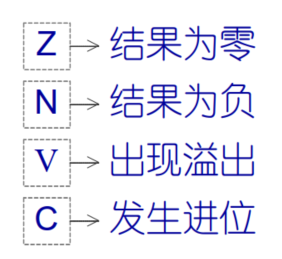
标志寄存器的内容称为程序状态字PSW,PSW分为状态标志位(条件码标志位)和控制标志位
状态标志位:记录ALU运算后的状态或者特征
如:结果是否为零?是否为负数?是否有溢出?是否有进位?
后续指令可根据状态标志决定程序执行顺序
例如:
ARM处理器的程序状态寄存器(PSR)中有4个状态(条件码)
Intel 8086中还有辅助进位位A和奇偶校验位P(P现已不用)
后续指令可根据这些状态标志决定程序是顺序执行还是跳转执行
控制标志位:是对CPU的某些行为进行控制和管理
Intel 8086的标志寄存器中有3个控制标志位
- D(Direction):串操作的地址改变方向 (D=1 → 地址减量)
- I(Interrupt):是否允许外部中断(I=1 → 允许中断)
- T(Trap):单步中断(T=1 → 单步中断)
Intel 8086提供了对D和I进行单独操作的指令,如
- STI:将I置位为1,允许外部可屏蔽中断,亦称开中断
- CLI:将I复位为0,禁止外部可屏蔽中断,亦称关中断
Intel 8086还提供了对状态标志位C的3条操作指令,操作内容分别是置位、复位和取反
2.4.2. 控制器
整个CPU的指挥控制中心
功能和作用:
根据指令中的操作码和时序信号,产生各种控制信号,对系统各个部件的工作过程进行控制,指挥和协调整个计算机有序地工作
控制器主要构成:
指令寄存器IR (Instruction Register)
指令译码器ID (Instruction Decoder)
操作控制器OC (Operation Controller)
有观点认为包括程序计数器PC (Program Counter)
(也有观点认为PC属于数据通道)
指令寄存器IR
- 临时存放从内存或者缓冲区中取出地下一条待执行指令,其输出作为指令译码器的输入
指令译码器ID
计算机能且只能执行“指令”
指令由操作码和地址码两部分构成
- 操作码表示要执行什么操作
- 地址码表明指令执行时操作对象(操作数)的存放地址
指令译码器只对操作码进行译码,分析和识别指令应该执行什么样的操作
操作控制器OC
- 根据指令译码器的译码结果,产生所需的各种控制信号并发送到相关部件,控制这些部件完成规定的操作
- 操作控制器内部包括时序脉冲发生器、控制信号发生器、启停电路和复位逻辑等
程序计数器PC
- 存放下一条待执行指令在内存中的地址
- 计算机开机时,指向引导程序的第一条指令
- 顺序执行时,每条指令执行后自动修改,PC=PC+n,n与指令字长以及PC的单位有关
- 遇到转移指令,转移目标地址→PC
控制器的工作过程:
- 根据程序计数器的内容获取下一条指令的存放地址
- 通过总线从存储器中取出这条指令并存放到指令寄存器中(取指)
- 指令寄存器的输出直接接到指令译码器的输入
- 指令操作码送入到指令译码器,由指令译码器对操作码进行分析和译码,识别出应执行什么样的操作
- 由操作控制器确定操作时序,产生所需的各种控制信号并发送到相关部件,控制这些部件完成指令规定的操作
- 地址生成部件根据指令特征将地址码转换成有效地址,送往地址缓冲器
- 对于转移指令,所生产的转移地址被转入程序计数器,实现程序的转移
微操作
每条指令的执行过程都可以分解为一系列的微操作
特点:可由简单电路实现;可被多个指令复用
举例:
假设指令“ADD R1,R2,R3”的功能为R2+R3→R1
这条指令的执行过程可以分解为以下几个微操作:
- 根据程序计数器的内容,从内存中读取一条指令到指令寄存器
- 指令译码器对指令进行译码
- 读取R2寄存器的数值,并发送到ALU中作为加法器的输入
- 读取R3寄存器的数值,也送到ALU作为加法器另外一个输入
- 加法器进行加法运算
- 将加法器运算结果写入R1
- 根据运算结果更新状态寄存器中的状态标志位
- 修改程序寄存器的内容,使其指向下一条指令
控制器的实现方式
微程序控制器
简介
- 指令执行过程看作多个微操作序贯执行完成的
- 对每个微操作进行编码,形成微操作码,微操作码可由简单电路产生微操作控制信号
- 执行顺序控制位:指示后续微操作的执行顺序
- 微操作码+执行顺序控制位=微指令
- 指令→一段由若干微指令编排而成微程序
- 所有指令对应的微程序都存放在控制存储器CM中逐条读出,其中微操作码经过译码产生微操作控制信号
结构
- 微地址:微指令在控制存储器CM中的存放地址
- CLK:作用等于读信号
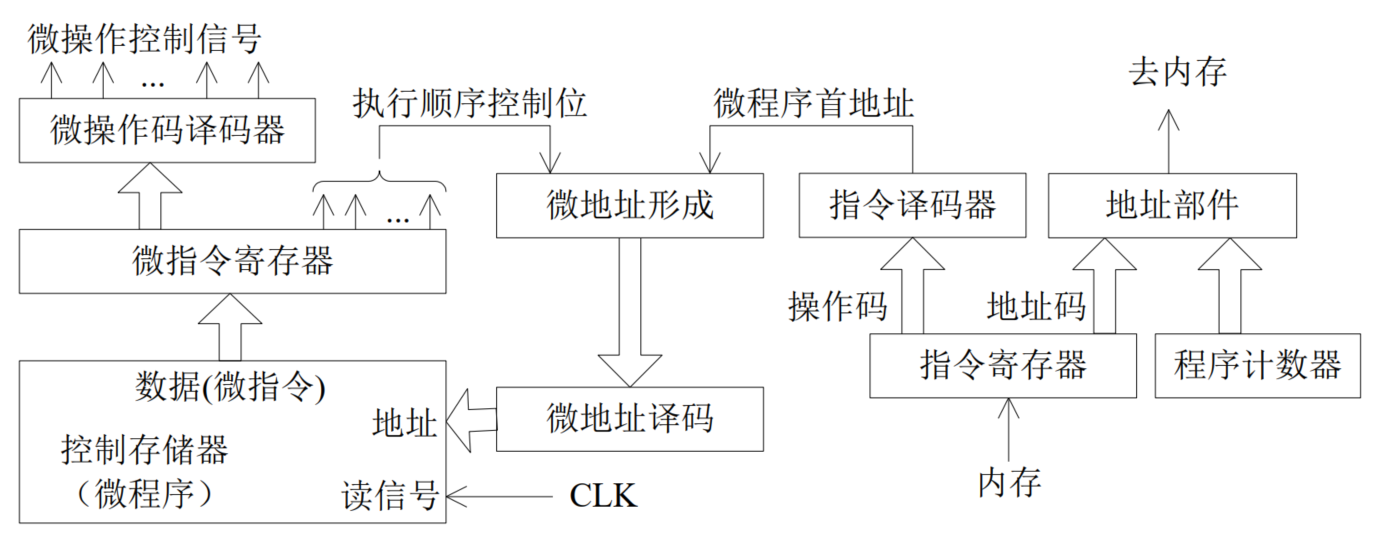
工作原理和过程
- 计算机指令分为操作码和操作数地址两部分
- 操作码由指令译码器译码,译码结果是该指令对应的微程序在CM中的首地址
- 该地址经微地址译码器译码后,从CM中读出第一条微指令,其中微操作码部分送往微操作码译码器进行译码,生成相应的控制信号以实现规定的微操作
- 执行顺序控制位送往微地址形成电路,生成下一条微指令的微地址
- 不断重复上述过程,直到这段微程序全部执行完毕
硬连线控制器
简介
- 也称为组合逻辑控制器,最早采用的控制器设计方法
- 把控制器看作专门产生固定时序的控制信号的逻辑电路,以使用元件少和速度快作为设计目标
- 因指令功能的多样性和差异性,导致所实现的控制器逻辑电路复杂、规模庞大,并且一旦形成就无法变更,除非重新设计和布线
设计步骤
- 输出:需要产生的微操作控制信号
- 输入:微操作信号类型、执行条件和时序
- 列出逻辑表达式,经过化简,设计相应的逻辑电路
一般结构
特点:速度快,电路复杂,不支持复杂指令,调试和改动困难,一度被微程序取代。近年因RISC的兴起和VLSI的进步,再度兴起
2.4.3. 寄存器阵列
也称为寄存器组、寄存器堆和寄存器文件
CPU内部若干高速存储单元,每个都有编号或名称,根据指令中的编号或者名称对其直接访问
CPU与寄存器之间的数据交换是通过内部总线直接进行的,所以CPU与寄存器之间的数据传送速度最快
受指令长度限制,寄存器数量有限,只能暂时存放CPU工作时所需的少量数据和地址
分为专用寄存器和通用寄存器两大类
- 专用寄存器作用固定,如PSR(FR)、IR和PC等
- 通用寄存器:为ALU运算提供一个存储区,早期数量较少且通用性差,现在数量增加,通用性增强
2.4.4. 地址与数据缓冲器
CPU内部总线与系统总线之间的接口,提供地址和数据传送缓冲,同时增加CPU的系统总线驱动能力
2.4.5. 数据通道
计算机各部件按功能划分为两大阵营:控制单元CU和执行单元EU
CU就是控制器,也是计算机中指令流的终点。控制器的组成包括指令寄存器、指令译码器和操作控制器。负责指令译码,生成相应的控制信号,控制执行单元完成指令规定的各种操作
EU负责指令执行,如生成地址、读取和传送数据、计算和处理数据、存储结果、更新PSR和PC。执行单元包括运算器、寄存器组、内部总线以及系统总线接口
在指令执行过程中,数据是在运算器、寄存器阵列和系统总线接口之间通过内部总线进行传送,所以这几个部件也被称为数据通道
2.4. 模型机指令集和指令执行过程
2.4.1. 模型机指令集
指令
根据计算机组成的层次结构,可以分为:微指令,机器指令和宏指令
- 微指令:微程序级的指令,属于硬件层面
- 宏指令:由若干条机器指令组成的软件指令,属于软件层面
- 机器指令:简称指令,介于位指令与宏指令之间,是CPU能识别和直接执行的一条二进制编码序列,包括操作码和操作数两部分
指令系统
一台计算机中所有指令的集合称为这台计算机的指令系统
- 指令集架构ISA:狭义上的计算机体系结构
汇编指令
使用助记符(容易理解和记忆的字母)表示指令的操作码
使用标号和符号地址代替指令和操作数的地址
模型机部分常用汇编指令:
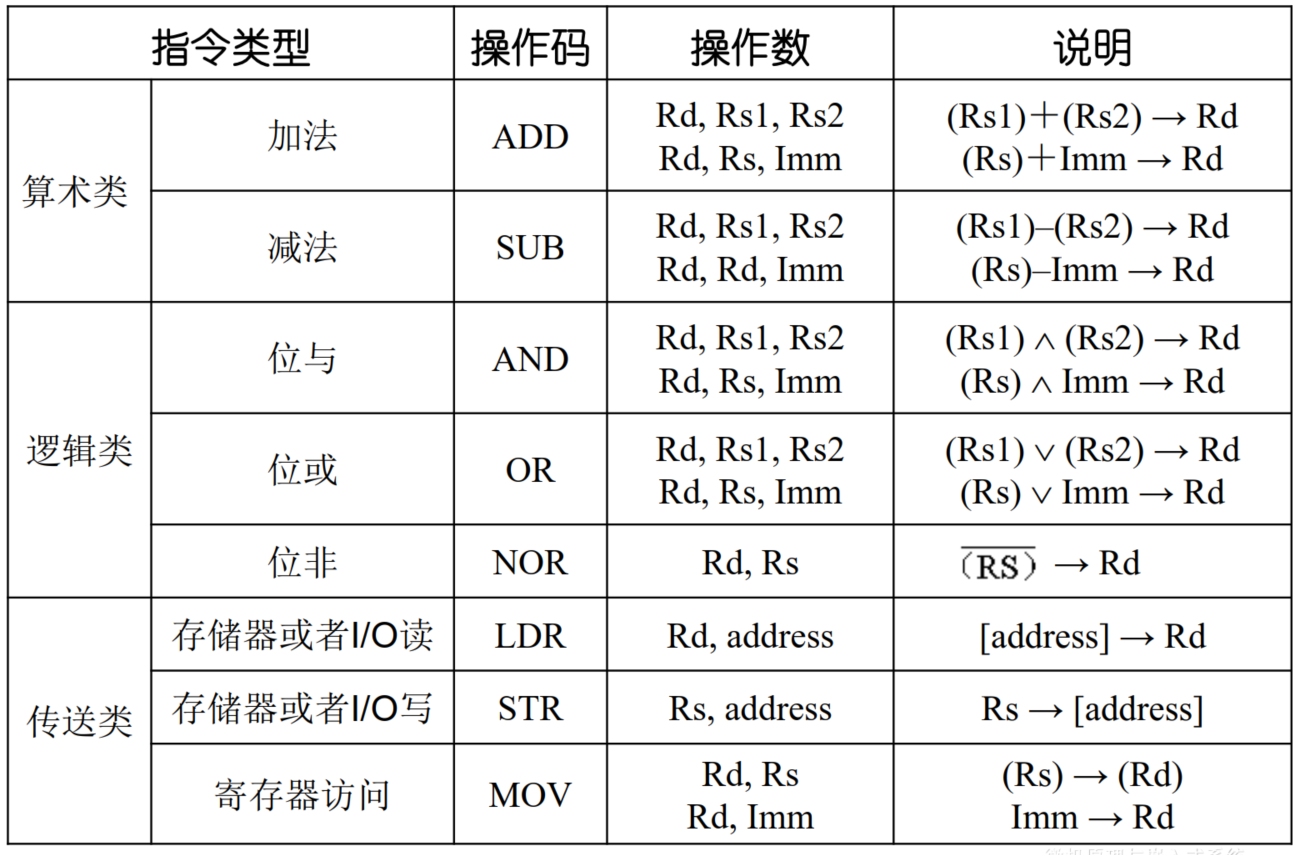

RISC指令风格:定长指令,Load/Store体系,三操作数
Rs-源操作数,Rd-目的操作数,Imm-立即数
Label-标号(用符号表示的指令地址)
定长指令
每条指令长度固定
特点(假设32位机,32位指令长度)
一次取指操作读取一个完整的指令
受指令位数限制,对立即数的大小或者类型有要求
同样原因,对内存寻址时,无法在指令中直接给出内存的单位地址
内存单元地址可用如下方法表示:
- 某个32位寄存器中的数值—寄存器间接寻址
- 某个32位寄存器内容+偏移量—基址加偏移量寻址
- 某两个寄存器之和—基址加索引寻址
2.4.2. 指令周期
计算机运行流程
开始 → 取指 → 执行 → 取指 → 执行 → ……
指令周期
开始取指到完成指令操作的时间
- 因功能和操作内容不同,许多处理器指令周期也不同
- 有些采用流水线技术的RISC处理器,所有指令执行时间相同,被称为单周期处理器
CPU时间
- 又称总线周期、机器周期
- 一个CPU周期等于一次取指时间
- 一个指令周期分为若干个CPU周期
T周期
- 又称时钟周期
- 一个总线周期包括若干个T周期
- T周期是处理器最基本的时间单位

2.4.3. 模型机指令执行流程
示例:利用模型机汇编指令编程实现如下操作:
将数据000FF000h(0x000FF000)与内存中某个字数据相加,字数据的地址位于R3寄存器中,如果相加结果没有溢出,则将0x000FF000存入由R3+80h指定的内存单元,然后停机;如果溢出,直接停机
模型机汇编语言源程序片段:

模型机系统结构:
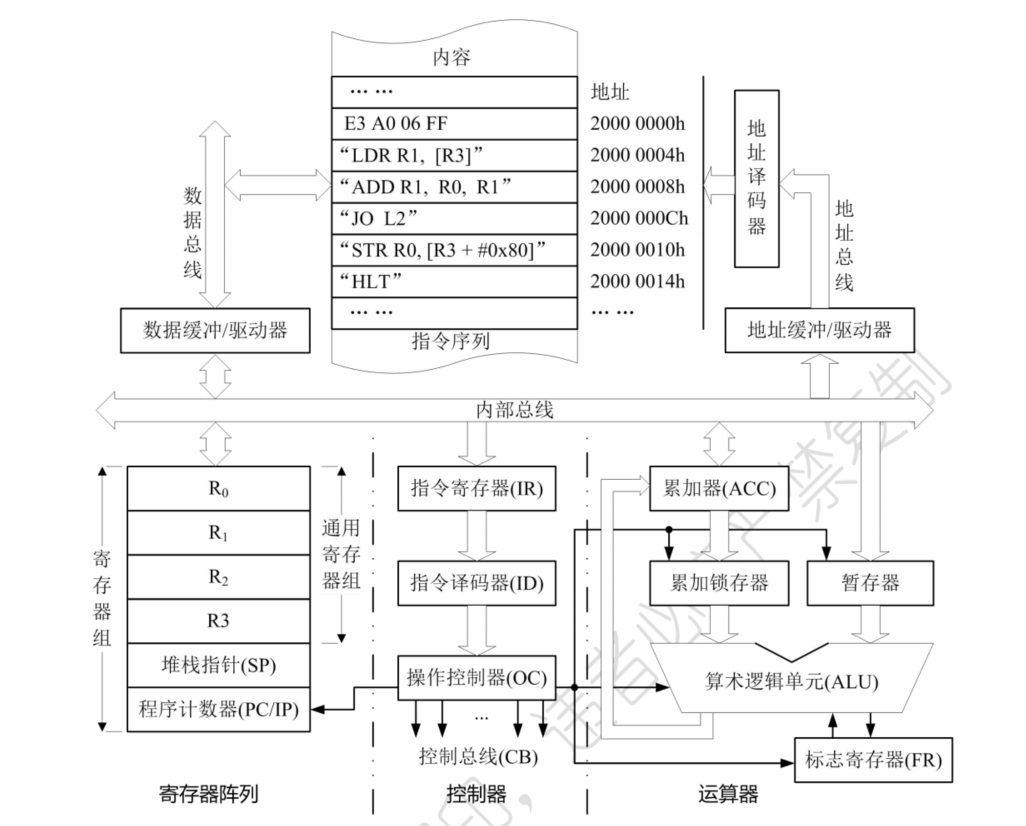
用汇编语言编写的程序称为汇编语言源程序,简称汇编程序。将其转换成机器语言的过程称为汇编,能够实现汇编功能的软件称为汇编器或者汇编软件
汇编后的机器指令顺序存放,若指令长度为4字节,后一条指令地址等于前一条地址加4(PC的单位为字节)
模型机结构假设:
- 模型机是32位,数据总线32位,地址总线32位
- RISC结构,定长指令设计,每条指令长度也是32位
- 待运行程序的首地址为0x2000 0000
- 第一条指令的机器码为“E3 A0 06 FF”
执行过程:
第一条:源操作数是立即数(取指时能从指令编码中立即得到的数),被装入R0寄存器后指令执行完毕
根据程序的名字,把0x20000000装入程序计数器PC
程序计数器PC内容0x20000000送至地址缓冲器/驱动器,地址总线的输出经地址译码器译码,寻址内存单元
操作控制器OC发读信号,将“E3 A0 06 FF”读出到数据总线
由于是取指操作,数据总线上的数据被装入指令寄存器IR
程序计数器PC值自动加4(假设PC内容的单元是字节),指向下一条指令的存放地址
- 流水线处理器取指后立刻更新,以便能够立即取下一条指令
- 另一种策略是临近指令执行结束时再更新,可根据执行结果确定该如何更新
指令译码器ID对操作码译码,操作控制器OC产生相应的控制信号
指令的地址码部分对应着汇编指令的操作数部分。本条指令中,源操作数为立即数#0x000FF000,目的操作数是R0寄存器
在操作控制器OC输出的控制信号作用下,立即数#0x000FF000经地址形成部件和地址驱动器送到地址总线,再经地址译码后寻址到源操作数存放的内存单元
操作控制器OC发出读信号,将源操作数读出到数据总线,然后加载到R0寄存器
第二条:Load操作,从内存取操作数到R1,操作数地址由R3提供
- 把第二条指令的地址0x20000004 装入程序计数器PC, 程序计数器的内容0x20000004 送到地址形成部件,地址形成部件产生的地址信号经地址缓冲器/驱动器和地址总线,被送到地址译码器进行译码,寻址指令存放的内存单元
- 操作控制器发读信号,将0x20000004 单元的内容“LDR R1, [R3]”读出,由于是取指操作,“LDR R1, [R3]”经过数据总线被存入到指令寄存器IR
- 如果程序计数器的单位是字节,则PC 自动加4,指向下一条指令的存放地址
- 指令译码器ID 对指令操作码进行译码,操作控制器OC 按照操作时序发出相应的控制信号
- 指令的地址码部分对应着汇编指令的操作数部分。本条指令中,存放源操作数的内存地址位于R3 寄存器中,目的操作数是R1 寄存器
- 在操作控制器输出的控制信号作用下,R3 寄存器的内容经地址形成部件和地址驱动器送到地址总线,再经地址译码后寻址到源操作数存放的内存单元
- 操作控制器发出读信号,将源操作数读出到数据总线,然后加载到R1寄存器。
第三条:ADD运算,R0与R1相加,结果存入R1寄存器,完成运算后更新到FR中相关状态位
第四条:条件转移,溢出则跳转执行标号为L2的指令,PC=PC+m(m是转移目的指令与转移指令之间的相对距离);否则继续执行下一条指令
第五条:Store操作,源操作数是R0寄存器的内容,目的操作数的地址是R3寄存器的内容再加上偏移量80h
第六条:HTL停机,持续执行空操作
总结与讨论
指令执行时,指令操作码送到IR,经IR译码后OC产生操作控制信号,指令的地址码送到地址形成部件,生成地址信号
- 指令存储器 → 数据总线 → 指令寄存器 → 指令译码器/地址形成部件
- 指令译码器是指令操作码的终点
- 地址形成部件是指令地址码的终点
CPU中的所有数据都在数据通道中传送
指令执行过程属于多级串行作业,始终有一部分部件处于空闲状态,部件的利用率不高
- 取指 → 指令译码 → 取操作数 → 执行 → 存操作数
模型机属于冯诺依曼架构,串行工作方式的取指和存取操作数在时间上相互错开,不会出现冲突
如果改用流水线方式,前后指令的取指和存取操作数可能同时发生。冯诺依曼体系结构将造成总线竞争,故不太适合流水线模式
2.5. 计算机体系结构的改进
2.5.1. CISC和RISC
CISC:指令数量多、功能丰富、可实现复杂操作
简介
- 采用微程序控制器,为了减少硬件实现难度,减少硬件规模
- 控制器结构简单、规整。增加新指令或者为已有指令添加新的功能较为容易 → 指令系统规模日渐庞大

CISC处理器指令的特点
指令长度不一
较长指令取指需要使用多个总线周期和多次总线操作
长短不一的指令给指令译码器设计带来挑战,增加了控制器的复杂性和电路规模,也不利于采用流水线和超标量等新技术
举例:
- Intel 8086处理器的最短指令只有一个字节(如CLC),最长指令6字节。指令长度的变化范围为1~6字节
- Motorola 68020处理器(32位)的指令长度从半个字到8个字,变化范围为2~32字节
非Load/Store体系
算术和逻辑运算指令的操作数可以是存储数
- 例如:存储器数 + 寄存器数 → 存储器
- CISC仅需要一条指令:
ADD[addr], Ri - RISC需要三条指令:
LDR、ADD和STR,比CISC至少多出2次取值和译码操作
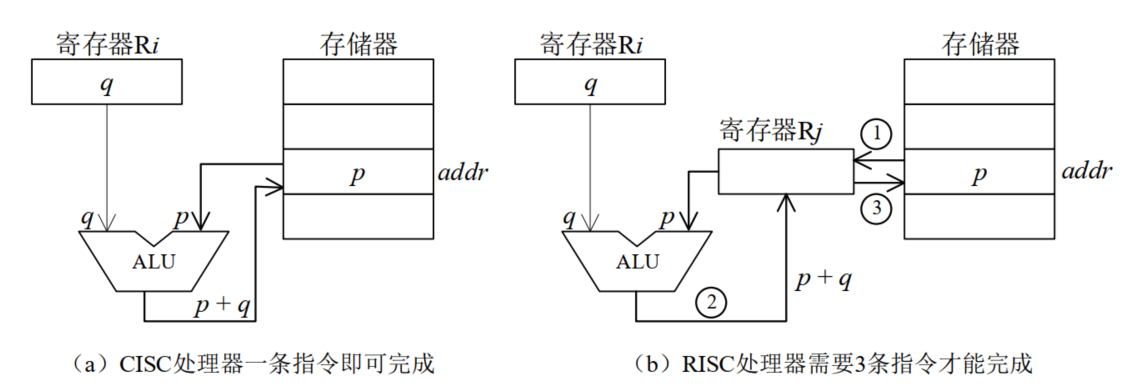
MOVE操作
格式为:
Move destination,source的传送指令,可实现寄存器与存储器之间的数据传送大多数CISC处理器规定,MOVE指令的源操作数和目的操作数最多只能有一个是存储单元
同一条总线上的两个存储单元,如果彼此之间需要传送数据,无论是RISC和CISC处理器,无论采用多条简单指令还是一条复杂指令,数据传送过程都分为两步
- 第一步,将源操作数从内存单元中读出到某个通用寄存器暂存
- 第二步,将暂存的内容写入目的存储单元
两操作数
在现代CISC处理器中,大多数算术和逻辑运算指令只有两个操作数,其格式一般为:
OPR(操作码) DST(目的操作数), SRC(源操作数)例如,加法指令:
xxxxxxxxxxAdd B, A对应的操作是(B)+(A)→B。指令执行后,结果送到B原来的存储位置,替换原先的内容。意味着DST既是目的操作数,也是参与运算的两个源操作数中之一
指令功能强大,寻址方式多样,程序简洁
- CISC处理器的指令功能强大,可以实现复杂的操作,灵活多样的寻址方式有利于软件编程
- 与RISC处理器相比,完成同样任务CISC处理器所需的指令数量较少,软件显得较为简洁
- 指令数量少意味着所需的取指和译码操作次数也比较少,在不考虑其他技术因素(如流水线)的情况下,CISC处理器执行效率要高于RISC处理器
CISC处理器的性能问题
主要影响因素:微程序控制器的工作流程
- 完成一条指令需要从控制ROM中顺序读出多条微指令,需要多个在时间上序贯执行的微操作,这种在时间上串行作业模式将影响指令的执行速度
两种解决思路:
- 提高处理器的工作时钟频率,加快微操作的节奏,但是增加时钟频率受到半导体材料物理特性的限制,并且难以消除由此产生的功耗和发热问题
- 使用流水线和超标量等技术,让多条指令在时间上并行执行。但是由于CISC体系结构的特点,流水线和超标量的设计和实现遭遇很多困难
RISC
特点
- 摒弃微程序设计思想,采用硬连线方式实现控制器
- 为了减少硬件实现难度,采用精简指令集
- 减少处理器电路数,多余的芯片面积用于增加Cache容量以及寄存器数量,利用层次化的存储结构优化数据传送
- 指令简单、长度一致、执行时间相同等特点使其更加易于引入流水线技术和超标量等可大幅度提高处理器性能的并行处理技术
- CISC处理器一条复杂指令就能实现的操作,RISC处理器需要使用多条简单指令才能完成
- 需要优秀的程序编译器,优化由数量较多的简单指令构成的程序代码
RISC指令特点
- 寻址方式简单,种类较少
- 指令集中的指令数量较少
- Load/Store体系结构
- 每条指令长度一致,执行时间相同
- 面向寄存器的编程思想
- 算术和逻辑运算指令普遍支持三操作数
- 只能对寄存器操作数进行算术和逻辑运算
- 程序代码量较大,因为执行复杂操作需要使用较多的简单指令
CISC & RISC借鉴与融合
- 为了减少执行一项操作所需的指令数量,RISC处理器也增加了一些能够快速执行的非RISC指令
- 为降低硬连线控制器的设计难度,有些RISC处理器还是部分采用了微程序和微指令设计
- Intel通过与RISC阵营的合作引入RISC技术,从P6开始,处理器中有一部分采用了RISC设计
- Intel 64位IA-64架构处理器是在HP的帮助下完成的;Intel所提出的EPIC体系大部分是Alpha的遗产
2.5.1. 流水线技术
流水线原理
指令执行过程可分解为多个步骤,假设分解为:
- etch(取指) → Decode(译码) → Read(去操作数) → Execute(执行) → Writeback(回写)
每个步骤都有专用部件完成操作,各部件分工明确,各司其职,每个步骤按照顺序执行
模型机任何时候只能执行一条指令,前后指令呈多级串联作业模式,将会造成部件的“窝工”
- 取指时,译码、取操作数、执行和回写处于等待状态
- 执行时,取指、译码、执行和回写又处于等待状态
将功能部件按指令操作步骤顺序进行排列部署,前后部件之间增加缓冲寄存器,构成指令处理流水线
前后两个部件经过缓冲寄存器隔离后,可以相对独立地并行工作

- 部件之间地工作交接(数据传递)将通过缓存寄存器进行
- 这种缓存寄存器被称为流水线寄存器
- 多条指令可以在流水线上以时间重叠的方式序贯执行
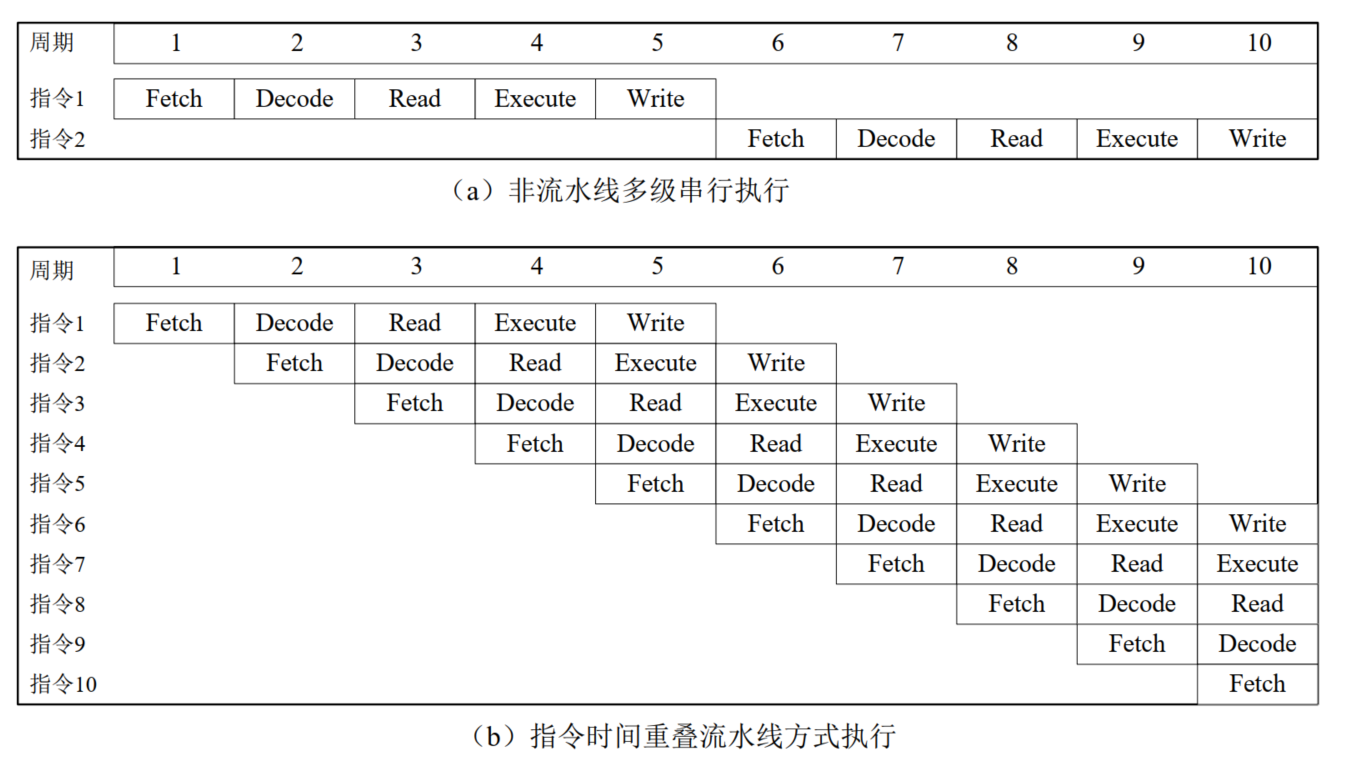
从流水线时空图可看出,在10个流水线周期内
- 串行作业模式只能完成2条指令的执行
- 流水线方式至少可以完成5条指令的执行。多条指令以时间方式重叠方式执行使得IPC大大提高
- 由于增加了流水线寄存器,增加了流水线寄存器写入时间和额外的门电路时延。因此,单条指令在流水线上执行所花费的时间要比非流水线方式更长
- 流水线周期将受制于最慢的部件,将导致流水线的性能下降
流水线中技术存在的主要问题
流水线高效运行的前提:保持畅通,不发生断流
指令执行过程中可能发生的三种相关冲突:
资源相关,又称结构相关
多条指令在同一周期内争用同一个公用部件
例如:冯诺依曼结构计算机的Fetch、Load和Store操作都使用公用总线接口访问同一个存储器,前一条指令的数据存取操作可能会影响后续指令的取指操作
解决方法
- 后面一条指令等待一个节拍再启动。称为向流水线插入气泡或者插入阻塞,这将造成流水线性能下降
- 采用哈佛结构(程序指令和数据分开的结构)。解除存取操作数与取指之间的资源相关
数据相关
后一条指令执行需要使用前一条指令的结果。例如流水线上前后执行的两条运算逻辑令
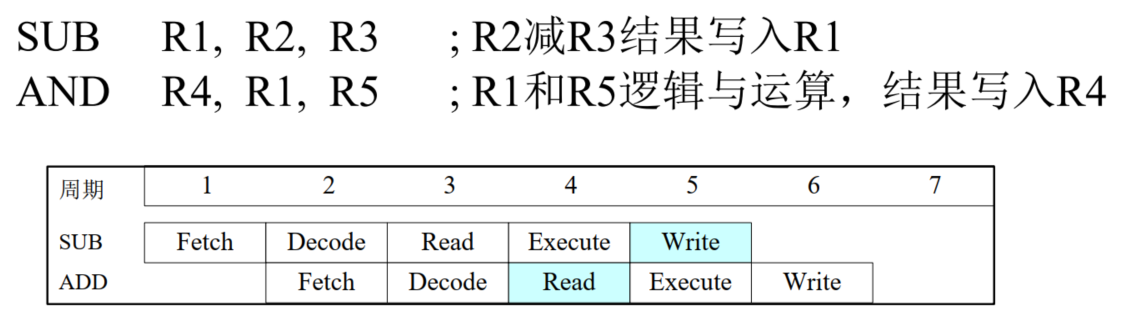
SUB指令在第5个周期才将结果写回R1,但是AND指令在第4个周期就要读R1进行运算,而程序的本意是“写后读”(RAW)
RAW是一种最为常见的数据相关
流水线可能还存在“写后写”(WAW)和“读后写”(WAR)两类数据相关
- WAW:试图在指令写数据之前写数据,这样最终结果将由决定,而程序本意是保留的结果
- WAR:试图在指令读数据之前写数据,此时指令读到的是被篡改后的结果
- 插入气泡可消除数据相关,但将造成流水线性能下降
解决方法
- 定向推送,前一条指令执行结果通过专用通道直接推送给下一条,减少一个流水线周期,可减少数据相关
- 优化编译器,对前后指令进行检查,调整执行顺序
控制相关
遇到转移指令时,后续已进入流水线的指令都应清空
以无条件转移(包括子程序调用)指令为例:
- 假设指令是无条件转移指令,其执行步骤为:取指、译码、计算转移地址并更新程序计数器PC。在第4个周期读取转移目标指令(转移目标指令:转移指令的目标指令,即下一条紧接着执行的命令)。在此之前流水线上的指令和应清除,造成流水线断流。产生两个流水线周期延迟被称为转移代价
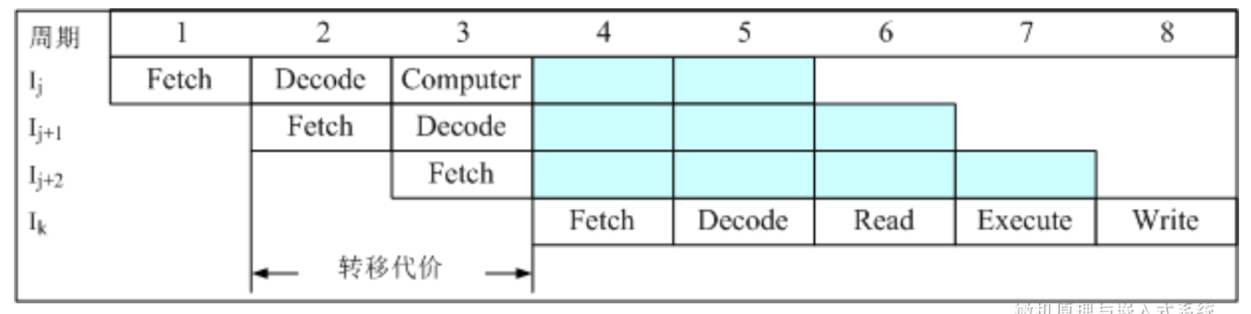
减少转移代价的方法
- 对于无条件转移指令,增加电路,在译码阶段提前计算转移目标地址,在第3个周期读取转移目标指令,将转移代价减少到一个流水线周期
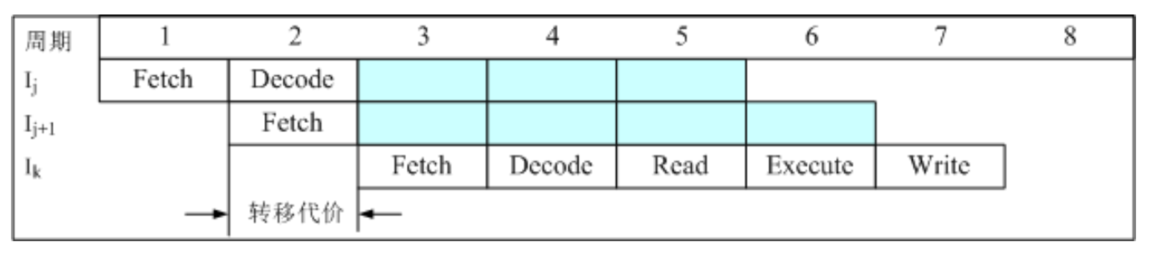
依旧存在的问题:大多数条件转移指令是否转移取决于状态标志位,而标志位在ALU运算后才更新,转移代价较大。流水线级数却多,代价越大
- 转移预测技术
转移预测技术
转移延迟槽:转移指令后面的一个时间片。无论是否转移,位于转移延迟槽的指令总是会被执行
动态转移预测:根据转移指令过去的行为进行预测
评估:用2bit(权值)对转移指令过去行为进行量化,‘11’总是转移,‘00’总是不转移
动态打分:每发生一次转移,权值+1,加到11b为止;每发生一次不转移,-1,减到00b为止
使用BTB(转移目标缓冲器),收集和存储了近期所有转移指令的有关信息,并按照查找表的形式进行组织,为动态转移预测提供信息
BTB不能太大,一般为1024个表项,其内容包括:
- 转移指令的地址(查找表索引)
- 转移可能性的量化结果(2bit权值)
- 转移目标指令的地址
每条指令在取指时,处理器根据其地址在BTB中进行快速搜索,若有记录则表明这是一条转移指令,并根据其“档案”进行相应处理,最后根据这条指令的实际行为修正BTB的记录内容
2.5.3. 超标量处理器和多发射技术
标量处理器:只能处理标量数据,一条指令一次只能处理一个数据,属于SSID
向量处理器(阵列处理器),一条指令完成一个向量计算,属于SIMD,用于科学计算和信号处理等领域
超标量处理器:拥有多条流水线,通过空间并行方式提高处理能力
将多条指令分发到多条流水线上,同时执行
分发前需配对检查,不同流水线上的指令不相干
- 若流水线2的指令要用到流水线1的结果,那便会产生窝工
可以使用不同类型的流水线,如整数和浮点数
多发射技术:多个指令分发单元
- 指令分发单元需要在一个流水线周期之内向多条流水线发射多条指令
2.5.4. 超线程处理器
进程:程序的动态执行过程
- 多任务系统中,CPU的运行时间被划分成多个时间片,CPU在不同的时间片轮流为每个任务进行服务
- 早期,进程被作为作业调度和资源管理的基本单位
- 进程运行时拥有所需的全部资源;任务切换时,操作系统回收资源并重新分配,无效开销太大
线程:能独立执行的代码最基本单元
- 每个进程拥有若干个线程
- 线程是作业调度和执行的基本单元,拥有少量的必备资源,与进程中的其他线程共享全部资源
- 线程调度时资源不可回收,无效开销小
单处理器同时只能执行一个线程,多线程只是利于操作系统的任务调度,减少无效开销,性能提高有限
超线程技术:为进一步减少处理器内部的硬件资源闲置,对流水线进行改造并添加少量部件,使处理器在同一时间可以执行两个线程
- 超线程只是有了两个逻辑上的线程处理单元,每个线程并不是独自拥有所需的全部资源
- ALU、FPU、Cache和总线接口等仍是两个线程共享
- 超线程需要操作系统、应用软件以及主板BIOS的支持
- 性能提升:多任务时可提升30%,单任务时处理器性能不升反降
2.5.5. 多处理器计算机和多计算机系统
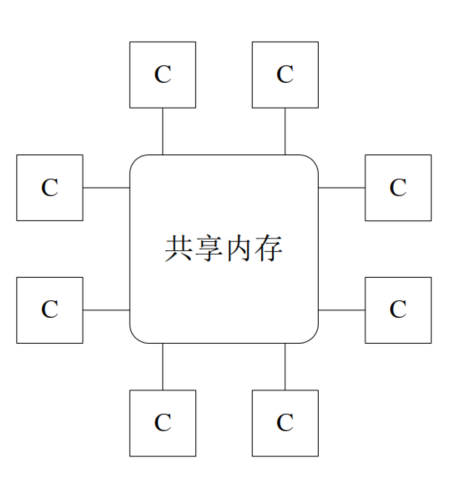
多处理器计算机
一个计算机有分布在不同的芯片上的多个处理器
多个处理器芯片通过共享内存或者共享总线进行数据交换,并行工作,属于一种紧耦合多处理器系统
多处理器计算机分为:
非对称多处理器计算机AMP
- 处理器有主从之分,不同的处理器承担不同的任务
全对称多处理器计算机SMP
- 现代服务器的主流架构。各处理器地位相同,对称工作;所有共享系统内存、I/O通道和外部设备
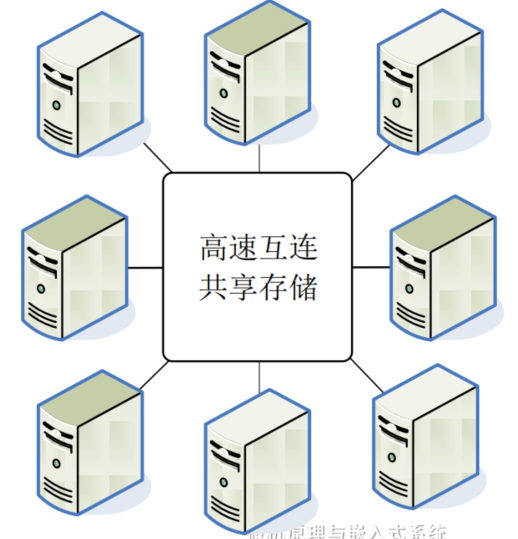
多计算机系统
- 每台计算机通过局域网以及私有网络彼此互连
- 每台计算机受各自独立的操作系统控制,有属于自己的存储系统和I/O设备,属于一种松耦合系统
- 可通过LAN或者SAN(存储域网)共享外部存储器,组成计算机集群
- 除提高了计算能力以外,也减少单点故障,具备高可用性,普遍应用于执行关键任务的信息系统中
分布式计算机系统
- 若干独立计算机或者集群通过网络互连而成
- 有一个全网统一的分布式操作系统,能够对用户所需的各种资源进行统一调度和管理,并且保证系统的一致性与透明性(不可见)
- 用户无需关心系统中的资源分布情况以及计算机差异
- 计算机之间没有主从之分,彼此既合作又自治,协同工作
- 分布式计算机系统是计算机应用领域发展的一个重要方向,也是云计算的主要基础
2.5.6. 多核处理器
可集成的电路数越来越多,可以把多个功能完整的CPU集成在一个芯片上——单芯片多内核处理器
每个计算内核普遍采用超标量和超级流水线技术,拥有所需的全部计算资源,可彼此独立地执行任务
多个内核通过片内总线或交叉开关矩阵互连,可看作一个片上多处理器机CMP系统,对外呈现为一个统一的处理器
分为同构多核和异构多核两种类型
同构
- 同构多核处理器的内核普遍采用通用处理器,每个处理器的结构相同,地位相同
- 同构多核的结构相对简单,硬件实现复杂度低
异构
- 通过配置具有不同功能和性能的内核以匹配实际应用需求
- 在提升芯片整体性能的同时,优化处理器结构,降低系统功耗
- “让专业的人做专业的事”,避免“大马拉小车”和“小马拉大车”
- 范例:华为海思麒麟处理器
多核处理器性能与任务的并行性有关
安达尔定律:性能加速比
其中,为节点数,为可并行代码比例
- 若,全是串行,
- 若,全是并行,
- 若代码为串行,,即使
应在核数、功耗、代价和实际效果间寻求平衡
2.6. Intel x86典型微处理器简介
2.6.1. Intel 8086处理器
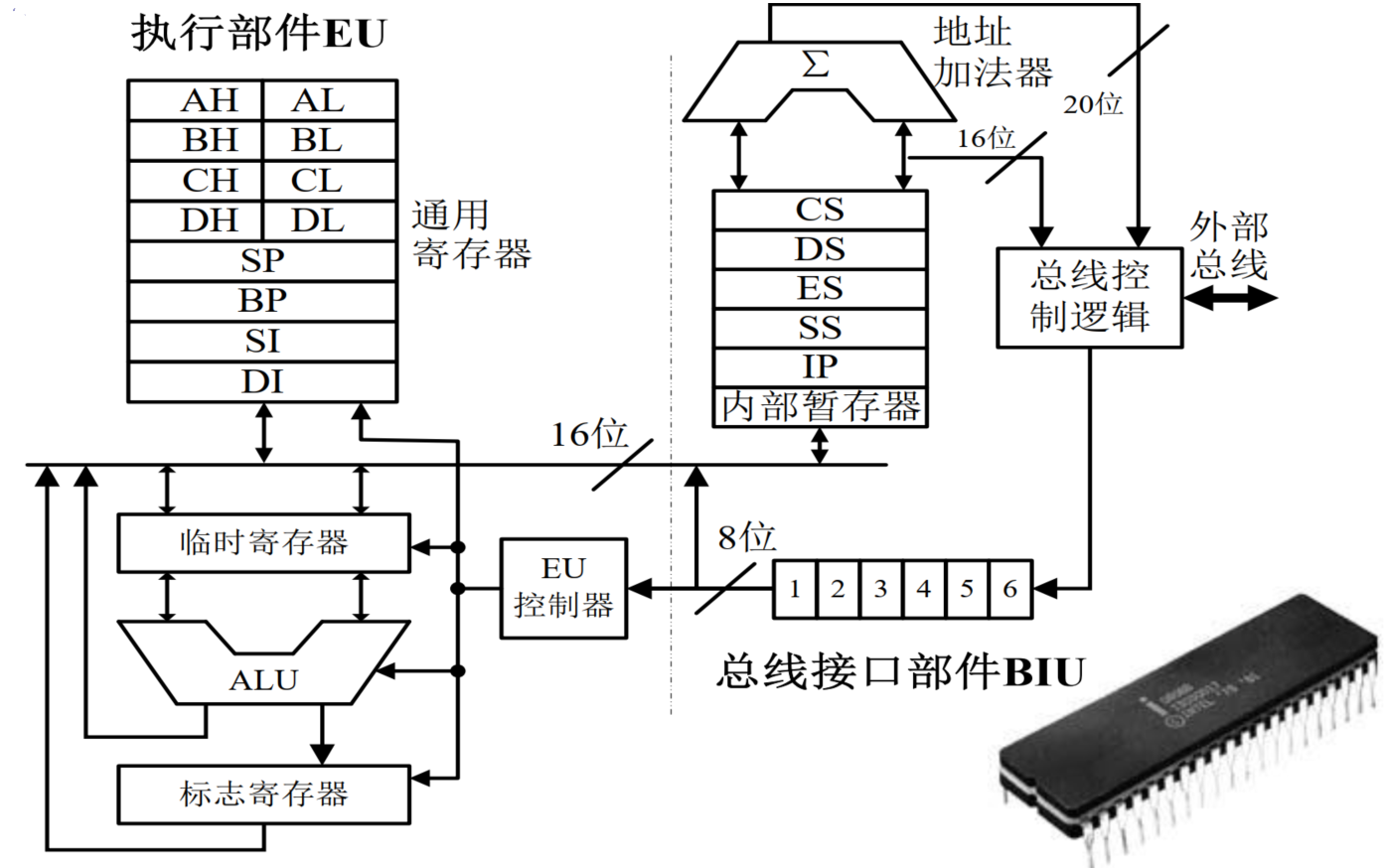
- 全球第一款16位通用微处理器芯片
- 内部寄存器为16位,其中有4个可以分拆成8位使用
- 16位数据总线,20位地址总线
- 内存分段管理,段寄存器左移4位+偏移量=20位地址
- I/O端口独立编址,端口总数为64K个
- 时钟频率仅有5MHz,最高不超过10MHz
- 分成指令执行单元EU和总线接口单元BIU两部分
2.6.2. Intel Pentium处理器
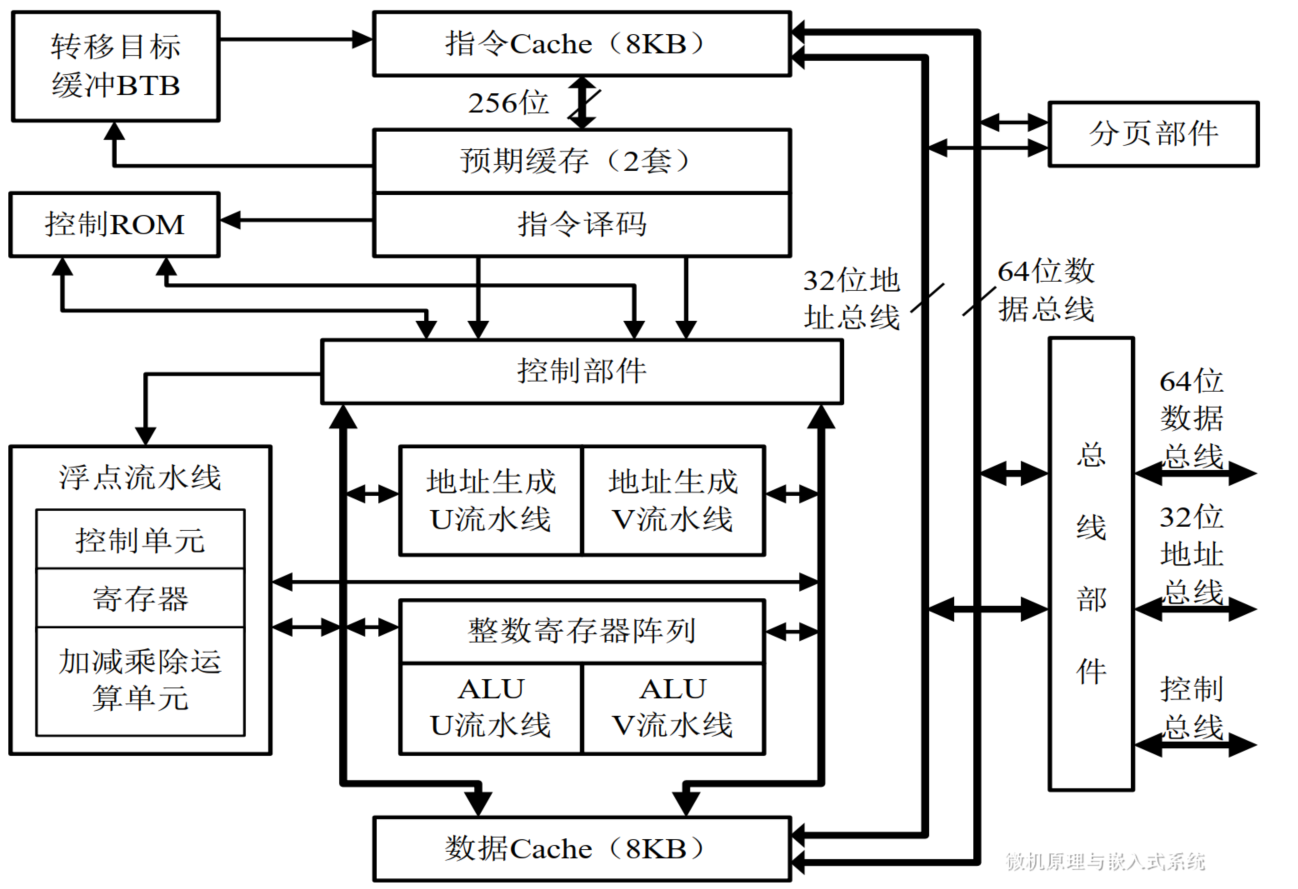
- 与以往的80x86系列微处理器兼容
- 32位地址总线,64位数据总线
- 采用CISC结果实现超标量结构,两条并行的5级整数指令流水线(U和V),一条8级浮点运算流水线
- 独立的指令Cache和数据Cache,数据和代码分离
- 汲取RISC的优点,简单指令改用硬连线控制器实现
- 基于BTB(转移目标地址缓冲器)的预测转移技术
- 191条指令,支持9种寻址方式
- 支持64位外部数据总线突发传输方式
- 支持SMM模式,增强的错误检测和报告功能
2.7. ARM嵌入式处理器简介
2.7.1. ARM体系结构、ARM处理器和ARM内核
ARM体系结构
ARMv1~ARMv7属于32位架构,ARMv8属于64位架构
ARMv7子版本
- ARMv7-A,对应的产品系列是ARM Cortex-A
- ARMv7-R,对应的产品系列是ARM Cortex-R
- ARMv7-M,对应的产品系列是ARM Cortex-M
ARM处理器和ARM内核
严格地说,ARM处理器是ARM公司设计的处理器
- 内部仅有的最基本的数据处理核心,习惯上称之为内核
- 基于同一体系结构版本,应用软件层面可相互兼容
芯片制造商获得授权后,根据实际需求和产品定位,在某款ARM设计的处理器基础上,再增加诸如实时时钟、ADC、DAC、存储器、协处理器、DSP,以及各种接口单元部件,形成多种各具特色的嵌入式处理器芯片,实际上应该属于SOC,但是往往也被称为ARM处理器(芯片)
2.7.2. ARM处理器的特点
ARM处理器成功三要素
- 代码密度高(代码占用内存少)
- 功耗低
- 性价比高
不同版本的ARM内核都具有如下RISC架构的共同特征:
- 每条指令长度固定
- 指令集中的指令数量较少
- Load/Store体系结构
- 只能对寄存器操作数进行算术和逻辑运算
- 采用硬件布线逻辑,大部分指令在一个周期内完成执行
ARM内核吸取的CISC架构特点:
- 保留少数功能强大的复杂指令,如多寄存器传送指令
- 提供自增、自减指令和基于PC的相对寻址方式
- 用于转移指令和条件执行的条件码(N-负,Z-零,C-进位,V-溢出)
- 少数指令可以在多个周期内完成
其他特点
- 支持不同的指令集
- 指令的条件执行
- 移位操作的实现方式
2.7.3. 典型ARM内核的基本结构
ARM7TDMI——ARM7系列基本型产品
属于ARMv4T版本,产品后缀含义:
- T表示支持16位的Thumb指令(ARM指令集的子集)
- D表示支持片上Debug
- M表示内嵌硬件乘法器
- I表示内嵌ICE逻辑
内部结构:
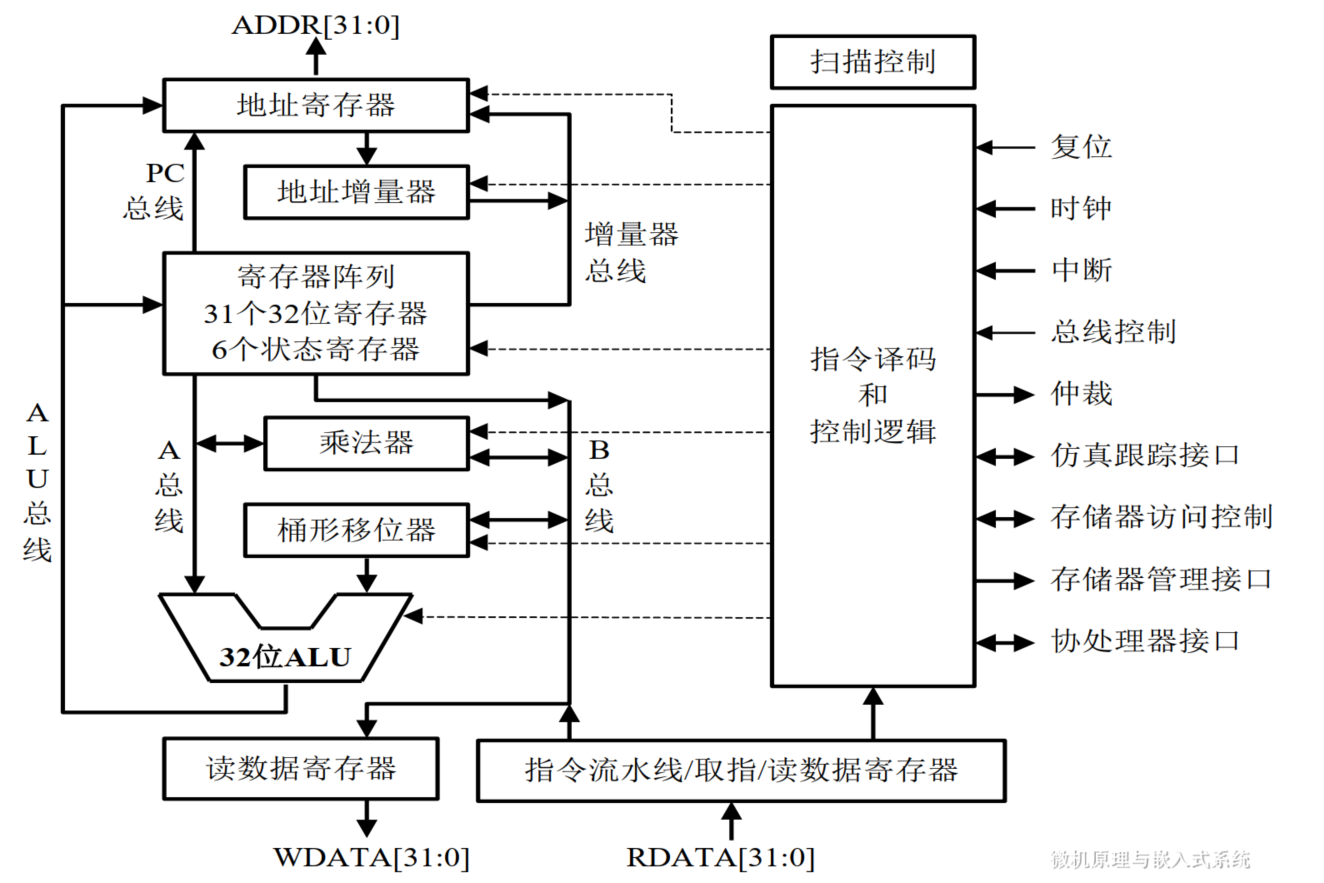
简介
ARM7家族其他产品的基础,内核中的内核
包括一个32位ALU,一个32位桶形移位寄存器和一个32位x8位乘法器
共有37个程序可访问的32位物理寄存器,包括31个通用寄存器和6个状态寄存器
- 这些资源不是同时可见,在不同工作状态以及不同工作模式下只能看到其中一部分
- 在任何状态和模式下,最多只能看到其中的18个
“写”和“读”数据总线分开,片外只需配置单向总线驱动器,没有双向驱动器的方向转换时延
特点
- 有ARM和Thumb两种状态,可软件切换,分别支持全功能的32位ARM指令集和简洁的16位Thumb指令集
- 一条3级(取指、译码和执行)流水线,性能可达0.9MIPS/MHz;支持8bit、16bit和32bit数据操作
- 快速中断响应能力
- 写数据和读数据总线分开,片外无需双向驱动器
- 冯诺依曼结构,系统简洁,门电路数量较少
- 高性能、低成本,超低功耗,尤其适合对功耗有苛刻要求的场合,如依赖电池供电的各种手持式电子设备
ARM920T基本结构和特点
ARM9系列简介
ARM9产品家族可分为ARM9和ARM9E两个系列
- ARM9系列是基于ARMv4T版本的普通型产品,包括ARM9TDMI、ARM920T、ARM922T和ARM940T
- ARM9E系列则是基于ARMv5TE版本的增强型产品,具有DSP和Java扩展功能,包括ARM926EJ和ARM946E
ARM9系列与ARM7相比在体系结构上的改进
- 指令流水线升级为5级(取指、译码、执行、存储器访问和回写),每级电路更简单,执行速度更快
- 采用哈佛结构,减少发生资源冲突的概率
- Thumb指令采用硬件译码,速度高于软件译码的ARM7
ARM9TDMI处理器简介
ARM9TDMI是ARM9产品家族中的基本型产品
同系列的其他处理器都是以ARM9TDMI为核心,扩展和集成其他功能部件所构成:
- 指令Cache和数据Cache、AMBA总线接口、嵌入式跟踪宏单元ETM、MMU或者MPU等
ARM920T处理器简介
属于ARM9系列,以ARM9TDMI为核心,另外配置了
- 各16B的数据和指令cache
- 数据和指令MMU
- 写缓存(16字的数据,4个地址)
- CP15
- 外部协处理器接口
- 嵌入式跟踪宏单元ETM
支持VxWorks,WindowsCE和Linux等嵌入式OS
高性价比和低功耗,典型的目标SOC芯片
提供1.1MIPS/MHz的哈佛结构
ARM920T处理器结构
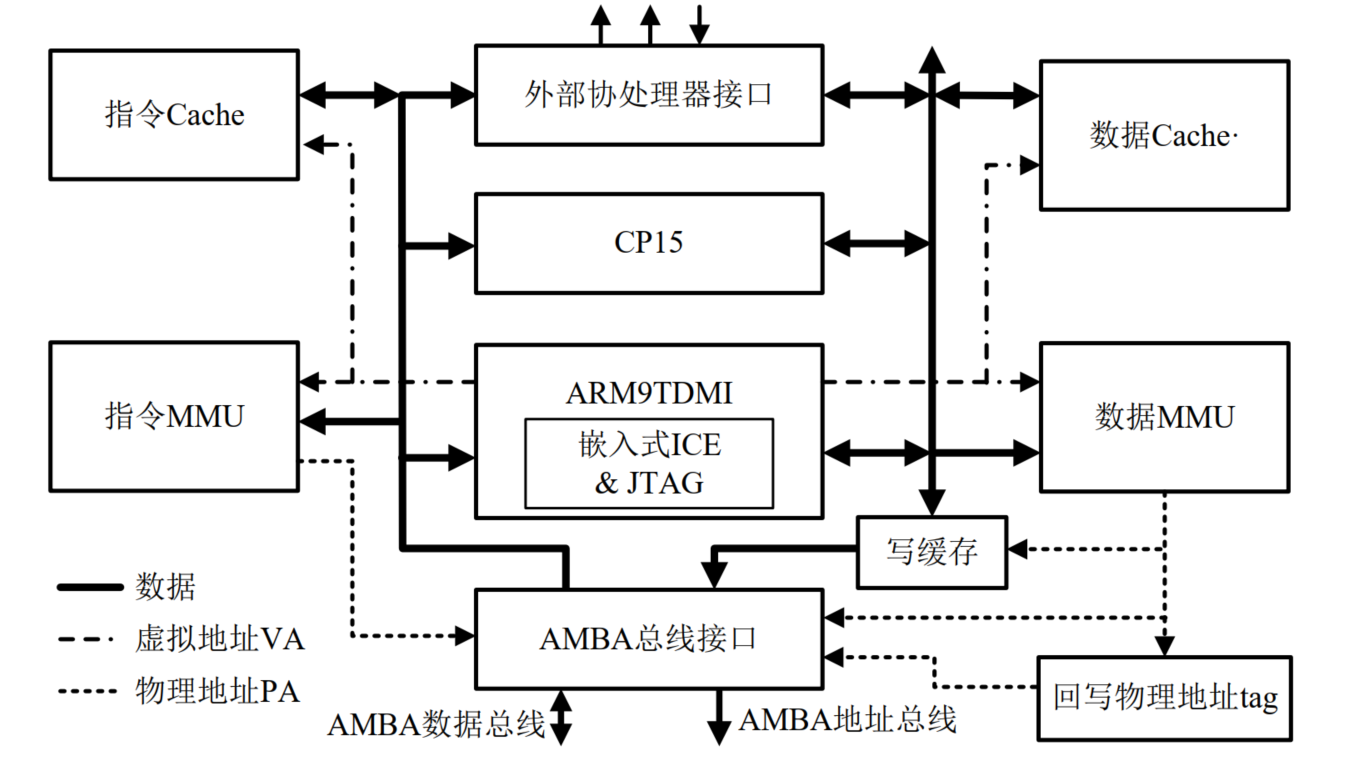
两类地址信号:物理地址PA和虚拟地址VA
- Physical Address:每个存储单元所拥有的真实地址
- Virtual Address:编程时所使用的地址,也称为逻辑地址
- 由MMU负责PA和VA的映射和转换
CP15:系统控制协处理器,用于管理和控制Cache、MMU、时钟类型和大小端设定等系统级操作
回写物理地址TAG:地址标记寄存器,存放Cache中需要回写(更新)数据字段在主存中的地址信息
数据总线上的写缓存:提高数据回写操作的速度
JTAG:符合JTAG规范的测试接口
2.8. 计算机性能评测
2.8.1. 定性描述指标
机器字长
计算机中的字长不仅影响计算精度,也影响运算速度。64位计算机的性能显然高于32位
存储容量
在计算机存储系统中,高速缓存和内存(主存)容量和类型是评价计算机系统性能的两项重要指标
一般来说,高速缓存和内存容量越大、存取速度越快,计算机的处理能力就越强
总线带宽和数据吞吐速率
一般来说,总线带宽取决于总线结构、位宽、主频等。数据吞吐速率还与存储器的存取速度、传送方式、数据的组织形式以及外设接口速度等因素有关
能耗与环保
关于CPU效能的指标主要有EPI,EPI指标越低,表明CPU的能源效率越高
计算机的环保指标:耗电量、辐射、噪声、各种器件中有害物质的含量、各种废弃物的可处理性等
RASIS特性
- Reliability,可靠性,MTTF与MBTF
- Availability,可用性,系统正常运行时间的百分比
- Serviceability,可维护性
- Integrity,集成性,all in one
- Security,安全性
2.8.2. 定量指标描述
定量描述指标:速度
一般来说,一台计算机的主频高、CPU数量或者内核数量多、高速缓存和主存容量大、总线传输速率高,表明计算机运算速度也快
早期指标:MIPS
对于执行相同的任务,RISC计算机相比CISC计算机要花费更多的指令,MIPS对CISC和RISC不能客观评价
现在指标:基准测试
Whetstone和Dhrystone
- 前者包括浮点数,后者只有整数,使用FORTRAN编写,代码量太小,与编译器有关
CoreMark
- 2009年由EEMBC提出,用C语言编写,包含嵌入式系统常见的4种计算(矩阵、查找和排序、状态机和CRC),已成为嵌入式内核标准评测的事实标准
SPEC测试,通用计算机使用最多的基准测试
- SPECjbb,用于评测JAVA应用服务器的性能
- SPECint,用于评测整数计算及编译器优化能力
- SPECfp,用于评测浮点数计算及编译器优化能力
- SPEC CPU,用于评测单核或多核处理器在进行整数及浮点数计算时的性能,包括多个种类和多个测试项目
其他基准测试
TPC
大型信息系统核心主机选型的重要依据
主要针对计算机在数据库应用及事务处理方面的性能,常见的有
- TPC-C,反映OLTP(联机事务处理)性能
- TPC-H,反映OLAP(联机事务分析)性能
Linpack(线性系统软件包)
一种高性能计算机系统浮点性能测试基准。通过在计算机(集群)系统中运行Linpack测试程序,可以得到能够反映高性能计算机浮点性能的测试结果Flops。在高性能计算领域,Linpack指标收到普遍重视
SAP基准测试
- SAP研发ERP在大型企业中得到广泛的应用,其测试结果对于ERP系统的硬件选型和配置具有一定指导意义
3. 存储器系统
3.1. 概述
3.1.1. 存储器的类型及特点
3.1.1.1. 半导体存储器
原理
半导体存储器是一种以半导体电路作为存储媒体的存储器,内存储器就是由成为存储器芯片的半导体集成电路组成
分类
按其功能分
- 随机存取存储器RAM
- 只读存储器ROM
按地位和作用分
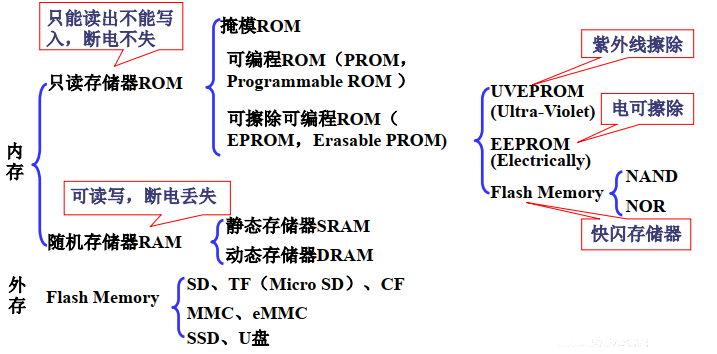
按结构和工艺分
- TTL(Transistor-Transistor Logic)
- COMS(Complementary metal-oxide-semiconductor)
按存储信息的可保存性分
- 易失性存储器
- 非易失性存储器
按存储器在计算机中的功能分
- 高速缓冲存储器(Cache)
- 主存储器
- 辅助存储器(外存储器)
优点
- 体积小
- 存储速度快
- 存储密度高
- 与逻辑电路接口容易
缺点
- 和磁芯存储器不同,半导体存储器如RAM,属于易失性存储器,在电源中断时数据消失
- 可擦除、可编程ROM,编程次数有限
3.1.1.2. 磁介质存储器
原理
利用磁性介质的磁极化来存储信息
分类
- 早期主要用磁泡、磁鼓和磁芯作为存储器
- 现在主要采用磁表面存储器;磁盘(硬盘、软盘)和磁带
特点
- 早期为主存。现在为外设,需接口电路支持
- 非易失性存储器,容量大,存取速度越来越快,体积不断减小。主要的外设,应用广泛
磁芯存储器结构和工作方式
磁芯在导线上流过一定电流情形下会被磁化或者改变磁化方向,实现通过实验和材料的工艺控制得到这个能够让磁芯磁化的电流最小阈值。根据磁化时电流的方向磁芯可产生两个相反方向的磁化,这就可作为0和1的状态来记录数据。每个磁芯都有XY互相垂直的两个方向的导线穿过,另外还有一条斜穿的读出线,这些线组成阵列,XY分别做两个不同方向的寻址
磁盘结构和工作方式
- 磁盘,是在一片或多片金属、薄膜或玻璃上覆盖磁性材料,由磁头随机存取表面被磁化的不同信息
- 以硬磁盘为代表的存储器,由硬磁盘、磁头、磁盘旋转运动机构,以及控制器组成,驱动盘片高速运动,由磁头沿径向运动进行存取信息的读写
- 作为计算机的海量外存,主要存储文件、图像和视频等
- 硬磁盘存储器已经是微型计算机系统最主要的标准外设之一,经过不断地技术进步,其容量越来越大,存取速度越来越高,而体积却不断减小
磁带结构和工作方式
- 磁带是一种柔软地带状磁性记录介质,由带基和磁表面层两部分组成,带基多为薄膜聚酯材料,磁表面层所用材料多为和等
- 由磁带传送机构、赐福控制电路、读写磁头、读写电路和有关逻辑控制电路等组成。驱动磁带相对磁头运动,用磁头进行电磁转换,在磁带上顺序地记录或读出数据
- 磁带控制器是中央处理器在磁带机上读写数据用的控制电路装置。存储数据地磁带可脱机保存和互换读出
3.1.1.3. 光存储器
原理
光盘上刻有凹点和空白,光照射后辐射强度不同,接收电路再转化为0、1地数字信号
分类
- 只读型光盘
- 可记录型光盘
光驱结构和工作方式
- 光驱组成:激光头组件(激光发射器、半分光棱镜、物镜、透镜以及光电二极管)、驱动机械部分、电路及电路板(电源电路、前置信号处理电路、聚焦/循迹/径向/主轴伺服电路、光电转换及控制电路、DSP数字信号处理电路等)、IDE解码器及输出接口、控制面板及外壳等
- 工作方式:驱动光盘高速旋转,激光二极管产生对应波长地激光光束,照射光盘表面,经由激光头组件中地光电二极管捕捉反射回来地信号从而识别实际地数据
特点
- 作为计算机外设:内置、外置。不同类型地光盘需要不用类型设备地支持
- 非易失性存储器,容量大,成本低,应用广泛
3.1.2. 微机系统的存储体系架构
微型计算机系统的存储体系架构是分层次的,离CPU越近的存储器,速度越快,每字节的成本越高,同时容量越小。按照与CPU由近到远的距离,有
按照访问速度快慢和容量,有
简单的二级结构:内存+外存
完整的四级结构:寄存器+Cache+主存+辅存(联机、脱机外存)
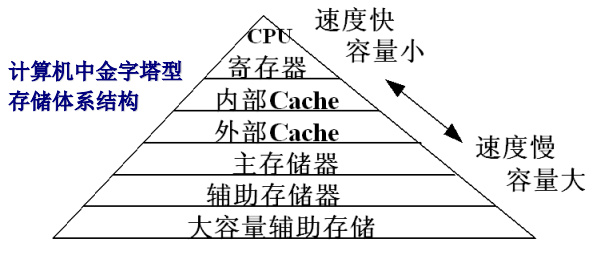
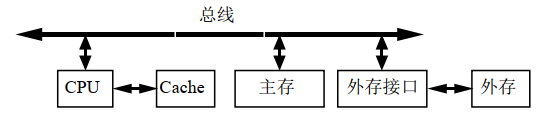
寄存器
组成
- 采用触发器,构成中央处理器CPU中地一部分
功能
- 暂存指令、数据和地址
特点
- CPU处理的数据先提取到寄存器。有限存储容量,高速
高速缓冲存储器Cache
组成
存在于CPU与内存之间,由静态存储芯片SRAM组成
功能
CPU向内存读取数据时,首先查询Cache存储体缓存区是否有对应数据,如果有则直接读取,没有再从内存中读取
特点
- 成本高,容量比较小。但速度比内存高得多,近于CPU的速度
- 系统动态管理缓存中的数据,如果有数据访问频率降低到一定值,就从Cache存储体中移除,而将内存中访问更加频繁的数据替换进去
主存储器
组成
- 主存储器,简称内存,是计算机运行过程中的存储主力,主要由DRAM和ROM组成
- 在一些特殊类型或者小容量应用场合,如,在嵌入式系统中,也采用SRAM作为主存
功能
程序的运行都是在内存中进行。存储指令(编译好的代码段),运行中的各个静态,动态,临时变量,外部文件的指针等等
特点
成本较高,容量比较大,速度高,但比Cache低得多
辅存
联机外存储器
组成:主要为磁介质的机械硬盘、固态硬盘SSD
功能:存储需要永久存储的文件
特点:
- 磁介质机械硬盘空间大,价格便宜
- 固态硬盘在接口的规范和定义、功能及使用方法上与普通机械硬盘完全相同,在产品外形和尺寸上也完全一致
脱机外存储器
- 移动硬盘、光盘、U盘、Flash等便携式存储器,便于携带
3.1.3. 辅助存储器主要接口标准
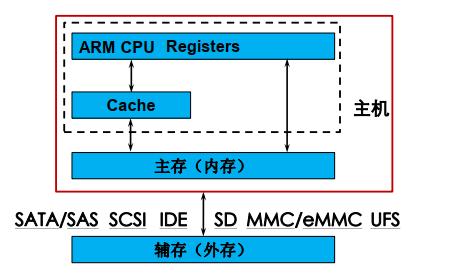
常将联机、脱机存储器称为辅助存储器。辅助存储器接口,主要包括硬盘接口标准、Flash存储卡的接口标准等。通用的接口标准为不同类型辅助存储器产品提供接入的互换性,便于产品升级和维护
微机常用存储接口:
嵌入式设备常用存储接口:
IDE接口
- IDE又称为ATA,用40/80针排线连接PC机和硬盘,16位双向总线并行传送,盘体与控制器集成一起以减少接口电缆长度,提高传输可靠性
- 后发展为Ultra DMA,最快的Ultra DMA133接口的时钟达到133MHz
- 由于采用并行接口传输数据,也称为PATA硬盘
SCSI接口
- 并行接口,用于计算机及其周边设备之间(硬盘、软驱、光驱、打印机、扫描仪等)系统级接口的独立处理器标准
- 配专门SCSI控制卡,最多连15个硬盘,也可驱动其他SCSI接口外设
- 优点:CPU占用率低,多任务并发操作效率高,转速高,传输速度快,更稳定,支持热插拔,连接设备多,连接距离长等
- 成本高,多用于中高端的服务器和工作站。主流的Ultra 320SCSI的速度为320MB/s
SATA接口
- SATA使用了差动信号系统,能有效滤除噪声
- 4针串行点对点传输数据,一次传一位,但总线8位,每时钟周期能传送1字节,并用数据包传送,速率达150MB/s
- 接口结构简单,能减小功耗,支持热插拔,还能对传输指令进行检查,并自动纠错,传输可靠性高
- SATA2和SATA3是最新硬盘接口,传输速度分别达到300MB/s和600MB/s
SAS接口
- 串行连接SCSI接口
- 新一代SCSI技术,它和SATA接口那样采用串行技术来获得更高的传输速度,并通过缩短连线来改善内部空间等
- SAS的接口技术可以向下兼容SATA,而SATA系统不兼容SAS
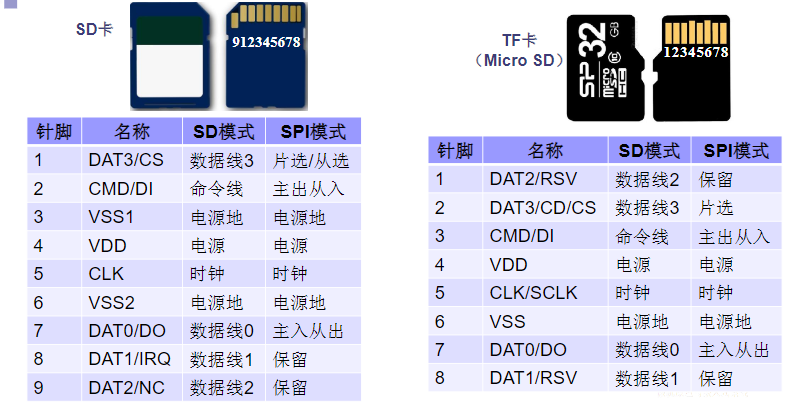
SD接口
- SD卡的数据传送和物理规范由MMC(Multi Media Card)发展而来,大小和MMC卡相似,长宽和MMC卡一样,比MMC卡厚0.7mm
- SD卡集成了闪存记忆卡控制器、MLC(Multilevel Cell)和NAND闪存,通过9针的接口界面与专门的驱动器相连接
- SD卡系统是一个新的大容量存储系统,提供了一个便宜的、结实的卡片式的存储媒介
- SD卡的低耗电和广供电电压,可以满足移动电话、电池应用。使用非常有效的数据压缩比如MPEG,SD卡可以提供足够的容量来存储多媒体数据
- SD卡衍生类型Micro SD(T-Flash,简称TF)卡,具有更小的尺寸,在大部分场合替代了常规的SD卡,成为脱机外存储器的主流
eMMC接口
嵌入式存储器接口
- 嵌入式MMC,基于MMC协议的内嵌式存储器标准规格。主要针对使用成本较低的数据存储和传播媒体产品,手机或平板电脑等产品
- eMMC=控制器+NAND Flash+MMC标准封装接口
- eMMC封装为MCP芯片。为BGA封装
- eMMC支持MMC、SPI模式
特点
- 接口速度高达每秒400MBytes
- 不需处理其它复杂的NAND Flash兼容性和管理问题,简化了存储器的设计
- eMMC加快了新产品更新速度,减少研发成本,缩短新产品研发周期
- eMMC为半双工方式。将有被全双工的UFS取代的趋势
UFS
UFS,即“通用闪存存储”,同样是一种内嵌式存储器的标准规格,由JEDEC(Joint Electron Device Engineering Council)发布。同样是整合有主控芯片的闪存,不过其使用的是PC平台上常见的SCSI结构模型并支持对应的SCSI指令集
UFS是UFSHCI标准JESD223的扩展
UFSHCI标准定义了UFS驱动程序和UFS主机控制器之间的接口。除寄存器接口外,它还定义了系统内存中的数据结构,用于交换数据,控制和状态信息
技术特点
- 串行传输,全双工,同一通道允许读写传输,读写能够同时进行,单通道带宽达1.5GB/s以上,传输效率有效提高
- 抗EMI和串扰
- 差分信号可以使用较低的电压,并且由于提高了抗噪声性能,获得更好的信噪比(SNR)
- 差分信号集成到UFS卡,降低接收器电路复杂性
- CLK线上的电阻,通过阻尼减少信号失真和EMI
- 电源电容,去耦以及储能
3.2. 半导体存储芯片的基本结构和性能指标
电子计算机主板上主要采用半导体存储器,称为内存
内存用来存放当前执行的数据和程序,有易失性和非易失性两种
RAM:易失性存储器,仅用于暂时存放程序和数据,关闭电源或断电数据会丢失
ROM:非易失性存储器,用于存放程序或静态数据,即使断电,数据也不会丢失
3.2.1. 随机存取存储器RAM
简介
特点:
- 在使用过程中即可利用程序随时写入信息,又可随时读出信息,分为双极型和MOS型两种。前者读写速度高,但功耗大,集成度低,故在微型机主存中几乎使用后者
分类:
静态RAM(SRAM):其存储电路以双稳态触发器为基础,状态稳定,只要不掉电,信息不会丢失。
- 优点是不需刷新
- 缺点是集成度低。适用于不需要大存储容量的微型计算机(例如,单板机和单片机)中
动态RAM(DRAM):其存储单元以电容为基础,电路简单,集成度高。但也存在问题,即电容中电荷由于漏电会逐渐丢失,因此DRAM需定时刷新电路。它适用于大存储容量的计算机
静态RAM(SRAM)
特点
- 用双稳态触发器(SR锁存器)存储信息
- 速度快(双极型<5ns,MOS型几十~几百ns ),不需刷新,外围电路比较简单,但集成度低(存储容量小,约1Mbit/片),功耗大
- SRAM被广泛地用作高速缓冲存储器Cache
- 对容量为的SRAM芯片,其地址线数=;数据线数=。反之,若SRAM芯片的地址线数为,则可以推断其单元数为个。如,地址线分别为13、10根,则单元数为
基本存储电路
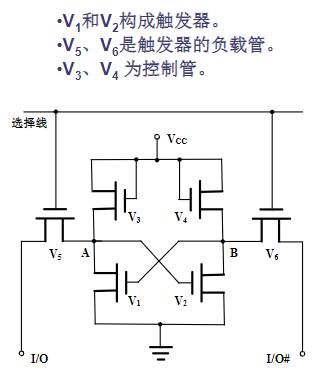
- 管组成双稳态锁存器,用于记忆1位二值代码
- 截止 → A为高电平 → 导通 → B为低电平 → 截止 → 状态“1”
- 导通 → A为低电平 → 截止通 → B为高电平 → 导通 → 状态“0”
- 控制管、 实现状态控制
工作原理
保持状态
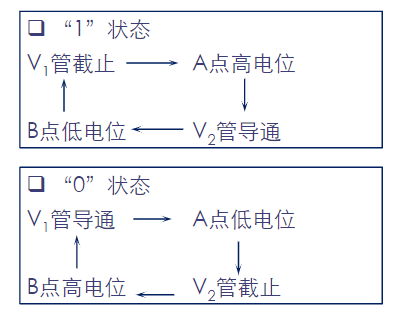
读出状态
选择线通过译码控制为高电平

写入状态
选择线通过译码控制为高电平

静态RAM芯片结构
静态RAM芯片内部由多个基本存储电路单元组成,容量为单元数与数据线位数之乘积
为了选中某一个单元,往往利用矩阵式排列的地址译码电路:行选择信号 + 列选择信号
- 例如,1K单元的内存需10根地址线,其中5根用于行译码,另5根用于列译码
- 译码后在芯片内部排列成32条行选择线和32条列选择线,这样可选中1024个单元中的任何一个,而每一个单元的基本存储电路的个数与数据线位数相同
常用的典型SRAM芯片有6116、6264、62256、628128等
以6116芯片为例:
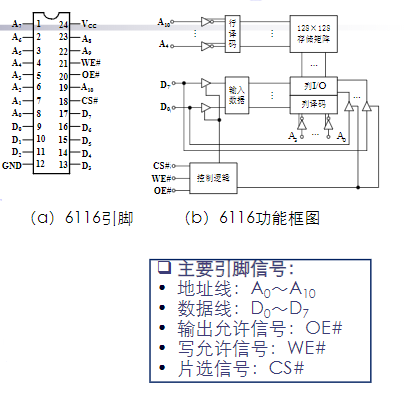
6116芯片的容量为位
2048个存储单元需11根地址线
- 7根用于行地址译码输入,4根用于列译码地址输入
- 每条列线控制8位,形成了128×128个存储阵列,即16384个存储位
6116控制线有三条:片选CS#、输出允许OE#和写入允许(读写控制)WE#
工作过程:
读出
- 地址输入线送来的地址信号经地址译码器送到行、列地址译码器
- 译码后选中一个存储单元(8个存储位)
- 由CS#、OE#、WE#构成读出逻辑(CS#=0,OE#=0,WE#=1)
- 打开右面的8个三态门,被选中单元的8位数据经I/O电路和三态门送到D7~D0输出
写入
- 地址输入线送来的地址信号经地址译码器送到行、列地址译码器
- 译码后选中一个存储单元(8个存储位)
- 由CS#、OE#、WE#构成写入逻辑(CS#=0,OE#=1,WE#=0)
- 打开左边的三态门,从D7~D0端输入的数据经三态门和输入数据控制电路送到I/O电路,从而写到存储单元的8个存储位中
无读写操作
- CS#=1,即片选处于无效状态,输入输出的三态门均为高阻状态,存储器芯片与系统总线断开
动态RAM(DRAM)
特点
- DRAM是靠MOS电路中栅极电容存储信息,电容上的电荷会逐渐泄漏
- 需要定时充电以维持存储内容不丢失(称为动态刷新),动态RAM需要设置刷新电路,相应外围电路就较为复杂。刷新定时间隔一般为几微秒~几毫秒
- 集成度高(存储容量大,可达1Gbit/片以上),功耗低,但速度慢,约为SRAM的一半,需要刷新
- DRAM在微机中应用广泛,如微机中的内存条(主存)、显卡上的显示存储器几乎都是用DRAM制造的
存储原理
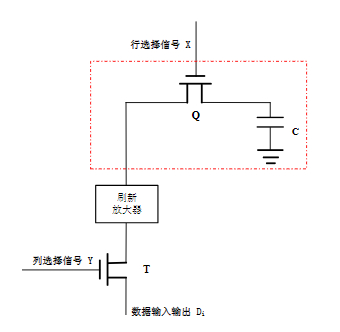
存储单元由1个MOS管和1个小电容构成
- 电容C充满电荷便保存了逻辑"1"
- 电容C无电荷为逻辑“0”
数据输入输出端连数据总线的某一位Di(位线)
低位地址(如A0~ A7)译码产生行选信号X,高位地址(如A15~A8)译码产生列选信号Y。X、Y都为高电平时该单元被选中
刷新操作:
- 电容C上保存的电荷会逐渐泄漏。故DRAM使用过程中需要及时向保存“1”的那些存储单元补充电荷,也就是对电容C进行预充电,这一过程称为DRAM的刷新
- 刷新逐行进行,当某一行选择信号X为“1”时,选中了该行,电容上信息送到刷新放大器上,刷新放大器又对这些电容立即进行重写。刷新时,列选择信号Y为“0”,因此电容上信息不会被送到数据总线上
- 温度升高会加快电容放电,因此两次刷新的间隔不能太短,规定为1~100ms。在70°C时的典型刷新间隔为2ms,绝大多数刷新电路按此标准设计
写操作时,X=1,Y=1,Q和T管均导通,要写入的值(0或1)从Di加到C上
读操作时,Q和T同样导通,存储在C上电荷通过Q、刷新放大器和T输出到Di
DRAM芯片举例
常见小容量DRAM芯片有:
- 64K×1位-4164/2164
- 256K×1位-41256
- 1M×l位-21010
- 256K×4位-21014
- 4M×1位-21040... ...等
大容量DRAM芯片有:
- 16M×16位
- 64M×4位
- 32M×8位
- 256M×4位
- 512M×4位(DDR结构)...等
DRAM芯片举例:Intel 2164A
- 单管存储电路设计,容量:64K×1位
- 数据线有二根:数据输入和输出;
- 8根地址输入脚A7~A0,分时接收8位行、列地址;
- 行和列地址选通信号RAS#和CAS#输入端;
- 读写命令WE# , 0-写,1-读
以Intel 264A为例
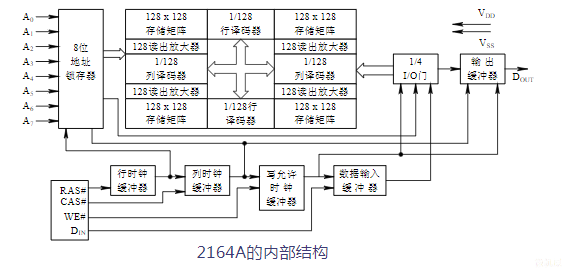
Intel 264A的地址线与寻址
- 容量为64K×1位,即片内有65536个存储单元,每个单元只有1位数据,用8片2164A才能构成64K字节的存储器。若想在2164A芯片内寻址64K个单元,则需要用16条地址线。但为减少地址线引脚数目,地址线又分为行地址线和列地址线,进行分时工作,这样DRAM对外部只需引出8条地址线
- 芯片内部有地址锁存器,利用多路开关,由行地址选通信号RAS,把先送来的8位地址送至行地址锁存器加以锁存。由随后出现的列地址选通信号CAS把后送来的8位地址送至列地址锁存器加以锁存
64K×1存储主体,设计成4个128×128矩阵
4个128路刷新放大器,接收由行地址选通的4×128个存储单元信息,经放大后再写回原存储单元进行刷新
16位地址分为行地址A7~ A0和列地址A15~A8,以分时复用方式,分两次送入芯片。行地址在先,列地址随后,各由一个8位地址锁存器保存
两次送来的8位地址信息的最高位(A7和A15),形成RA7和CA7去控制4选1的I/O门电路,从4个矩阵中选择1个进行读/写
行/列地址译码器对行/列地址的低7位进行译码,从某个128×128个单元中选择1个进行读/写
行地址到达,选通信号RAS#变低;列地址到达,选通信号CAS#变低。经行/列时钟缓冲器协调后,有序控制行/列地址的选通以及数据读/写或刷新
要写入的1位数据从脚输入,由数据输入缓冲器暂存;准备从脚读出的1位数据,也先由输出缓冲器暂存
写允许WE#以及RAS#、CAS#信号, 通过写允许时钟缓冲器控制后, 决定打开哪个数据缓冲器
DRAM存储条
内存条
- PC配置的内存已高达16GB、32GB,服务器更高达256GB,要求更高的DRAM集成度
- 容量为1G位以及更高集成度的存储器芯片已大量使用。通常,把这些芯片放在内存条上形成更大存储容量,用户只需把内存条插到系统板上提供的存储条插座上即可使用。
- 内存条标准化,实现通用和互换,便于维护和升级
内存条的主要技术指标
- 容量:用户最关心的指标,每种内存条都有多种容量规格
- 时钟频率:内存芯片的基本工作频率,即表5.2中列出的时钟频率
- 数据速率:芯片上每根引脚可传输数据的速率
- 数据宽度:可同时传输数据的位数,现大多为64位
- 奇偶校验:在每1字节外增加了1位,用作出错检测
- ECC功能:出错检查和修正功能
- ......
存储条示例
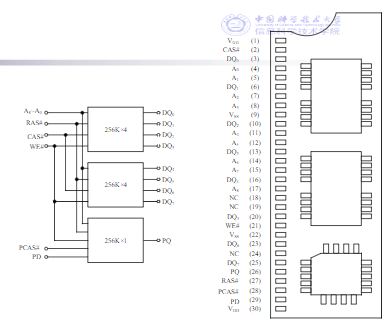
图中是采用HYM59256A存储芯片,构成256K×9位存储容量的存储条
其中,2片256K×4位的存储芯片通过位扩展形成256K字节的存储单元,1片256K×1位的存储芯片作为奇偶校验
引脚
- A8~A0为地址输入线。
- DQ7~DQ0为双向数据线,PD为奇偶校验数据输入,PCAS#为奇偶校验的地址选通信号,PQ为奇偶校验数据输出。
- WE#为读写控制信号,RAS#、CAS#为行、列地址选通信号。
- VDD为电源(+5V),VSS为地线。
- 30个引脚定义是存储条的通用标准之一
3.2.2. 只读存储器ROM
只读存储器(ROM)掉电后信息不会丢失(非易失性或不会挥发性),弥补了RAM的不足,因此成为计算机中的一个重要部件
ROM包括掩模ROM、PROM、EPROM、EEPROM等多种类型
掩模ROM和PROM已淘汰,广泛使用的是EEPROM 和Flash
注意:
- ROM早已不是“只读”,仍称为ROM只是一种习惯
- 只读,是相对于CPU的读写控制电平及其控制逻辑而言
- EEPROM、Flash都是可在线编程读写的,只不过需要专门的写、擦除电平和时序
掩膜ROM
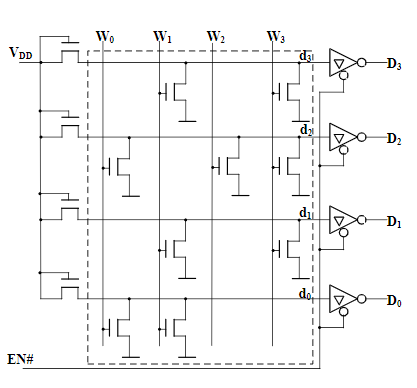
Mask ROM(掩膜ROM)的存储数据由专门设计的掩模板决定,为固化数据,用户不能修改
ROM电路结构包括存储矩阵、地址译码器和输出缓冲器三个组成部分
- 存储矩阵由许多存储单元排列而成。存储单元可以用二极管构成,也可以用双极型三极管或MOS管构成。每个单元能存放一位二值代码(0或1)。每一个或一组存储单元有一个对应的地址代码
- 地址译码器的作用是将输入的地址代码译成相应的控制信号,利用这个控制信号从存储矩阵中将指定的单元选出,并把其中的数据送到输出缓冲器
- 输出缓冲器的作用有两个,一是能提高存储器的带负载能力,二是实现对输出状态的三态控制,以使与系统的总线连接与隔离
掩膜ROM芯片示例:
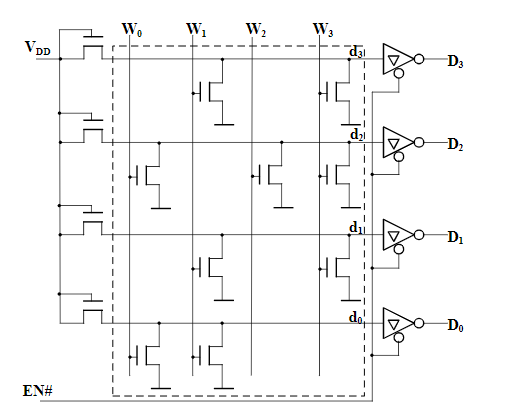
4位数据输出,4×4位的MOS管,单译码结构
地址线A1、A0,译码后可译出4种状态W3~ W0。输出4条选择线,分别选中4个单元,每个单元4位输出
存储矩阵由MOS门组成,当W3~ W0每根线上给出高电平信号时,都会在4根线d3~ d0上输出一个4位二值代码
将每个输出代码称为一个“字”,并将W3~ W0称为字线,将d3~d0称为位线(或数据线),而A1、A0称为地址线
输出端的缓冲器用来提高带负载能力,并将输出的高、低电平变换为标准的逻辑电平
通过给定EN#信号实现对输出的三态控制,将数据反相输出
若地址线A1A0=00,则选中0号单元,即字线0为高电平,若有MOS管与其相连(如位线d2和d0),其相应的MOS管导通,位线输出为0,而位线1和3没有MOS管与字线相连,则输出为1
- 行列交叉处有无MOS管分别表示了“0”和“1”
掩膜ROM存储矩阵的内容:
单元/位 d3 d2 d1 d0 0 1 0 1 0 1 0 1 0 0 2 1 0 1 1 3 0 0 0 1
可编程ROM(PROM)
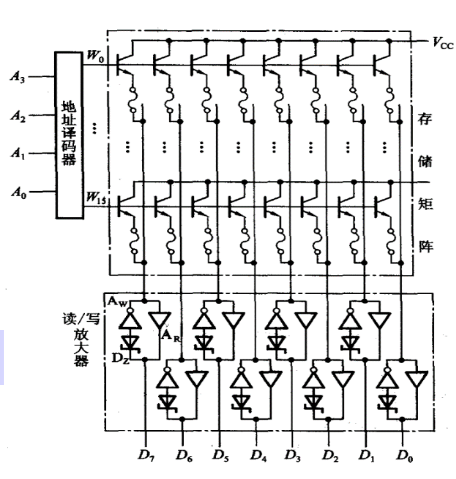
简介
- 可编程ROM,即PROM是一种简单的可编程逻辑器件PLD
- PROM的总体结构与掩模ROM一样,同样由存储矩阵、地址译码器和输出电路组成
- 在出厂时已经在存储矩阵的所有交叉点上全部制作了存储元件,即相当于在所有存储单元中都存入了“1”
- 用户可以根据需要将其中的某些单元写入数据“0”(部分的PROM在出厂时数据全为“0”,则用户可以将其中的部分单元写入“1”),以实现对其“编程”的目的
PROM采用经典的“双极性熔丝结构”
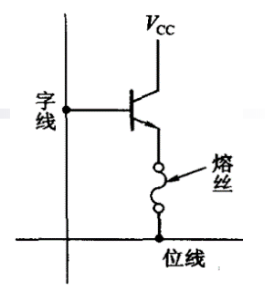
- 由一只三极管和串在发射极的快速熔断丝组成
- 三极管be结相当于接在字线与位线之间的二极管,熔丝用很细的低熔点合金丝或多晶硅导线制成
- 如果改写某些单元,则可以给这些单元通以足够大电流,维持一定时间后,需存入0的那些存储单元上的熔丝烧断
编程过程
- 地址译码器选择要编程的地址,找出要写“0” 的单元地址
- 将VCC和选中的字线提高到编程所要求的高电平
- 在编程单元的位线上加入编程脉冲(幅度约20V,持续时间约十几微秒)
- 写入放大器AW的输出为低电平、低内阻状态,有较大的脉冲电流流过熔丝,将其熔断
- 正常工作时读出放大器AR输出的高电平不足以使DZ导通,AW不工作
EPROM
简介
可擦除可编程ROM
- 采用叠栅注入MOS管SIMOS (Stacked-gate Injection MOS)做存储单元
是一个N沟道增强型的MOS管,有两个重叠的栅极—控制栅Gc和浮置栅Gf
- 控制栅Gc用于控制读出和写入
- 浮置栅Gf用于长期保存注入电荷
初始状态
- 浮栅上未注入电荷以前,在控制栅上加入正常的髙电平能够使漏-源之间产生导电沟道,MOS管导通,存储信息“0”
重复擦写编程的EPROM
- 利用编程器写入后,信息可长久保持,因此可作为只读存储器
- 需要变更时,可利用擦除器将其擦除,各单元内容读出值为FFH
- 再根据需要利用EPROM编程器编程,因此这种芯片可反复使用
编程原理
- 漏-源间加较高电压(约+20~+25V),发生雪崩击穿
- 同时在控制栅上加以高压脉冲(幅度约+25V,宽度约50ms)
- 在栅极电场作用下,一些高能量电子穿越SiO2层到达浮置栅,被浮置栅俘获而形成注入电荷
- 浮置栅上注入了电荷的SIMOS管相当于写入了“1”,未注入电荷的相当于存入了“0”
擦除原理
- 存储器芯片开有玻璃窗口
- 用特定波长紫外线照射该窗口数分钟,所有存储单元浮栅上的电荷会形成光电流泄放掉,使浮栅恢复初态
- 擦净的芯片可重新编程
- 编程过程总是从头到尾,对1块芯片的全部单元进行重写,因此不能修改芯片中的部分内容(哪怕1个字节)
- 通过编程器写入新的数据后,需要将窗口用不透光胶带遮蔽,避免紫外线照射而使电荷泄放,以防数据丢失
EPROM芯片示例
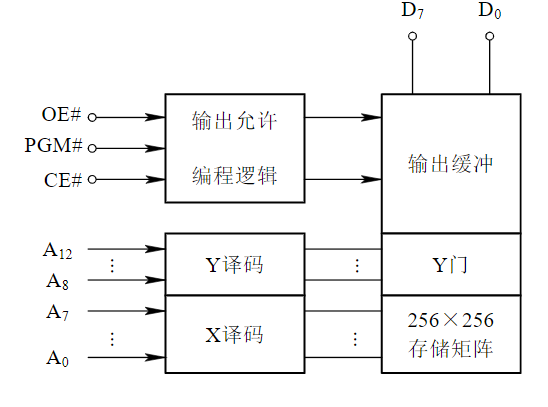
EPROM芯片有多种型号,如2716(2K×8 位)、2732(4K×8 位)、2764(8K×8 位)、27128(16K×8 位)、27256(32K×8 位)等
典型EPROM芯片2764A
- 28脚DIP封装
- 13条地址线A12~A0
- 8条数据线D7~D0
- 2个电压输入端VCC和VPP
- 片选端CE#(功能同CS#)
- 输出允许OE#
- 编程控制端PGM#
读方式(数据)
- VCC和VPP都接至+5 V,PGM#接至高电平
- 当从2764A的某个单元读数据时,先通过地址引脚接收来自CPU的地址信号,然后使控制信号和CE#、OE#都有效
- 经过一个时间间隔,指定单元的内容即可读到数据总线上
读方式(读Intel标识符)
- A9引脚接至11.5~12.5 V
- 分两次顺序读出两个字节,先让A1~A8全为低电平,而使A0从低变高
- A0=0,读出制造商编码(陶瓷封装为89H,塑封为88H)
- A0=1,读出器件编码(2764A为08H,27C64为07H)
备用方式
- CE#为高电平,2764A就工作在备用方式,输出端为高阻状态
- 芯片功耗将下降,从电源所取电流由100 mA下降到40 mA
编程方式
- VPP接+12.5V,VCC接+5V
- 从数据线输入数据
- CE#端保持低电平,OE#为高电平
- 每写一个地址单元,都必须在PGM#引脚端给一个低电平有效,宽度为45 ms的脉冲
编程禁止
- 在编程过程中,只要使该片CE#为高电平,编程立即禁止
编程校验方式
- 完成一个字节编程后,电源接法不变
- PGM#为高电平,CE#、OE#均为低电平
- 则同一单元数据在数据线上输出,这样就可与输入数据相比较,校验编程结果是否正确
快速编程方式
- 传统编程按字节方式,宽度为45 ms的编程脉冲,速度慢。且容量越大,速度越慢
- 新的编程方法提高速度达6倍以上
- 思路:Vpp上加编程电压,用1ms编程脉冲依次写完所有数据,再从头开始校验;若有错误,重写此单元
小结
2764A的工作方式选择表
方式/引脚 CE# OE# PGM# A9 A0 VCC Vpp 数据端功能 读 低 低 高 × × 5V VCC 数据输出 输出禁止 低 高 高 × × 5V VCC 高阻 备用 高 × × × × 5V VCC 高阻 编程 低 高 低 × × VCC 12.5V 数据输入 校验 低 低 高 × × VCC 12.5V 数据输出 编程禁止 高 × × × × VCC 12.5V 高阻 标识符 低 低 高 高 低 5V VCC 制造商器件编码 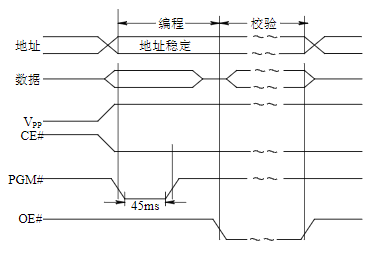
EPROM存在的问题
- EPROM虽可多次重新编程使用,但是整个芯片只要写错一位,就必须从电路板上取下擦掉重写,擦除时间很长,因而使用不便
- 在实际应用中,往往只要改写几个字节的内容,因此多数情况下需要以字节为单位进行擦写
电可擦除可编程ROM(EEPROM,E2PROM)
基本特性
- 可以在电路板上直接编程写入(在系统编程)
- 允许以字节为单位擦除和重写,而EPROM需要将整个芯片所有的信息擦除后才能重写
- 使用单一的+5V电源,不需要专门的编程电源
- 在写入过程中自动进行擦写,一个字节的擦写时间远远小于EPROM所需的时间,约需10ms左右(但还是远远大于RAM)
- 无需专用电路,只要按一定的时序操作即可进行在线擦除和编程
工作原理
- 采用了一种称为浮栅隧道氧化层MOS管(Floating gate Tunnel Oxide,简称Flotox管)。Flotox管与SIMOS管相似,属于N沟道增强型的MOS管,有两个栅极—控制栅GC和浮置栅Gf
- 在E2PROM中,使浮动栅带上电荷与消去电荷的方法与EPROM不同
- 在E2PROM中,在浮动栅上方增加了一个控制栅,而浮动栅与漏极之间有一层极薄的氧化硅,称为隧道区(隧道二极管),在控制栅与源极之间的电压(实际是在电场)VG的作用下,电荷通过隧道流向浮空栅,实现写入
- 若VG的极性相反,则使电荷从浮动栅流向源极,即起擦除作用。编程与擦除所用的电流是极小的,可用普通的电源供给
结构示意

为了提高擦、写的可靠性,并保护隧道区超薄氧化层,在E2PROM的存储单元中除Flotox管外还附加了一个选通管T2。右图中的T1为Flotox管(也称为存储管),T2为普通的N沟道增强型MOS管(也称为选通管)
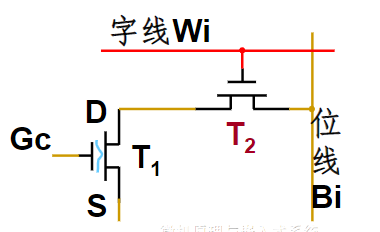
工作过程
读出
- 字线加高电平使选通管T2导通
- T1管浮置栅没充负电荷 → T1管导通 → 在位线上读出“0”(低电平)
- T1管浮置栅充有负电荷 → T1管截止 → 在位线上读出“1”(高电平)
写入
- 使写入为“0”的存储单元的T1管浮置栅放电
- 控制栅GC为0电平
- 同时在字线和位线上加+20V左右、宽度约10ms的脉冲电压
- 浮置栅存储电荷通过隧道区放电,使T1管开启电压降为0V左右,成为低开启电压管
擦除
- 控制栅、字线施加+20V左右、宽度约10ms脉冲电压,漏区接0电平
- 浮置栅存储的负电荷,使Flotox管的开启电压提高到+7V以上
- 读出时控制栅上电压只有+3V,故T1管不导通。一个字节擦除后,所有的存储单元均为1状态
典型芯片
E2PROM的主要产品有:
- 早期的高压编程芯片,如:2816、2817...
- 低压编程芯片,如:2816A、2817A、2864A...
- “大容量”28010(1M位,128KB)、28040(4M位)等
主要技术指标
- 读取时间120~250ns
- 字节擦写时间10ms左右
- 写入时间与字节擦写时间相当,约10ms左右
举例:2816芯片
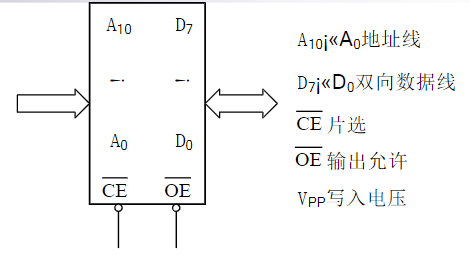
基本特点
- 2 K×8 位的E2PROM
- 24脚DIP封装
- 2816为双向数据线,以适应读写工作模式
- 2816的读取时间为250ns,可满足多数微处理器对读取速度的要求
- 最突出的特点是可以字节为单位进行擦除和重写
- 擦或写用CE#和OE#信号加以控制,一个字节的擦写时间为10ms
- 2816可整片进行擦除,整片擦除时间也是10ms
- 无论字节擦除还是整片擦除均在机内进行
工作方式选择表
方式/引脚 CE# OE# VPP/V 数据端功能 读 低 低 +4V~+6V 输出 备用 高 × +4V~+6V 高阻 字节擦除 低 高 +21V 输入为高电平 字节写 低 高 +21V 输入 片擦除 高 +9~+15V +21V 输入为高电平 擦写禁止 低 × +21V 高阻 2816读方式
- 允许CPU读取2816的数据
- 发出地址信号以及相关的控制信号
- CE#、OE#信号有效
- 延时读取,有效数据出现在总线上
2816写方式
以字节为单位的擦除和写入是同一种操作,即均为写
字节擦除与写入
- CE#为低电平
- OE#为高电平
- 数据线为字节数据
- VPP端输入编程脉冲,宽度最小为9ms,最大为70ms,电压为+21V
- 字节擦除是固定写“1”,数据输入是TTL高电平
2816片擦写方式
- 两种擦除方式:片擦除、字节擦除
- CE#为高电平
- OE#引脚电压达+9~+15V
- VPP接+21V编程脉冲
- 数据输入引脚置为TTL高电平
- 约经10ms,整片内容全部被擦除,即2KB的内容全为FFH
2816备用方式
- 进入备用状态,输出呈高阻态
- CE#端加TTL高电平
- OE#控制无效
- 备用状态下,其功耗可降到55%
快闪存储器Flash
简介
- 快闪存储器,常称为闪存,也称快擦写存储器,简称Flash Memory
- 闪存是一个笼统的称呼,准确地是指具有快速擦写和非易失等特性的存储器件
- 与普通存储芯片不同,闪存内部通常还带有多个寄存器和内部控制逻辑,可以编程选择闪存的工作方式和操作内容
- 由于闪存的存储密度(容量)大、非易失、存取速度快等特点,成为各个主要半导体厂商争先恐后的研发重点,新技术、新材料和新产品不断涌现
- 除了半导体以外,采用新型材料作为存储介质的全新一代闪存也在不断涌现、发展和完善之中
工作原理
目前常见的半导体闪存工作原理类似于E2PROM,采用MOS工艺
- 浮空栅保存有电荷 → 源、漏极之间形成导电沟道 → 稳定状态 → 保存信息“0”
- 浮空栅没有电荷 → 源、漏极之间无法形成导电沟道 → 稳定状态 → 保存信息“1”
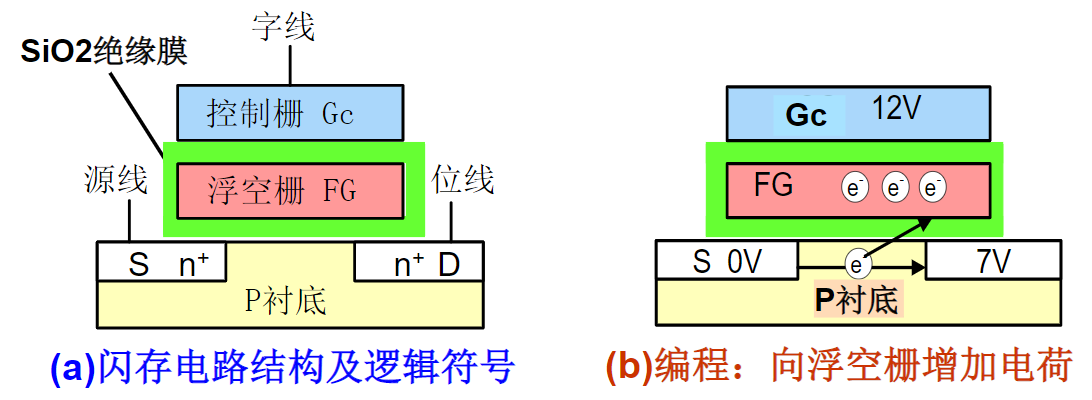
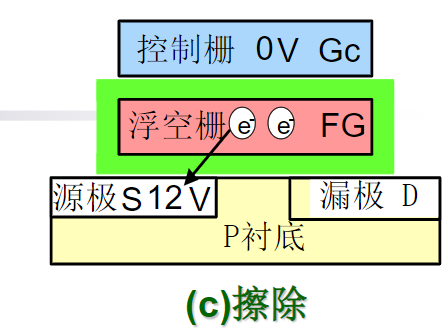
Flash与E2PROM的区别
Flash没有选通管T,因此集成度高,容量大,但稳定性和擦写次数都不如E2PROM
E2PROM可按位擦除,Flash只能按块(或按页或行)擦除
Flash的缺陷:由于闪存写入时有“突破氧化膜”这一剧烈动作,不仅限制了写入速度,而且随着反复的写入,氧化膜出现老化。NOR和NAND闪存可擦写次数分别限制在10万次和100万次左右
工作方式
- 读出:源极VSS接地,字线为5V逻辑高电平
- 写入:利用雪崩注入法。源极VSS接地;漏极接6V;控制栅12V脉冲,宽10s
- 擦除:利用隧道效应。控制栅接地;源极接+12V脉冲,宽为100ms。用于片内所有叠栅管的源极都连在一起,所以一个脉冲就可以擦除全部单元
分类
- 基于MOS工艺的闪存从结构上就有:AND、NOR、NAND、DiNOR等类型,其中NAND和NOR是目前的主流类型
- 快闪存储器Flash分为NAND flash和NOR flash二种
- NAND flash的擦和写均是基于隧道效应,电流穿过浮置栅极与硅基层之间的绝缘层,对浮置栅极进行充电(写数据)或放电(擦除数据)
- NOR flash擦除数据是基于隧道效应(电流从浮置栅极到硅基层),但在写入数据时则是采用热电子注入方式(电流从浮置栅极到源极)
NOR型闪存

- N是NOT,含义是浮置栅中有电荷时,读出‘0’,无电荷时读出‘1’,是一种‘非’的逻辑;OR的含义是同一个位线下的各个基本存储单元是并联的,是一种‘或’的逻辑
- NOR型闪存读写和存储格式与内存相近,其基本存储单元是bit,有独立的地址线和数据线,可按位随机读取
- NOR型闪存的特点之一是芯片内执行,应用程序可以像访问内存一样使用闪存
- NOR型闪存读操作的传输效率很高,在1~4MB的小容量时具有很高的成本效益。适合存储程序及相关数据
- 闪存的写入操作只能在空(存储“0”)或已擦除的单元内进行。虽然可以按位读取,但其擦除只能按“块”进行,所以写入和擦除速度较慢,影响了它的性能。NOR型闪存另一个的缺点是容量小,成本较高
- 允许单字节编程但不能单字节擦除
- 手机中存放电话簿、短信和通话记录的是NOR型闪存
NAND型闪存
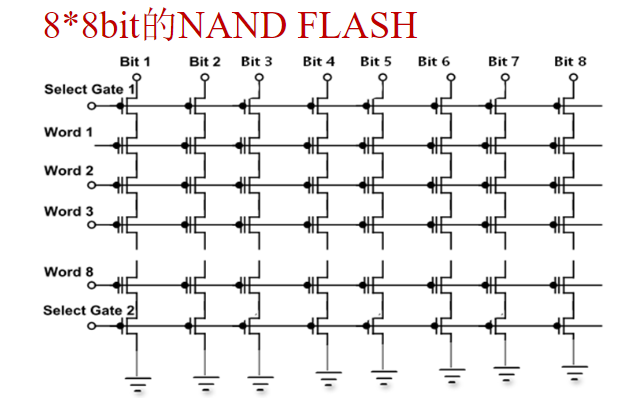
N是NOT,含义是浮置栅中有电荷时,读出‘0’,无电荷时读出‘1’,是一种‘非’的逻辑;OR的含义是同一个位线下的各个基本存储单元是并联的,是一种‘或’的逻辑
NAND型闪存的优点是存储密度和存储容量大
NAND型闪存也需要先擦除再写入,擦除和写入是以块或者页为单位进行的,一个块包含了若干页,每一页的有效容量是512字节的倍数
- 有效容量指数据存储可用容量,此外还有m×16字节的空闲字节,用(n×512+m×16)Byte表示。2GB以下多是每页(512+16)字节,32页组成一个块(16KB);2Gb以上页容量扩大到(2048+64)字节,64页组成一个块(128KB)。空闲字节可用于ECC和磨损均衡
3.2.3. 存储芯片的性能指标
存储容量
在一个存储器中容纳的存储单元总数通常称为该存储器的存储容量
存储容量可以用位数、字数或字节数来表示
以位数表示的存储器芯片容量计算:存储器芯片容量=单元数×数据线位数
例如,设地址线位数为n,数据线位数为m,则:
- 编址单元总数为:2n
- 存储器芯片容量为:2n×m
存储器芯片是以存储1位二进制数(bit)为最小单位
存放一个机器字的存储单元,通常称为字存储单元,相应的单元地址叫字地址。而存放一个字节的单元,称为字节存储单元,相应的地址称为字节地址
如果计算机中可编址的最小单位是字存储单元,则该计算机称为按字编址的计算机。如果计算机中可编址的最小单位是字节,则该计算机称为按字节编址的计算机
一个机器字可以包含数个字节,所以一个存储单元也可以包含数个能够单独编址的字节地址
虽然微型计算机的字长已经达到16位、32位,甚至64位,但其内存仍以一个字节为一个单元
计算机存储单位换算表:
| 中文单位 | 中文简称 | 英文单位 | 英文简称 | 进率(Byte=1) |
|---|---|---|---|---|
| 位 | 比特 | bit | b | 0.125 |
| 字节 | 字节 | Byte | B | 1 |
| 开字节 | 开 | KiloByte | KB | 210 |
| 兆字节 | 兆 | MegaByte | MB | 220 |
| 吉字节 | 吉 | GigaByte | GB | 230 |
| 太字节 | 太 | TeraByte | TB | 240 |
| 拍字节 | 拍 | PetaByte | PB | 250 |
| 艾字节 | 艾 | ExaByte | EB | 260 |
| 泽字节 | 泽 | ZettaByte | ZB | 270 |
| 尧字节 | 尧 | YottaByte | YB | 280 |
| 布字节 | 布 | BronteByte | BB | 290 |
存取时间和存取周期
存取时间(访问时间)Ta
- 存取时间称存储器访问时间,是指从启动一次存储器操作到完成该操作所经历的时间。如,从一次读操作命令发出到该操作完成,将数据读入数据缓冲寄存器为止所经历的时间
- 超高速存储器的存取时间小于20ns、中速100~200ns之间、低速300ns以上
影响Ta的因素
- 不同存储器芯片,存取速度不同
- 只读存储器还是随机存储器
- 芯片的位容量,表示存储功能的指标
- 功耗,CMOS器件功耗低,速度慢
- HMOS存储器件在速度、功耗和容量方面进行了折中
- 价格,存储器的价格,包括附加电路的价格
存取周期TM
- 存取周期是指连续启动两次独立的存储器操作(如连续两次读操作)所需间隔的最小时间。通常,存取周期略大于存取时间
其他指标
数据传送速率(频宽)BM
数据传送速率,指单位时间内能够传送的信息量
若系统的总线宽度为W,则BM=W/TM(b/s)
例如,若W=32位,TM=100ns,则
- BM=32位/(100×10-9s)=320M位/s=40MB/s
- 若TM=40ns,则BM=100MB/s
体积与功耗
- 便携式微机,其便携性能和续航时间尤为重要,因而对体积、功耗非常敏感
可靠性
- 采用平均故障间隔时间MTBF衡量,即两次故障之间的平均时间间隔
- MTBF=1/λ
- λ为故障率,表示单位时间内故障次数
3.3. 内存条性能的改进
内存条的特点:
- 扩展性:早期,计算机将内存芯片直接固化在线路板上。由于无法拆卸更换,要进行内存的扩展非常麻烦。这对于计算机的发展造成了阻碍。随着软件规模的扩大,以及新的硬件平台对扩展性提出了更高的要求,迫切需要提高运行速度和扩大内存容量
- 互换性:不同的系统采用同样的内存,降低系统成本
- 灵活性:针对不同的系统规模,要求内存以更加灵活的方式配置
- 可维护性:通过标准化,使得内存通用,提高维护效率,降低维护成本
3.3.1. 内存条的组成
内存颗粒
内存芯片称为内存颗粒
芯片封装:TSOP(Thin Small Outline Package)和BGA(Ball-Gird-Array)
TSOP:引脚由四周引出
BGA:引脚由芯片中心方向引出
有效缩短信号的传导距离,使信号衰减减少,更加快速有效的散热
在相同容量下,体积只有TSOP封装的三分之一

根据内存条容量,集成数量不等的内存颗粒
SPD芯片
- SPD(Serial Presence Detect)是一片E2PROM,记录内存条出厂时预先存入的速度、工作频率、容量、工作电压、行/列地址带宽、传输延迟、SPD版本等基本参数
- 开机时BIOS自动读取SPD记录信息,对主存进行设置,使内存运行在规定的工作频率,工作在最佳状态
PCB电路板
内存条的PCB采用4层或6层电路板
- 紧凑,减小电路板体积
- 分层屏蔽电路,减少电磁辐射,电源和地用单独的层有利于信号完整性
引脚/金手指
- 金手指就是内存条电路板上的引脚,用于与计算机总线连接,也是内存条在主板上进行固定的装置,并连接总线上的有关信号线
- 按照引脚布局,常用的内存条有:SIMM(single in-line memory module)、DIMM(Dual In-line Memory Module)、SODIMM(Small Outline Dual In-line Memory Module)等
排阻和电容
- 用于提高信号完整性,如防止信号反弹、滤除高频干扰等
3.3.2. 内存条的演变
SIMM
- 最初的内存是直接以DIP封装芯片的形式安装在主板的DRAM插座上
- 最早的30脚SIPP(Single In-line Pin Package)接口,针脚的定义与30脚SIMM一样。SIPP很快就被SIMM取代,两侧金手指传输相同的信号
- 早期的内存频率与CPU外频不同步,采用异步DRAM。可细分为FPM DRAM(Fast Page Mode DRAM)、EDO DRAM(Extended Data Out DRAM),常见接口为30脚SIMM与72脚SIMM,工作电压都是5V
- 第一代SIMM内存为30个引脚,单根内存数据总线为8位,用在16位数据总线处理器上需要两根,用在32位数据总线处理器上则需要四根
- 随后出现了72脚SIMM内存,单根内存位宽增加到32位,一根就可以满足32位数据总线处理器,拥有64位数据总线的奔腾处理器则需要两根
FPM DRAM & EDO DRAM
- 传统DRAM的访问,需要经过“发送行址—发送列址—读写数据”3个阶段,一次访问时间是每个阶段所需时间之和
- FPM(Fast Page Mode,快速页面模式)对地址连续(列址相同)的多个单元进行读写访问。除访问第一个数据之外,后续访问只需要经历“发送行地址—读写数据”2个阶段,从而缩短了访问时间
- EDO(Extended Data Out,扩展数据输出)是对传统DRAM存取技术的改进。它取消了主板与内存两个存储周期之间的时间间隔,每隔2个时钟脉冲周期传输一次数据,大大地缩短了存取时间。在输入下一个行地址时,仍然允许数据输出进行,扩展了数据输出的时间,“EDO”因此得名
SDR SDRAM (Single Data Rate SDRAM)
SDRAM(Synchronous DRAM,同步动态随机存取内存)
传统DRAM采用“异步”的方式进行存取,存储器的吞吐速率受限从而导致系统性能难以提高
SDRAM采用同步方式进行存取。送往SDRAM的地址、数据和控制信号都在一个时钟信号的上升沿被采样和锁存,SDRAM输出的数据也在另一个时钟上升沿锁存到芯片内部的输出寄存器
SDRAM收到地址和控制信号之后,在内部进行操作。在此期间,处理器和总线主控器可以处理其它任务(例如,启动其它存储体的读操作),无需做无谓等待,从而提高了系统性能
输入地址、控制信号到数据输出所需的时钟个数可以通过对芯片内“方式寄存器”的编程来确定
SDRAM芯片支持“突发总线模式(Burst)”进行读写操作。当对一组相邻的存储单元进行访问时,第一个地址给出后,后续地址自动生成,无需再发,可以进行连续读写,大大提高了速度
- SDRAM增加了时钟信号和内存命令的概念。内存命令的类型取决于时钟上升沿上的CE#、RAS#、CAS# 和WE#信号状态
- SDRAM工作电压为3.5V,采用168线带两个缺口的DIMM插槽。早期时钟频率为66M,后来多为133M,可进行64位的读写。产品规格用时钟频率表示,如pc100或pc133表示其时钟频率为100M或133M
- SDRAM的存在时间相当长,Intel奔腾2、奔腾3与奔腾4,以及Slot 1、Socket 370与Socket 478的赛扬处理器,AMD的K6与K7处理器都可使用SDRAM内存条
RDRAM (Rambus DRAM)
Intel与Rambus合作并推出了Rambus DRAM内存条以代替SDR SDRAM,简称为RDRAM
与SDRAM不同,采用了新的高速简单内存架构,减少数据复杂性,提高整个系统性能
- RDRAM内部引入了RISC,依靠高时钟频率来简化每个时钟周期的数据量
RDRAM采用RIMM(Rambus In-line Memory Module)插槽,184脚,总线位宽16位,插两条组建双通道时就是32位,工作电压2.5V,频率有600、700、800、1066MHz等
- RIMM与DIMM的外型尺寸差不多,金手指同样也是双面的
RDRAM内存条通常都是用在Socket 423的奔腾4平台上,搭配Intel 850芯片组使用。由于RDRAM的制造成本高,使得RDRAM的价格居高不下。同时由于奔腾4平台的成本相对较高,最终导致RDRAM被DDR SDRAM替代
DDR SDRAM (Double Data Rate SDRAM)
DDR(Double Data Rate)SDRAM(双倍速率同步内存),原来的SDRAM被称为SDR SDRAM
SDR仅在时钟脉冲的上沿进行一次写或读操作,DDR内部有两个乒乓交替工作的存储体,还有2bit的预取缓冲,可在时钟上沿和下沿都进行一次对等的写或读操作,至少在理论上DDR的数据传输能力比同频率的SDR提高了一倍
DDR内存条的工作电压是2.5V,共有184线,金手指只有一个“缺口”
DDR工作频率有100/133/166/200/266MHz等。所谓双倍速率就是传输速率是工作频率的两倍,因此型号上所标识的是工作频率×2,即标称为DDR200、266、333、400和533,容量128/256/512MB等,主要用于P4级别的64位PC机
DDR内存条最初只有单通道,后来出现了支持双通芯片组,让内存的带宽直接翻倍,两根DDR-400内存条组成双通道,可以满足FBS800MHz的奔腾4处理器
- 能用DDR内存条的CPU很多,除Intel与AMD外,还有NVIDIA、VIA、ALI、ATI等厂家
DDR2 SDRAM
DDR2内存采用了4bit预读取(类似于快餐店里的备餐)技术,数据通过四条线路串行传输到I/O缓存区,使工作频率为100MHz的内存可实现400MHz的数据传输频率,因此称为DDR2-400,其带宽为(100MHz×4)×(64b/8b)=3200MB/s=3.2GB/s
数据预取以及多路串行传送,实际数据传送速率相同时的功耗更低;或同样的功耗下拥有更快的传送速率
- DDR2有240个金手指,DDR是184个,两者的防呆缺口位置不同
- DDR2采用CAS、OCD、ODT等技术提高信号完整性
- DDR2的标准电压下降至1.8V,相较上代产品更为节能
- DDR2的频率从400MHz到1200MHz,主流的是DDR2-800
- 容量从256MB至最大4GB,4GB的DDR2内存条应用很少
- DDR2在2004年6月与Intel的915/925主板同步推出,伴随了大半个LGA 775时代
DDR3 SDRAM
在DDR2基础进一步改进为8位预取,如100MHz的DDR3-800,带宽可达到: (100MHz×8)×(64b/8b)=6.4GB/s
预存比特数 vs 数据传送速率
- 提高预存比特数需要将I/O控制器的频率再次翻倍,并且增加数据线数量,在I/O芯片频率已经很高时,技术难度和成本都会大幅增加
其他特性
- DDR3的工作电压1.5V,240线,容量512MB和1/2/4/8GB,单条16GB的DDR3内存比较少。
- DDR3还采用CWD、Reset、ZQ、STR、RASR等新技术,让内存在休眠时也能够随着温度变化去控制对内存颗粒的充电频率,以确保系统数据的完整性。
- DDR3内存条随着Intel在2007年发布3系列芯片组一同到来。
- 支持DDR3内存的平台有Intel后期的LGA 775主板P35、P45、x38、x48等,LGA 1366平台,LGA 115x系列全都支持。还有LGA 2011的x79,AMD方面AM3、AM3+、FM1、FM2、FM3接口的产品均支持DDR3
DDR4 SDRAM
DDR4是目前的主流,相比DDR2和DDR3有以下几项关键技术
Bank Group架构。使用2个或4个可选择的采用8n预取的Bank Group分组,每个Bank Group可以独立读写数据,如果是2个独立的Bank Group,相当于将内存预取值提高到了16n,如果是4个独立的Bank Group,则等效的预取值提高到了32n。
点到点传输。每个通道只连接一根内存条,消除了共享传输带来的性能瓶颈。
3D堆叠。在散热允许情况下,采用3D堆叠封装技术,使得单根内存条的容量从目前8GB提高到64GB。
其他技术变化
- DDR4功耗明显降低,电压达到1.2V,传输速度从2133 MT/s起,最高可达4266 MT/s
- DDR4增加了DBI(Data Bus Inversion,数据总线反转)、CRC(Cyclic Redundancy Check,循环冗余校验)、CA parity等功能,增强了信号的完整性、改善数据传输及储存的可靠性
DDR5 SDRAM
主导内存标准制定的JEDEC(Joint Electron Device Engineering Council)规范组织,虽然之前宣布2018年正式发布DDR5标准,但实际上并没有,最终规范要到2020年才能完成。
DDR5主要特性是芯片容量,而不仅仅是更高的性能和更低的功耗。
- 内存带宽在DDR4基础上翻倍,从8位翻倍到16位。
- 频率最低4800MHz,最高6400MHz。
- 电压则从1.2V降至1.1V,功耗减少30%。
- 每个模块使用两个独立的32/40位通道,支持ECC(Error Correcting Code)。
此外,DDR5将具有改进的命令总线效率,更好的刷新方案以及增加的存储体,以获得额外的性能,提高总线效率
小结:
- 传统DRAM访问,“发送行址—发送列址—读写数据”3个阶段
- FPM DRAM:访问地址连续的多个单元,不发送列址
- EDO DRAM:在输入下一个行地址时,仍然允许数据输出进行
- SDR SDRAM:采用同步方式,支持Burst模式
- Rambus DRAM:简单内存架构,减少复杂性,提时钟频率
- DDR SDRAM:在时钟上沿和下沿都进行一次写或读操作
- DDR2 SDRAM:4bits预读取
- DDR3 SDRAM:8bits预读取
- DDR4 SDRAM:Bank Group架构、点到点传输、3D堆叠
- DDR5 SDRAM:预期2020年才能完成规范
3.4. 存储系统的层次架构
3.4.1. 存储系统的分层管理
完整的四级结构
- 寄存器+Cache+主存+辅存(联机、脱机外存)
存储系统的基本特点
- 存储系统是指计算机中由存放程序和数据的各种存储设备、控制部件及管理信息调度的设备(硬件)和算法(软件)所组成的系统
- 存储系统的性能在计算机中具有非常重要的地位,存储管理与组织的好坏影响到整机效率。主要因为冯·诺伊曼体系结构是建筑在“存储程序”概念基础上,访存操作约占中央处理器70%左右的时间
存在的问题
- 存储器的存取速度在不断提高,但相比较而言,主存增速与CPU增速不同步。
- 指令执行期间多次访问存储器。频繁的存储器访问,导致占用大量的CPU运行时间。
- 主存储器(内存)存放当前正在执行的应用程序及数据,但难以同时满足存取速度快、存储容量大和成本低的要求。
- 在早期计算机系统中,程序员会直接对主存储器的物理地址进行操作,这种编程方式的缺陷是,当程序出现寻址错误时,可能会导致整个系统崩溃,一个进程出现寻址错误时也可能会导致另一个进程崩溃
虚拟存储器的意义
特点
- 允许用户程序使用比实际主存空间大得多的空间来访问主存
- 每次访存都要进行虚实地址转换
提供三个重要能力
- 将主存看成是一个存储在磁盘上的地址空间高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,高效使用主存
- 为每个进程提供一致的地址空间,从而简化存储器管理
- 保护每个进程的地址空间不被其他进程破坏
解决三个根本需求:
- 确保可以运行存储空间需求比实际主存储容量大的应用程序
- 确保可执行程序被装载后占用的内存空间是连续的
- 确保同时加载多个程序的时候不会造成内存地址冲突
3.4.2. 虚拟存储器与地址映射
虚拟存储器简介
虚拟存储器思想的诞生
- 问题:应用程序太大以至于内存容纳不下该程序
- 简单解决方法:程序分割覆盖块片段,程序员需要对代码进行分割
- 更好的解决方法:虚拟存储器
虚拟存储器的基本思路
- 程序,数据,堆栈的总的大小可以超过物理存储器的大小,操作系统把当前使用的部分保留在内存,而把其他未被使用的部分保存在磁盘上
- 例如一个16MB的程序和一个内存只有4MB的机器,操作系统通过选择,可以决定各个时刻将哪4MB的内容保留在内存中,并在需要时在内存和磁盘间交换程序片段,这样就可以把这个16M的程序运行在一个只具有4M内存机器上了。而这个16M的程序在运行前不必由程序员进行分割
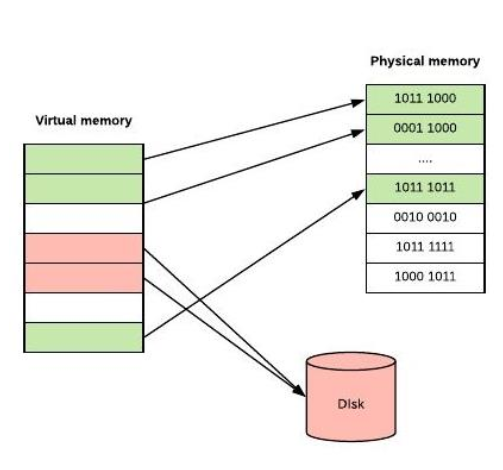
Cache与虚拟内存的异同
相同点:
- 两者都有利于提高存储系统的性能。
- 均基于程序局部性原理。一个程序运行时,只会用到程序和数据的一小部分,仅把这部分放到比较快速的存储器(内存)中,其他大部分放在速度低、价格低、容量大的存储器中
不同点
- 在虚拟存储器中未命中的性能损失要远大于Cache系统中未命中的损失。因为主存和Cache的速度相差5~10倍,而外存和主存的速度相差上千倍
- Cache主要解决主存与CPU的速度差异问题,而虚存主要解决内存容量问题
- CPU与Cache和主存之间均有直接访问通路,Cache不命中时可直接访问主存。而虚存所依赖的辅存与CPU之间不存在直接的数据通路,当主存不命中时只能通过调页解决,CPU最终还是要访问主存
- Cache的管理完全由硬件完成,对系统程序员和应用程序员均透明。而虚存管理由软件(操作系统)和硬件共同完成,虚存对实现存储管理的程序员是不透明的(段式和段页式管理对应用程序员”半透明“)
虚拟地址与物理地址
概念
- 任何计算机上都存在一个程序能够产生的地址集合,称之为地址范围。这个范围的大小由CPU的位数决定,例如一个32位的CPU,它的地址范围是0~0xFFFFFFFF (4G)。我们把这个地址范围称为虚拟地址空间,该空间中的某一个地址我们称之为虚拟地址
- 与虚拟地址空间和虚拟地址相对应的则是物理地址空间和物理地址,例如,对于一台内存为256MB的32bit x86计算机而言,它的虚拟地址空间范围是0~0xFFFFFFFF(4GB),而物理地址空间范围是0x000000000~0x0FFFFFFF(256MB)
- 在没有使用虚拟存储器的机器上,虚拟地址被直接送到内存地址总线上,使具有相同地址的物理存储器被读写
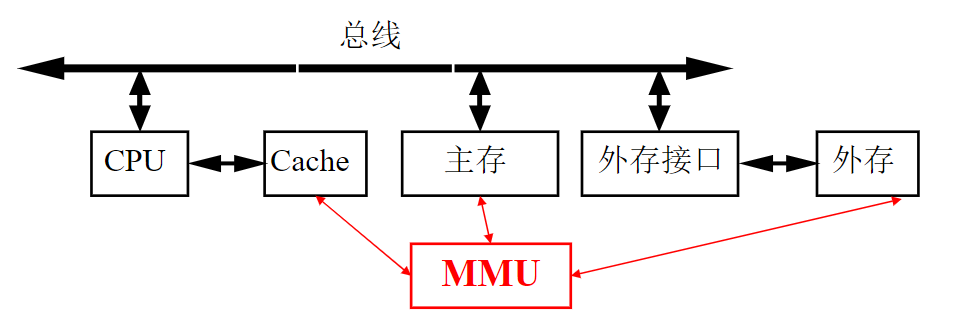
虚拟地址与物理地址之间需要映射
- 在使用了虚拟存储器的情况下,虚拟地址不是被直接送到内存地址总线上,而是送到内存管理单元MMU。MMU由一个或一组芯片组成,其功能是把虚拟地址映射为物理地址
- MMU是一种负责处理CPU内存访问请求的计算机硬件。它的功能包括虚拟地址到物理地址的转换、内存保护、CPU高速缓存控制等
虚拟存储器地址映射方式
虚拟存储器利用大容量的外存来扩充内存,产生一个比实际内存空间大得多的、逻辑的虚拟内存空间,简称虚存
- 例如,Windows操作系统下,虚拟内存在硬盘上就是为一个很大的隐藏文件文件,文件名是
PageFile.Sys。虚拟内存有时候也被称为是“页面文件”就是从这个文件的文件名中来的
- 例如,Windows操作系统下,虚拟内存在硬盘上就是为一个很大的隐藏文件文件,文件名是
一般情况下,程序代码是保存在虚存。但是当代码需要运行的时候就必须将其装入内存,要将虚存地址以一定的规则转换成物理地址
虚存的地址变换,分三种:段式,页式,段页式
段式虚拟存储器
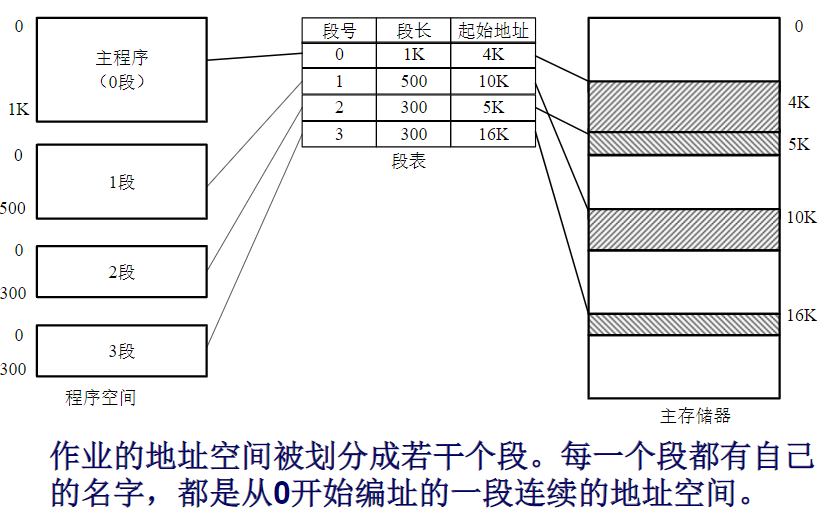
简介
段式存储管理是一种把主存按段分配的存储管理方式,主存与辅存间信息传送单位是不定长的段
- 段:按照程序的自然分界划分的长度可以动态改变的区域。通常可把子程序、操作数和常数等不同类型的数据划分到不同的段中,并且每个程序可以有多个相同类型的段
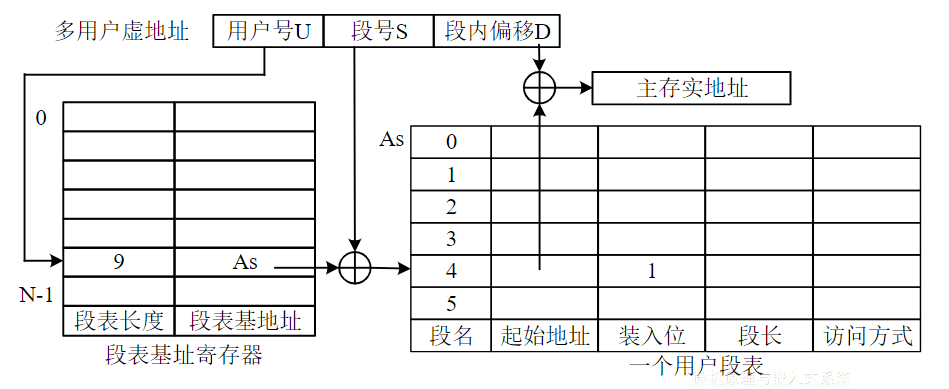
地址变换
- 多用户虚地址是由用户号U,段号S,和段内偏移地址D组成
- 虚地址和物理地址之间通过段表(存放于主存储器)来映射,CPU中会有一个段表基址寄存器,段表记录段号、段长、起始地址,从基址寄存器能够直接读出段表的起始地址。
- 通过用户号U查找到对应的基址寄存器,基址寄存器的起始地址加上虚地址的段号,就能找到段表地址As
- 如果所访问的段在内存中,则从段表中给出的起始地址,加上虚地址的偏移量,则得到物理地址(主存实地址)
段式存储管理的优点
- 段的分界与程序的自然分界相对应,使得段易于编译、管理、修改和保护,也便于多道程序共享
段式存储管理的缺点
- 容易在段间留下许多空余的存储空间碎片
- 段式存储管理还存在交换性能较低的问题。因为辅存的访问速度比主存慢得多,而每一次交换,都需要把一大段连续的内存数据写到硬盘上,导致了当内存交换一个较大的段时,会让机器显得卡顿
页式虚拟存储器
简介
页式存储管理是一种把主存按页分配的存储管理方式,主存与辅存间信息传送单位是定长的页
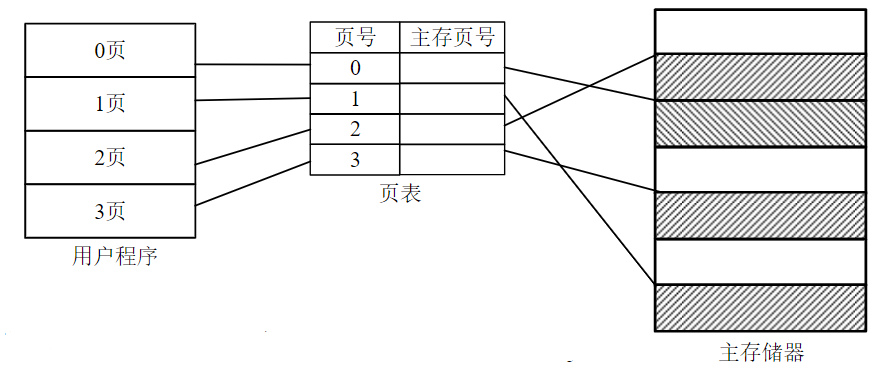
地址映射
- 将一个进程的地址空间划分成若干个大小相等的区域(页)
- 对应地主存空间划分成与页同样大小的若干个物理块
- 在为进程分配主存时,将进程中若干个页分别装入多个不相邻的块中
地址转换
- 用户虚地址,由用户号U,虚页号P,和页内偏移地址D组成
- 页表用来记录页号和主存页号
- CPU中的基址寄存器存放页表的基地址。和段表一样,用户号U会通过基址寄存器找到页表起始地址,起始地址与虚页号相加,再与偏移地址拼接就得到物理实地址
- 由于页的大小一样,故它在虚地址中某一页的偏移量和主存中某一页的偏移量相同
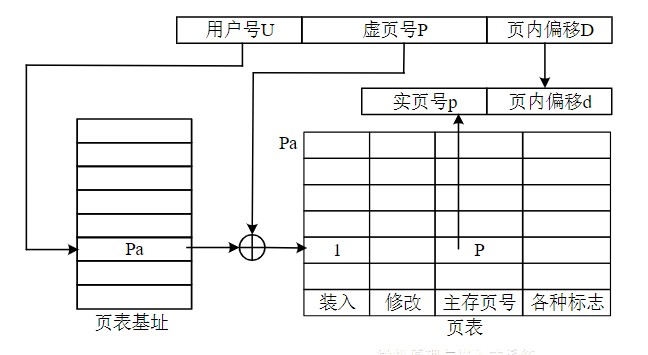
特点
- 对比段式虚拟存储,管理的粒度更细,所以造成内存页碎片浪费也会小很多
- 但页不是程序独立模块对应的逻辑实体,处理、保护和共享都不如段方便
- 页要比段小得多,如Linux操作系统采用页式存储管理,页的默认设置为4KB,所以页在进行交换时,相比段交换卡顿有所缓解
- 加载程序的时候,无需一次性把程序加载到内存,而是在程序运行中需要用到的对应虚拟内存页里面的指令和数据时,再加载到内存中,由操作系统完成
- 当CPU要读取特定的页,但却发现页的内容没有加载时,就会触发一个来自CPU的缺页错误(Page Fault)。操作系统会捕获这个错误,然后找到对应的页并加载到内存中。通过这种方式,使得可以运行那些远大于实际物理内存的程序,但相对的执行效率也会有所下降
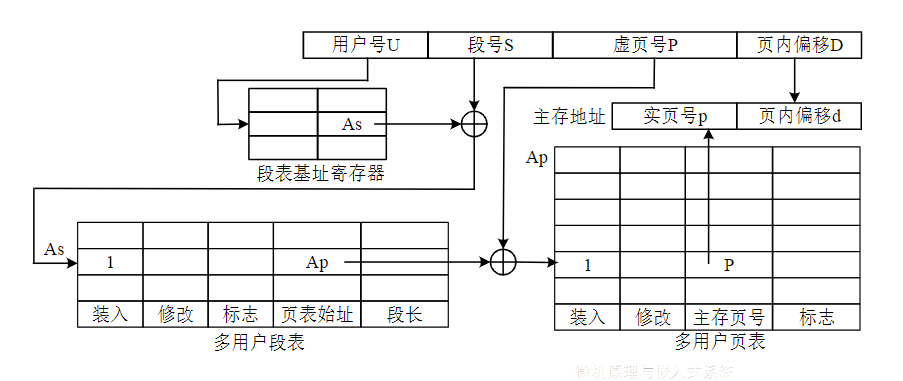
段页式虚拟存储器
简介
- 段页式虚拟存储器,先将用户程序按程序的逻辑关系分为若干个段,并为每一个段赋予一个段名,再将每一个段划分成若干页,以页为单位离散分配
- 段页式虚拟存储器充分利用段式和页式两种虚拟存储器在管理主存和辅存空间的优点,提高了主存利用率
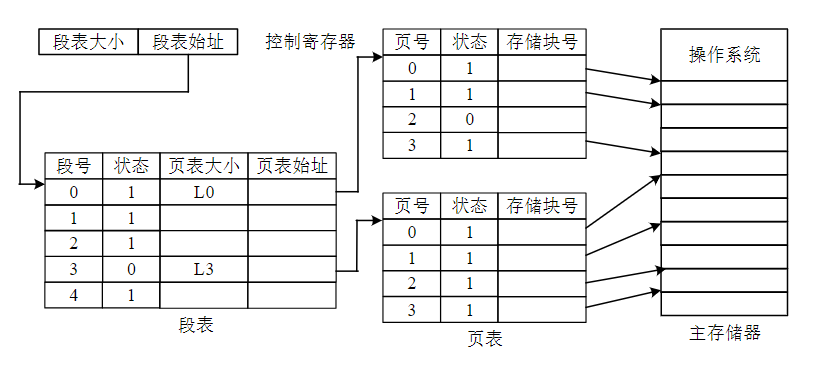
地址转换
- 虚地址,由用户号U,段号S,虚页号P,页内偏移D组成
- 段表,记录页表长度和页表地址
- 页表用来记录页号和主存页号
- 先通过U在段表基址寄存器中找到段表基地址,然后和段号S相加,得到页表起始地址和页表长度,通过页表找到主存实页号再与偏移量拼接,得到物理地址
- 如果要访问的地址不在内存中,就会需要调入一页或一段到主存中
3.5. 高速缓冲存储器Cache
3.5.1. 高速缓冲存储器Cache的原理
Cache的意义
- 在CPU的所有操作中,存储器的存取访问是最频繁的操作
- CPU的运行速度比大容量DRAM存储器的存取速度高得多
- 存储器的访问速度低是制约计算机系统性能的关键因素
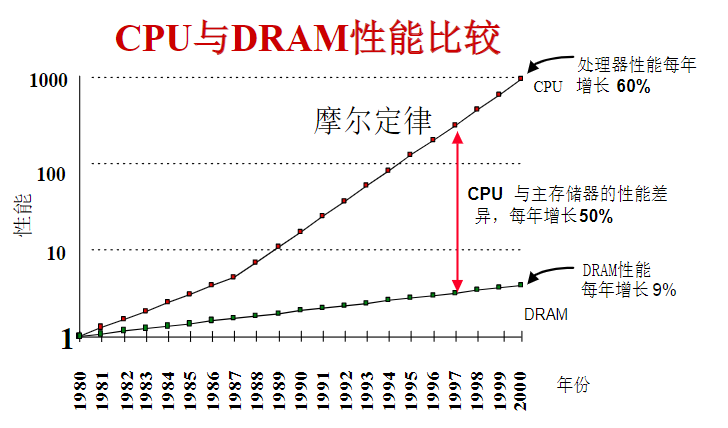
CPU与DRAM的发展现状
CPU和主存储器的速度总是有差距,CPU的发展一直是提高速度为核心目标;主存的发展则一直以提高容量为核心目标
程序访问的局部性原理
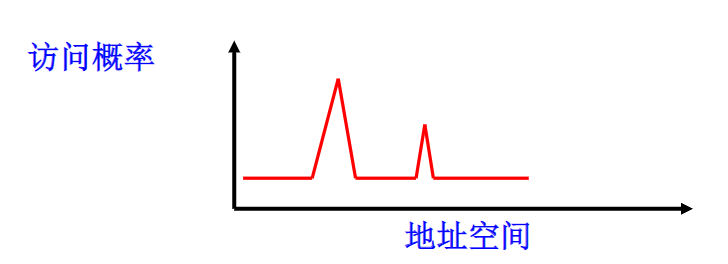
程序在一定时间段内通常只访问较小的地址空间
两种局部性:时间局部性和空间局部性
- 时间局部性:最近访问的信息很可能再次被访问
- 空间局部性:最近访问信息的邻近信息可能被访问
在主存与CPU之间设置Cache
思想:根据程序访问的时空局部性,把经常访问的代码和数据保存到高速缓冲存储器(Cache)中,把不常访问的代码和数据保存到大容量的相对低速DRAM中,尽量减少CPU访问DRAM的概率,在保证系统性能的前提下,降低存储器系统的实现代价
实现:Cache设置在CPU与主存储器之间,通常采用存取速度快并且无需刷新的SRAM来实现
- 根据时间局部性:将最近被访问的信息项装入到Cache中
- 根据空间局部性:将最近被访问的信息项的邻近信息也装入到Cache中
在主存和CPU之间设置了Cache之后,如果当前正在执行的程序和数据存放在Cache中,则当程序运行时不必再从主存储器读取指令和数据,而只需访问Cache即可
使用场合:CPU与主存之间、显示系统、硬盘和光驱,以及网络通讯中
Cache的基本运行原理
当CPU访问主存时,给出的地址同时送往Cache。首先检查Cache,如果要访问的数据已经在Cache中,则CPU就能很快完成访问,这种情况称为Cache“命中”(Cache hit)
否则,CPU就必须从主存中提取数据,称为Cache“未命中”(Cache miss)
如果组织的好,那么程序所用的大部分的数据都可在Cache中找到。Cache的“命中率”(hit rate)和Cache的容量大小、控制算法和组织方式等有关,当然还和所运行的程序有关
Cache的“命中率”通常应在90%以上。某些组织较好的Cache系统,命中率可达95%(例如早期IBM 360可达99%)
Cache的组织方式
Cache的基本单元称为行或区块,其中包括:
- 数据字段:保存从主存单元复制过来的数据,单位是(区)块。每个区块的大小为4~128字节,典型的Cache line通常的大小为32或64字节
- 标志字段:保存数据字段在主存中的地址信息,又称为地址标记寄存器,记为Tag
- 有效位字段:标识区块和Tag是否有效
在Cache系统中,主存是以区块为单位映象到Cache中。以CPU读取一个字节的数据为例,如果所需字节不在Cache中,在CPU从内存中读取数据的同时,Cache控制器将把该字节所在的整个区块从主存复制到Cache
Cache的管理
- 主存和Cache都会采用分Cache Line(也称字块)的方式进行管理,Cache中保存的就是对应的主存字块的一个副本。每一个Cache字块都会有一个标记位,用于表示当前字块里存放的是哪一个内存字块的副本。通过这个标记位,CPU就可以判断出希望访问的内存字块是否已经存在于Cache中
- 当Cache已经用满,但主存还需将新的字块调入Cache时,就会执行一次Cache字块的替换。这种替换应遵守一定的规则,最好使得被替换的字块是下一个时间段内估计最少使用的。这种规则称为替换策略或替换算法,由替换部件实现
- 当程序对Cache字块执行写入时,如何保证Cache字块和内存字块的一致性。通常的有两种写入方式:一个是先写Cache字块,待Cache字块被替换出去时再一次性写入内存字块;再一个是在写Cache字块的同时也写入内存字块
Cache管理的基本问题
Cache中存放近期需要重复运行的指令数据,形成主存储器内容的副本。CPU首先从副本中读取数据,只有Cache中没有所需的数据时或Cache中已满时,才直接访问内存。从而提高CPU对存储器的访问速度。
Cache和主存储器一起构成一级存储器。高速缓冲存储器和主存储器之间信息的调度和传送由硬件自动进行。
高速缓冲存储器Cache,需要解决两个问题:一是主存地址与缓存地址的映像及转换;二是按一定原则对Cache的内容进行替换。
- 依靠专门的硬件实现,Cache对CPU和程序员而言是透明的
3.5.2. 高速缓冲存储器Cache的基本结构
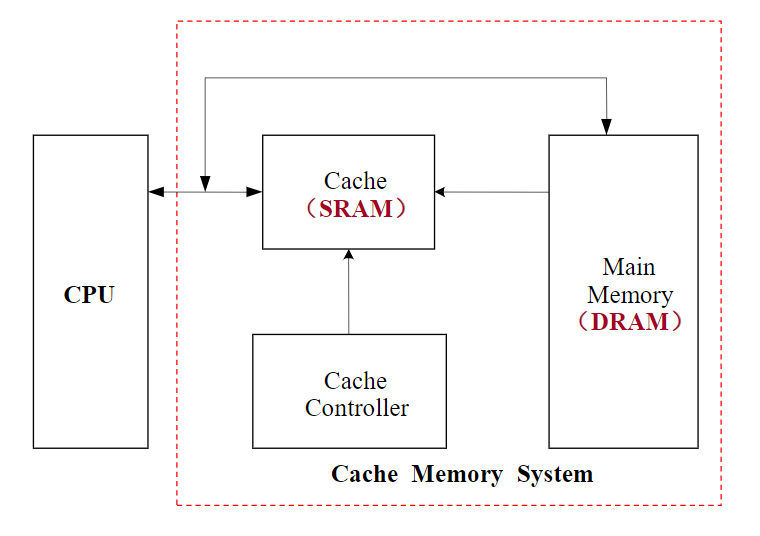
计算机的Cache系统基本组成
- Cache模块(SRAM)
- 主存(DRAM)
- Cache控制器
Cache的基本结构
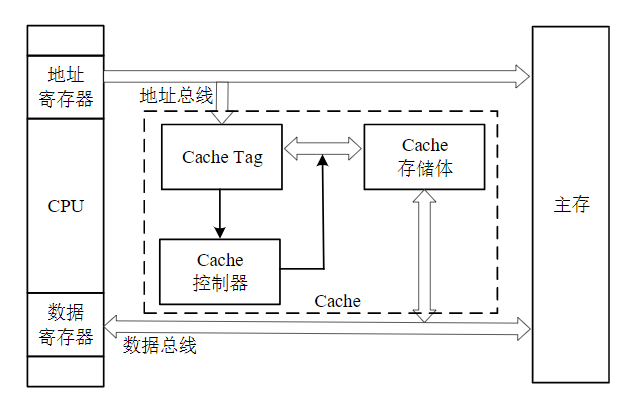
Cache由Cache Tag、Tag存储体和Cache控制器三部分组成
Cache Tag主要用来记录Cache存储体中数据的位置,判断Cache内数据是否命中
Cache存储体主要用来存储片外数据,方便处理器直接调用
Cache控制器由主存地址寄存器、Cache地址寄存器,主存-Cache地址变换部件及替换控制部件等四部件组成。Cache控制器控制整个Cache的具体工作,决定了Cache的工作效率
- 主存地址寄存器,存放主存的页号、块号、字号或者块内偏移地址等信息,具体包括哪些信息决定于所采用的地址映射方式
- Cache地址寄存器,存放所要映射的Cache的页号、块号、字号或者块内偏移地址等信息,具体包括哪些信息决定于所采用的地址映射方式
- 地址变换部件,建立目录表以实现主存地址到缓存地址的转换
- 替换控制部件,在缓存已满时按一定策略进行数据块替换,并修改地址变换部件
注意:地址寄存器中存放的信息不是直接地址,要得到地址信息必须通过地址变换部件按地址映射方式进行变换
Cache控制器的控制行为
Cache控制器控制主存和Cache间的数据传输
- CPU发出数据读(写)请求后,Cache控制器先将这个请求转向Cache存储器
- 若数据在Cache中,就对Cache进行读(写)操作,称为一次命中
- 若不在Cache中,CPU就对主存操作,称为一次脱靶,这时CPU必须在其总线周期中插入等待周期Tw
Cache控制的特点
- Cache对于CPU和用户程序都是透明的,即CPU和程序不知道它的存在
- 主存-Cache地址变换部件,以判断CPU要寻访的数据是否在Cache中
- 主要包含一个相联存储器,能在Cache控制器管理下,按照一定的地址映射关系,动态地在其中构建起一个表格,将Cache中的一个存储块与主存中的若干个存储块对应起来
影响命中率的因素
影响命中率的因素:Cache容量、存储单元组数目和组大小、地址映射方案、联想比较策略、数据替换算法、写操作处理方法、程序本身特性等
命中率的计算:
- 式中,和是对Cache和主存的存取次数,只有足够大,才有
- 为丢失率(Miss Rate),访问信息不在Cache中的比率
- 没有命中的数据,CPU只好从内存获取,并把该数据所在的数据块调入Cache,使以后对整块数据的读写都从Cache中进行,不必再调用内存
3.5.3. 地址映射与转换
地址映射(或称映像):主存单元的数据在被复制到Cache中的同时,该主存单元的地址,在经过某种函数关系处理后也被写进Tag,这一过程被称为Cache的地址映像
地址变换:CPU读写数据时,把访问主存地址变换为访问Cache的地址,这一过程被叫做Cache的地址变换。再根据地址变换结果对Cache进行检查
按照主存和Cache之间的映像关系,Cache的组织方式分为以下几种:
- 全相联映像(Fully associative mapping ):完全随意的对应。
- 直接映像(Direct mapping);一对多的硬性对应。
- 多路组相联映像(Multi-way set associative mapping):多对多有限随意对应
全相联映射
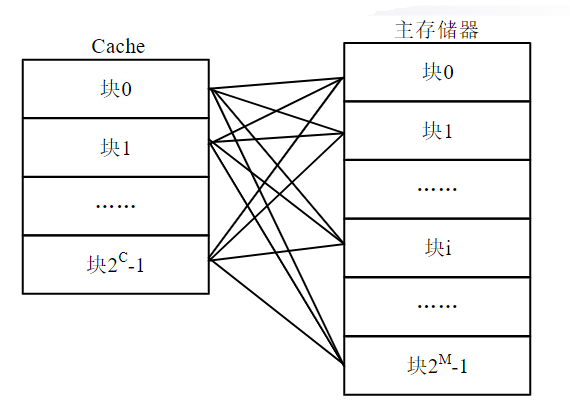
简介
- Cache与主存都分成块(Cacheline),每块由多个字节组成,大小相等。在一个时间段内,Cache的某块中放着主存某块的全部信息,即Cache的某一块是主存某块的副本(或叫映像)
- 主存中任意一个块都可以映射到Cache中任意一个块。设Cache共有块,主存共有块,当主存的某一块j需调进Cache中时,它可以存入Cache的块0、块1、...、块i、...或块的任意一块上
地址变换
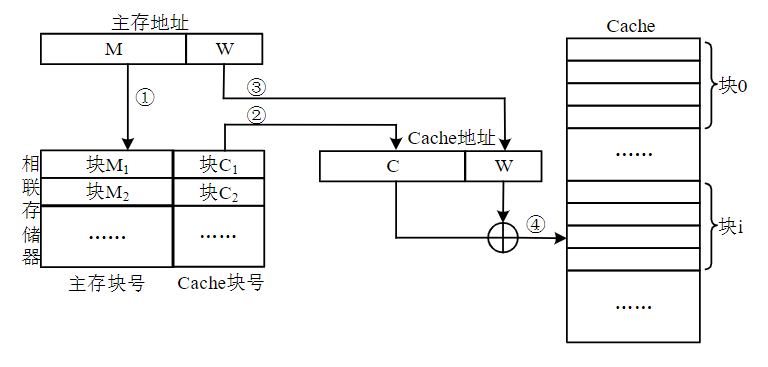
主存地址到Cache地址的转换是通过查找块表完成
CPU的访主存地址:M为主存的块号,W为块内的字号
CPU访Cache的地址:C为Cache的块号,W为块内的字号
当一个主存块调入Cache中时,会在一个存储主存块号Mj和Cache块号Ci映射关系的块表中进行登记。 CPU访问内存时:
- 根据主存地址中的主存块号Mj在块表中查找Cache块号Ci
- 若找到,则本次访Cache命中,于是将对应的Cache块号Ci取出
- 并与块内字号W一起形成一个访Cache的地址
- 最后根据该地址完成对Cache单元的访问
特点
- 大多数程序运行时需要访问位于主存不同位置的数据,在全相联映像方式中,主存中的区块可以映像到Cache的任意位置,因此Cache的利用率高
- 在这种方式中,Cache中区块的位置与在内存的位置没有任何关系。每个区块在主存中的地址需要在Tag中保存。CPU访问主存时,Cache控制器对访问主存的地址与Tag中的地址逐一进行比较,匹配成功才算命中
- 为保证比较的时效性,若Cache中共有N个区块,则需要有N个比较电路同时并行比较。若主存有2m个区块,则有m位区块地址,Tag较长,不仅造成Cache的实际利用率较低,并且比较电路的实现代价太高
- 优点:Cache存储空间利用率高,不易产生冲突,命中率比较高
- 缺点:比较和替换策略都需要硬件实现,电路复杂,只适用于小容量Cache。访问相关存储器时,每次都要与全部内容比较,速度低,成本高。因而应用少
直接相联映射

简介
直接相联映射(Direct-Mapped)方式是将主存空间按照Cache的大小划分为若干页,也称为区,页内分块。主存储器中一块只能映射到Cache的一个特定的块中
- 主存的某块j只能映射到满足如下特定关系的Cache块i中:
- 例如,主存的第0、2C、2C+1、...块只能映射到Cache的第0块,主存的第1、2C+1、2C+1+1、...块只能映射到Cache的第1块,......,主存的第2C-1、2C+1-1、...2M-1块只能映射到Cache的第2C-1块
地址变换
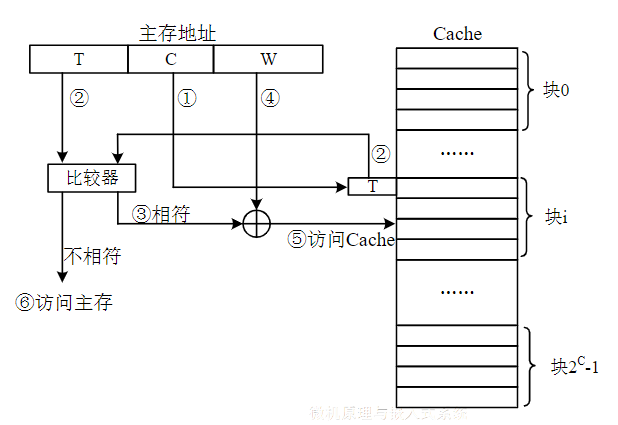
CPU的访主存地址为如下形式:T为标志号,C为Cache的块号,W为块内的字号。在这里,原主存的块号M实际上被分成了两个字段:T和C,其中C用于指出主存的块可以映射的Cache的块(即对2C求余后的余数部分),而对于余数相同的不同的主存块来讲,整除2C后的商(即T)部分则不相同。在直接相联映射方式下,标志号T是随Cache的每个块一起存储的
CPU送来一个访存地址时
- 根据该主存地址的C字段找到Cache的相应块
- 然后将该块标志字段中存放的标志与主存地址的T标志进行比较
- 若相符,说明主存的块目前已调入该Cache块中,则命中
- 根据主存地址的W字段合成Cache地址
- 访问该Cache块的相应单元。若不相符,未命中,使用主存地址直接访主存
特点:
- 直接映象是一种最简单的地址映像方式,其思想是:按照Cache的大小,将主存也分为同样尺寸的若干“页”。主存中位于不同页但是偏移量相同的数据在调往Cache时,只能存放在Cache中具有同样偏移量的位置,Tag只需记录区块在主存的页号
- 当程序访问不同页但具有相同偏移量的数据时,将不可避免地产生冲突。此时,即使Cache中有其它空闲块,也因为固定的地址映像关系而无法应用
- 优点:地址映射方式简单,数据访问时,只需检查页号是否相等即可,因而可以得到比较快的访问速度,硬件设备简单
- 缺点:替换操作频繁。主存每个块在Cache中只有一个对应位置,若另一个块也要调入该位置,将会发生冲突,即使Cache的其它块位置空闲,也不能接受它,导致命中率低
组相联映射
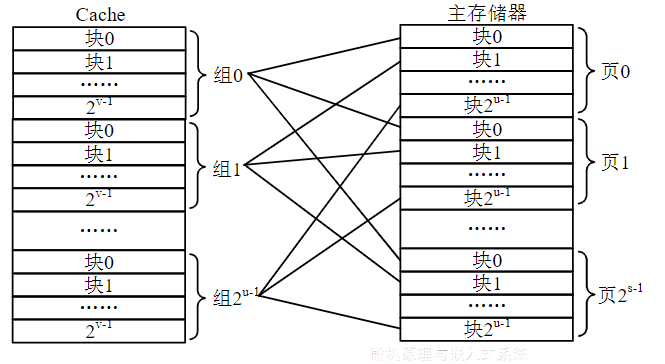
简介
- Cache划分成大小相等的组,将总块数为2C的Cache分成2u组,每组2v块。主存容量是Cache容量的整数倍,将总块数为2M的主存划分为2s页,每页2u块,即主存每页的大小与Cache的组数相等
- 主存的块与Cache的组之间采用直接相联映射,而与组内的各块则采用全相联映射。也就是说,主存的某块只能映射到Cache的特定组中的任意一块。主存的某块j与Cache的组k之间满足关系:
地址变换
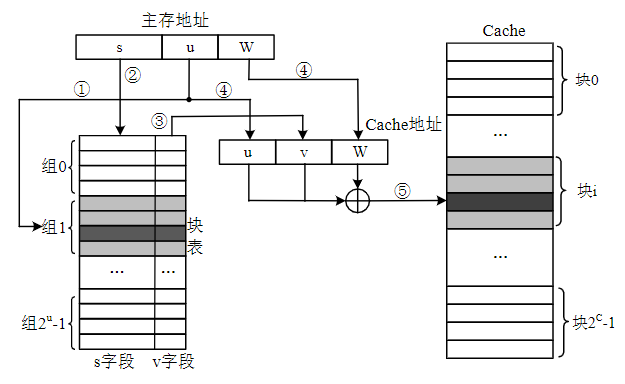
主存划分为2s页,每页2u块,Cache分成2u组,每组包含2v块
- s为主存的页号,u为页内的块号,w是块内地址
- u为Cache的组号,v为组内的块号,w是块内地址
Cache的块号C=u+v,而主存的块号M=s+u
主存块被调入Cache时,同时将其地址的前s位写入块表的s字段
CPU访问存储器时
- 根据主存地址中的u字段,找到块表对应的组
- 然后将该组的所有项的前s位,与主存的s字段比较
- 若相符,则表明主存块在Cache中,则将该项的v字段取出
- 再取出主存地址w字段
- u+v+w形成Cache地址
特点
- 又称为成组相联映像方式,是以上两种方式的一种折衷方案。主存和Cache之间,既不是硬性的多对一对应,也不是完全的随意对应,而是采用了一种有限度的随意对应
- 该方案将Cache进行分组(路),例如分成2组或4组。每组采用直接映像方式,以减少比较电路的成本;组与组之间为全相连映像方式,以避免区块位置的冲突。用多组Cache并行提供高速缓存功能
- CPU访问内存时,Cache控制器经过两次比较,判断是否命中。这种方式集中了以上两种方式的优点,因此得到了广泛应用
- 优点:块冲突概率比较低,块利用率大幅度提高,块失效率明显降低
- 缺点:实现难度和造价要比直接映射方式高
3.5.4. Cache更新与替换策略
读取结构
贯穿读出(Look Through)
- 该方式将Cache隔在CPU与主存之间
- CPU对主存的所有数据请求都首先送到Cache,由Cache在其中查找
- 如果命中,则切断CPU对主存的请求,并将数据送出
- 不命中,则将数据请求传给主存
- 优点:降低了CPU对主存的请求次数
- 缺点:延迟了CPU对主存的访问时间
旁路读出(Look Aside)
- CPU同时向Cache和主存发出数据请求
- 由于Cache速度更快,如果命中,则Cache在将数据回送给CPU的同时,还来得及中断CPU对主存的请求
- 不命中,则Cache不做任何动作,由CPU直接访问主存
- 优点:没有时间延迟
- 缺点:每次CPU都存在主存访问,从而占用一部分总线时间
写入更新策略
当CPU对Cache数据做了修改之后,应修改主存相应位置内容
写通方式(Write Through)
- 从CPU发出的写信号送到Cache的同时,也写入主存,保证主存的数据能同步更新
- 优点:操作简单,较好地保持了Cache与主存内容的一致性,可靠性高
- 缺点:由于主存的慢速,降低了写速度并占用了总线时间,没有发挥Cache高速访问优势
写回方式(Write Back)
- 更新数据只写到Cache,而主存中的数据不变
- 在Cache中设置“修改标志位”,Cache中有被修改的数据时,该标志位置“1”
- 每次Cache有数据更新时,判断该标志位。只有该标志位为1,即Cache中的数据被再次更改而需要换出时,才将原更新的数据写入主存相应的单元中,然后再接受再次更新的数据
- 优点:克服了写通方式写速度低的问题,有利于提高CPU执行效率
- 缺点:有Cache与主存数据不一致的隐患,控制也较复杂
替换策略
Cache一个块对应主存多个块,块大小相同。主存数据块装入Cache时,如果相应位置被其他块占用,则必须替换掉旧块,以新块填充
随机(Random)替换策略
- 随机确定需要替换的Cache块,不管Cache块过去、现在及将来的使用情况,而随机地选择某块进行替换
- 优点:方法最简单,易硬件实现,速度快
- 缺点:被换出的数据可能马上就需要再次使用,增加了映射装入次数,降低命中率和效率
最不经常使用(Least Frequently Used,LFU)替换策略
- 将一段时间内被访问次数最少的块替换出去
- 每块设置一计数器,从0开始计数,每访问一次,被访块的计数器就增1
- 需要替换时,将计数值最小的块换出,同时将所有块的计数器清零
- 优点:方法较简单,较易硬件实现
- 缺点:统计的是各块两次替换间的访问次数,不能严格反映近期被访问情况。新调入的块很容易被替换出去
先进先出(FIFO)替换策略
- 根据进入Cache的先后次序来替换,先调入的Cache块被首先替换掉
- 优点:不需要随时记录各个块的使用情况,容易实现,且系统开销小
- 缺点:一些需要经常使用的程序块可能会被调入的新块替换掉
近期最少使用(Least Recently Used,LRU)替换策略
- 将CPU近期最少使用的块作为被替换的块
- 需要随时记录Cache中各块的使用情况,以便确定哪个块是近期最少使用的块
- 为每个块设置一个“未访问次数计数器”
- 每次Cache命中时,命中块的计数器清0,其它各块的计数器加1
- 每当有新块调入时,将计数值最大的块替换出去
- 优点:确保新加入的块保留,还可把频繁调用后不再需要的数据淘汰掉,提高Cache利用率和命中率。硬件实现并不困难
3.5.5. 影响Cache性能的因素
Cache脱靶的原因
分块太小
程序开始执行时,主存块逐步复制进Cache,因此容易脱靶,需经过一段时间后Cache才装满。首次执行产生脱靶的次数,与分块大小有关,块越大,不命中次数就越小
容量太小
不能将所需指令和数据都调入Cache,因此频繁的替换,导致CPU访问慢速主存次数增多
替换进Cache的主存块过大或过多
- 替换进Cache的主存块数目太多,会把下次要访问的指令或数据替换出去
- 数据块太大,替换所传数据量越大
- Cache所含块数减少,少数块刚装入就被覆盖掉
提高Cache性能的方法
增大Cache容量来降低不命中率
Cache太小致命中率太低,过大改善不明显。一般选Cache与内存容量比4:1000,命中率90%以上。每块取4~8字节(或字)较好
通过结构设计减少不命中次数
指令、数据分开存储,存取比例不一样,可将两类Cache分开,并采用二级、三级Cache结构
通过预取技术提高命中率
预测将要访问的指令和数据,提前将下条要执行指令取入Cache,提高CPU取指令的速度
3.6. 存储器系统设计
3.6.1. 主存储器系统设计技术
CPU总线的负载能力
CPU通过总线直接驱动负载的能力有限,应根据需要连接的存储器芯片参数,考虑在总线上增加缓冲器或驱动器,增大CPU的负载能力
CPU时序与存储器存取速度间的配合
CPU要对存储器频繁读/写,选芯片时要考虑其存取速度能否与CPU读/写时序匹配
存储器的地址分配和片选
需要为存储器分配地址范围。由于每块芯片存储容量有限,一个存储器系统可能是由多块芯片组成,要重点考虑容量的扩充方案和片选信号的形成
控制信号的连接
CPU提供的存储器控制信号,如CS#、OE#、WE#等,应与存储器的相关引脚正确连接,才能实现读/写等控制功能
3.6.2. 存储器系统扩展方式
位扩展
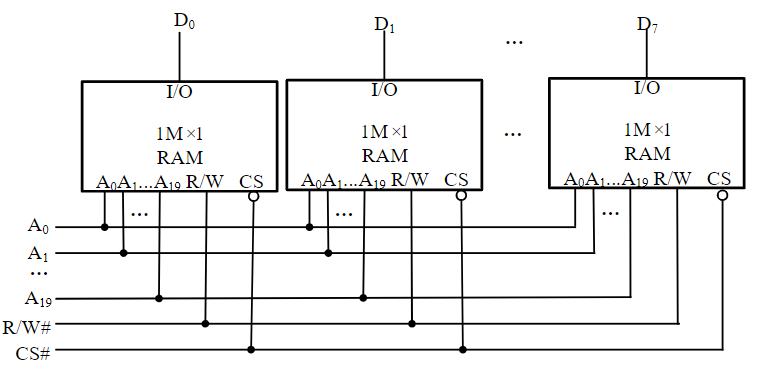
在存储器芯片字数不变的前提下,进行数据的位数扩展
举例:1M×1位的芯片扩展为1M×8位的RAM并与CPU总线连接
- 每个芯片数据线分别连接数据总线D7~D0的不同位,以形成8位数据
- 各芯片的地址线A19~A0与CPU地址总线对应地址线并联
- 读写控制线R/W#与CPU读写控制线分别并联连接,CPU的片选控制线CS#与各芯片的CS#并联
字扩展
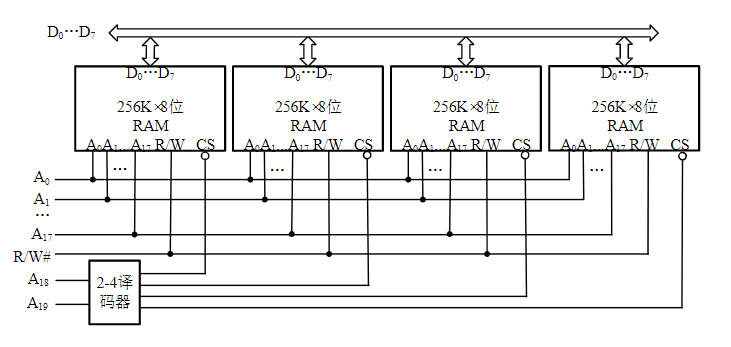
在存储器芯片的位数满足的前提下,进行字数扩展
举例:存储器芯片为256K×8位,采用4片进行字扩展为1M×8位的RAM,并与CPU总线连接
- 每个芯片的各位数据线分别与数据总线D7~D0位并联
- 各芯片低位地址线A17~A0与CPU地址总线对应地址线并联
- 高位地址线A19、A18通过2线-4线译码器分别产生不同的译码输出信号控制每个存储器芯片的片选端CS#
- 各芯片的读写控制线R/W#与CPU读写控制线分别并联连接
复合扩展
在位长和字数均不足时,采用复合扩展方式
举例:如将256K×1位的芯片扩展为1M×8位的存储器系统
- 先进行位扩展,用8片256K×1位芯片进行位扩展,构成256K×8位的存储器
- 再将位扩展后的存储器作为整体进行字扩展,用4个256K×8位的存储器,从而构成1M×8位的存储器系统
3.6.3. 嵌入式存储器系统设计
存储结构特点:
嵌入式微处理器内置小容量NOR Flash内存和小容量的SRAM
嵌入式系统的存储器扩展
- 通过不同的总线接口,连接大容量的NAND Flash、DRAM、SD、eMMC、TF等存储器
- 嵌入式微处理器内置的存储器容量有限,在内置存储器存储容量不足时,可外部扩展SRAM或者DRAM
NOR Flash内存的存储器扩展设计
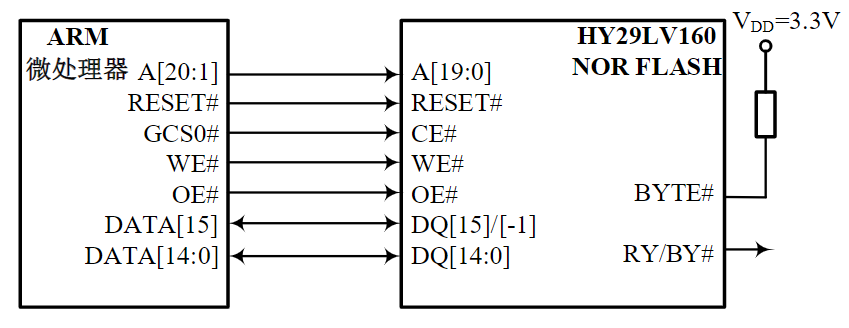
HY29LV160 NOR Flash芯片
- 地址线20根,共1M=220个存储单元
- 每个存储单元16位
- 容量2MB=16Mbits
- 地址线A[19:0] →ARM A[20:1]
- 数据线DQ[15:0]
- 控制线OE#、WE#、CE#
- BYTE# = 1表示工作在字模式
- RY/BY#指示编程或擦除的状态
ARM微处理器对NOR Flash的访问不需要其他任何软件的设置,系统在上电复位后,从NOR Flash的0X0地址开始执行第1条指令,即开始执行NOR Flash存储器的启动代码
NAND Flash内存的存储器接口设计
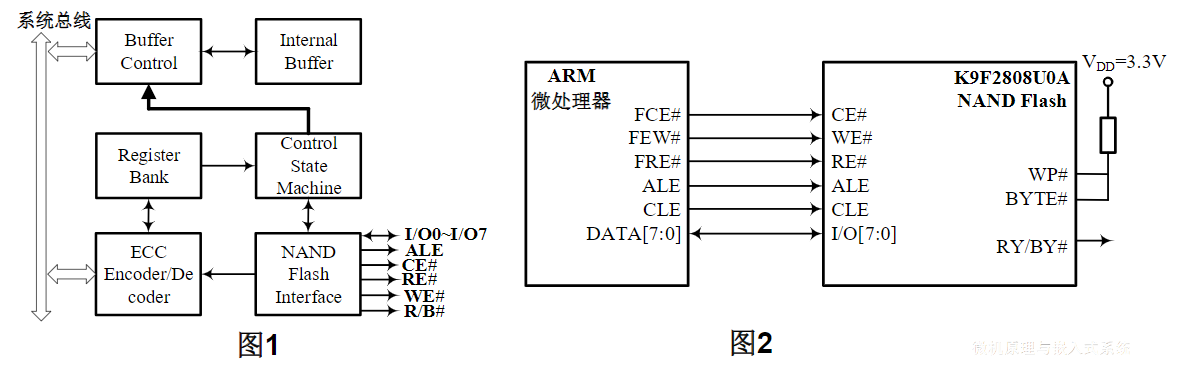
NAND Flash与嵌入式微处理器的连接,通过NAND Flash控制器实现
- ARM微处理器集成的NAND Flash控制器的内部结构方框图,如图1所示
- NAND Flash K9F2808U0A与ARM嵌入式微处理器的接口电路,如图2所示
NAND Flash 是以存储外设方式存在,故ARM微处理器对NAND Flash的访问,是通过NAND Flash控制器接口进行
SDRAM的存储器扩展设计
SDRAM作为同步动态存储器,是利用同一个时钟信号同步控制DRAM的地址、数据和控制信号。从而保持SDRAM的时钟频率与系统前端时钟频率,保证CPU对存储器的访问速度与处理速度一致
嵌入式系统采用SDRAM或者SRAM作为系统的主存储器器,用于保存程序运行过程中的实时数据或者存储从外存装入的程序或数据
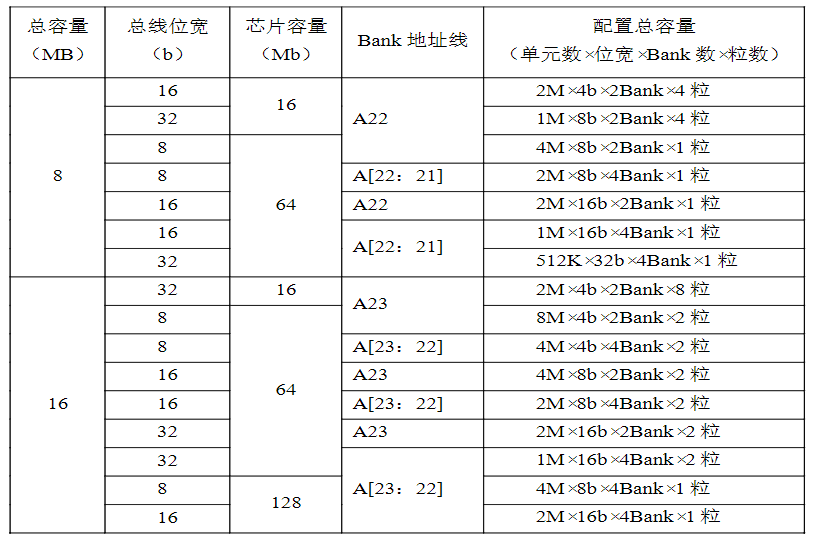
在SDRAM与ARM微处理器进行电路连接时,要根据实际,对扩展主存容量、芯片粒数、单元数、芯片位宽与Bank之间的关系进行配置
ARM微处理器SDRAM控制器Bank地址配置:
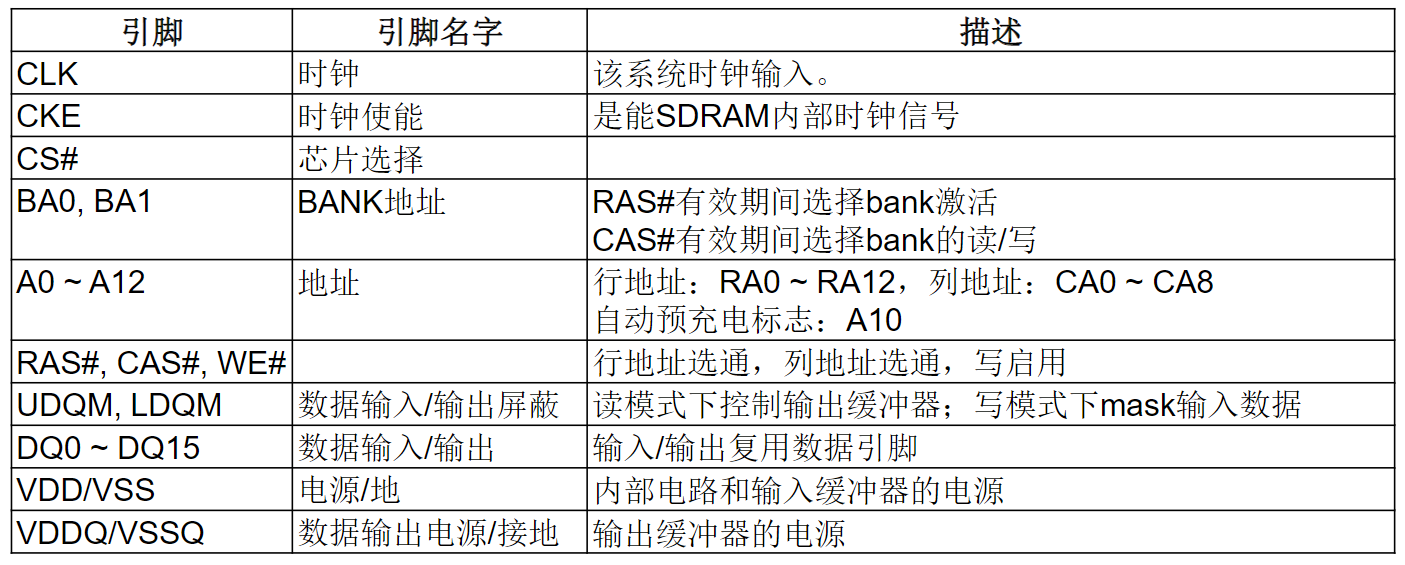
HY57V561620T SDRAM的引脚定义:
ARM微处理器与HY57V561620T SDRAM的连接示意图:
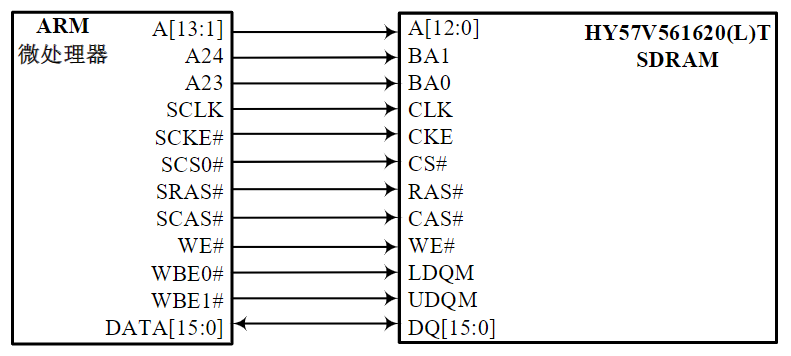
HY57V561620T的存储器组织为4M×16位×4Banks,从而构成32MB的总存储容量
4. 总线和接口
计算机不同部件间,如从硬盘到处理器、从CPU到内存,从内存到显卡,都需要进行数据传输。总线提供了一种经济的思路:把不同计算机部件均接到一个公共的通道上
4.1. 总线技术
4.1.1. 总线技术概述
4.1.1.1. 总线的概念
总线的作用
总线:计算机系统内部或者计算机系统之间传输信息的公共信道。总线是由一些电导体的互连组成,其具体形式可以是印刷线路、各种连接器、多路电缆等
系统早期的互联方式——分散连接
- 内部连线十分复杂,布线困难,扩展性差
- 效率高
现代的系统互连方式——总线连接
- 优点:简洁、协调、扩展性好
- 缺点:有共享竞争问题
接口的作用
计算机数据处理过程中存在大量数据交换
- CPU和计算机其他部件/外设之间
- 计算机不同部件/外设间:内存到显卡、网卡到内存...
外部设备种类繁多、差异大
- 信号形式:数字/模拟、电压/电流...
- 速度:摄像头30帧/s、键盘2-6次/s、打印机1-30页/s...
需要中间环节来协调
- 中间环节就是输入/输出(Input/Output,I/O)接口
- 接口电路起转换、缓冲速度匹配作用
总线与接口的区别与联系
电路单元之间的硬件电路
- 接口包括了电路单元之间的硬件电路
- 总线不仅包括分时共享传输线路和相关电路,也包括传输和管理信息的规则(即协议)(硬件+协议)
- 挂接在总线上的电路单元一定需要相应的接口电路。
点到点连接和多点互联
- 两个电路单元连接需要接口电路,未必需要总线协议。
- 多个电路单元互联,每个电路单元不仅要有接口电路,还需要按照总线协议来规范。
有时候并不做严格区分
- 广义的接口还包括了接口电路相应的驱动程序
总线的意义
考虑一个具有个电路模块的计算机系统,若模块间两两采用直接连接的方式,则实现所有模块互联共需要组连接线
总线的基本特性
总线的两个基本特性:共享、分时
共享:当多个部件连接在同一组总线上,各部件之间相互交换的信息都可以通过这组总线传送
分时:是指任意时刻只能有一个设备向总线发送信息,但是允许多个部件同时从总线接受相同信息(广播)
- 分时是制约系统性能的瓶颈
总线的主要性能指标
总线频率
- 每秒能够发起数据传输的最大次数(Transfer/s,T/s),也称总线传输速率,常用单位MHz
- 许多总线每个时钟周期能发起一次传送,总线频率就等于总线时钟频率
- 总线频率越高,传输速度越快
- 如ISA/EISA的总线频率为8MHz,PCI有33.3MHz和66.6MHz两种总线频率
总线宽度
- 总线可同时传输的数据位数,也称总线位宽。例如,8位总线、16位总线、32位总线等
- 总线越宽,相同时间内能传输更多的数据
总线带宽
又称总线最大数据传输速率,单位MB/s。影响带宽的因素有总线宽度、总线频率等,并行总线的带宽为:
带宽(MB/s)=总线宽度/8×总线频率
例:求33.3MHz@32位总线的带宽
总线带宽=32b/8×33.3 MHz =133.2MB/s
并行总线一次能传输多位数据,但信号间存在干扰,频率越高,位宽越大,干扰越严重,带宽难于提高
串行总线可通过较高的总线频率获得较大的总线带宽。此外,为弥补一次只能传送一位数据的不足,串行总线常用多条管线传输,其带宽为:
带宽=总线频率×管线数
同步方式
- 同步总线:主、从模块之间严格按照确定的时钟进行数据传输,传送速率较高,但是对模块的速度有要求
- 异步总线:主、从模块之间通过应答握手确保可靠传送,适应性广,灵活性高,但会减小总线带宽
总线复用
在一条线路上,不同的时刻传送不同的内容,例如某一时刻传输地址,另一时刻传输数据或命令信号,以减少总线的信号线数量,并提高信号线的利用率
信号线数
数据、地址、控制和电源总线数的总和。信号线数量与总线的性能不成正比
总线控制方式
包括并发工作、自动配置、仲裁方式、逻辑方式、计数方式等
寻址能力
指地址总线的位数及所能直接寻址的存储器空间大小
总线的定时协议
为使源与目的同步,需要有信息传送的时间协议。分为同步总线定时、异步总线定时、半同步总线定时
负载能力
指总线上最多能连接的器件数,一般指总线上的扩展槽的个数
总线特性
- 为了保证总线与部件之间机械上的可靠连接,必须规定其机械特性
- 为了保证电气上正确连接,必须规定其电气特性
- 为了正确传输信息,必须规定其功能特性和规程特性
4.1.1.2. 总线的分类
按物理接口分类:电缆式、主板式、背板式
按总线信号传输类型分类:数据总线、地址总线、控制总线、电源总线
按控制特性分类:同步总线、异步总线、半同步总线
按通信方式分类:串行总线和并行总线
按总线位置分类
- 片内总线(In Chip Bus),位于芯片(CPU或其他的处理器)的内部,连接CPU内部的各个部件
- 芯间总线(Chip Bus),也称为芯片总线(Component-Level Bus)或者局部总线(Local Bus),连接CPU和外围芯片
- 内总线(Internal Bus),又称为板级总线(Board-Level Bus)或系统总线(System Bus),用于系统内部各高速模块之间的互连。例如ISA、EISA、PCI等
- 外总线(External Bus),又称I/O总线或通信总线(Communication Bus),用于计算机之间,或者计算机与外设之间的互连。例如SCSI、USB等
片上总线的由来:片上系统SoC的发展,采用片上总线来描述芯片内部使用的总线(实际涵盖传统内总线及外总线的定义)
总线的层次结构:
- 计算机内部同时存在多条总线,通常采用多级分层结构
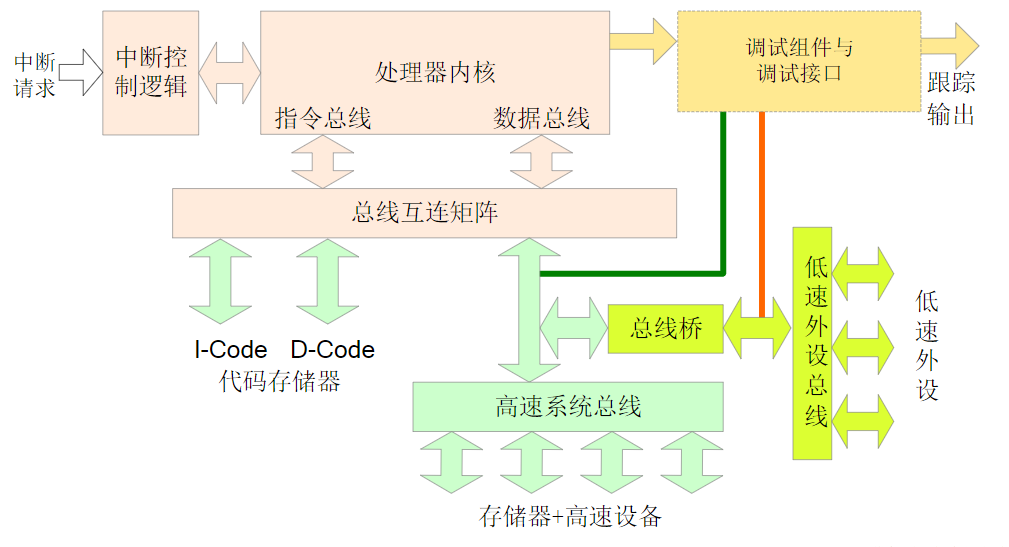
外总线的分层结构:
- 由于外设种类繁多,速率不一,通用计算机外部总线也采用层次化的结构
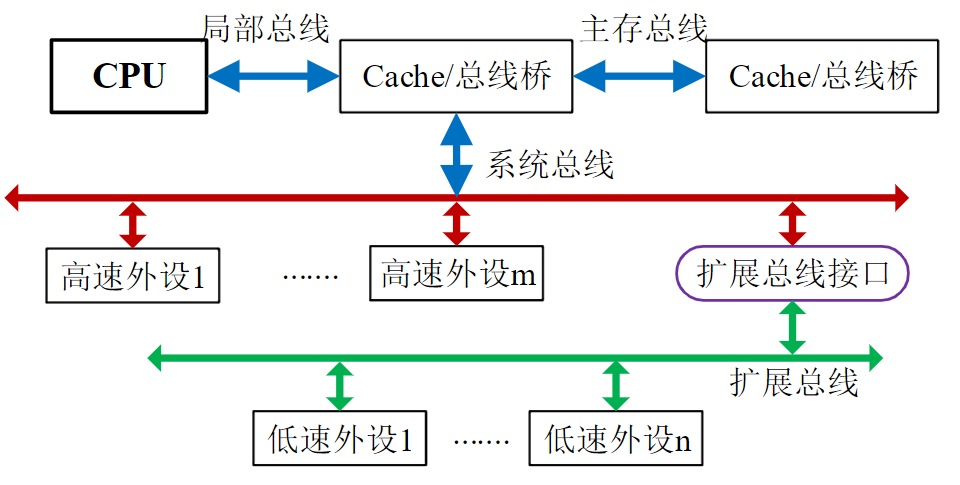
总线按功能分类
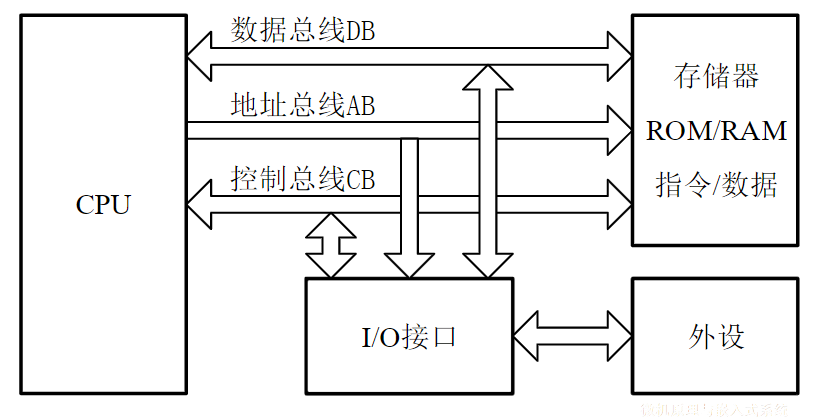
地址总线AB:专门用来传送地址
- 一般为单向传送总线,信号通常从CPU发出,送往总线上所连接的各个模块
- 也可用于I/O的寻址
- 地址总线宽度决定了系统最大存储器空间寻址范围。如:20位宽度的地址总线可寻址空间为220=1M,可寻址1M个存储单元。若数据总线为8位宽,则可寻址1MB;若数据总线为16位宽,则可寻址2MB
数据总线DB:用于传送数据信息
双向三态
数据总线的位数(宽度)通常与微处理的字长相一致
带宽(B/s)=总线宽度/8X总线频率
控制总线CB:用于传输完成各项操作所需要的控制信号
- 一般来说,总线信号线中,除电源线、地线、数据线和地址线外的所有信号线都归纳为控制总线
按数据传输方式分类
串行传输:串行总线
- 串行总线只用一根信号线(如果传输的是差分信号则是两根信号线)来传输数据
- 需传输的比特串一个接一个地在一条信道上传输
并行传输:并行总线
- 比特以成组的方式在两条或更多的并列信道上进行传输
- 一般为一字节或多字节,其位数为该总线的宽度
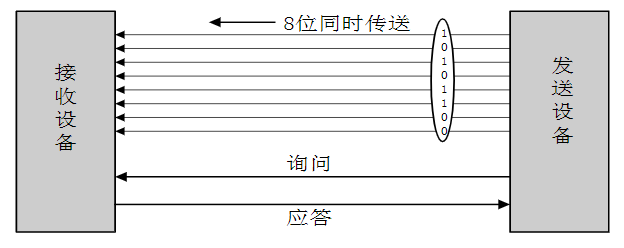
过去,内总线一般为并行总线,系统外总线多采用串行总线
按时序控制方式分类
异步总线
- 传输的双方有各自独立的定时时钟
- 通过主从双方的“握手”应答机制进行数据传输
- 传输可靠性高
- 但是握手应答导致速度较慢,例如Motorola公司的VME总线
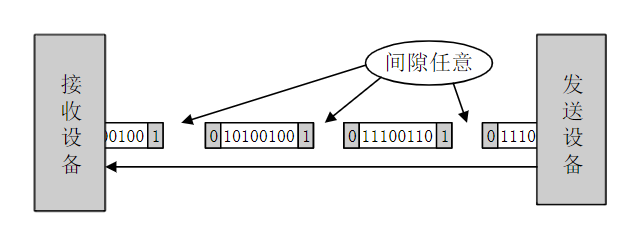
同步总线
- 所有挂接在总线上的设备,按照统一的时钟,在规定时间完成规定的工作
- 需要独立的信号线来传输时钟
- 没有握手应答过程,速度快
- 所有部件的速度应该相对一致
- 可靠性不如异步总线
- 为了照顾少数低速设备,采用“就绪-等待”机制——半同步总线
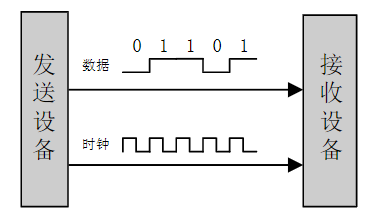
按时分复用方式分类
非复用
- 每条信号线的功能恒定
- 缺点:总线上信号线数量较多
复用
某些信号线在不同时段传输不同的数据,目的为了减少信号线的数量
区分服用信号的方法:
约定。例如PCI总线上的AD[31:0]是32根地址和数据复用的信号线,按照数据传送的规律,首先传送地址,然后再传送数据
增加专用信号线加以标识,如下图所示:

4.1.1.3. 总线的结构
单总线
- 将CPU、主存、I/O接口等都挂到一组总线上,CPU与内存以及与I/O之间访问都通过同一条总线
- 优点:结构简单
- 缺点:影响了CPU与存储器之间的数据存取速度

双总线:面向CPU的双总线结构
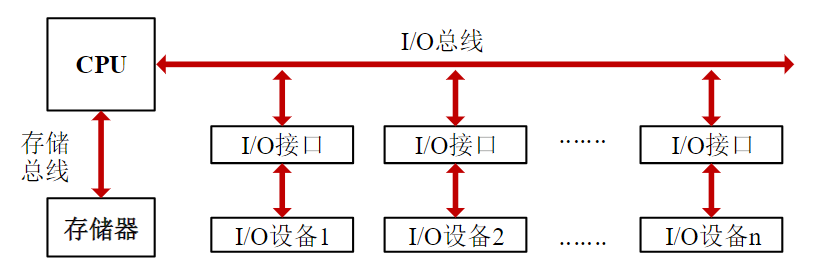
- 思想:设置一条与主存总线独立的I/O总线,专门连接速度低的I/O接口
- 优点:在CPU与主存储器之间、CPU与I/O设备之间分别设置了总线,提高了微机系统信息传送的速率和效率
- 缺点:外部设备与主存储器之间没有直接的通路,它们之间的信息交换必须通过CPU才能进行中转,会降低了CPU的工作效率
双总线:面向存储器的双总线结构
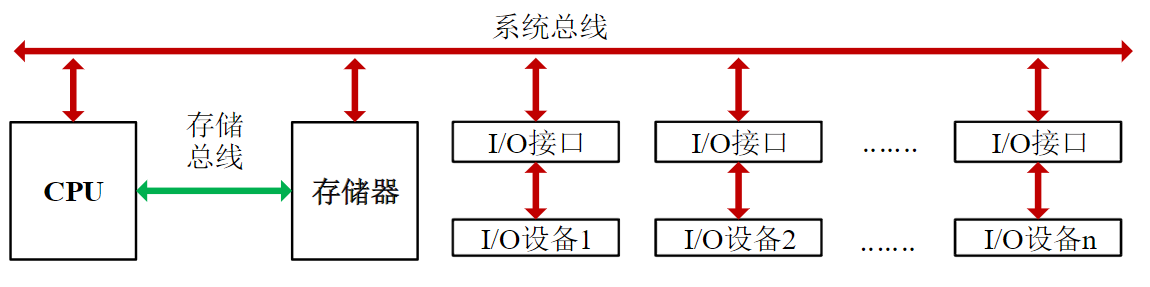
- 思想:在CPU与存储器之间,专门设置了一条高速存储总线,使CPU可以通过它直接与存储器交换信息
- 优点:面向存储器的双总线结构信息传送效率较高
- 缺点:I/O接口与存储器交换信息时,速度依然较慢
典型的三总线结构
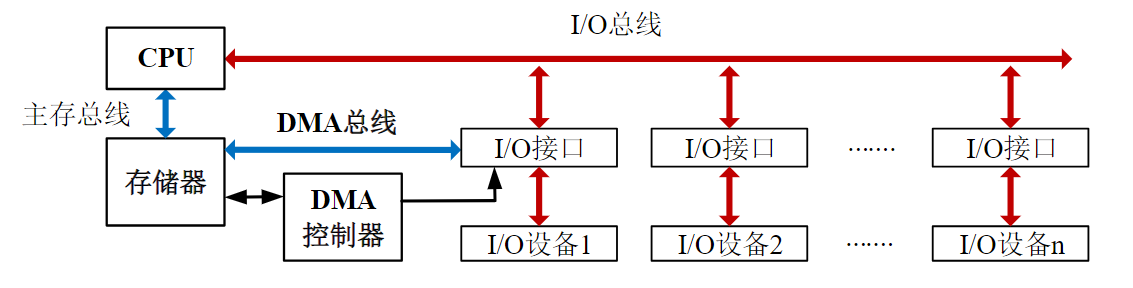
- 主存总线:连接CPU与主存
- I/O总线:I/O总线只有在CPU执行I/O指令时才能用到
- DMA总线:为高速I/O设备建立了一个到达主存的高速通道,称为DMA(Direct Memory Access,直接存储访问)总线
注意:任意时刻只有一套总线能够使用,主线总线与DMA总线不能同时访问主存
四总线结构
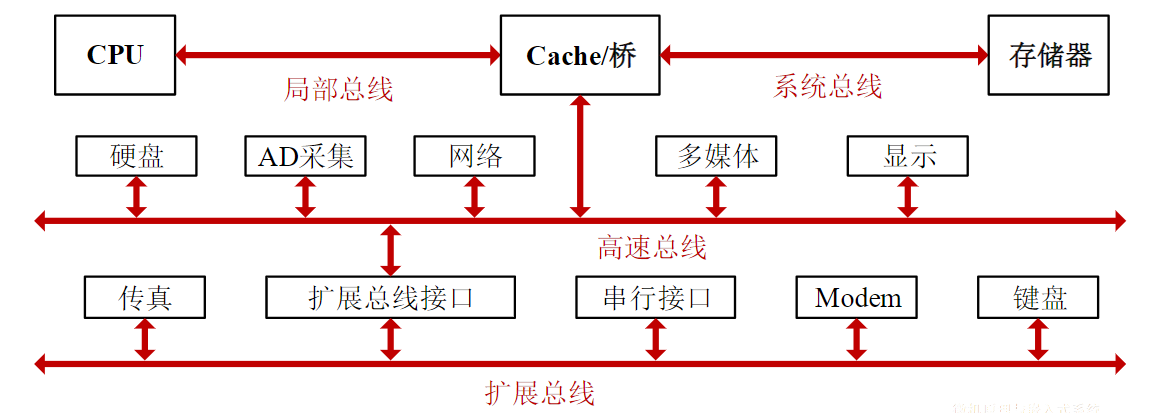
- 局部总线、系统总线、高速总线、扩展总线
- 增加了一条与系统相连的高速总线,连接高速的I/O设备,它们通过高速总线桥或者高速缓冲器与系统总线和局部总线连接
- 较低速的设备放在扩展总线上
- 优点:对于高速设备而言,比扩展总线上的设备更接近CPU,有利于提升高性能设备与CPU的效率,且高速总线和扩展总线的速度以及各自的信号线定义可以不同,有利于扩展不同类型的外设
4.1.2. 总线仲裁
总线上的设备
总线上的设备一般分为总线主设备(主控模块)和总线从设备(从属模块)。常把总线主设备称作总线主机,把总线从设备称作总线从机
总线主设备是指具有控制总线能力的模块,在获得总线控制权之后能启动数据的传输
从设备能够对总线上的数据请求做出响应,但本身不具备总线控制能力
总线仲裁(bus arbitration)是在多总线主设备的环境中提出来的
总线仲裁
总线的使用权分配即总线判优控制,也称为总线使用权仲裁。当有多个主设备同时申请总线时,按一定的优先等级顺序,判定哪个主设备能优先使用总线
两种仲裁方式:
- 集中式:将控制逻辑(即总线仲裁器)集中在一处,分为串行仲裁、并行仲裁、循环优先权以及串并行混合等方式
- 分布式:将控制逻辑分散在(与总线连接的)各个部件或设备上,由各个节点按照事先约定的协议,竞争使用权
4.1.2.1. 集中式仲裁
串行仲裁
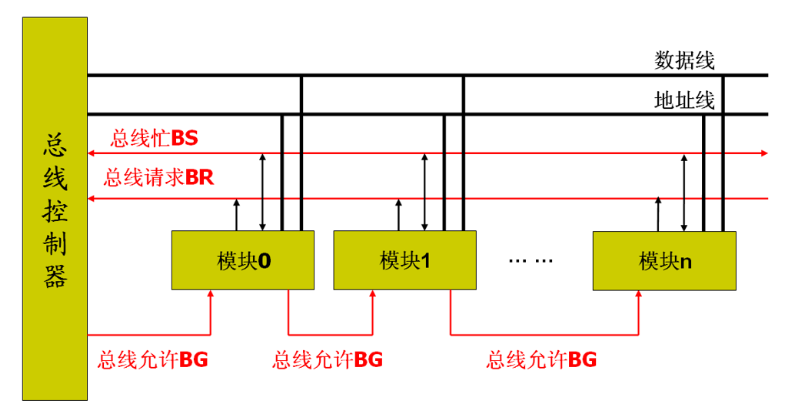
串行仲裁是最为常见的链式仲裁(“菊花链仲裁”)
- 信号线包括:总线请求BR(Bus Request)信号、总线允许BG(Bus Grant)信号和总线忙BB(Bus Busy)信号
仲裁过程:
- BB无效(即总线空闲)时,主设备才能提出总线请求
- 各主设备的BR信号用“线与”方式接到仲裁器的请求输入端
- 仲裁器在接到BR信号后输出BG信号,BG信号通过主设备链向后逐个传递,直到提出总线请求的那个设备为止
- 请求总线的主设备收到BG号后,获得总线的控制权,将BB信号置为有效,以通知其他设备总线已被占用,同时使总线仲裁器撤销BG信号
- 主设备的总线操作结束后,撤销BB信号,从而允许其他设备重新申请总线
特点:
- 使用总线的优先权由它到总线仲裁器的距离决定,最近的优先级最高,最远的优先级最低
- 链形优先级存在传播延迟,这种延迟与模块数量成正比,仲裁较慢。由于总线申请和使用权分配必须在一个时钟周期内完成,受总线周期的限制,一般只能接少量的(几个)模块
- 优点:信号线数与设备数目无关,电路实现简单,造价低
- 缺点:速度慢,连接方式确定后优先级即固定,不易更改,可靠性低,一个模块故障将造成整条链失效
举例:
- Intel MultiBus
- Motorola VME总线
并行仲裁
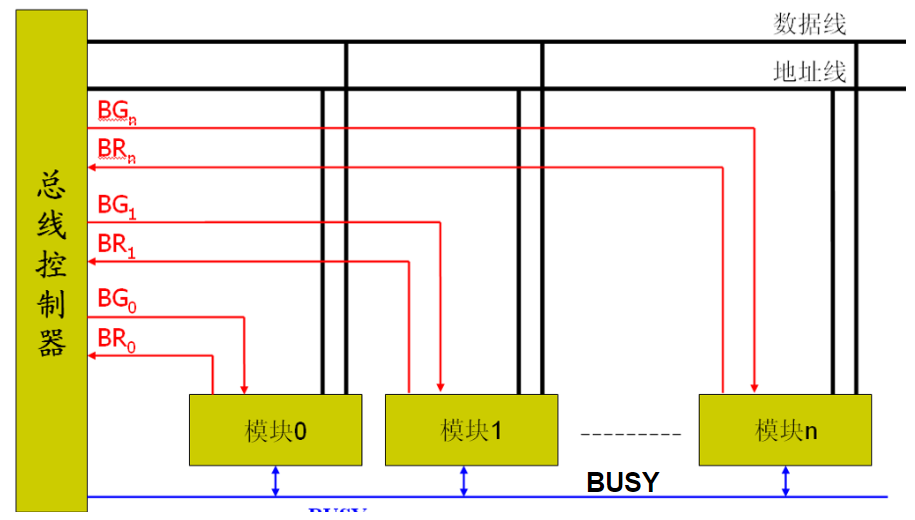
并行仲裁又称为“独立请求式仲裁”
- 每个主设备都有独立的总线请求BR和总线允许BG信号线,并分别接到仲裁器上
仲裁过程:
- 任一主设备使用总线都要通过BR信号向仲裁器发出请求,仲裁器按规定的优先级算法选中一个主设备,并把BG信号送给该设备
- 被选中的设备撤销BR信号,并输出有效的BB信号,通知其他设备“总线已经被占用”
- 主设备总线操作结束后,撤销BB信号,根据各请求输入的情况重新分配总线控制权
独立请求方式的工作原理:
- 每个模块有一条总线请求(BR)、一条总线允许(BG)和一条所有模块共用的总线忙(BUSY)信号
- 控制器内置一个优先级编码器和优先级译码器,用以选择优先级最高的请求,并产生出相应的“总线允许”信号
- 当BUSY信号有效时,表示有模块正使用总线,因此请求使用总线的模块必须等待,直至BUSY信号变为无效。所有需要使用总线的模块都可发“总线请求”信号,总线仲裁器仅向优先级最高的模块发出“总线允许”信号
特点:
- 判优速度快,且与模块数无关
- 所需的“请求线”和“允许线”较多,N个模块需要2N条
- 优点:仲裁速度快,优先级设置灵活
- 缺点:连接到总线上的设备数量受到限制
混合仲裁
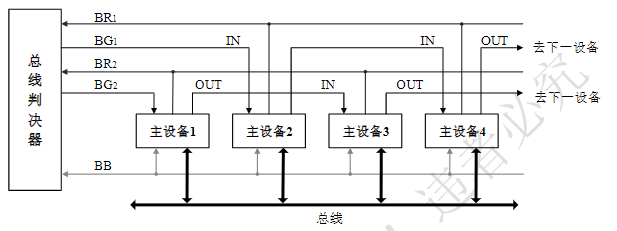
混合仲裁又叫多级仲裁
两级混合仲裁的结构:
- 总线判决器按照并行方式连接BR1和BR2
- 所有主设备的总线请求BR要么连接在BR1,要么连接在BR2上
- BG1按照串行方式连接一部分主设备,BG2按照串行方式连接另一部分主设备
仲裁过程:
- 先并行,所有主设备的总线请求首先经过总线判决器(BR1或BR2),总线判决器决定是BR1所连主设备还是BR2所连主设备获得总线控制权
- 按串行方式来决定BR1上的设备是主设备2还是主设备4、BR2上的设备是主设备1还是主设备3应该获得总线控制权
- 并行请求线BR1和BR2的优先级由总线判决器内部逻辑确定,同一链路上各设备的优先级则由该设备与总线判决器的远近程度确定
特点:兼具有串行仲裁和并行仲裁的优点,既有较好的灵活性、可扩充性,又可容纳较多的设备而结构也不会过于复杂,且具有较快的响应速度
4.1.2.2. 分布式仲裁
分布式仲裁方式中,每个设备模块都包含总线访问的控制逻辑,这些设备模块共同作用,分享总线
以自举分布式的总线仲裁为例:
假定模块1~4通过BR1~4进行自举分布式仲裁。其中BR1为总线忙信号,正在使用总线的模块应将BR1置为有效;BRi为模块i的总线请求信号线,只有在BR1无效时才能发总线请求。下图中设备1的优先级最低,设备4的优先级最高(主设备4输出,主设备1只能取回)
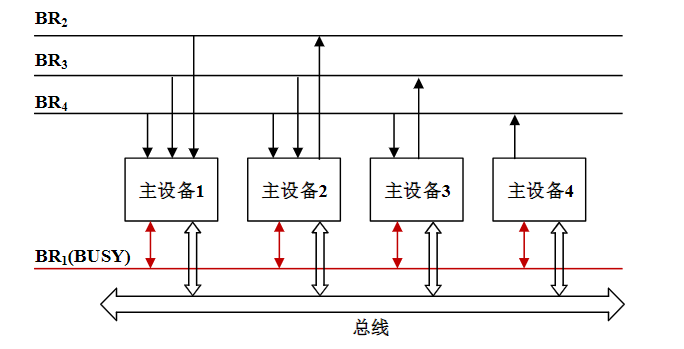
特点:使用多个请求线,不需要中心裁决器,每个设备独立地决定自己是否是最高优先级请求者
原理:分为申请期和裁决期
- 在申请期,需要请求总线控制权的设备在各自对应的总线请求线上发送出请求信号
- 在裁决期,每个设备将有关请求线上的合成信号取回分析,已确定自己能否拥有总线控制权
- 每个设备通过取回的合成信息能够检测出其它设备是否发出了总线请求
- 若检测到其他优先级更高的设备也请求使用总线,则本设备暂时不能使用总线;否则,本设备可立即使用总线
举例:NuBus(Macintoshi II中的底板式总线)和SCSI总线
4.1.3. 总线操作与时序
计算机系统中,通过总线进行信息交换的过程称为总线操作
- 包括:读/写存储器周期、读/写I/O端口周期、DMA周期、中断周期等
总线设备完成一次完整信息交换的时间称为总线周期(或总线传输周期)
在含多个主控制器的总线系统中,一个总线操作周期一般分为如下四个阶段:
- 请求及仲裁阶段:主模块请求,仲裁机构决定把下一个总线传输周期分给哪一个请求源
- 寻址阶段:取得总线使用权的主模块通过总线发出本次要访问的从模块(存储器或I/O端口)地址及有关命令,通知参与传输的从模块开始启动
- 数据传输阶段:主模块和从模块进行数据传输,数据由源模块发出,经数据总线到达目的模块
- 结束阶段:主模块、从模块的有关信息均从总线上撤销,让出总线,以便下一个总线传输周期其他模块能够使用总线
总线时序是指总线操作过程中总线上各信号在时间顺序上的配合关系,即主从设备如何在时间上协调和配合,以实现可靠的寻址和数据传送
总线时序的分类:同步总线时序、半同步总线时序、异步总线时序、周期分裂式总线时序
4.1.3.1. 同步总线时序
总线上的数据传输由统一时标控制
时标通常由CPU的总线控制部件发出,送到总线上的所有部件;也可以由每个部件各自的时序发生器发出,但是必须由总线控制部件发出的时钟信号对它们进行同步
优点:模块间的配合简单一致
缺点:主从模块之间的时间配合属强制性同步,必须按速度最慢的部件来设计公共时钟
例1:写命令
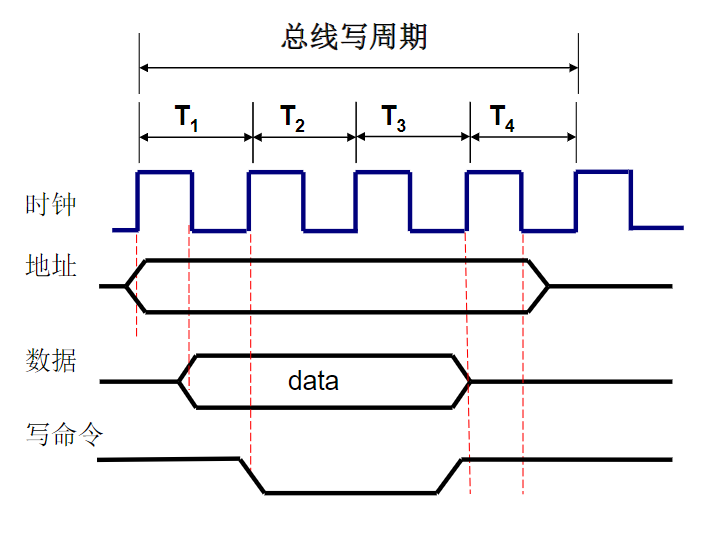
传输周期为:
- T1:主模块发地址
- T1.5:主模块提供数据
- T2 :主模块发写命令,从模块必须在规定时间内将数据写入地址总线所指明的单元中
- T4:主模块撤销写命令和数据等信号
例2:读命令
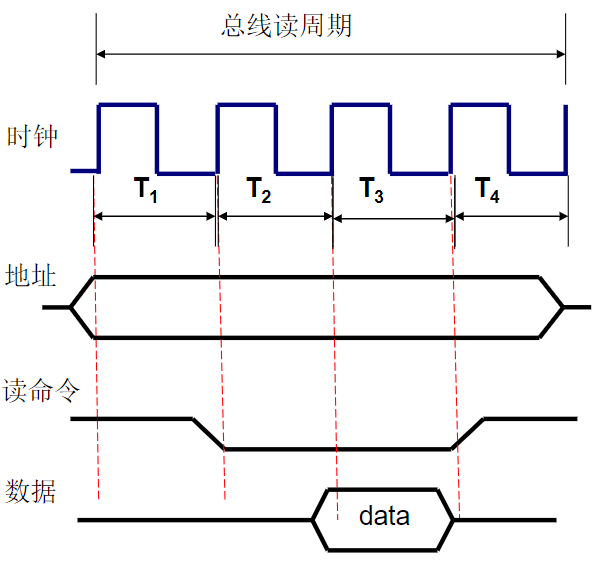
传输周期为:
- T1:主模块发地址
- T2:主模块发读命令
- T3:从模块提供数据
- T4:主模块撤销读命令
STD总线的读存储器时序
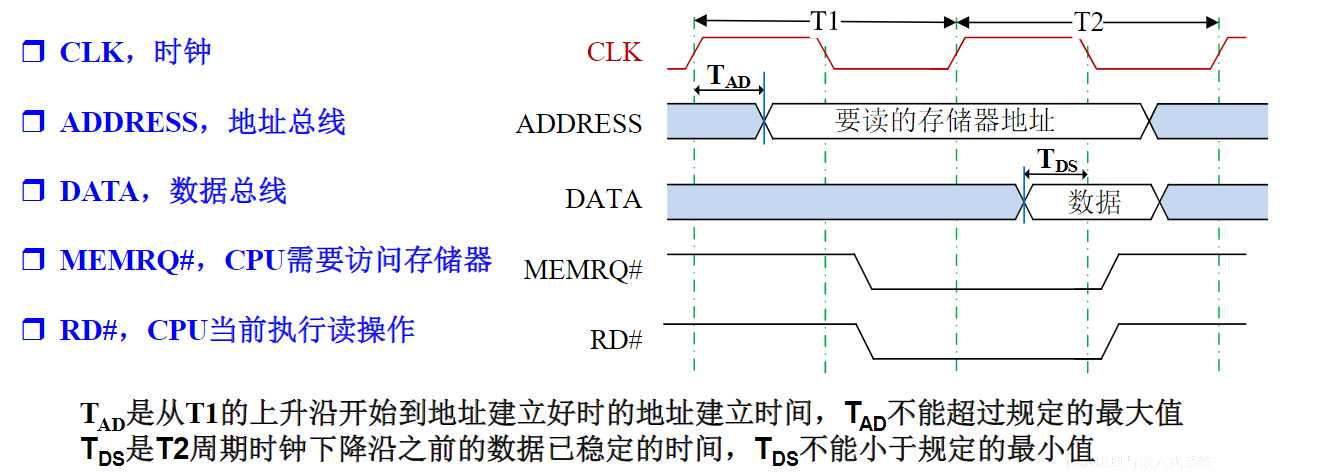
4.1.3.2. 异步总线时序
异步总线允许各模块速度的不一致性,提高了模块的适应性
异步总线中系统没有公用的时钟,主从模块之间通信时,采用应答方式进行联络和协调工作
根据问答信号之间的关系,异步总线时序可分成不互锁方式、半互锁方式和全互锁方式(又称握手方式)
主设备在发数据的同时发选通信号STB,从设备收到数据后应答ACK;主从模块之间增加两条握手应答线
不互锁方式
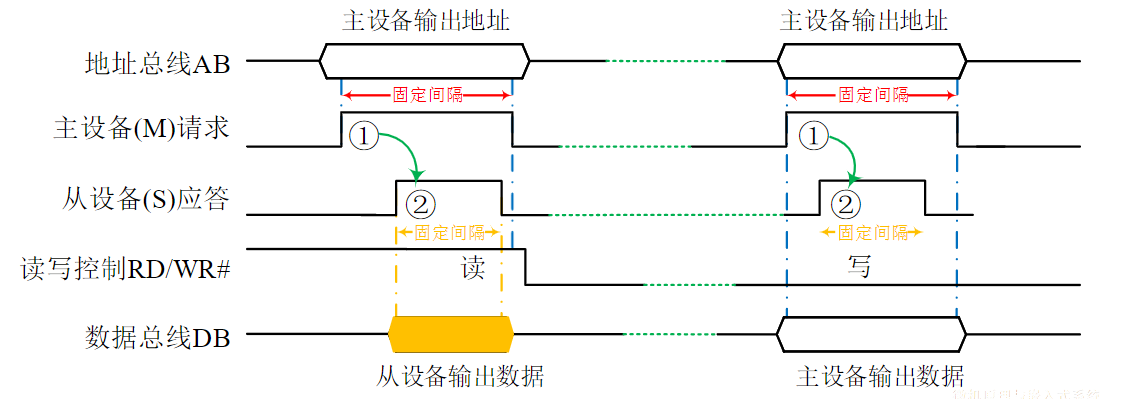
- 主设备发STB,高速从设备当前数据有效,间隔固定时间后,认为从设备已收到,撤销STB
- 从设备收到数据后发ACK应答,间隔固定时间后,撤销ACK
半互锁方式
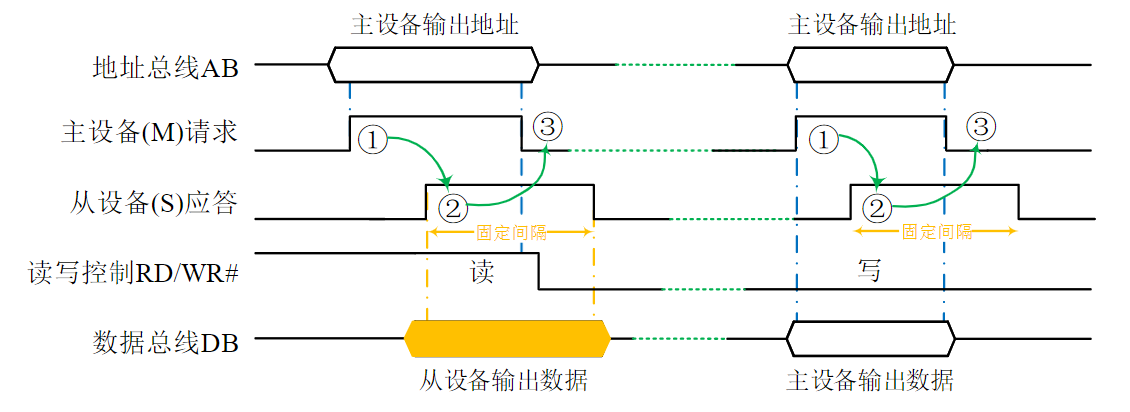
- 主设备发STB后,等待从设备的ACK应答,只有收到ACK应答后才撤销STB
- 从设备发ACK后,不等待主设备的应答,在间隔固定时间后,撤销ACK
全互锁方式(四边沿协议)
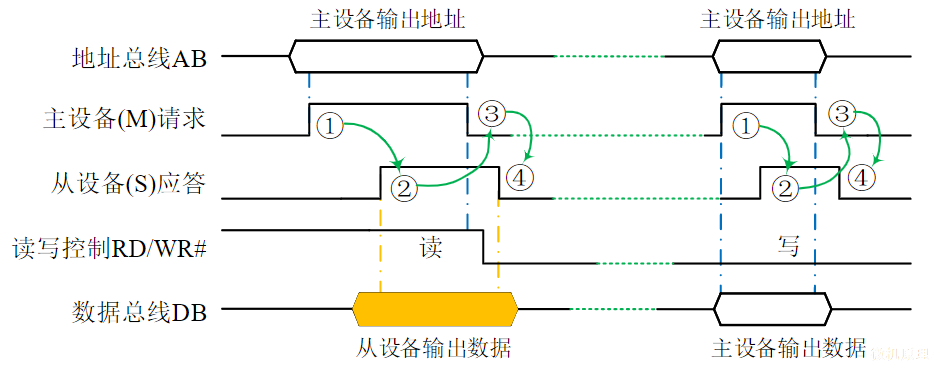
- 主设备发STB后,等待从设备的ACK应答,只有收到ACK后才撤销STB
- 从设备发ACK后,等待主设备的应答(撤销STB),然后才撤销ACK
主从设备相互等待,传输可靠性最高
关于同步和异步通信方式的讨论
传输速度
- 同步:如果从设备太慢,就无法满足时序要求
- 异步:应答过程的交互次数越多,速度越慢
可靠性
- 最可靠的方式:异步全互锁,每步操作“环环相扣”
兼顾传输速度和通信的可靠性
- 互锁方式应配合使用等待超时处理机制
4.1.3.3. 半同步总线时序
半同步总线是对同步总线的一种优化,对于大多数速度较快的传送对象,均按照同步方式定时
- 例如:主存储器的速度太慢,可插入一个时钟周期的办法让CPU等待存储器准备数据
对于系统所连接的少数速度较慢的设备,增加一条Ready/wait状态信号线,当慢速设备被访问时,可以利用这条信号线请求主模块延长传送周期
- 例如:8086/8088 采用的就是半同步总线。当检测到READY信号线被拉低,则在T3/T4之间插入Tw
半同步总线提高了系统的适应性,但是速度依然偏慢
示例
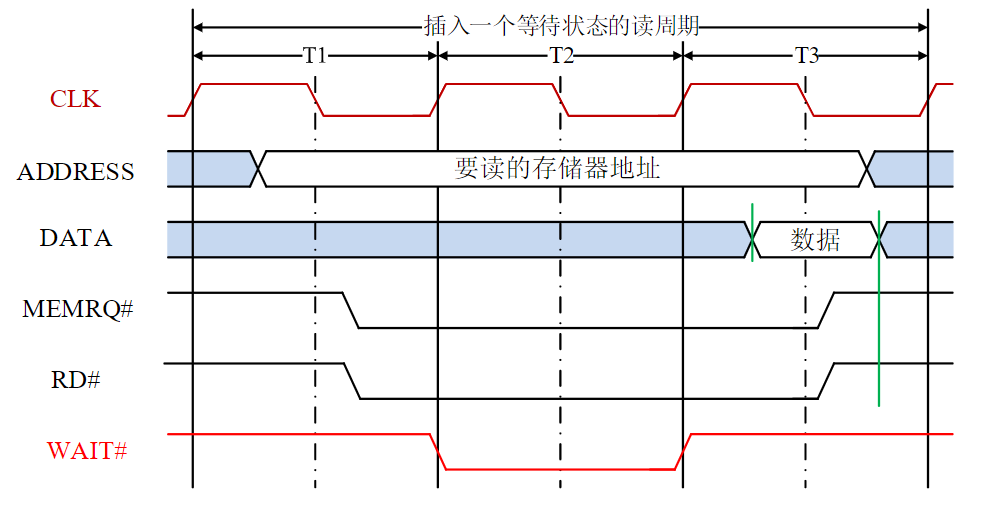
- WAIT#信号表示需要进行等待,低电平有效,WAIT#信号持续一个时钟周期,则CPU读数据的时间滞后一个时间周期
- 插入等待时钟周期的数目可以根据存储器访问速度来确定,如果存储器访问速度低于两个时钟周期,那么就需要插入两个等待时钟周期(WAIT#信号持续两个时钟周期)
4.1.3.4. 周期分裂式时序
在上述各种传输过程中,占用总线使用权的主设备以及被其选中的从设备,无论是否进行数据传输,始终占据着总线资源
若对读命令过程的进一步分析:在读命令传输周期中,除了申请总线这一阶段外,其余时间主要被用于如下三个方面的开销:
- 主模块通过总线向从模块发送地址和命令
- 从模块按照命令进行读数据的必要准备
- 从模块经总线向主模块提供数据
周期分裂总线的思想:将一个传输周期(或总线周期)分解成两个子周期(或称子阶段)
- 在第一个子周期(寻址子周期,或称为地址阶段)中,主模块A获得总线使用权后,将命令、地址、A模块编号等信息发到系统总线上,由相关的从模块B接收下来。然后A模块放弃总线,供其他模块使用
- 在第二个子周期(数据传输子周期,或称为数据阶段)中,B模块根据所收到的命令,经过一系列的内部操作,将A模块所需的数据准备好,然后由B模块申请总线使用权,一旦获准,B模块将A模块的编号和所需数据,B模块的地址等信息送到总线上,供A模块接收
分裂式操作的技巧是总线设计中一种重要的思路:
- 将一个耗时长的操作分成几个耗时短的操作也是流水线设计的基本思想
- 周期分裂式操作又称“分离式操作”、“流水线分离”等
4.2. 片内总线AMBA
4.2.1. AMBA总线概述
简介
AMBA(Advanced Microcontroller Bus Architecture)总线是ARM公司研发的一种片上总线(on-chip bus)标准
AMBA设计独立于处理器和芯片制造工艺
- 与工艺无关的片上协议,不提供任何与电气特征有关的信息,电气特性取决于设计时选择的生产工艺
AMBA拥有众多第三方支持
- AMBA2已具备相对完整的功能
- AMBA3侧重引入高性能的功能支持
- AMBA4/AMBA5针对多CPU核环境做相应的优化
AMBA定义了三种不同的总线:
- 高级性能总线AHB(Advanced High-performance Bus)
- 高级系统总线ASB(Advanced System Bus)
- 高级外设总线APB(Advanced Peripheral Bus)
| AMBA AHB | AMBA ASB | AMBA APB |
|---|---|---|
| 高性能 流水线(pipelined)操作 多总线主机(multiplebusmasters) 突发传输(bursttransfers) 分裂式操作(splittransactions) | 高性能 流水线操作 多总线主机 | 低功耗 地址锁存和控制 接口简单 适合大多数外设 |
基于AMBA总线的系统:
- 以AHB或ASB作为高性能系统中枢总线,支持CPU、片上存储器、外部存储器和DMA设备间的数据传输
- 用桥接器以连接低带宽的APB,外设挂接在APB上
一个基于AMBA2总线的微控制器系统如下:
4.2.2. AHB总线
4.2.2.1. AHB系统的构成
在AMBA2中,AHB担当高性能系统的中枢总线。AHB支持处理器、片上存储器、片外存储器,以及低功耗外设单元之间的有效链接
AHB总线是支持多主机的总线,能支持高带宽、高时钟频率的数据传输操作
AHB系统要素
AHB主机(Master)
即总线的主控模块。总线主机能够通过提供地址和控制信息发起读写操作。任何时候只允许一个总线主机处于有效状态并能使用总线
AHB从机(Slave)
即总线的从属模块。从机在给定的地址空间范围内响应主机发起的读写操作。从机将成功、失败或等待的信号返回给有效的主机
AHB仲裁器(Arbiter)
确保每次只有一个总线主机被允许发起数据传输。AHB要求即便在单总线主机系统中也要实现仲裁器,且所有系统中只有一个仲裁器
AHB译码器(Decoder)
AHB译码器用来对每次传输进行地址译码,从而为从机提供选择信号。AHB要求实现集中式的译码器
基于多路选择器的AHB总线互联
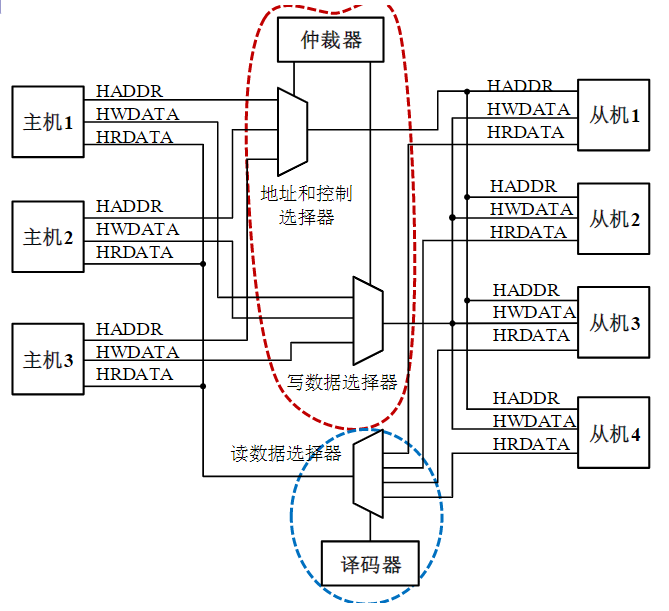
- 地址和控制选择器负责将主机发出的地址和控制信号连接至从机
- 数据选择器负责主机和从机之间的数据信号连接
- 仲裁器在不同的总线主机之间进行总线使用权仲裁,并决定当前得到授权的主机能将它的地址和控制信号连通到哪个从机
- 译码器控制读数据选择器,读数据选择器负责将从机信号连接到对应的主机上
AHB特点概述
支持突发传输(burst transfer)
启动一次AHB传输可以连续传输一个数据块
支持分裂式操作(split transaction)
寻址和数据传输子周期分离
单周期总线主机移交(single cycle bus master handover)
主机在时钟上升沿发出总线使用请求,仲裁器在时钟下降沿采样获得该请求,随即在下一个时钟上升沿更新总线允许信号。即:仲裁器在每个时钟周期都更新总线允许信号
单一时钟沿操作(single clock edge operation)
所有信号变化均发生在时钟上升沿,这利于芯片内集成更多的电路单元
非三态实现(non-tristate implementation)
可扩展至更宽的数据总线架构(64位或128位)
4.2.2.2. AHB信号定义
- AMBA中信号名称的前缀规则:
| 前缀 | 含义及示例 |
|---|---|
| T | 测试信号(与总线类型无关) |
| H | AHB信号,如HREADY是表示AHB的数据传输完毕的信号,高电平有效 |
| A | ASB信号,主机与仲裁器之间的单向信号 |
| B | ASB信号,如BRESn为ASB复位信号,低电平有效 |
| D | ASB信号,单向的ASB译码信号 |
| P | APB信号,如PCLK表示APB使用的主时钟 |
所有的信号名均为大写字母,信号若为低电平有效,则信号名称的最后加小写字母n
- AMBA中AHB的信号
| 信号名称 | 信号来源 | 用途说明 |
|---|---|---|
| HCLK 总线时钟 | 时钟源 | 为所有总线传输提供时基,所有信号时序都与HCLK的上升沿相关 |
| HRESTn 复位 | 复位控制器 | 总线复位信号,用于复位系统和总线,低电平有效 |
| HADDR[31:0] 地址总线 | 主机 | 32位系统地址总线 |
| HTRANS[1:0] 传输类型 | 主机 | 主机表示当前传输的类型,可以是不连续、连续、空闲和忙(NONSEQUENTIAL,SEQUENTIAL,IDLE,BUSY) |
| HWRITE 传输方向 | 主机 | 高电平时表示一个写传输,低电平时表示读传输 |
| HSIZE[2:0] 传输大小 | 主机 | 表示传输的大小,可以是字节(8位)、半字(16位)或字(32位)等,协议允许的最大传输大小是1024位 |
| HBURST[2:0] 突发类型 | 主机 | 表示传输是否组成了突发的一部分。支持4个、8个或16个节拍的突发传输,突发传输可以是增量或回环的 |
| HPROT[3:0] 保护控制 | 主机 | 提供总线访问的附加信息,指示当前传输的安全保护级别 |
| HWDATA[31:0] 写数据总线 | 主机 | 用来在写操作期间,从主机到从机传输数据。建议最小数据宽度为32位,在高带宽运行时可扩展 |
| HSELx 从机选择 | 译码器 | 每个AHB从机都有自己独立的从机选择信号,并且用该信号来表示当前传输是否打算送给选中的从机。该信号是地址总线的组合译码 |
| HRDATA[31:0] 读数据总线 | 从机 | 用来在读操作期间,由从机向主机传输数据。协议允许的数据宽度为:8、16、32、64、128、256、512、1024位 |
| HREADY 传输完成 | 从机 | 当该信号为高电平时,表示总线上的传输已经完成。在扩展传输时该信号可能会被拉低 |
| HRESP[1:0] 传输响应 | 从机 | 给传输状态提供了附加信息,提供四种不同的响应:OKAY、ERROR、RETRY和SPLIT |
- AMBA中AHB的仲裁信号
| 信号名称 | 信号来源 | 用途说明 |
|---|---|---|
| HBUSREQx 总线请求 | 主机 | 从总线主机x传向总线仲裁器,用来表示该主机请求(控制)总线的信号。系统中每个总线主机都有一个HBUSREQx信号,最多16个总线主机 |
| HLOCKx 锁定的传输 | 主机 | 当该信号为高时,表示主机请求锁定对总线的访问,并且在该信号为低之前,其他主机不应该被允许授予总线 |
| HGRANTx 总线授予 | 仲裁器 | 该信号用来表示总线主机x目前是优先级最高的主机。当HREADY为高电平时,传输结束,地址控制信号的所有权发生改变。所以主机应在HREADY和HGRANTx都为高电平时,获得对总线的访问 |
| HMASTER[3:0] 主机号 | 仲裁器 | 表示哪个总线主机正在执行传输,被支持突发传输的从机用来确定哪个主机正在尝试一次访问 |
| HMASTLOCK 锁定顺序 | 仲裁器 | 表示当前主机正在执行一个锁定序列(sequence)的传输。该信号与HMASTER信号有相同时序 |
| HSPLITx[15:0] 分离式传输请求 | 从机(支持分裂式操作) | 指示仲裁器,总线主机被允许重试一个分裂式操作。每位对应一个总线主机 |
信号后缀x表示模块x。如,HBUSREQx可能分别表示HBUSREQarm或HBUSREQdma
4.2.2.3. AHB的数据传输过程及“流水线”
在一次AHB传输开始之前,总线主机必须先获得总线访问的授权
该授权过程由总线主机向仲裁器发出一个请求信号而发起,随后仲裁器指示主机何时被授权
获得授权的主机通过提供关于地址信号、传输方向、传输宽度和传输类型等控制信号发起一次AHB传输
单个数据简单传输
两个阶段:地址阶段和数据阶段
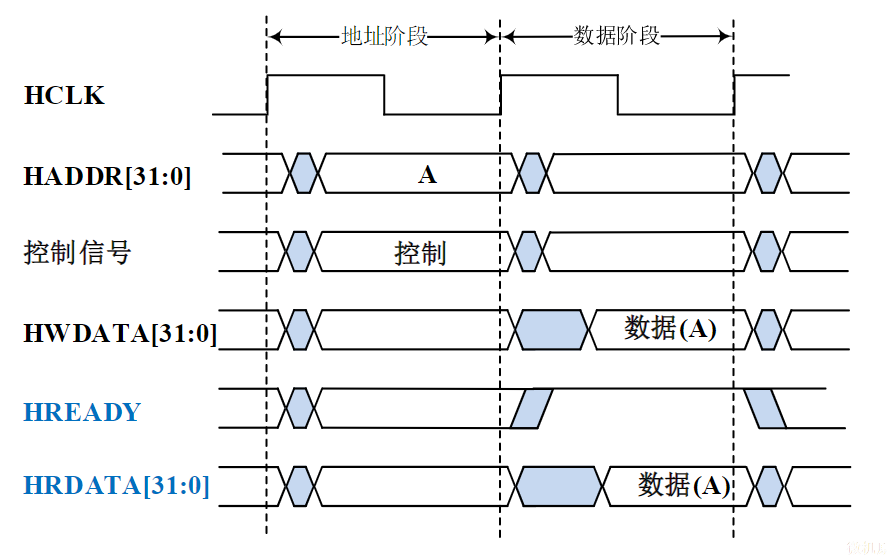
地址阶段仅持续一个时钟周期,用来传输地址和控制信息
数据阶段可持续一个或多个时钟周期,用来传输有效数据
主机写传输应关注
HADDR[31:0]和HWDATA[31:0];主机读传输应关注
HADDR[31:0]和HRDATA[31:0]传输过程:
- 第一个时钟周期的上升沿:主机把地址、控制等信息驱动到总线上(
HADDR[31:0]及其他控制信号线) - 第二个时钟周期的上升沿:从机采样获得这些地址和控制信息,并据此把相应的数据驱动到数据总线
HRDATA[31:0]上 - 第三个时钟周期的上升沿:主机在
HRDATA[31:0]上采样即可获得从机响应的数据
- 第一个时钟周期的上升沿:主机把地址、控制等信息驱动到总线上(
AHB的流水线机制
地址信息和数据信息交叠的操作方式,被称为流水线机制
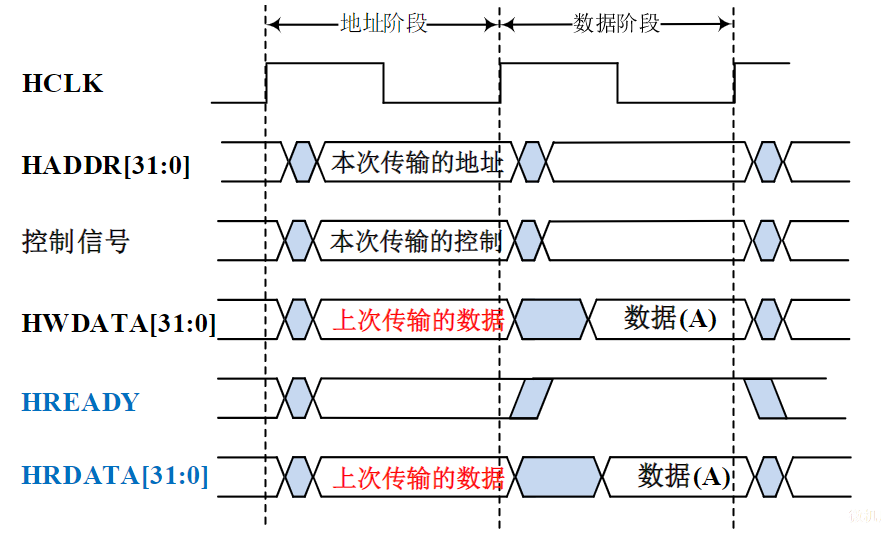
流水线分离:
2级流水线
- 第n次传输的地址在第n-1次传输时被驱动到了地址总线上。“驱动地址”和“驱动数据”两个操作构成2级流水线操作
- 从机因某种原因不能及时响应时,这个流水线就会被打断
周期分裂式时序
- 地址阶段和数据阶段可以被分离
- 从机不能及时响应时,发送控制信号
HSPLITx通知仲裁器 - 仲裁器检测到
HSPLITx后,知道从机当前不进行传输,则可以把总线的使用权出让给其他主机 - 当从机做好接收数据准备后,通过控制信号
HSPLITx发出重新启动传输的信号,仲裁器根据挂起操作主机的优先级决定何时再次分配总线使用权 - 当主机获得总线使用权后,重新发送地址、控制等信息,继续刚才挂起的传输操作
单个数据简单传输中插入等待状态
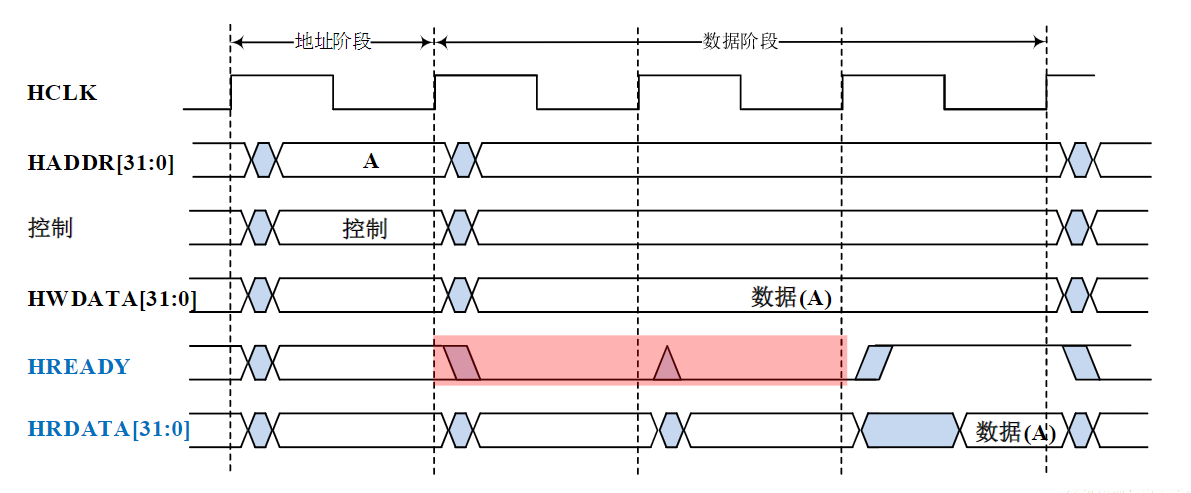
如果数据阶段持续一个时钟周期不足以完成数据的传输,从机可以通过
HREADY信号(拉为低电平)扩展数据周期(即插入等待周期)传输过程:
- 主机在HCLK上升沿之后将地址和控制信号驱动到总线上
- 在时钟的下一个上升沿,从机采样地址和控制信号
- 进入数据阶段,从机开始驱动适当的响应
- 若从机在数据阶段第一个时钟周期没能准备好,则需要把
HREADY拉为低电平,插入等待周期 - 从机准备好后,拉高
HREADY电平 - 总线主机在随后的下一个时钟(第五个时钟)上升沿采样
HRDATA[31:0]获得从机响应的数据
说明:
- 对写操作而言,总线主机必须保持数据在整个扩展期中稳定
- 在读传输中,从机没必要提供有效数据直至传输结束,只需要在相应周期提供数据即可
多个数据的传输
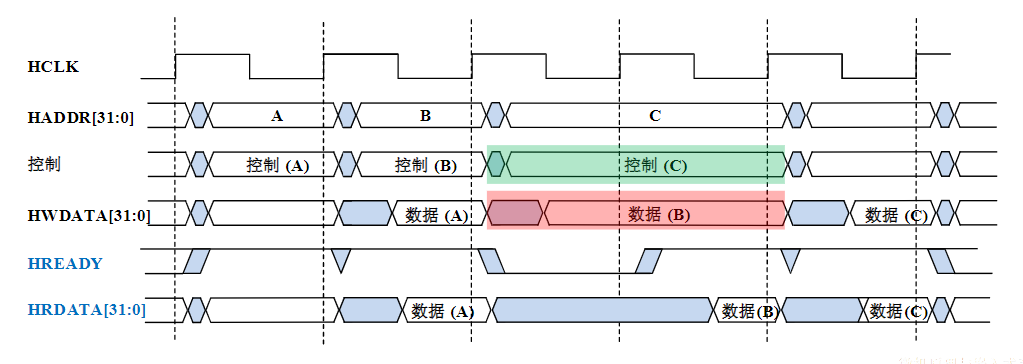
三次AHB传输分别需要传输的是地址A、地址B和地址C对应的数据
- 传输地址A和地址C数据都没有插入等待周期,但是传输地址B数据的时候插入了一个等待周期
- 地址B对应数据在总线上停留的时间被扩展为2个周期
- 对应地,地址总线上地址C也被扩展了
4.2.2.4. AHB的突发传输
突发传输
突发传输就是一次传输过程传输一个数据块而不是单个数据。既然是传输一个数据块,就涉及到数据块的长度,数据块的地址递增方式等
用突发传输类型信号HBURST[2:0]标识:
| HBURST[2:0] | 类型 | 类型的描述 |
|---|---|---|
| 000 | SINGLE | 单次传输 |
| 001 | INCR | 未标识长度的地址递增式传输 |
| 010 | WRAP4 | 突发长度为4的地址循环增式传输 |
| 011 | INCR4 | 突发长度为4的地址顺序增式传输 |
| 100 | WRAP8 | 突发长度为8的地址循环增式传输 |
| 101 | INCR8 | 突发长度为8的地址顺序增式传输 |
| 110 | WRAP16 | 突发长度为16的地址循环增式传输 |
| 111 | INCR16 | 突发长度为16的地址顺序增式传输 |
突发传输的状态
HTRANS[1:0]用来向从机指示突发传输过程中的不同状态,因而从机可知自身下一步的操作提示
| HTRANS | 状态 | 状态含义描述 |
|---|---|---|
| 00 | IDLE | 指示当前周期没有数据需要传输,当主机被授权使用总线,但是不需要传输时使用该状态 |
| 01 | BUSY | 指示主机正在进行突发传输,但是下一次数据传输不会马上发生。地址和控制信号线上的信号对应下一次即将发生的传输 |
| 10 | NONSEQ | NONSEQUENTIAL,指示当前传输是一次突发传输过程或单次传输的第一次传输。地址和控制信号线上的信号与前一次传输无关 |
| 11 | SEQ | SEQUENTIAL,一次突发传输过程中非第一次的传输。地址和信号线上的信号对应上一个刚完成的传输 |
WRAP4突发传输时序
WRAP4,拟传输数据的地址在16字节的边界处发生回转,0x38、0x3C → 0x30、0x34

整个传输过程共进行4次数据传输,插入1个等待周期T2
- T1周期:第一个拟传输数据对应的地址为0x38,在T1周期被推送到地址总线
HADDR[31:0]上,T1周期传输状态指示信号HTRANS[1:0]为NONSEQ,指示拟传输的数据是突发传输中的第1次 - T2周期:第2个拟传输数据的地址0x3C被推送到地址总线上,同时传输状态指示为SEQ
- T3周期:第1个拟传输数据被推送到数据总线
HWDATA[31:0]上 - T4周期:第3个拟传输数据的地址0x30被推送到地址总线上,同时第2个拟传输数据被推送到数据总线上
- T5周期:第4个拟传输数据的地址0x34被推送到地址总线上,同时,第3个拟传输数据被推送到数据总线上
- T6周期:第4个拟传输数据被推送到数据总线上
INCR4突发传输时序
INCR4,4个传输数据的地址变化是递增的(0x38,0x3C,0x40,0x44),没有在16字节边界处发生回转
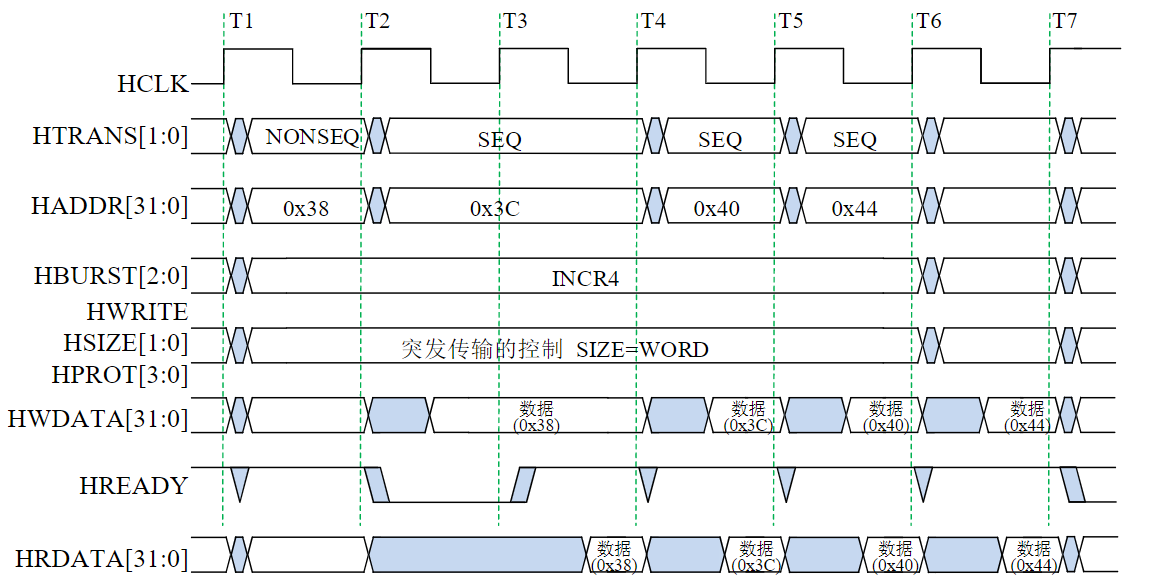
AMBA规范中定义:突发传输过程中拟传输的数据块不能跨越1kB的边界
4.2.2.5. AHB的译码
地址译码和从机选择信号
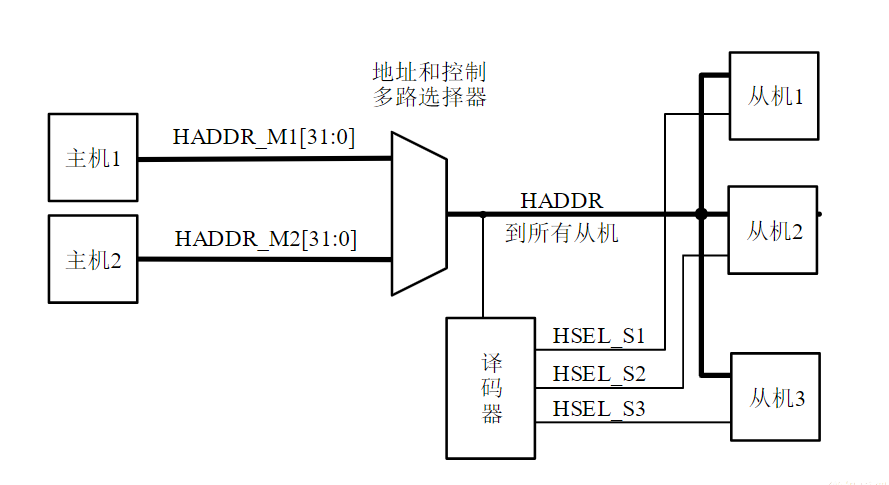
AHB总线通过一组多路选择器实现主从设备的互连
从机选择信号
HSELx:AHB总线上的所有从机使用一个中央地址译码器提供从机选择信号HSELx。选择信号是高位地址信号的组合译码结果。从机x在HSELx和HREADY有效的情况下,对地址和控制信号进行采样,从而获得地址和相关的控制信息能够分配给单个从机的最小地址空间是1KB。所有总线主机不允许执行超过1KB的地址边界的增量传输,因此确保了一个突发传输不会超过地址译码的边界
总线允许信号与主机号的生成
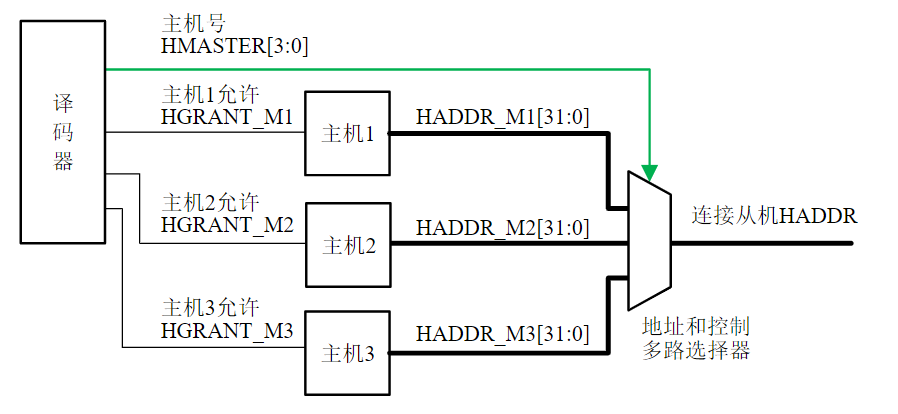
主线允许信号
HGRANTx:由于采用了一个集中式的译码器,每个主机可以在需要的时候随即驱动自身的地址信号,而无须等待总线允许信号HGRANTx对于主机而言,
HGRANTx信号是自身获得总线控制权的指示,同时,通过HGRANTx可知自己所驱动的地址是否已经被从机采样集中式的译码器根据各个主机的总线使用请求产生总线允许信号
HGRANTx,并在仲裁器的控制下生成主机号HMASTER[3:0],HMASTER[3:0]指示地址和控制多路选择器把主机的地址总线与对应从机的地址总线连接
4.2.2.6. AHB的仲裁
AMBA2中AHB的仲裁器接口信号
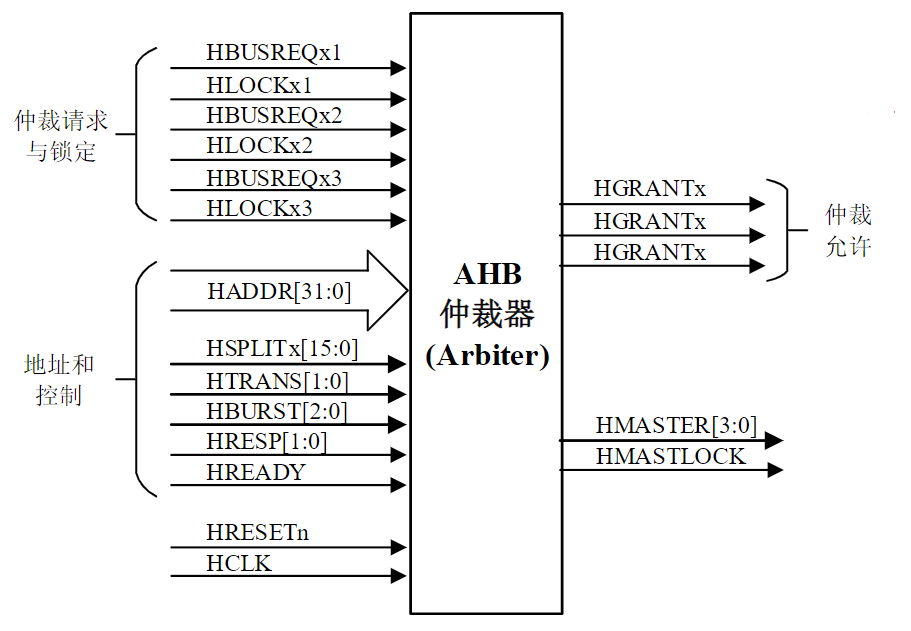
信号后缀x表示模块x,每个总线主机都有一个HBUSREQx信号,最多支持16个总线主机
仲裁机制是为了保证在同一时刻,只有一个主机能够控制总线。仲裁器通过检测请求的优先级等信息确定哪个主机能够获取总线控制权。同时,仲裁器也响应从机分离式传输的请求
无等待状态的仲裁授予
基本步骤:
- 主机通过
HBUSREQx信号请求对总线的使用需求,如果主机x希望使用总线的时候能够锁定总线资源,则同时需要发出HLOCKx信号 - 仲裁器通过
HGRANTx信号指示主机x获得了总线使用权 - 如果当前
HREADY有效,则不需要等待,仲裁器通过HMASTER[3:0]以指示当前获得总线使用权的主机号
HREADY有效的前提下的仲裁授予过程:
- 在T3周期的时钟上升沿。
HGRANTx有效 - 在T4周期的时钟上升沿,仲裁器开始驱动
HMASTER[3:0]指示了当前获得总线使用权的主机号,同时获取了总线控制权的主机将地址A驱动到地址总线HADDR[31:0] - 在T5周期的时钟上升沿,地址A对应的数据被驱动到数据总线
HWDATA[31:0]
有等待状态的仲裁授予

如果HGRANTx有效,HREADY为无效状态(低电平),则需要插入等待周期
有等待状态的仲裁授予过程:
- T4周期时钟上升沿由于
HREADY无效,插入了一个等待周期 - T5周期时钟上升沿时候,可检测到
HREADY有效,仲裁器开始驱动HMASTER[3:0]指示了当前获得总线使用权的主机号,同时,获取了总线控制权的主机将地址A驱动到地址总线HADDR[31:0]上 - T6周期时钟上升沿时候,
HREADY无效,故获得总线使用权的主机又等待了一个周期 - T7周期时钟上升沿的时候,才驱动数据到
HWDATA[31:0]上
总线控制权在两个主机之间移交
总线的控制权包括地址总线控制权和数据总线控制权,数据总线控制权滞后于地址总线
当一次传输完成后(通过HREADY信号高电平予以指示),随后拥有地址总线控制权的主机接管数据总线
主机2控制地址总线的时候,主机1仍在控制数据总线
突发传输后的总线移交
总线控制权移交发生在一次突发传输的末尾
仲裁器在倒数第二个地址被采样后改变总线允许信号HGRANTx
新得总线允许信号HGRANTx将与最后一个地址在相同时刻被采样
4.2.2.7. AHB主机接口及时序参数
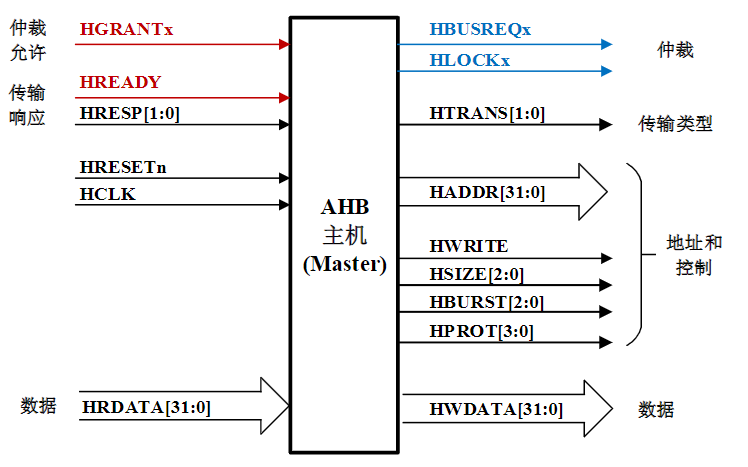
复位信号HRESETn:
- 复位信号
HRESETn是AHB中定义的唯一一个低电平有效的信号,该信号将引起所有总线上电路单元进行复位操作 - 复位信号
HRESETn的产生可以与时钟信号HCLK异步,但是复位信号的撤除是与HCLK同步的,需要与HCLK上升沿对齐 - 复位过程中,总线上所有的主机要确保地址总线和控制总线处于有效的状态且
HTRANS[1:0]指示处于IDLE状态
主机接口:
- 主机在
HREADY和HGRANTx都为高电平时,获得对总线的访问 - 主机
x通过HBUSREQx向总线仲裁器请求使用总线,通过HLOCKx告知其他主机不应该被允许授予总线
4.2.2.8. AHB从机接口及流水线分离
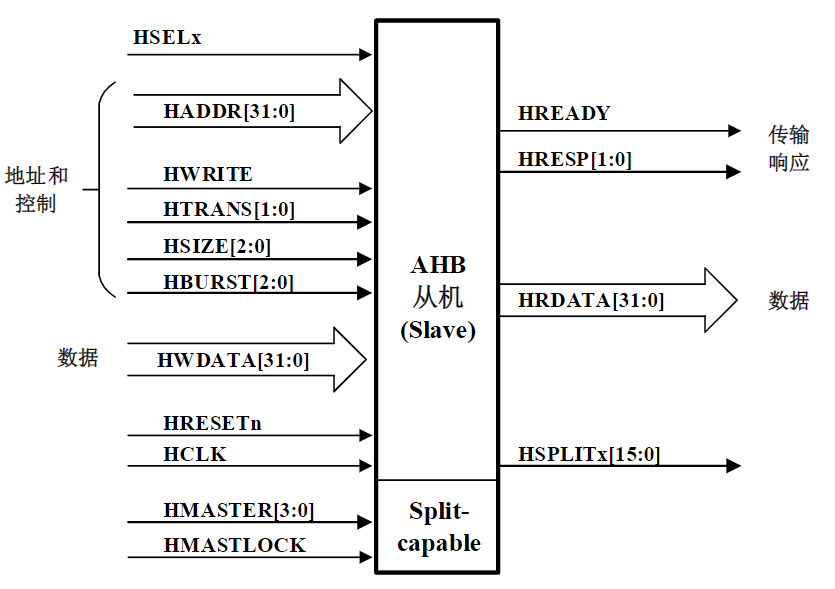
HMASTER[3:0]、HMASTLOCK和HSPLIT[15:0]用于支持“SPLIT”传输模式
SPILT传输
- AHB传输的两个阶段(地址阶段和数据阶段)可以被分离
- 流水线机制:第n次AHB传输的地址在第n-1次传输时就已经被驱动到地址总线上;两级操作:驱动地址+驱动数据
- 从机因某种原因不能及时响应时,流水线就会被打断,从而影响到总体性能。SPLIT方式的数据传输就是为了应对这种情形
- 从机在不能及时准备好数据时,
HSPLITx[15:0]发出启动SPLIT传输的信号。仲裁器检测到HSPLITx后,知道从机当前不进行传输,则可以把总线的使用权出让给其他主机 - 当从机做好接收数据准备后,通过
HSPLITx[15:0]发出重新启动传输的信号,仲裁器根据挂起操作主机的优先级决定何时再次分配总线使用权。当主机获得总线使用权后,重新发送地址、控制等信息,继续刚才挂起的传输操作 - 在传输的地址阶段,仲裁器产生一个标识号(主机号)
HMASTER[3:0],用来指示哪个主机正在使用总线。任何一个从机如果要发出SPLIT信号,需要根据HMASTER[3:0]信号决定HSPLITx[15:0]中哪个位要置1.HSPLITx有16耕信号线,意味着最多支持16个不同主机来源的传输采用SPLIT分离机制 - 注意:AHB中仅允许一个主机存在一个SPLIT传输,即SPLIT传输不可嵌套
4.2.3. AXI总线
从设计思想上看,ASB、APB可视为AHB功能的一个子集;AXI可视为AHB的升级版本;AXI之后的其他版本针对高性能、智能手机等不同场景改进设计
AHB总线分离了一个总线周期的地址阶段和数据阶段,更便于实现在现代总线中常用的Pipelining和Split技术
AXI总线则进一步分离了总线的通道,将AHB的单通道分解为5个独立的通道:读地址通道(Read Address)、读数据通道(Read Data)、写地址(Write Address)通道、写数据(Write Data)通道、写响应(Write Response)通道,进一步加速了对存储器的读写访问
AXI、AHB和APB的对比:
| 总线 | AXI | AHB | APB |
|---|---|---|---|
| 总线宽度 | 8,16,...,1024 | 32,64,128,256 | 8,16,32 |
| 地址宽度 | 32 | 32 | 32 |
| 通道特性 | 读写地址通道 读写通道均独立 | 读写地址通道共用 读写数据通道独立 | 读写地址通道共用 读写数据通道独立 不支持读写并行操作 |
| 体系结构 | 多主/从设备 仲裁机制 | 多主/从设备 仲裁机制 | 单主设备(桥)/多从设备 无仲裁 |
| 数据协议 | 支持流水线 支持分裂式操作 支持突发传输 支持乱序访问 字节/半字/字 大小端对齐 非对齐操作 | 支持流水线 支持分裂式操作 支持突发传输 支持乱序访问 字节/半字/字 大小端对齐 不支持非对齐操作 | 一次读/写传输占两个时钟周期 不支持突发传输 |
| 传输方式 | 支持读写并行操作 | 支持读写并行操作 | 不支持读写并行操作 |
| 时序 | 同步 | 同步 | 同步 |
| 互联 | 多路 | 多路 | 无定义 |
4.3. 系统总线/外部总线
4.3.1. PCI
PCI总线
PCI(Peripheral Component Interconnect)外部设备互连总线,是一种高性能的局部总线
PCI最早由Intel的IAL实验室提出,在IBM兼容PC上得到应用,后得到Compaq、HP和DEC等公司的响应,成立PCI-SIG
PC领域:逐渐被PCI Express总线替代;工业控制计算机领域:Compact PCI仍在广泛使用
PCI → PCI-X
最初的PCI标准中总线时钟(总线频率)为33MHz,数据线宽度为32位,可扩充到64位,数据传输速率可达132MB/s~264MB/s。后期的PCI版本64位并行数据传送,总线时钟支持33/66MHz,能够达到最高528MB/s的数据传输速率
在PCI的基础上,进一步提出PCI-X规范。PCI-X 553峰值速率是4.2GB/s
PCI总线结构
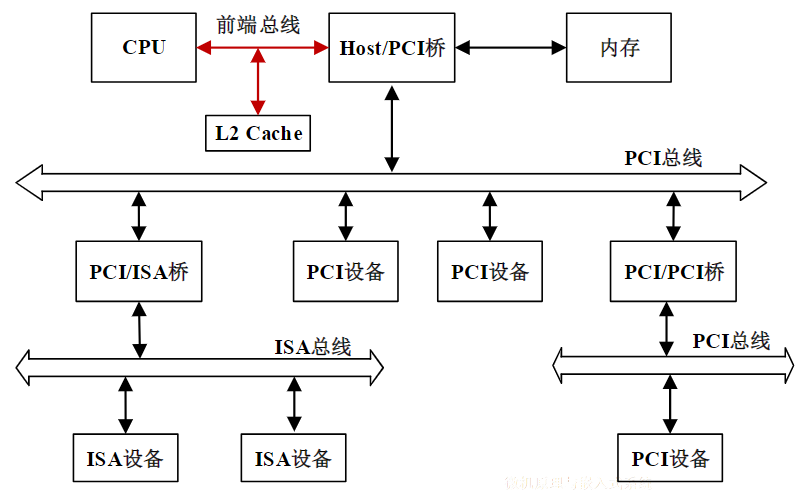
PCI总线的三类设备:PCI主设备、PCI从设备和桥设备
PCI总线在高速处理器与其他低速设备之间架起了一座“桥梁”。使计算机结构成为基于PCI总线的三级总线结构
PCI总线是一种树型结构,PCI总线上可以挂接PCI设备和PCI桥片,PCI总线上只允许有一个PCI主设备,其他的均为PCI从设备,而且读写操作只能在主从设备之间进行,从设备之间的数据交换需要通过主设备中转
PCI系统框图
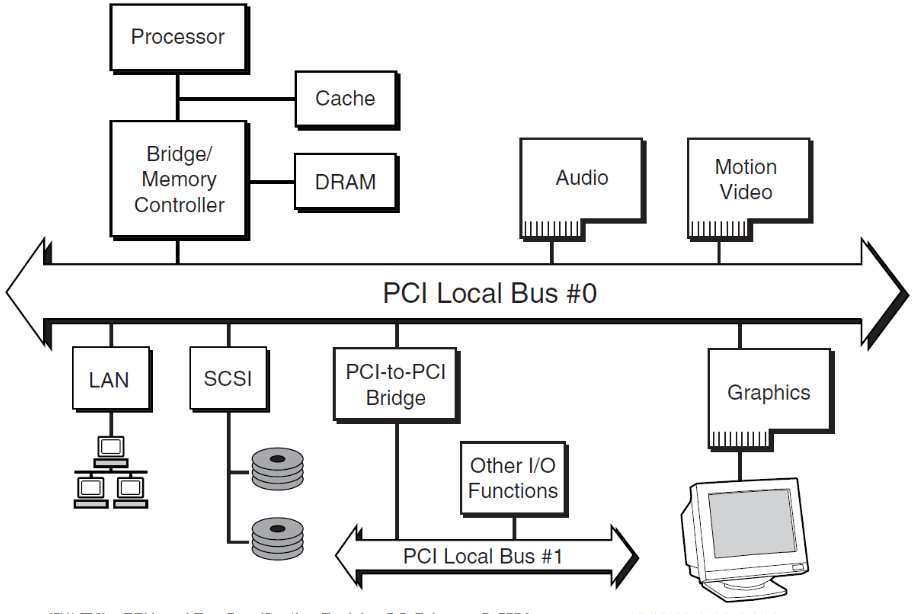
#0总线挂接了主存储器、辅助存储器、多媒体设备等不同外设
#1总线通过PCI-to-PCI桥设备挂接到#0总线
4.3.2. PCI Express
PCI Express(简称PCI-E或PCIe)
Intel公司提出用新一代的技术取代PCI总线和多种芯片的内部连接,称之为第三代I/O总线
包括Intel、AMD、DELL、IBM在内的20多家业界主导公司开始起草新技术的规范,并在2002年完成,对其正式命名为PCI Express
标准由PCI特别兴趣工作组(PCI Special Interest Group,PCI-SIG)维护和升级
相比于PCI,PCI-E最大的改变是由并行改为串行,使用差分信号传输
PCI-E的通道
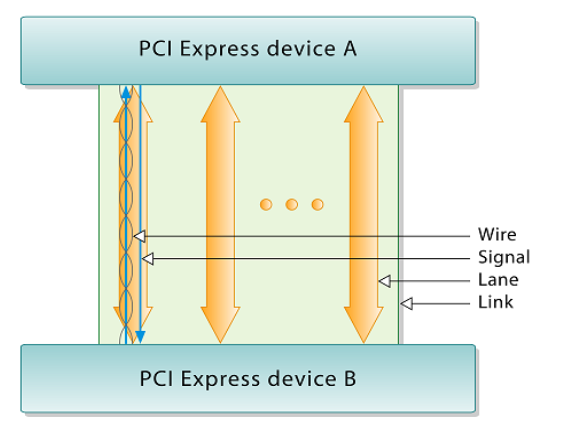
- 两个设备间的一条PCI-E链路(link)可包含1至32个通道(lane)。习惯上用X1、X4、X8、X16、X32等方式表示链路所包含的通道数目,也称为PCI-E的“宽度”或“位宽”
- 单个通道(lane)包含两对差分传输信号线,一对用于接收数据,另一对用于发送数据。故每个通道共4根信号线(wire)
- 逻辑上看,每个通道就是一条双向的比特流传输通路
目前高速接口均为串行标准
- ATA(IDE) → SATA (Serial ATA)
- SCSI → SAS (Serial Attached SCSI)
- ISA → PCI → PCI-Express
并行数据线多,CLK不能高
PCI-E点对点串行连接拓扑结构
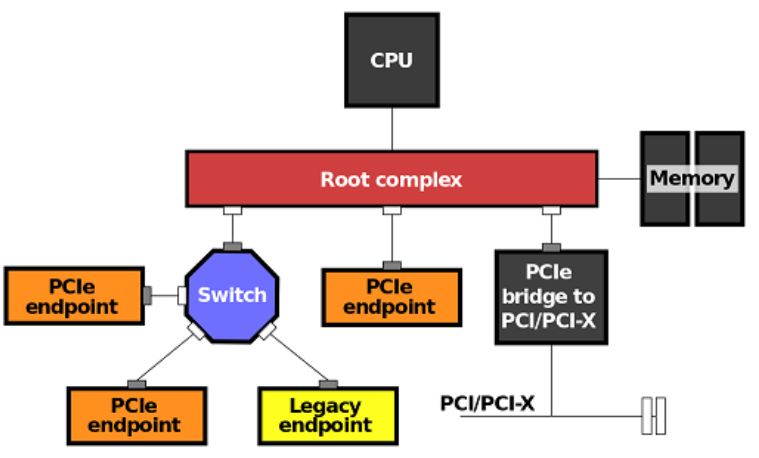
PCI Express总线是一种点对点串行连接的设备连接方式,各个设备之间并发的数据传输互不影响。PCIe系统包括Root complex、Switch、PCIebrige、Endpoint四大类设备
- Rootcomplex(根复合体)是处理器与PCIe总线的接口,通常由CPU集成
- Switch(交换器),允许多个设备连接到一个PCIe端口,用于扩展PCIe总线,具有路由功能
- PCIe桥,负责PCIe和其他总线转换连接,如连接PCI、PCI-X甚至是另外一条PCIe总线
- Endpoint(端点设备),即PCIe接口的各种设备,分为标准PCIe端点和传统端点(LegacyEndpoint)
PCI-E不同版本的传输速率
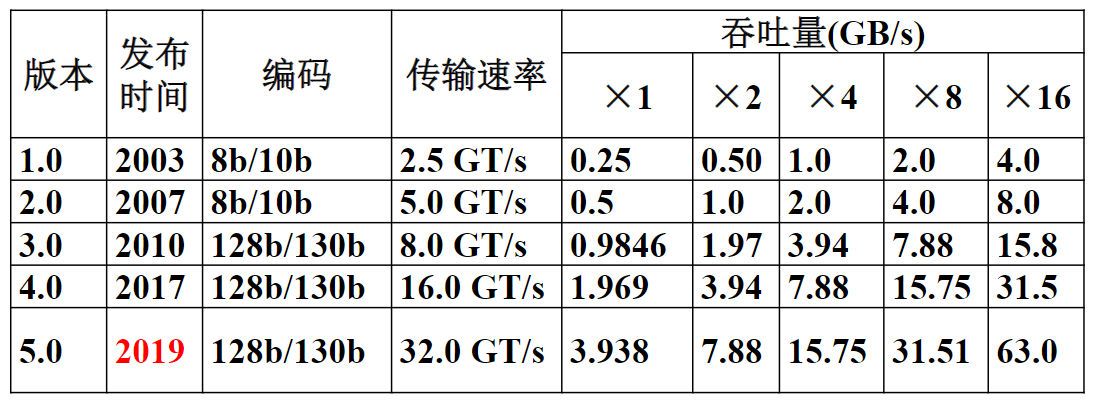
- 表中“8b/10b编码”意为将8比特编码为10比特
- 表中“GT/s”表示“giga transfers per second”,2.5 GT/s对应每秒钟每通道传输2500M比特,若采用8b/10b编码,实际每秒钟每通道能传输的业务比特是2500M*8/10=2000M (bits)=250M (Bytes)
4.3.3. USB
USB
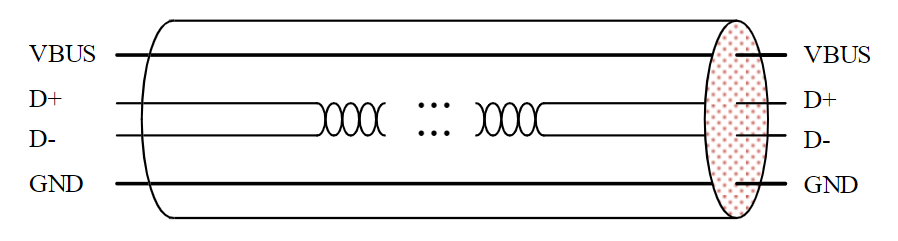
USB(universal serial bus),通用串行总线,是一种外部总线标准。用于规范电脑与外部设备的连接和通讯,是应用在PC领域的接口技术
USB接口支持设备的即插即用和热插拔功能
USB是在1994年底由由Compaq、Digital、BM、Intel,Microsoft、NEC和NothernTelecom7家公司联合提出的
在USB1.0/USB2.0中,“D+”和“D-”组成一对差分信号线用于数据传输,VBUS和GND对应5V电源和地
USB3.0后,又增加了两对差分信号线以提供更高速的数据传输
USB的机械接口

USB不同版本
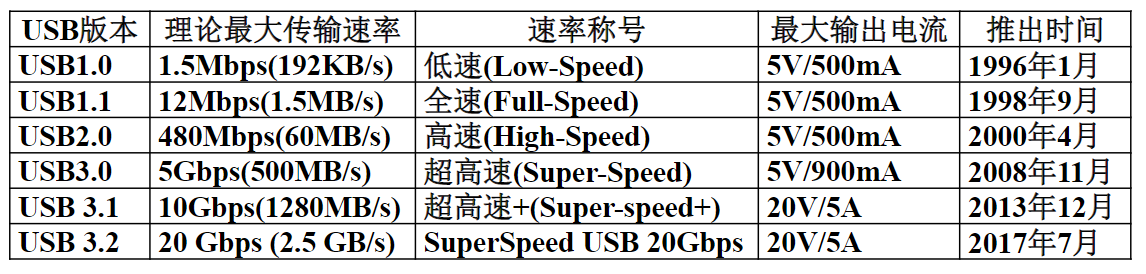
4.3.4. 典型的计算机总线系统
以8051为核心的嵌入式控制器的总线
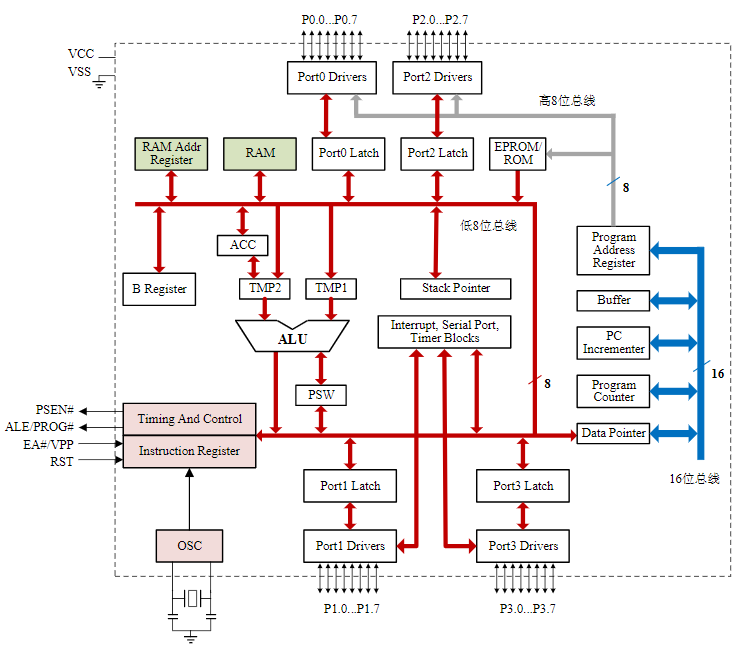
8051是一种八位单芯片微控制器,属于MCS-51单芯片的一种,由Intel于1981年设计
以Cortex-M3为核心的嵌入式控制器的总线
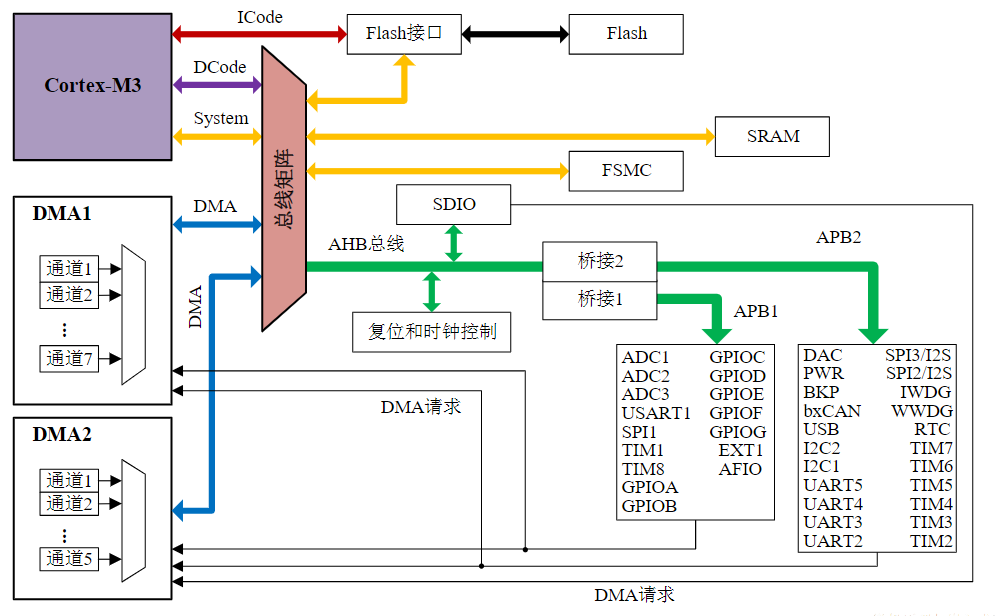
- Cortex-M3内核通过DCode总线访问数据存储器SRAM,通过ICode总线访问代码存储器Flash,同时挂接到系统总线上
- 两个DMA控制器通过DMA总线连接系统总线
- 外设模块则APB总线挂接,AHB到APB的桥连接所有的APB设备
- 所有的总线通过一个多级的AHB总线架构相互连接
基于8086的初期PC系统总线
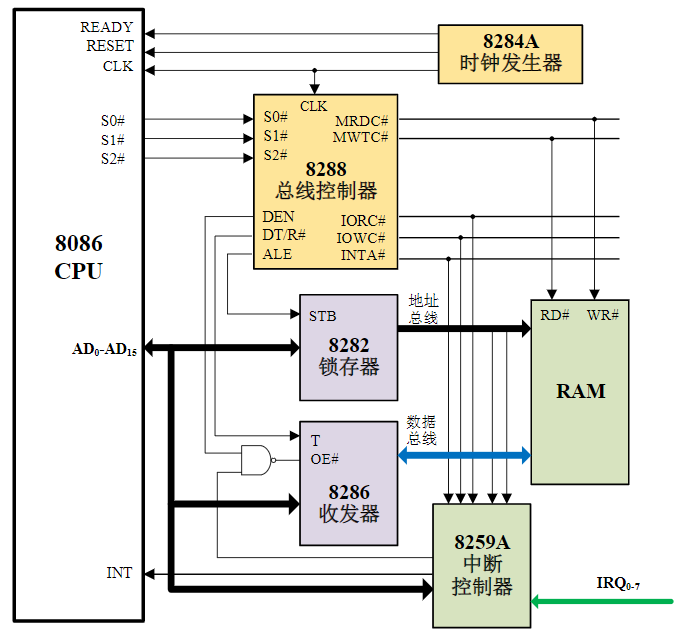
- 全球第一款16位通用微处理器芯片,诞生于1978年
- Intel在二十世纪70年代设计了8086微处理器,是x86架构处理器的鼻祖。8086有16根数据线和20根地址线(其中16根是与数据线复用的)
- 8086系统为简单的单总线结构
x86架构PC早期基于前端总线的多总线结构
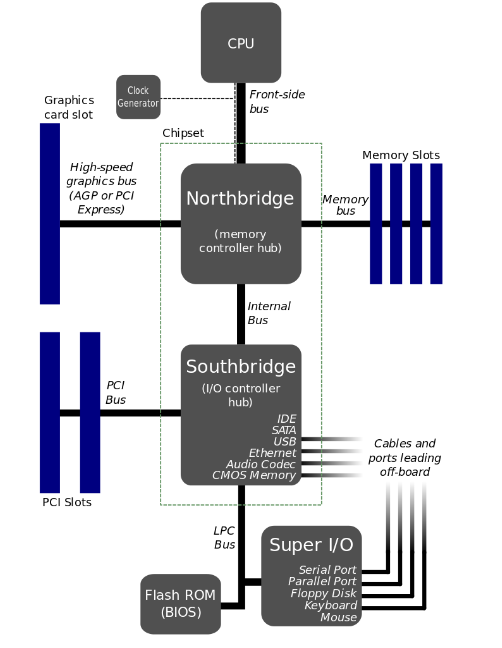
CPU通过前端总线FSB(F ro n tSideBus)与存储器和外设进行数据交互,计算机主板上的北桥(Northbridge)芯片负责联系内存、显卡等数据吞吐量最大的部件,并和南桥芯片(S o u t hbridge)连接。CPU就是通过前端总线FSB连接到北桥芯片,进而通过北桥芯片和内存、显卡交换数据
如今x86架构PC的PCH控制总线结构
2009年,Intel推出的单芯片设计的南北桥芯片整合方案。这颗主控芯片既不叫北桥,也不叫南桥,而是称作“Platform Controller Hub”芯片。PCH主要负责PCI-E和I/O设备的管理,它实际上仅提供南桥的功能(此时处理器已经整合北桥功能)
第十代智能英特尔® 酷睿™

- 2019年Intel发布的第十代智能英特尔® 酷睿™ 移动式处理器,添加了一些新的接口标准,如雷电接口、USB3.1、SATA3.0。
- PCH已经不再是一颗单独封装的芯片,而是和CPU一起被封装在一起
4.4. 输入/输出接口
CPU与存储器交换信息——数据格式和存取速度基本匹配
CPU与外设交换信息——由于外设的多样性
- 速度有较大差异
- 信号电平不一致
- 数据格式不同
- 时序不匹配
因此CPU必须经过中间电路再与外设相连,这部分电路被称为I/O接口电路
完整的I/O接口不仅包括外部设备与CPU或计算机之间的硬件电路,也包括相应的驱动程序
PC机系统板的可编程接口芯片、I/O总线槽的电路板、适配器/连接器都是接口电路
4.4.1. 输入/输出接口概述
4.4.1.1. I/O接口的功能
设置数据缓冲解决速度不匹配问题
- 事先把要传送的数据准备好,在需要的时刻完成传送。经常使用锁存器和缓冲器,并配以适当的联络信号来实现这种功能
设置电平转换电路解决电平不一致问题
- 如计算机和外设之间串行通信时,必须采用(线路)驱动器进行电平转换
设置信息转换逻辑满足各自格式要求
- 将外设传送的模拟量,经A/D转换成数字量,送到计算机去处理。计算机送出的数字信号经D/A转换成模拟信号,驱动某些外设工作
设置时序控制电路同步CPU和外设的工作
- 接口电路接收CPU送来的命令或控制信号、定时信号,实施对外设的控制与管理,外设的工作状态和应答信号也通过接口及时返回CPU,以握手联络(handshaking)信号来保证主机和外部I/O操作实现同步
提供地址译码电路
- 计算机中存在多个外设,每个外设需要与CPU交换几种信息,因此接口电路中常含若干端口,其I/O地址由接口电路中的地址译码电路提供
提供I/O控制、读/写控制及中断控制等逻辑
4.4.1.2. I/O接口的分类
按数据传输方式
可分为串行接口和并行接口
- 并行接口:指微处理器与I/O接口之间、I/O接口与外部设备之间均以多个比特位的并行方式送数据
- 串行接口:接口与外设之间采用单个比特位串行方式传送数据
串行接口 vs 并行接口
- 并行接口适用于传输距离较近、传输速度较高的场合,接口电路相对简单
- 串行接口适用于传输距离较远、传输速度相对较低的场合,传输线路成本较低,接口电路相对并行接口更复杂
按时序控制方式分类
同步接口
- 同步接口是指数据传输由统一的时钟信号同步控制,这个时钟信号为发送方和接收方共有
异步接口
- 异步接口上的数据传送则采用异步应答的方式进行,不依赖于统一的时钟
按主机访问I/O设备的控制方式分类
程序查询接口
- 指CPU通过程序来查询I/O设备的状态(状态信息通常保存在状态寄存器中),并执行相应接口的数据访问操作
中断接口
- 指I/O设备与CPU之间采用中断方式进行联络,即I/O设备向CPU提出中断请求,CPU响应中断请求后运行中断服务程序与I/O设备进行信息交换
DMA接口
- 指I/O设备与主存间采用直接内存访问的方式传递数据,这种交换方式一旦建立后,,不需要CPU参与即可实现存储器与I/O设备之间的数据传送
其他分类
如按数据流方向可分为单工、半双工、全双工
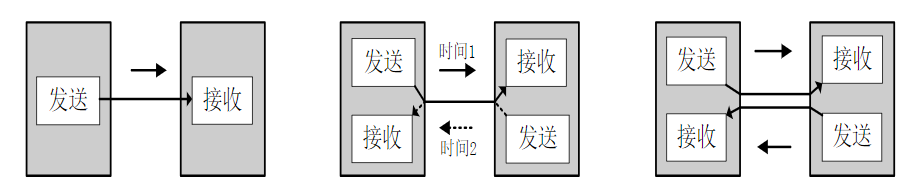
4.4.1.3. I/O接口规范的常规内容
接口设计的目的是为了协调上述微处理器与外设之间的不一致,用来实现速率匹配、缓冲、数据格式的转换和电平的转换等功能
依据不同外设的特点,形成了很多典型的接口设计,这些全球通用的接口设计方案往往以工业界公认的规范(Specification)形式出现
- 存储接口SATA(Serial Advanced Technology Attachment)
- 通用数据接口USB (Universal Serial Bus)
- 视频接口DVI (Digital Video Interface)
- 视频接口HDMI(High Definition Multimedia Interface)
输入/输出接口电路
输入/输出接口电路的功能隶属于通常意义的物理层功能。规定了为传输数据所需要的物理链路创建、维持、拆除,而提供具有机械的、电子的、功能的和规范的特性
- 机械特性,指明通信实体间硬件连接接口的机械特点。如接口所用接线器的形状和尺寸、引线数目和排列、固定装置等。
- 电气特性,规定了在物理连接上,导线的电气连接及有关电路的特性。一般包括接口电缆的各条信号线上出现的电压的范围、信号的识别、最大传输速率的说明、发送器的输出阻抗、接收器的输入阻抗等电气参数。
- 功能特性,指明物理接口各条信号线的用途,如某条信号线上出现的高低电压表示什么含义。如接口信号线分为数据线、控制线、地址线、时钟线和接地线等。
- 规程特性,规定接口传输比特流的全过程,及不同传输事件发生的先后顺序,规定了物理连接建立、维持和交换信息时,收发双方在各自电路上的动作序列
I/O接口标准的链路层功能
在一些输入/输出接口的标准定义中,除了物理层功能,也纳入了数据块格式、数据块检验方式等链路层功能(OSI模型的第二层)
4.4.1.4. I/O接口的结构
I/O端口
I/O端口指I/O接口电路中的各类寄存器
CPU与外设通信时,主要传送数据信息、状态信息和控制信息
在接口电路中,这些信息分别进入不同寄存器,CPU也是通过地址对这些寄存器进行寻址。为了与内存单元及CPU内部寄存器相区别,通常将这些寄存器和它们的控制逻辑统称为I/O端口
在一般接口电路中都要设置以下几种端口:数据端口、状态端口、命令/控制端口。此外还有中断控制逻辑,负责中断请求信号的建立与撤销
端口寄存器
读信号用以指示数据从I/O传输到CPU
写信号用以指示数据从CPU传输到I/O接口
高位地址生成片选信号,选择当前接口
低位地址连接外设片内地址线,选择内部端口
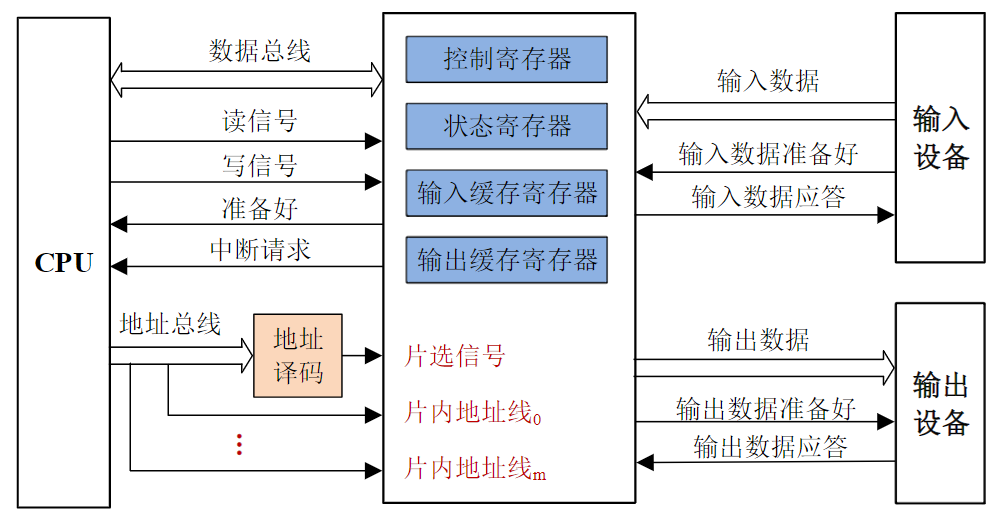
数据端口
- 用来存放CPU与外设需要交换的数据,长度一般为1~2字节。数据口主要起数据缓冲作用
状态端口
指示外设的当前状态。状态口通常具有以下几个常见的状态位,以反映外设的工作状态
准备就绪位(Ready)
- 对于输入输出端口,该位为1表明端口的数据寄存器已准备好数据,等待CPU来读取;当数据被取走后,该位清0
- 对于输出端口,该位为1表明端口中的输出数据寄存器已空,可以接收下个数据;当新数据到达后,该位清0
忙碌位(Busy)
- 表明输出设备是否能接受数据
- 若该位为1,表示外设正在进行I/O传送操作,暂时不允许CPU送新的数据过来
- 本次数据传送完毕,该位清0,表示外设已处于空闲状态,又允许CPU将下一个数据送到输出口
错误位(Error)
- 如果在数据传送过程中产生了某种错误,可将错误状态位置1,以便CPU进行相应的处理
- 系统中可以设置若干错误状态位,表明不同性质的错误,如奇偶校验错、溢出错等
命令端口
- 也称为控制端口(Control Port),用来存放CPU向接口发出的各种命令和控制字,控制接口或设备的动作
- 常见的命令信息有启动、停止、允许中断等
4.4.1.5. I/O端口编址
I/O端口的编址方法
为了让CPU能够访问这些I/O端口,每个I/O端口都需要有自己的端口地址(或端口号)
处理器通过端口地址可对各个端口寻址访问
I/O端口有两种编址方式:独立编址和统一编址
I/O端口统一编址
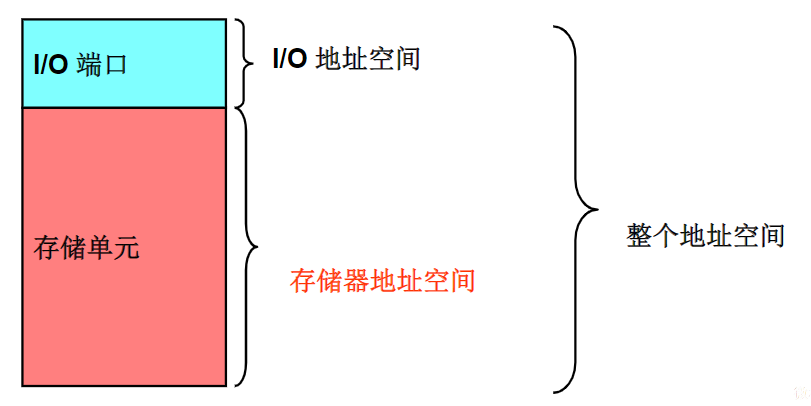
I/O端口统一编址也称为内存映像编址(memory mapped I/O addressing)方式
将外设接口中的I/O寄存器(即I/O端口)视为主存的存储单元,每个端口占用一个存储单元的地址,把主存地址的一部分划出来用作I/O地址空间
所有访存指令均可用来访问I/O端口,不用设置专门的I/O指令
I/O端口独立编址
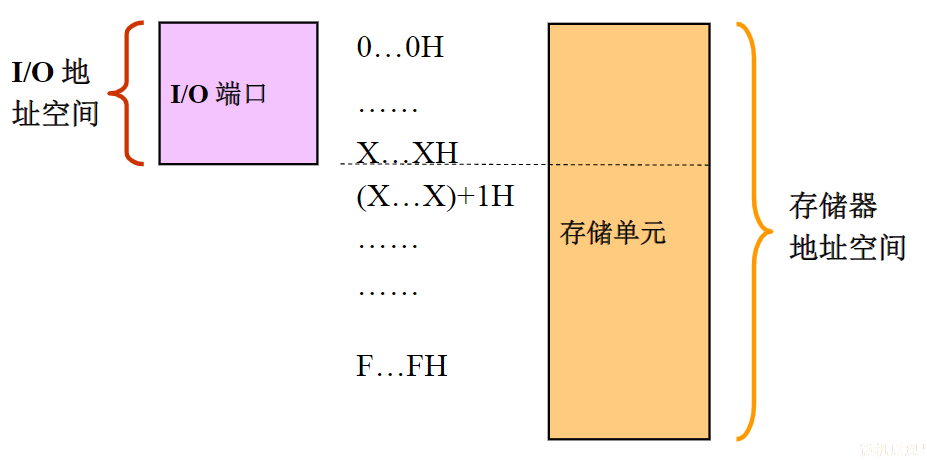
I/O端口独立编址又称分离编址(Isolated I/O Addressing)
存储器和I/O端口分开编址,即存储器和I/O端口的地址空间相互独立,I/O端口编址不占用存储空间,使用专门的
IN/OUT指令来访问I/O端口统一编址 vs 独立编址
独立编址:
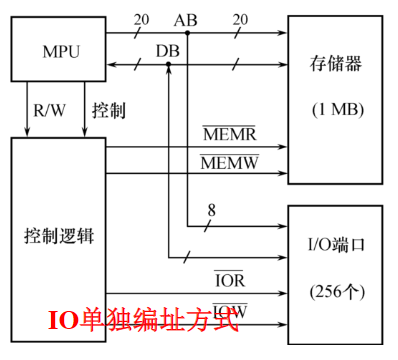
优点:
- I/O端口地址不占用存储器地址空间
- I/O端口地址译码较简单,寻址速度较快
- 使用专用I/O指令和存储器访问指令有明显区别,可使程序可读性较好
缺点:
- 专用I/O指令类型少,功能简单,远不如存储器访问指令丰富
- CPU提供存储器读/写,I/O端口读/写两组控制信号
统一编址:
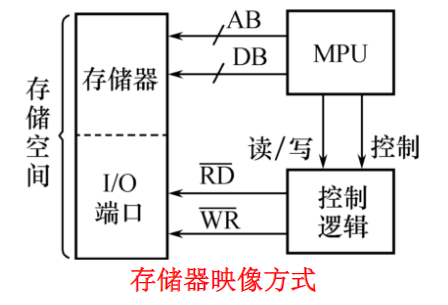
优点:
- 对I/O口的操作与对存储器的操作完全相同,无需专用的I/O指令
- 外设数目或I/O寄存器数目几乎不受指令限制
- CPU读/写控制逻辑较简单
缺点:
- 占用了存储器的一部分地址空间
- 增加了地址译码电路的复杂性
4.4.2. 输入/输出接口的数据传送方式
外设的多样性使外设极其接口电路的差异极大,故而需要多种CPU与外设接口交换信息的方式。常用的数据传送方式包括:
程序控制方式(软件),数据传送在程序控制下完成
- 无条件传送:外设永远处于“准备好”的状态
- 条件传送(查询传送):只有外设状态许可才可访问
中断方式(软件)
- 中断发中断请求,CPU响应后完成数据传送
DMA方式(硬件)
- DMA控制器临时接管CPU地址、数据和控制总线,在存储器和I/O接口之间实现直接数据传送
通道处理机方式(I/O Processor),专用I/O处理器,如Intel 8089
4.4.2.1. 无条件传送方式
也称为同步传送方式,主要用于对简单外设进行操作,所需的硬件和软件都较少
特点
- 需要输入时,总是认为输入设备处于准备好状态
- 需要输出时,总是认为输出设备处于准备好状态,无需对外设进行查询
- 需要输入或输出操作时,直接执行I/O输入输出指令,立即进行数据传送操作
- 此类接口在实现时,数据输入需要使用缓冲器,数据输出需要使用锁存器
I/O接口电路
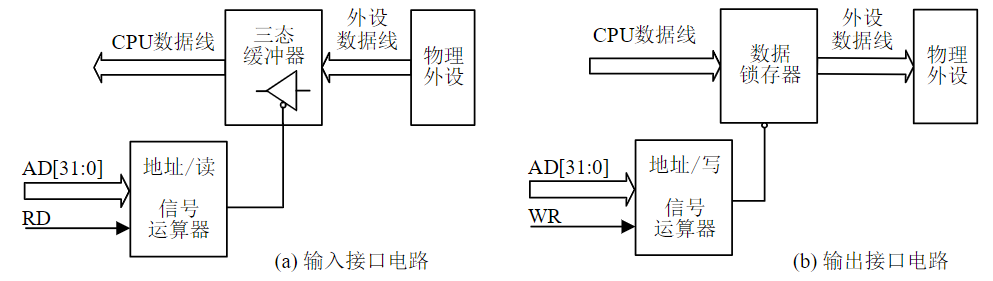
三态缓冲器:
三态输出受使能输出端的控制,当使能输出有效时,器件实现正常逻辑状态输出;当使能输入无效时,输出处于高阻状态,相当于与所连电路断开
作用:
- 外设数据保持时间相对于CPU的处理时间要长的多
- 输入数据不能影响系统总线的正常使用
输出使用一个锁存器
- CPU速度很快,而物理外设的速度比较慢,需要电路输出端保持数据
4.4.2.2. 查询传送方式
也称为异步查询传送方式
有一些外设,处理器访问时需要关心外设的状态,只有状态许可方可访问外设:
- 如,对A/D转换器的访问,只有模/数转换结束后,CPU才能读取转换的结果。又如,在使用串口外设进行数据通信时,只有串口发送缓冲区有空位置了,CPU才可以写入数据;同理,CPU接收数据的时候,也需要在接收缓冲区不空(有接收数据)时进行读取
- CPU对此类外设进行输入或输出操作时需要考虑外设的状态,故此类外设的访问方式也称为条件传送方式
- 大多数外设都是条件访问方式
特点:
输出:CPU对外设查询“BUSY?”,不忙才输出,否则继续查询
输入:CPU对外设查询“READY?”,准备好才读入,否则继续查询
接口特点:
- 优点:避免了对端口的“盲读”、“盲写”,数据传送的可靠性高,并且硬件接口相对简单
- 缺点:CPU工作效率低,I/O响应速度慢
对外设的要求:提供状态口和数据口
在有多个外设的系统中,CPU的查询顺序由外设的优先级确定
查询流程
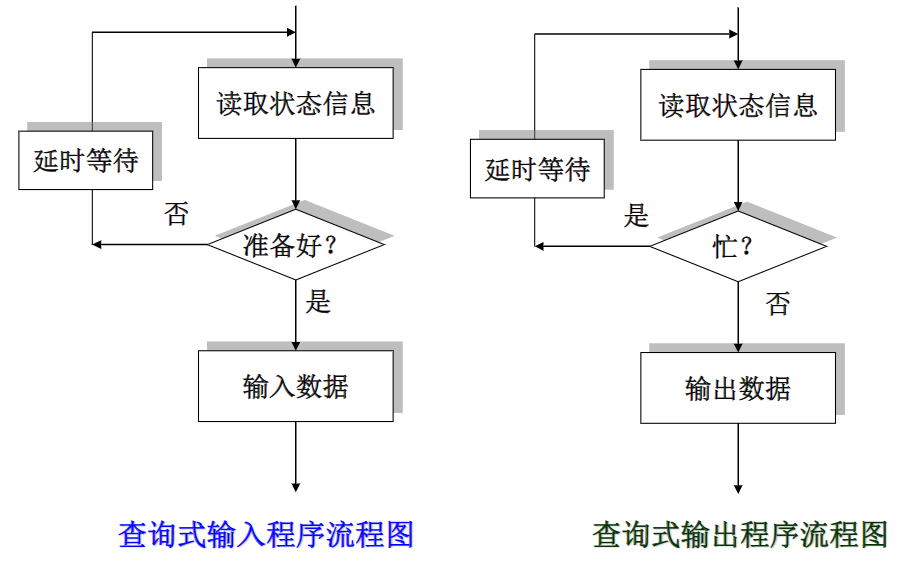
I/O接口电路
为了实现状态的查询,接口电路中既要有数据端口,又要有状态端口
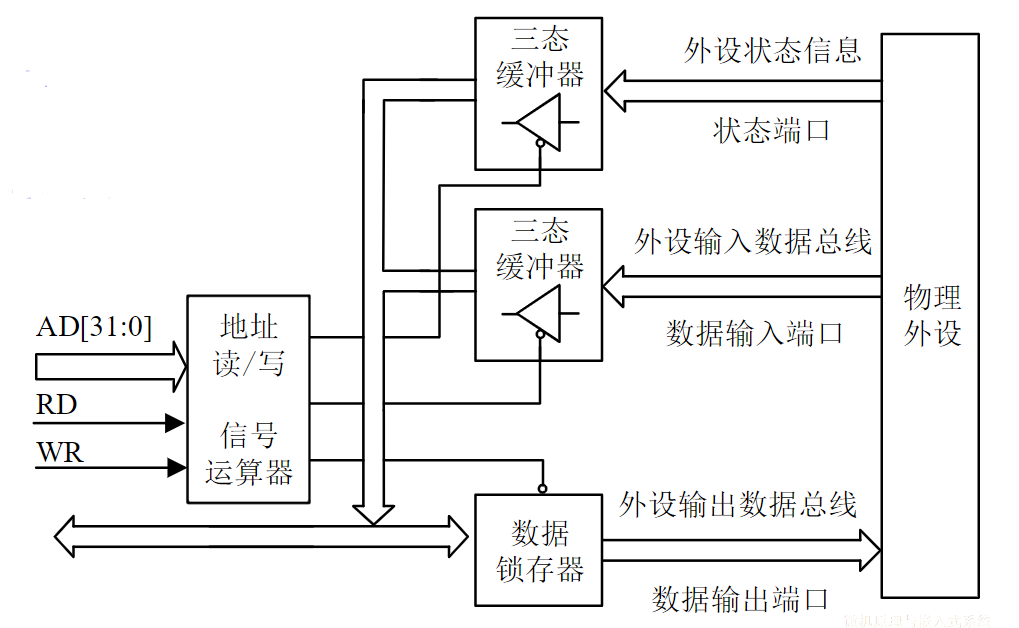
4.4.2.3. 中断传送方式
特点
优点:
- 提高了CPU的工作效率
- 外围设备具有申请服务的主动权
- CPU可以和外设并行工作
- 可适应实时系统对I/O处理的要求
采用中断方式后,仅在需要进行I/O传送时外设才向CPU发中断请求
CPU在中断服务程序中完成CPU和外设之间的数据交换
I/O接口电路
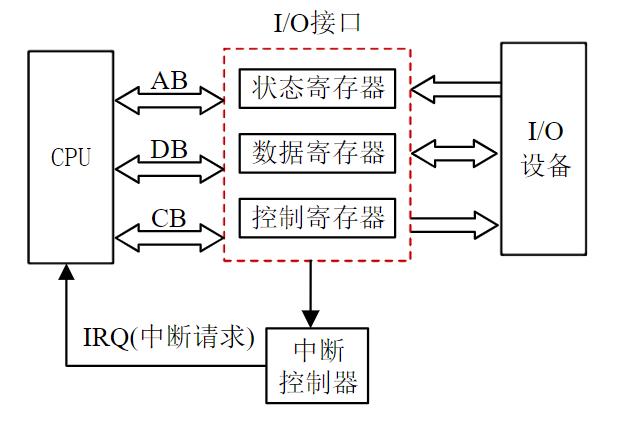
- 外部设备需要传输数据时,外设触发中断控制器的中断请求信号并由中断控制器把该信号送给CPU,CPU收到中断请求信号后,暂停当前程序的运行,而转去执行读/写接口数据的中断服务程序,实现CPU与外设的数据传输
- 在程序查询方式中,由于CPU对外部设备会执行大量状态查询的指令,CPU的利用率不高。如果CPU采取不断查询的方法,则长期处于“等待”状态,不能进行别的处理,也不能对其他事件做出响应。在程序中断传输方式下,I/O端口状态查询工作交给中断控制器去完成。由中断控制器接收申请,并负责优先级排队、嵌套(抢占)管理和中断屏蔽设置等事务
中断的概念
定义
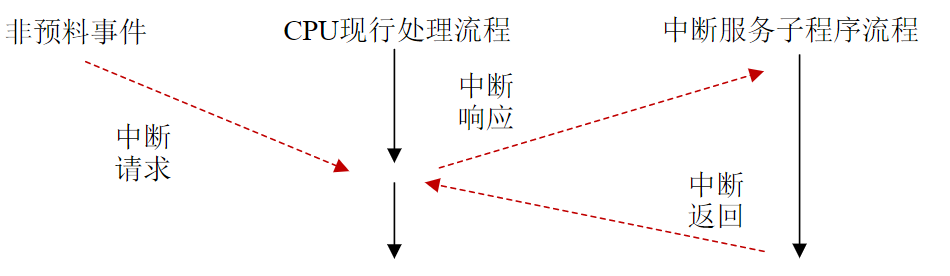
- 中断:由于某些事件计算机中止当前程序的运行,转去执行中断服务程序,中断服务程序完毕后,又返回继续运行正常程序
- 中断源:引起中断的原因
中断源
为了区分源自CPU的内、外的中断源,早期的资料中习惯上把来自CPU外部的外中断称作中断(Interrupt),而把来自CPU内部的内中断称作陷阱(Trap)
如今的微处理器芯片则习惯用异常处理(Exception Handling)机制来描述过去CPU设计中的中断技术
- ARM的Cortex-m3/m4的嵌套中断控制器(NVIC,Nested Vectored Interrupt Controller)处理芯片内所有的异常(Exception)
- Cortex-m3/m4定义的异常包括不可屏蔽中断(NMI)、硬件错误(HardFault)内存管理错误(MemMange Fault)、总线错误(Bus Fault)、使用错误(Usage Fault)、系统定时器(SysTick)等,另外还有多达240个外部中断
- Intel 8259A是著名的可编程中断控制器,一片可以管理的外部中断数为8个
典型计算机系统中的中断源
通常计算机系统的中断处理模块可以管理多个中断源并处理多种不同类型的中断。为了能够识别不同的中断源,会对中断源进行命名或编号,这个编号被称为中断类型码或中断类型号
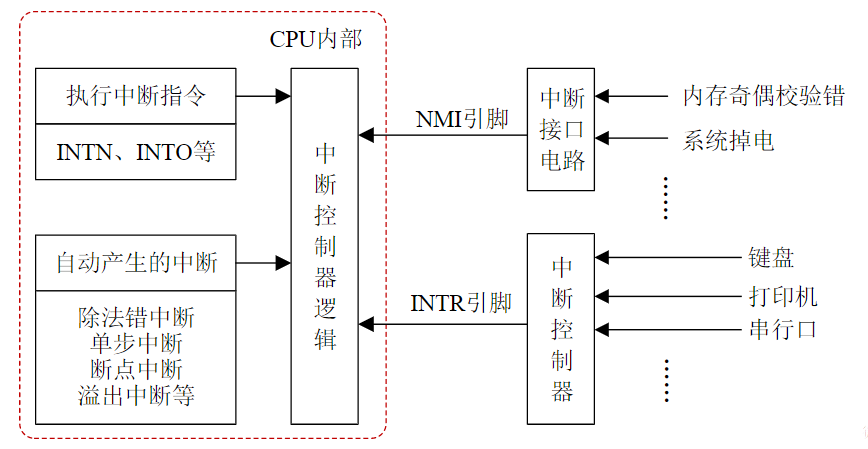
中断向量
- 中断向量即中断服务子程序的入口地址(或首地址)。即中断服务子程序的第一条指令在存储器中的存放地址。一般来说,每个中断源都有自身的中断名或中断向量,有自身对应的中断服务子程序
- 通常的处理器设计中,所有的中断服务子程序入口地址会集中存放在存储器的特定区域(如8086系统中是内存的最低1KB),特定的中断类型码对应这个区域中特定位置的中断矢量。这个特定的区域称为中断向量表(IVT,Interrupt Vector Table),通过中断向量表将中断类型码和中断向量关联起来
- 当中断发生的时候,系统根据中断类型码到中断向量表中获得中断向量的过程也被称做中断索引
断点和现场
断点:指被中断的主程序下一条待执行指令在存储器中的地址,也就是中断返回时的程序地址
- 为保证在终端服务子程序执行完之后能正确返回到原来的程序,中断系统必须能在中断发生时自动保存断点,并在中断返回时自动恢复断点
现场:指中断发生时原主程序的运行状态,一般指系统标志(状态)寄存器和其他相关寄存器中的内容
- 为了保证在中断返回后能继续正确地执行原来的程序,中断系统必须在中断发生时对现场进行保护,并在中断返回时恢复现场
中断处理过程
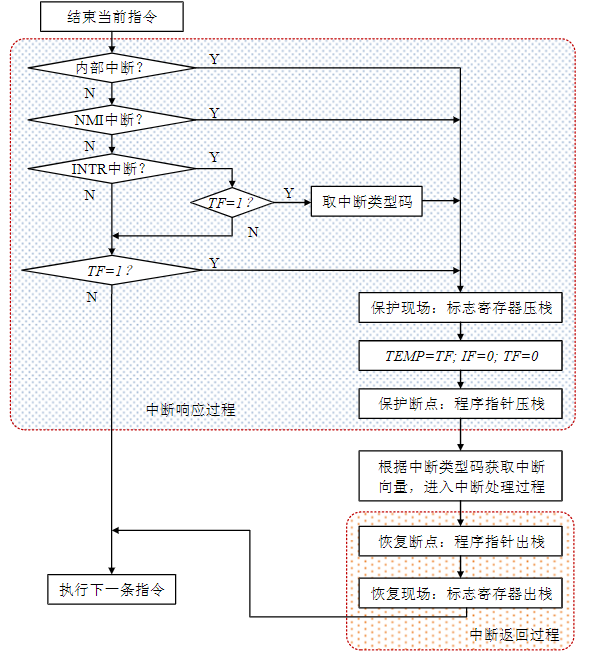
计算机系统中,中断的整个过程分为:中断响应、中断处理和中断返回等三个阶段
上图位8086 CPU的中断处理过程
- TF(Trap Flag),陷阱标志位
- IF(Interrupt Flag),允许标志位
- CPU内部标志寄存器中的两个控制标志位
- TF=1,表示单步中断(陷阱)
- IF=1,表示允许外部中断
注意:
- 保护断点是由CPU自动完成
- 保护现场是由中断服务程序完成,但是现代CPU也能自动保护部分寄存器
优先级、嵌套
中断优先级
- 中断请求有优先顺序之分。若同时出现多个中断请求,CPU按照事先规定的策略,响应优先级最高的中断请求
- 对外设优先级的判断一般可以采用软件查询、硬件排序或采用专用芯片管理等方法来实现
中断嵌套
- CPU正在执行中断服务程序时又有优先级更高的中断请求到达时,如果此时CPU允许中断,则CPU暂停当前中断服务程序,进入更高级的中断服务程序
中断屏蔽
CPU通过硬件电路和软件设置,对中断源产生的中断请求能否到达CPU的硬件引脚进行控制
- 系统设置+优先级
- 可屏蔽中断INTR(Non Maskable Interrupt)和不可屏蔽中断NMI(Interrupt Require)
- 不可屏蔽中断源一旦提出请求,CPU必须无条件响应,而对可屏蔽中断源的请求,CPU可以响应,也可不响应
中断优先级管理
软件管理(软件查询)
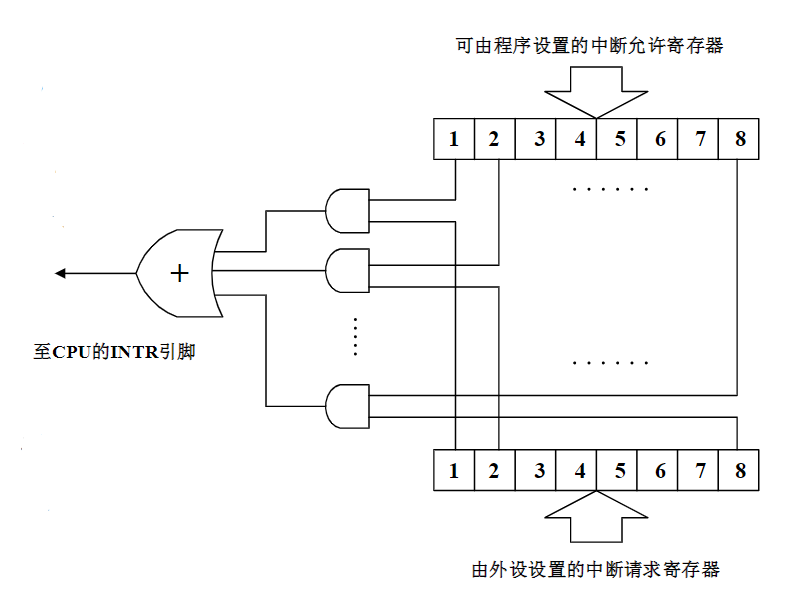
- 软件管理也需要使用少量硬件电路,当系统中有多种外部设备,将这些设备的中断请求信号相“或”,从而产生一个总的中断请求信号INTR发给CPU
- CPU读取中断请求寄存器后可获知有哪些中断,之后程序员所选择的处理顺序就体现了优先权
中断优先权编码电路(硬件排序)
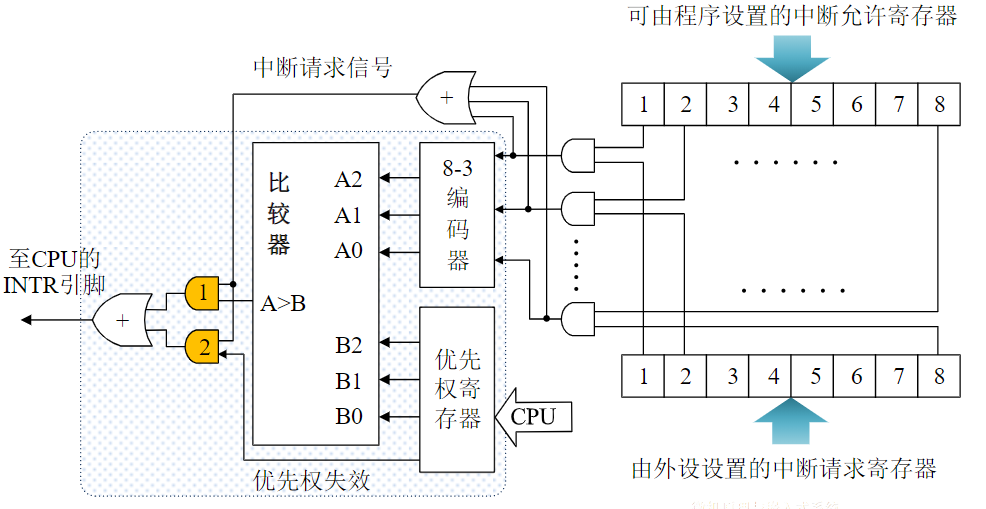
任一外设对应的中断请求位和中断允许位同时为“1”时,即可产生中断请求信号
在两种情况下该中断请求信号能传送至INTR引脚:
- 比较器输出为“1”时,中断请求信号可通过与门1送出
- “优先权失效”信号为“1”时,中断请求信号可通过与门2送出
编码器每位输入线的有效电平都对应一个编码,在多位输入线有效时编码器只输出优先权最高的编码
优先权寄存器中记录的是CPU当前正在处理的中断的编码
若A>B,比较器输出“1”,可以产生中断嵌套
“优先权失效”信号用于一种名为特殊屏蔽中断方式,该方式所有中断源没有优先级之分
菊花链式优先权排队电路(硬件排序)
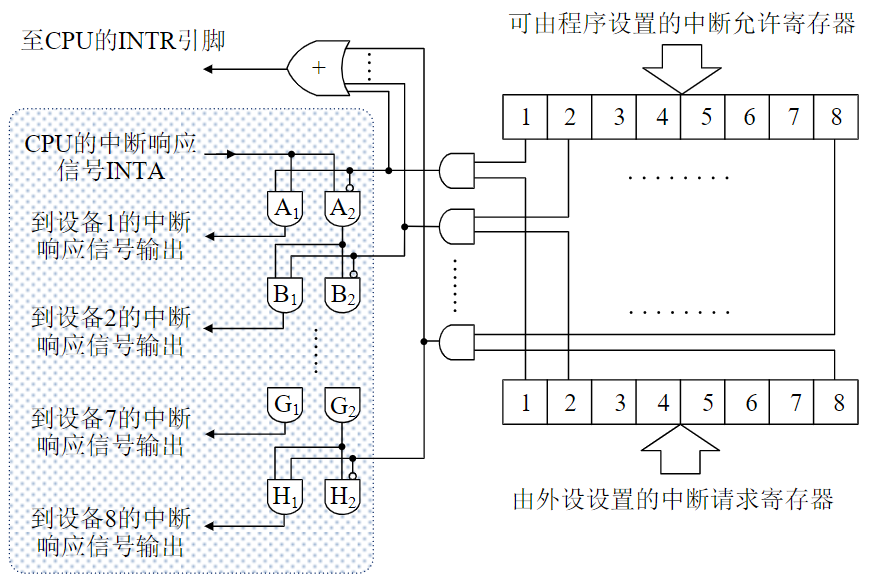
每个中断源接口电路中设置一个逻辑电路,组成一个daisy chain,菊花链
CPU送出中断响应信号后,若设备1无中断请求,则与门A1关门,A2开门,中断响应信号继续向下一级传送
若设备2有中断请求,则与门B1开门,中断响应信号送至设备2,同时B2关门,中断响应信号不再向下传送
设备接入菊花链的顺序就确定了设备的中断优先级别
对链的长度有限制
中断控制方式的接口电路(以输入为例)
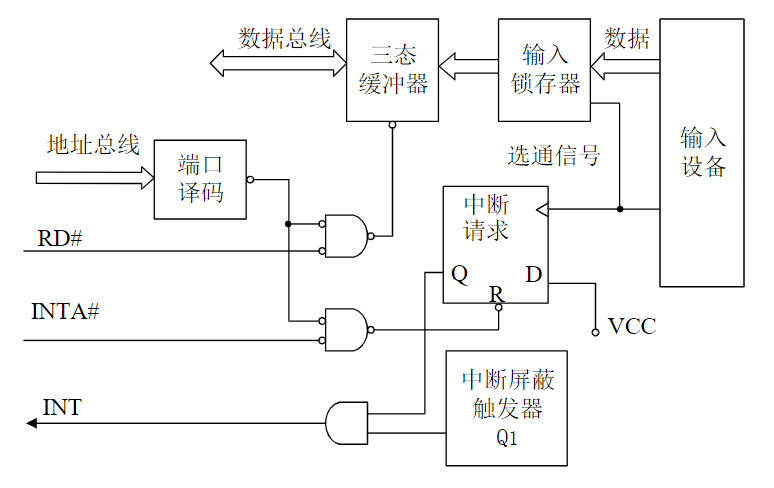
当外设准备好输入数据后发出选通信号,数据进入锁存器中,并同时将中断请求触发器置“1”。如果中断屏蔽触发器允许中断(Q1输出为“1”),与门被打开,因而可以产生中断请求信号INT
INTA#为中断响应信号,INTA#到达后将撤销INT请求
4.4.2.4. 直接存储器访问(DMA)方式
问题的提出
- 采用程序控制方式进行数据传送时,都是靠CPU执行指令实现数据的输入/输出。CPU先从“源”将数据读入到内部寄存器,再将内部寄存器的数据写到“目的”,因此存储器与I/O接口之间进行数据传送至少需要两个完整的总线周期
- 中断方式虽能较好地利用CPU资源,但是每次进入中断和退出中断的现场保护与恢复需较多的时间开销
- 对于高速外设(如磁盘或高速数据采集系统等),程序控制方式传送无法满足数据传输率的要求
基本思路
- DMA方式也要利用系统总线,平时总线由CPU管理,当外设需用DMA方式传送数据时,可请求CPU让出总线控制权,用专用硬件接口电路临时接管总线,在I/O接口与存储器之间直接进行数据传送
- 该电路在一个总线周期内能够同时发出内存单元和I/O端口的选择信号以及“源”的读信号和“目的”的写信号,直接将“源”输出的数据写到“目的”中
- 以上方式称为直接存储器存取(Direct Memory Access),简称DMA方式。完成这一任务的硬件控制电路称为DMA控制器,简称DMAC
DMA传送形式
DMA又分为DMA写(I/O接口 → 内存)和DMA读(内存 → I/O接口)。下图是几种DMA传送形式的示意:
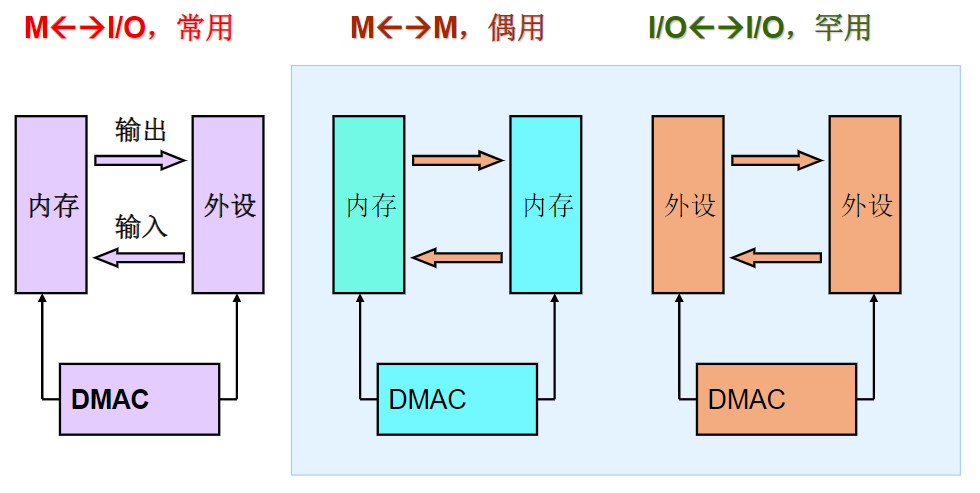
基本步骤
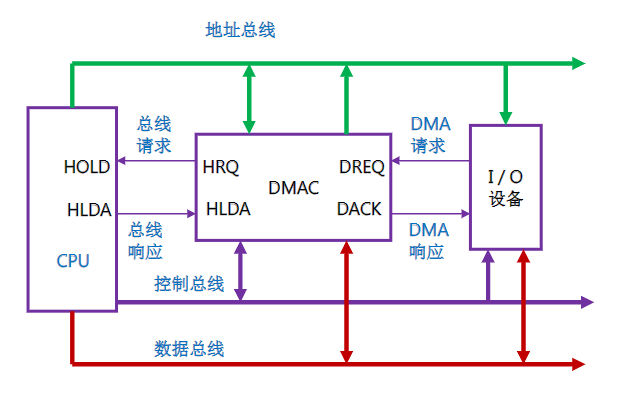
- 需要DMA传送的外设发DMA请求DREQ(DMA Request)到DMAC
- 若运行,DMAC向CPU或总线仲裁机构发出总线请求HRQ(Hold Request)
- CPU或总线仲裁器若同意总线使用权转移,发总线响应信号HLDA(Hold Acknowledge),并完成总线切换
- DMAC接管总线,发DACK通知(也是选定)外设,即将DMA传送的外设
- DMAC发内存单元地址信号,若是DMA写,再发I/O读和存储器写信号;若是DMA读,发存储器读信号和I/O写信号
- DMA结束后,DMAC撤消HRQ,CPU或者总线仲裁器撤消HLDA,CPU重新接管总线
基本工作方式
单次传输方式
假设从Memory → 外设
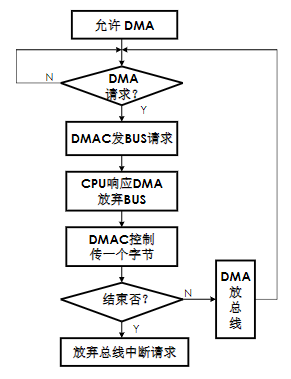
DMA控制器每次请求总线只传送一次数据,每次传送的数据大小取决于总线宽度
传送完后即释放总线控制权,如果还有数据需要传送,继续申请
块传输方式
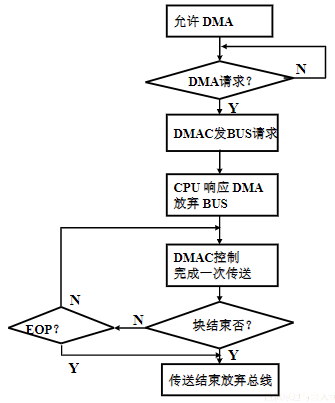
- DMAC获得总线使用权之后,“一口气”把整个数据块全部传送完成后再释放总线控制权
- 特点:获得总线使用权后,DMAC控制总线连续传送,直到传送任务全部完成
- 如果在传送期间遇到了外部输入的EOP(End of Process)信号,传送任务将被强行终止
请求传输
此方式与块传输方式基本类似,不同的是每传输一次,DMA控制器都要检测DREQ信号是否仍然有效,如果该信号仍有效,则继续进行DMA传输;否则,就暂停传输,交还总线控制权给CPU,直至DMA请求信号再次变为有效,数据块传输则从刚才暂停的那一点继续(称为“断点续传”)
随机请求:
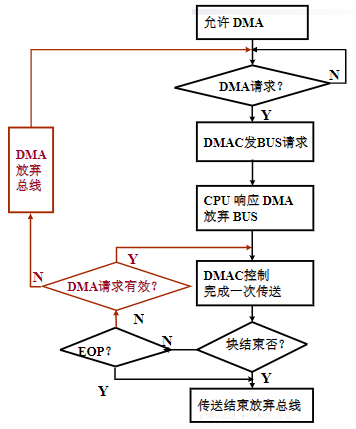
与成组传送区别:在传送期间,若DMA请求信号无效,DMAC暂停传送并放弃总线。当DMA请求信号重新有效,DMAC再次申请总线使用权,获准之后从断点处续传
在询问方式中,DMA请求信号的作用类似于“PAUSE”
DMA传送方式的特点
依靠硬件实现数据传送
- 不运行程序,不能处理较复杂的事件。故DMA方式并不能完全取代中断方式,当某事件处理不只是单纯的数据传送时,还是需要采用中断方式。事实上,在以DMA方式传送完一批数据后,常利用中断通知通知CPU结束处理
DMAC本身也是接口芯片
- 在使用之前需要进行初始化配置
- DMAC有个缺陷,无法对接口进行寻址,当多个外设需要采用DMA传送方式时,DMAC一般会设置多个通道,为多个外设提供DMA传送服务。每个通道都有自己的一套寄存器和DMA请求响应信号线。多个通道还需要通过优先级电路加以排队,决定先响应哪个通道的DMA请求
4.4.3. 并行接口
串行与并行
串行传输
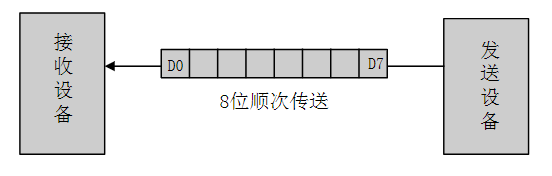
- 将需传输的比特串排成一行,一个接一个地在一条信道上传输
- 串行总线只用一根信号线(如果传输的是差分信号则是两根信号线)来传输数据
- 只需要少数几条线就可以在系统间交换信息,特别适用于计算机与计算机、计算机与外设之间的远距离通信
并行传输
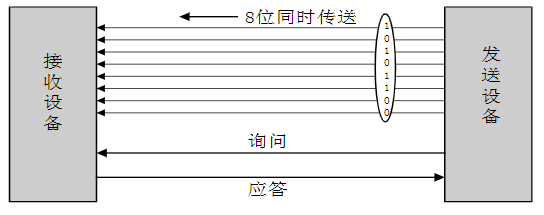
- 将数据以成组的方式在两条或更多的并列信道上进行传输
- 一组数据的各数据位在多条线上同时传输
- 并行通信时数据的各个比特位同时传送,可以字或字节为单位并行进行。并行通信速度快,但用到的信号线多、成本高,故不宜进行远距离通信
4.4.3.1. 无握手信号的并行接口
无握手信号的并行接口典型电路
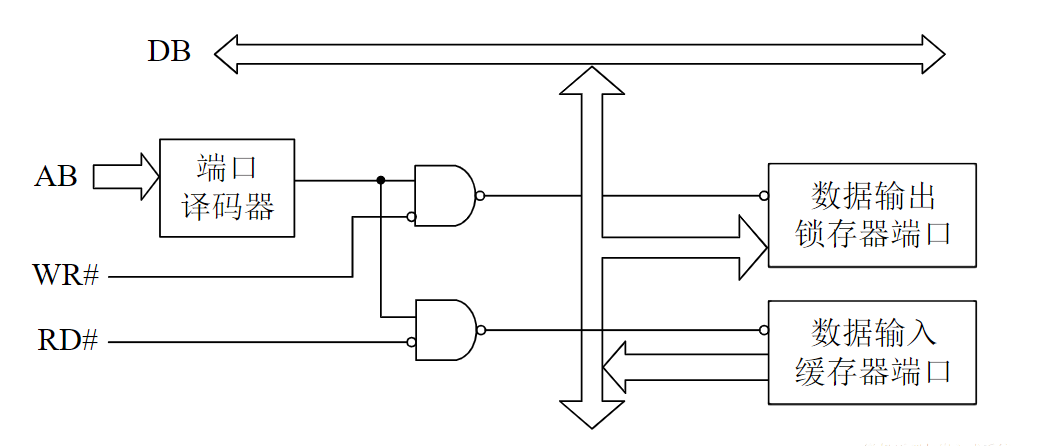
采用无握手信号接口连接的外设一般是功能简单的电路模块,如按键,数码显示管等。CPU与这些无握手信号的外设接口传输数据时,总是假定外设总是处于准备好的状态
输入接口示例:线性键盘
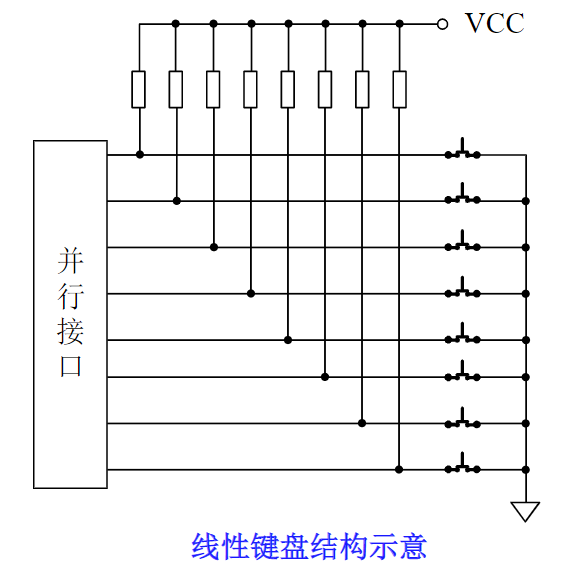
键盘分类:按压式、常开式、开关阵列
按压式开关存在的问题:抖动、串键(2个或2个以上的键被同时按下,又称重键)
依据按键状态获取方式的不同,可以将键盘分为线性键盘和矩阵键盘,矩阵键盘又可分为非编码键盘和编码键盘
线性键盘:每一个案件需要占用I/O端口的一根口线
矩阵键盘:可分为非编码键盘和编码键盘
- 编码键盘——能够自动提供被按下键的编码信息,同时产生选通脉冲,具有抖动处理和重键保护功能,但是键数较少
- 非编码键盘——由一组开关组成,通常按照行列排列所以又称为矩阵键盘。需要通过接口电路和软件实现键码识别(确定被按下键的行列位置),并解决防抖和串键的问题
输入接口示例:矩阵键盘
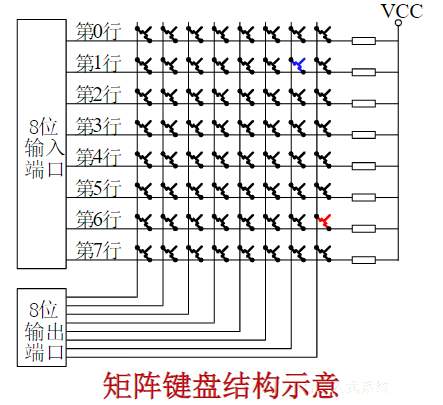
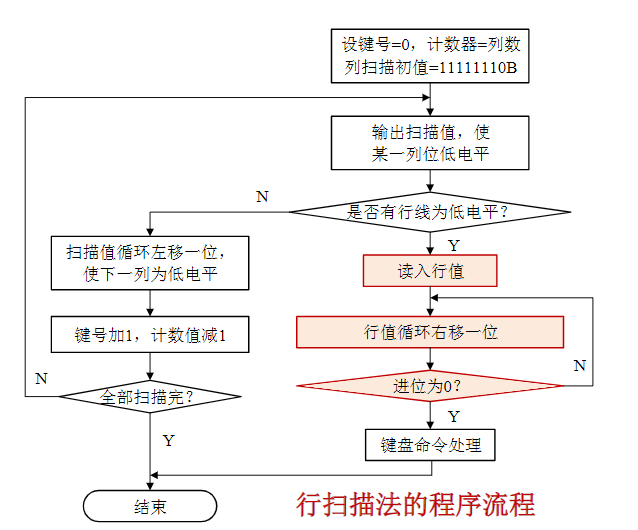
- 思路:首先输出0x00,读入如果为0xFF则无按键按下;再逐列检查是否有键按下,发现某列有键按下后再确定行
输出接口示例:LED显示
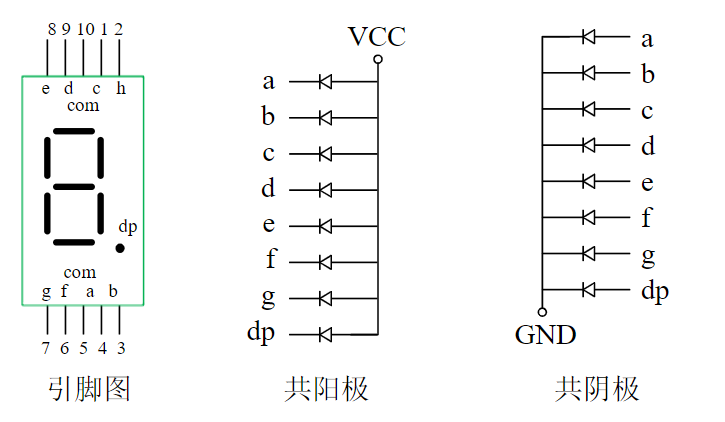
码显示管是一种半导体发光器件,简称数码管,分为点阵式和段式。常见的段式有7段或8段(多一个小数点)
按照连接方式分为共阳极和共阴极两种结构
按照显示特性又分为静态显示和动态显示
静态显示方式
- 每个数码管相应的段(发光二极管)恒定地导通或截止,直到下一次更换信息
- 若需要显示N个数字,那么数码管个数为N时,需要的接口口线数目为8×N
动态显示方式
- 各个数码管轮流显示,每位数码管的点亮时间约1~2ms,由于人的视觉暂留现象及发光二极管的余辉效应,尽管各个数码管并非同时点亮,但给人的印象是所有数码管同时显示
- 在动态显示方式下,各个数码管的对应段输入控制端并连在一起,因此无论数码管的个数是多少,需要的口线数目都只需要8条,该端口称为段选口。各个数码管的公共端分别连接一根口线,该口线称为位选口。当数码管的个数为N时,则需要的位选口口线数目为N,因此动态显示方式总共需要的口线数为8+N
输出接口示例:数码管的显示接口电路
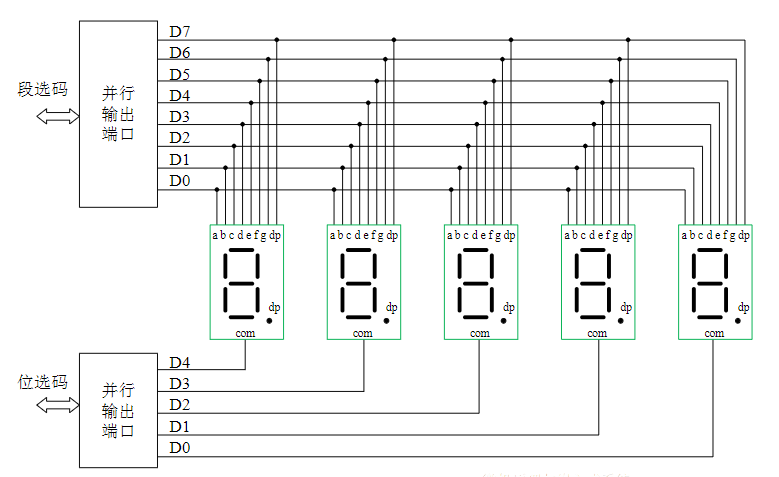
- 图为显示5位十进制数的共阴极LED数码管接口电路。8位段选码由一个I/O端口控制,在每次输出段码之后,5个数码管同时获得了该段码值。要在每个数码管显示不同的字符,就必须采用扫描方法,轮流点亮各个LED数码管
- 扫描即控制位选码
- 显示第一个十进制数字时,段选控制端口输出相应字符的显示码;位选码中对应第一个数码管的位为“0”(低电平,因数码管为共阴极结构),而其他位为“1”(高电平)
- 显示第二个数字时,第二个数码管的位选码为“0”,其他位都为“1”
4.4.3.2. 带握手信号的并行接口
带握手信号的输入接口电路
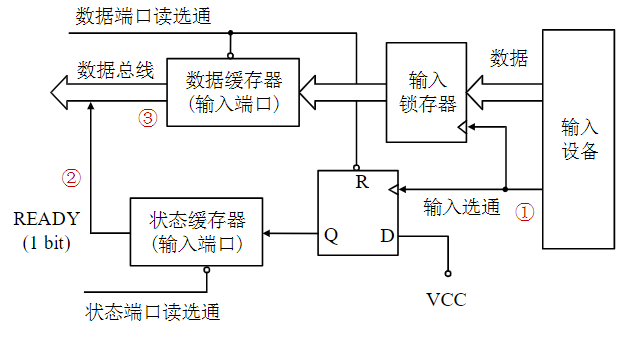
- 输入设备发出选通信号,将准备好的数据送到接口电路的数据锁存器中,同时使D触发器置“1”并将该信号送到状态缓存寄存器中待CPU查询
- CPU读取接口中的状态寄存器,检查状态信息。READY为“1”,说明数据已到数据缓冲寄存器
- CPU读数据端口,同时数据端口的读信号将D触发器清零,令READY为“0”,完成本次传送
带握手信号的输出接口电路
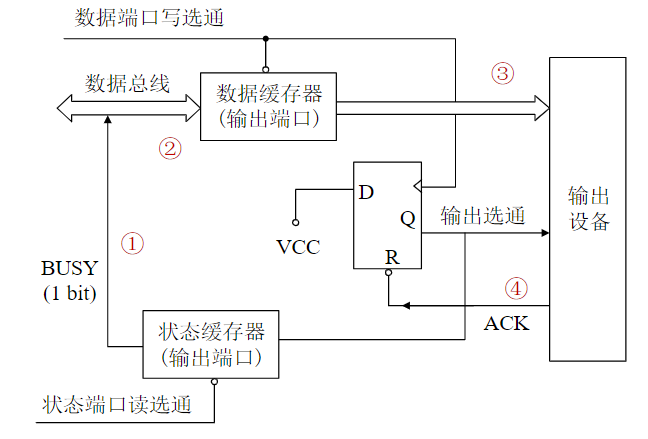
- CPU读状态口,若BUSY为“0”,说明数据缓存器空,外设可以接收数据
- CPU向数据端口写入需发送的数据,同时将接口中的D触发器置“1”,该信号作为状态信号BUSY,一方面通知输出设备:“输出缓冲器满”,外设可以取数据;另外一方面作为状态信号,让CPU了解数据输出的动态
- 输出设备发响应信号ACK,一方面从接口的数据锁存器中读出数据;另外一方面将接口中的D触发器清零,再次使BUSY=“0”,完成本次数据传送
4.4.3.3. 可编程并行接口(GPIO)
GPIO模块电路
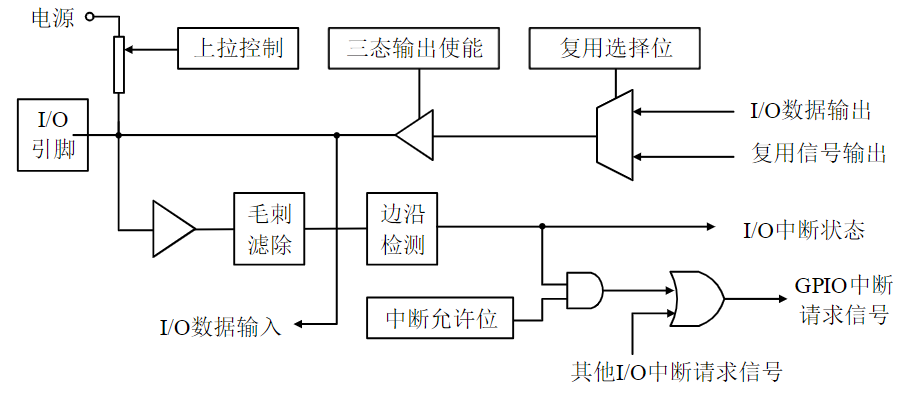
可编程通用并行接口是计算机及其他数字电路系统中最常使用的一种简单外部设备接口电路。其结构简单、应用途广泛,且可以通过编程控制字来实现控制,故得名“通用可编程I/O接口”,即GPIO(General-Purpose IO ports)
可编程并行接口芯片:Intel 8255A
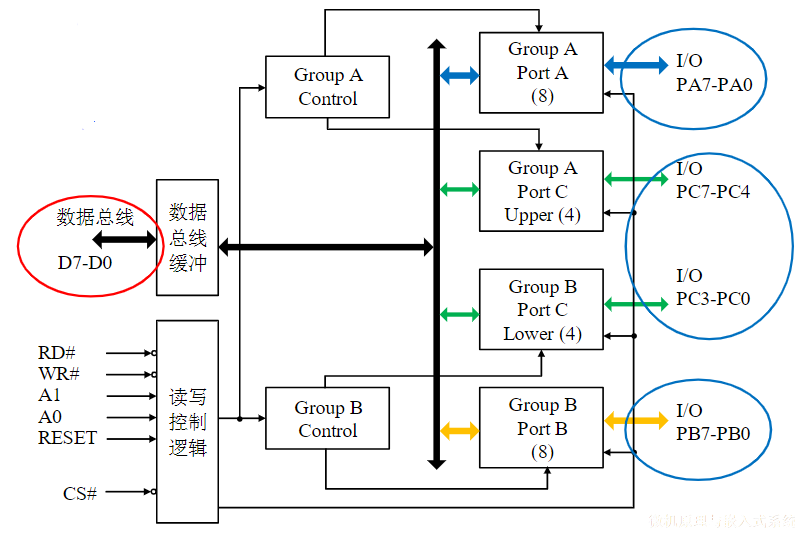
早期的计算机使用单独的可编程芯片来控制I/O,如英特尔的8255芯片有3个8位并行I/O口,具有3个通道、3种工作方式:
- 工作方式0:基本输入/输出方式
- 工作方式1:选通输入/输出方式
- 工作方式2:带选通的双向传送方式
典型嵌入式控制器的I/O端口位接口
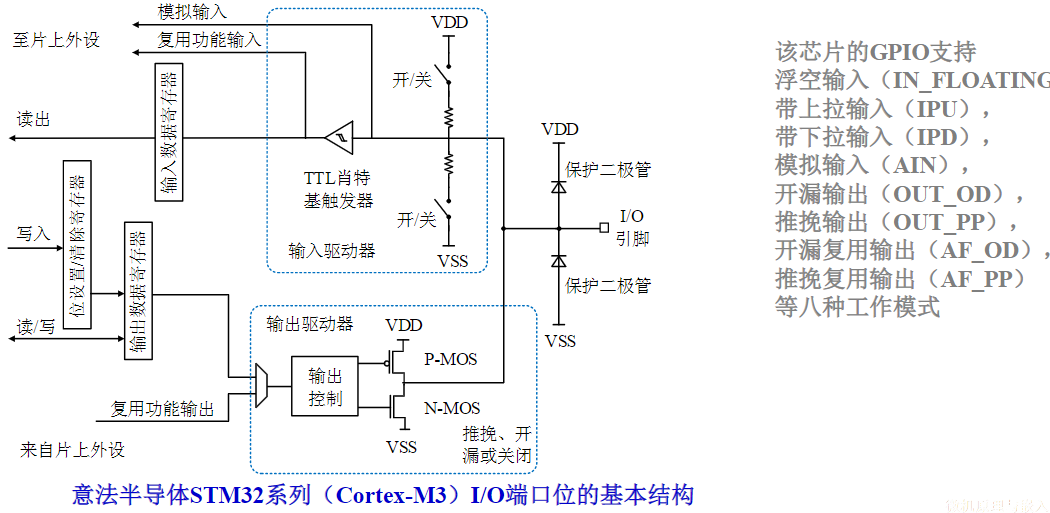
微控制器芯片(单片机)往往会集成GPIO接口。一般来说,GPIO接口至少有两个寄存器,即“通用I/O控制寄存器”与“通用I/O数据寄存器”
4.4.4. 串行接口
4.4.4.1. 串行接口概述
概述
串行通信——数据在单条一位宽的传输信道上按时间先后一位一位地进行传送。与并行通信相比,串行通信具有以下特点:
优点:
- 不仅传输距离远,而且串行数据传送速率比并行数据传送速率更快,因为串行通信的通信时钟频率比并行通信更容易提高
- 抗干扰能力强,通信费用低
- 传输线既传数据,又传联络信息
缺点:需要串/并转换,对数据格式有要求
通过Modem实现远程数据通信
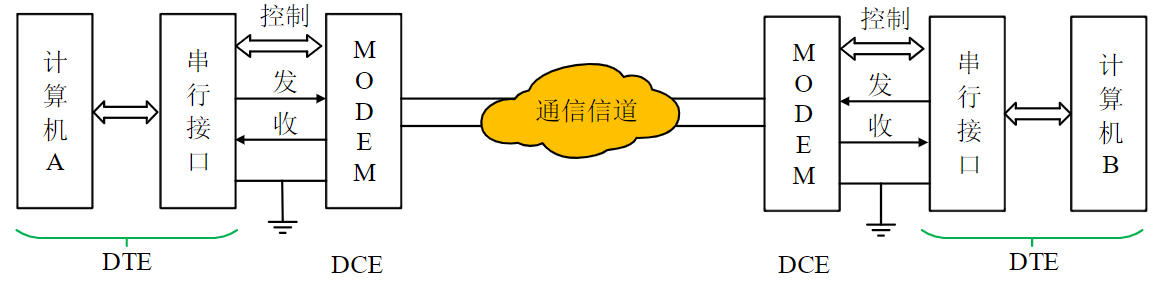
串行通信常用于需要远距离传输的情形,然而受限于传输线的特性,数字信号无法在传输线上直接进行远距离传输。一般发送方需要使用调制器(Modulator),把要传送的数字信号调制为适合在线路上传输的信号;接收方则使用解调器(Demodulator),将从线路上接收到的调制信号进行解调,还原成数字信号。调制器和解调器两者通常集成在一起作为一个设备,称为调制解调器(Modem)
调制解调器被称为DCE(Data Communication Equipment,数据通信设备)数据终端被称为DTE(Data Terminal Equipment,数据终端设备)
串行通信的性能参数
衡量数据传输速率有两个单位:
- 比特率:单位时间内传送的二进制码元的个数,单位是bps ( bit per second )。由于1个二进制码元代表了1 bit的信息,因此比特率也称为传信率
- 波特率:单位时间内传输的符号个数,单位是波特(Baud或Bd)
计算机普遍采用二进制,一个“符号”仅有高、低两种电平,分别代表逻辑值“1”和“0”,所以每个符号的信息量为1比特,此时波特率等于比特率。但在其它一些应用场合,一个“符号”的信息含量可能超过一个比特,此时波特率小于比特率
串行通信的同步方式
同步技术——能够检测和识别所传送的数据单元(位、字符或字节、帧、数据块等)的起止的技术
根据同步方式,串行通信又分为:
同步通信方式
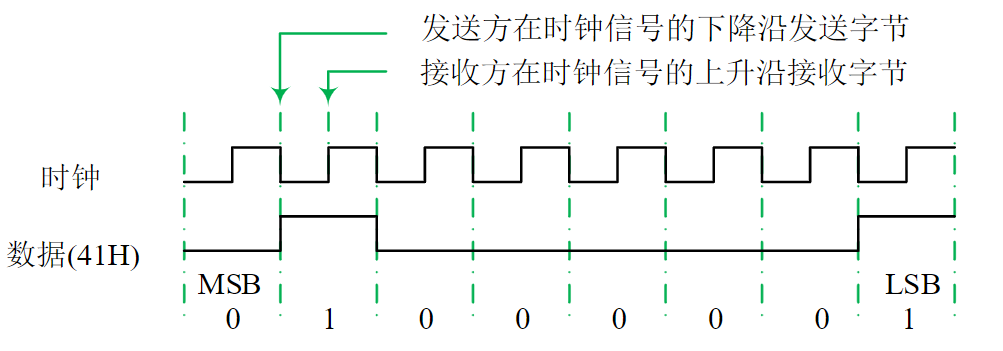
- 收发双方在时钟同步的基础上,通过位同步以及帧同步等措施,保证可正确接收和识别所传送的数据
- 同步串行接口传输信息时,发送方和接收方电路在同一个时钟下工作,所传输信息的字节与字节之间、位与位之间均与时钟有严格的时间关系
- 图中包含了八个数据位。很多同步协议首先发送MSB(Most Significant Bit),而很多异步协议首先发送LSB(Least Significant Bit)
异步通信方式

- 收发双方通过信号波形编码表示所传输数据单元的起止。收发双方的时钟相位互不相关,甚至允许频率存在误差
- 收发双方使用异步串行接口传输数据时,只使用数据线,而不像同步串行接口那样还需要时钟信号。异步串行接口常用于计算机系统之间的远程数据传输,可以实现远程通信
- 图示为异步传输协议下发送串行数据的示意,中包含了七个数据位、一个起始位和一个停止位
4.4.4.2. 异步串行接口
概述
如果采用相同的接口时钟频率,串行数据传输的速度要比并行传输慢得多,但对于覆盖面极其广阔的公用电话系统来说具有更大的现实意义
另外,并行接口时钟频率提升会遇到瓶颈,近年来出现了很多高速的串行接口标准
“异步串行接口”包括了两方面的内容:
- 串行通信双方进行数据传输时的接口电路
- 收发双方约定的通信协议
异步串行数据帧格式

拟传输的数据以字符(一个字符通常含五至八位)为单位进行传送。考虑到传送发生的相对时间是随机的,为了确保整个通信过程的正确性,需要找一种合适的方法,使发送方和接收方在所传送的字符与字符间实现同步。常用的方法:在字符数据格式中设置起始位和停止位
如图。每个字符传输包括:一个起始位(低电平,逻辑“0”)、五至八位有效数据位、一位奇偶校验位、一位(或1.5位,或2位)停止位,停止位(高电平)之后是不定长度的空闲位(高电平)
异步传输信号波形的检测
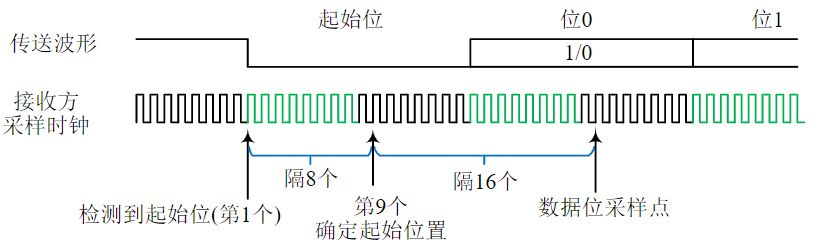
问题:难以保证收发双方时钟的频率完全相等、相位严格对齐 → 检测困难
解决办法:设约定的波特率为,接收方用频率为的时钟对接收信号进行检测,,称为波特率因子,。有些芯片可编程设置,有些固定,如
设,接收端检测到一个低电平时,须证实是否的确是起始位。不同的芯片可能采用不同的方法,如:隔八个再检测一次,若仍为低电平则确认是起始位。或连续检测八个,若有五次以上是低电平则确认是起始位而不是干扰
确认了起始位后,从第九个检测脉冲(起始位中间位置)开始,接收端每隔16个脉冲采样一次输入信号,顺序接收各个数据位
异步串行接口电路
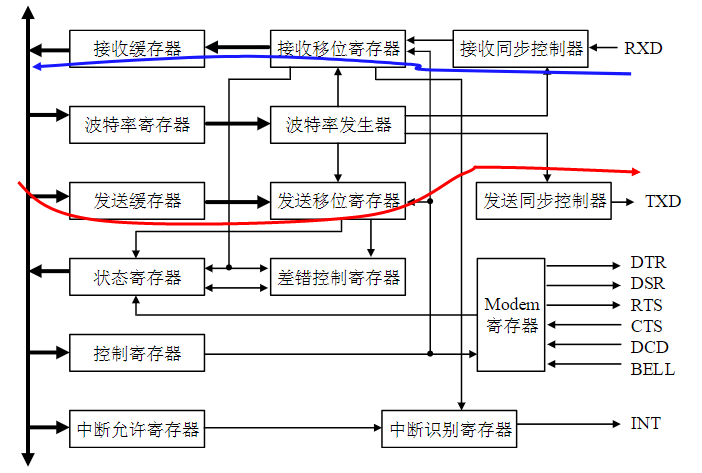
异步串行接口电路需要完成的基本功能包括:
- 数据的串/并、并/串转换
- 串行数据的格式化(如自动加入起始位、校验位或同步字符等)
- 校验码的生成
- 现接口间控制信号的解析
- 调制与解调
发送过程:从数据总线上接收来自CPU的并行数据 → 基于移位寄存器进行并/串转换 → 入起始位、停止位等 → 按特定波特率由TXD发送
接收过程:RXD输入的数据 → 在本地时钟和波特率发生器的控制下,经同步控制器送给移位寄存器 → 串/并转换后进入接收缓存器 → 同时进行错误检测、帧解析并把相关信息写入状态寄存器 → 通过中断告知CPU接收完毕
异步串行接口信号定义
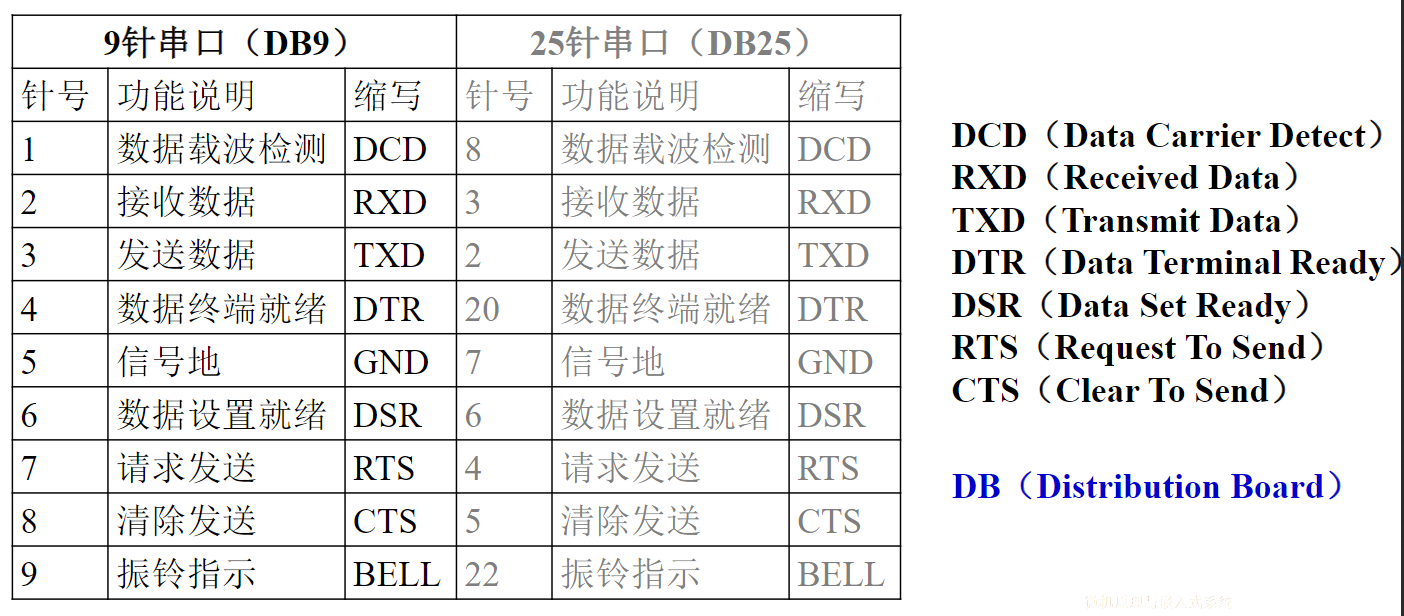
异步串行接口协议
- 接口协议(标准)是通信的收发双方共同遵循的传输数据帧结构、传输速率、检错与纠错、数据控制信息类型等相关约定
- 在任何一个串行通信协议中,都会对接口物理层的机械特性、电气特性、规程特性和功能特性进行规范
- 本节讨论常见的异步串行通信协议,如RS-232、RS-422、RS423和RS-485
最常见的串行通信标准:RS-232C接口
S-232是由EIA(Electronic Industry Association,美国电子工业协会)1970年制定的串行二进制数据交换接口技术标准。先后出现了多个版本,其中应用最广的是修订版C,即RS-232C
RS-232C标准最初是为远程通信连接数据终端设备(DTE)与数据通信设备(DCE)而制定的。虽然该标准并未考虑计算机系统的要求,但后来它被广泛应用于计算机系统
RS-232C定义了DTE与DCE之间的物理接口标准。数据通信设备可以是传真机、电话机、智能终端等
- 物理层中的连接指的是DTE和DCE之间的连接(又称接口)
- 物理层的功能是在两个网络设备之间提供透明的比特流传输
信号线定义——机械特性、功能特性
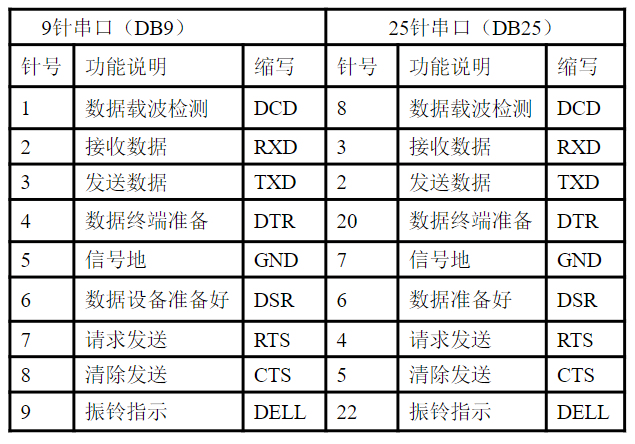

标准串口的设置——规程特性
- 波特率
- 数据位
- 奇偶校验位
- 停止位
- 流控制
电气特性——负载电容与传输距离
- RS-232C传输电缆的长度与负载的电容值有关
- 标准规定被驱动电路(终端)的电容,包括电缆的等效电容必须小于2500pF
- 对于多芯电缆,每英尺(0.305米)电容为40~50pF,所以满足电容特性要求的电缆长度最长为50英尺(约15米)
电气特性——PC与一般单片机的串口逻辑电平
电脑上的RS-232接口采用的是负逻辑电平
- -15V~ -3V表示逻辑1
- +15V~ +3V表示逻辑0
- 电压值通常在7V左右
单片机的串口输出电路采用的逻辑电平是TTL电平。这种电平信号由TTL器件产生的,一般的芯片,如运放,数字器件等...
TTL:三极管结构
- VCC:5V
- VOH>=2.4V;VOL<=0.5V
- VIH>=2V;VIL<=0.8V
RS-422/432标准
- RS-232接口是一种基于单端非对称电路的接口,即一条信号线与一条地线,这种结构容易受到干扰,传输距离受限。为此,EIA又制定了RS-422和RS-423等标准
- RS-422标准采用了平衡差分传输技术,即每路信号都使用一对以地为参考的正负信号线。这种平衡差分结构的抗噪声能力较强,传输速率与距离都明显提高。最高传输速率为10Mbps,最远传输距离为4000英尺(1218米)
- RS422标准有点对点全双工与广播两种通信方式。广播方式下只允许一个发送驱动器工作,而接收器可以多达十个。RS-423则是RS-232与RS422之间的一个过渡标准,因而兼有两者的特点
RS-485标准
- S-485是RS-422标准的改进增强版本,该标准兼容了RS-422,提供了多点通信能力,很好地支持了联网功能,在仪器仪表和工业控制等领域得到了广泛的应用
- 多点通信能力的支持,把RS-232定义的异步串行接口改造为了一种总线。多个主机系统可以同时挂接到线缆上,RS-485实际上提供了“总线仲裁”的能力
- 在RS-485的多点通信系统中,接收器节点数可达32个,后期推出的版本则多达64/128/256个节点
- RS-485标准器件的数据传输速率有32Mbps、20Mhps、12Mbps、10Mbps、2.5Mbps及数百kbps等各种规格
RS232/RS485/RS422对比
4.4.4.3. I2C接口及总线
NXP(Philips) Inter-Integrated Circuit (I2C)

PHILIPS公司开发的两线式串行总线(一条串行数据线SDA,一条串行时钟线SCL),用于连接微控制器及其外围设备
- Synchronous / Master-Slave Protocol / Half Duplex
标准模式下:100Kbps;快速模式下:400Kbps;高速模式下:3.4Mbps
示例:2块芯片通过I2C连接
驱动SDA和SCL线的器件的输出级必须漏极开路(OD门),以实现总线的“线与”功能。使用外部上拉电阻(接电源),以确保当没有器件将线拉低时能保持高电平
I2C接口典型电路
I2C的接口电路一般包括数据寄存器、控制寄存器、状态寄存器、地址寄存器,有些还包括和时钟有关的分频寄存器等
主从式通信方式
- 为便于描述,I2C定义了“主器件”和“从器件”的概念。主器件(主机,或称为主设备)用于启动总线传送数据,并产生时钟,此时任何被寻址的器件均被认为是从器件(从机,或称为从设备)
- 从如果主器件要发送数据给从器件,则主器件首先寻址从器件,然后主动发送数据至从器件,最后由主器件终止数据传送
- 反之,如果主器件要接收从器件的数据,首先由主器件寻址从器件。然后主器件接收从器件发送的数据,最后由主器件终止接收过程
多主机总线
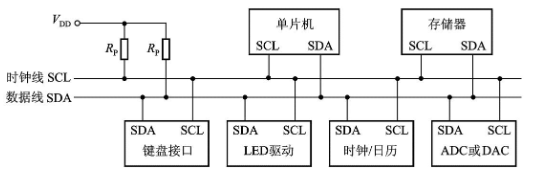
- I2C总线是一个多主机总线,在两根信号线上可同时挂接多个器件(存储器、键盘、LED、ADC等)。任何器件既可以作为主机也可以作为从机,但同一时刻只允许有一个主机
- 多主机总线,需要通过仲裁机制予以协调
- I2C总线对发生在SDA信号线上的总线竞争进行仲裁。原理为:在检测到总线空闲(SCL和SDA均为高电平)后,拟使用总线的主机向SDA信号线发送数据(高电平或低电平),每一位数据发送后随即检测SDA信号线电平是否与自身发送电平一致,若电平不符则竞争失败,自动关闭其输出
I2C的地址

I2C总线采用两线制总线,不具备微机系统所具有的由多位地址线所组成的并行地址总线,通过串行发送地址实现
总线上每一个器件的地址必须是唯一的
I2C标准中有7位地址和10位地址两种
I2C总线协议状态
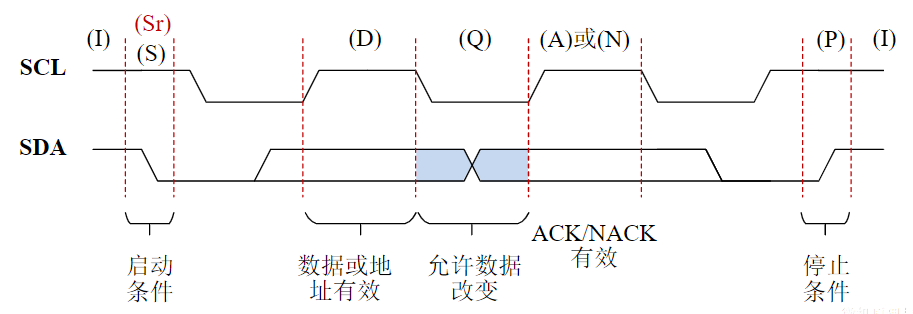
- 启动数据传输(S);停止数据传输(P)
- 重新启动(Sr):重新启动可以让主器件在不失去总线控制的情况下改变总线方向
- 数据有效(D)应答(A)或不应答(N)
- 等待/ 数据无效(Q)总线空闲(I)
I2C数据传输过程
主设备向从设备发送信息
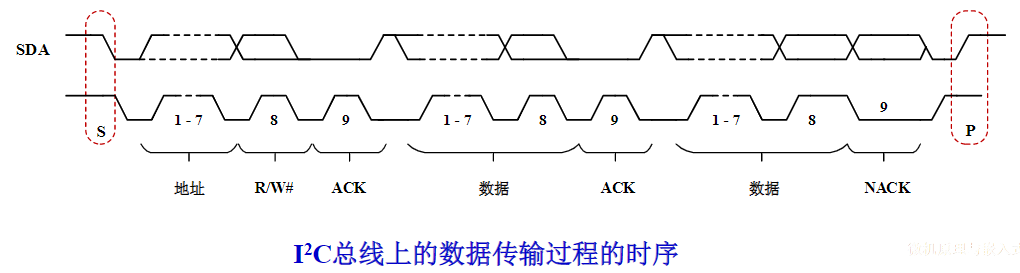
- 主设备发送开始信号(S),对应图中(S)状态
- 主设备发送7比特的从设备地址,对应图中发送地址阶段
- 主设备发送写命令(低电平,W#),对应图中R/W#
- 接着从设备应答(A),ACK为应答成功(A),表示有这个设备
- 主设备发送8位字节数据
- 接着从设备应答,ACK为应答成功(A),或,NACK为不成功为(N)
- 如果从设备应答成功(A)继续主设备发送数据;若应答不成功(N)则主设备发送停止信号(P),对应图中(P)状态
主设备读取从设备信息
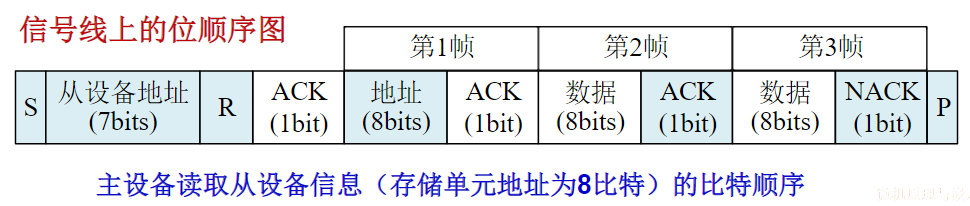
- 主设备发送开始信号(S),对应图中(S)状态
- 主设备发送7比特的从设备地址,对应图中发送地址阶段
- 主设备发送读命令(高电平,R),对应图中R/W#
- 接着从设备应答(A),ACK为应答成功(A),表示有这个设备
- 从设备发送8位字节数据,主设备从SDA上读取数据
- 接着主设备应答,ACK为应答成功(A),或,NACK为不成功为(N)
- 如果主设备应答成功(A)则从设备继续往SDA上送数据;若应答不成功(N)则主设备在发送NACK后发送停止信号(P),对应图中(P)状态
I2C电气特性
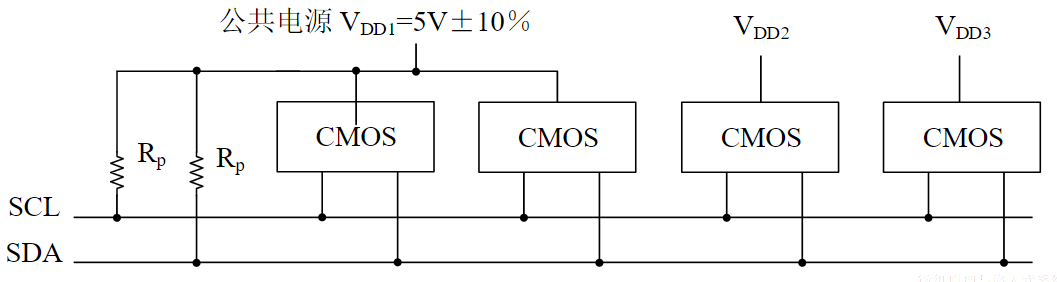
- I2C允许不同制造工艺生产的器件、使用不同电源电压的器件进行通信。具有固定输入电平的I2C总线器件,可以分别单独连接适合自己的电源电压,但是SDA和SCL必须通过上拉电阻(图中RP)连接到5V的公共电源上。
- 单个IO引脚的负载电容不能超过10pF,所有IO引脚的总负载电容不能超过400pF。拓展传输距离和可挂接器件数目,可将I2C总线分段。分段时可以使用缓存(buffers)、多路复用器(multiplexers)、交换开关(switches)等不同的芯片隔离不同的段,每段总的负载电容不能超过400pF
I2C支持的节点数
- 决定因素1:I2C从设备的地址位数。I2C标准中有7位地址和10位地址两种。如果是7位地址,允许挂接的I2C器件数量为:27=128,如果是10位地址,允许挂接的I2C器件数量为:210=1024,一般I2C总线上挂接的I2C器件不会太多,所以现在几乎所有的I2C器件都使用7位地址
- 决定因素2:挂在I2C总线上所有I2C器件的管脚寄生电容之和。I2C总线规范要求,I2C总线容性负载最大不能超过400pF
I2C操作示例:读取串行EEPROM
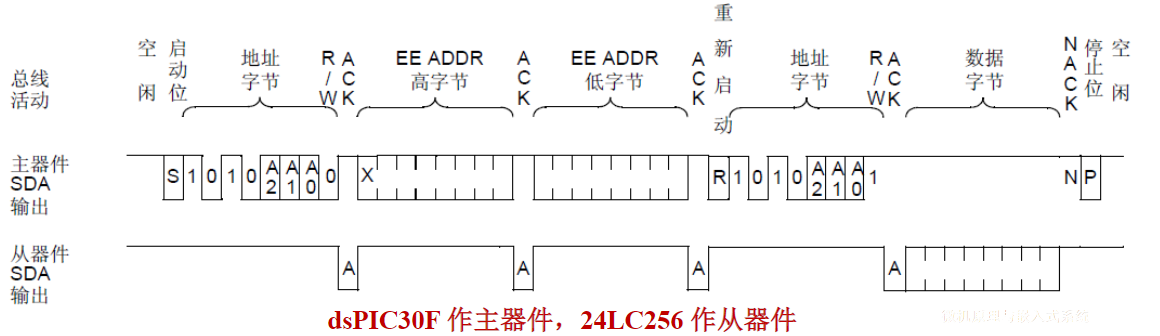
- 所有报文都以“启动”条件开始并以“停止”条件终止
- 第一个字节是器件地址字节
- R/W = 0,表示主器件将充当发送器,从器件则将是接收器
- 接收到每个字节后,接收器件必须产生应答信号“ACK”
- ......
- 要让从器件向主器件发送数据,总线必须转为另一个方向。要实现此功能且不终止报文传送,主器件可发送一个“重新启动”信号。“重新启动”后接一个器件地址字节,该字节包含和前面相同的器件地址,但R/W = 1,以表明从器件发送,主器件接收
- 现在从器件发送驱动SDA 线的数据字节,主器件继续产生时钟信号
4.4.4.4. SPI接口及总线
SPI是一种高速、全双工、同步的通信总线,通信过程使用四根信号线
SPI概述
同步串行外设接口,它可以使MCU与各种外围设备以串行方式进行通信以交换信息。是Motorola首先在其MC68HCXX系列处理器上定义的。SPI接口主要应用在EEPROM,FLASH,实时时钟,AD转换器,还有数字信号处理器和数字信号解码器之间
需要至少4根线,事实上3根也可以(单向传输时)
- MISO (Master Input Slave Output),主设备数据输入,从设备数据输出
- MOSI(Master Output Slave Input),主设备数据输出,从设备数据输入
- SCLK(Serial Clock),时钟信号,由主设备产生
- CS (Chip Select),从设备使能信号,由主设备控制
SPI中主设备与从设备的连接
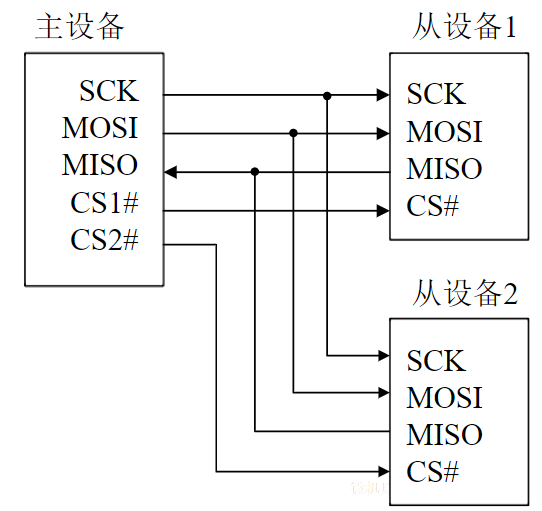
- SPI上可以挂载一个主设备和多个从设备。任何时刻,一个主设备只与一个从设备进行通信,通信的从设备CS为低电平(有效)
- 在不使用CS信号时,SPI上只能有一个主设备与一个从设备
- SPI的缺点是没有应答机制,传输过程全都由主设备进行控制,数据传输成功与否没法直接验证
SPI典型接口电路
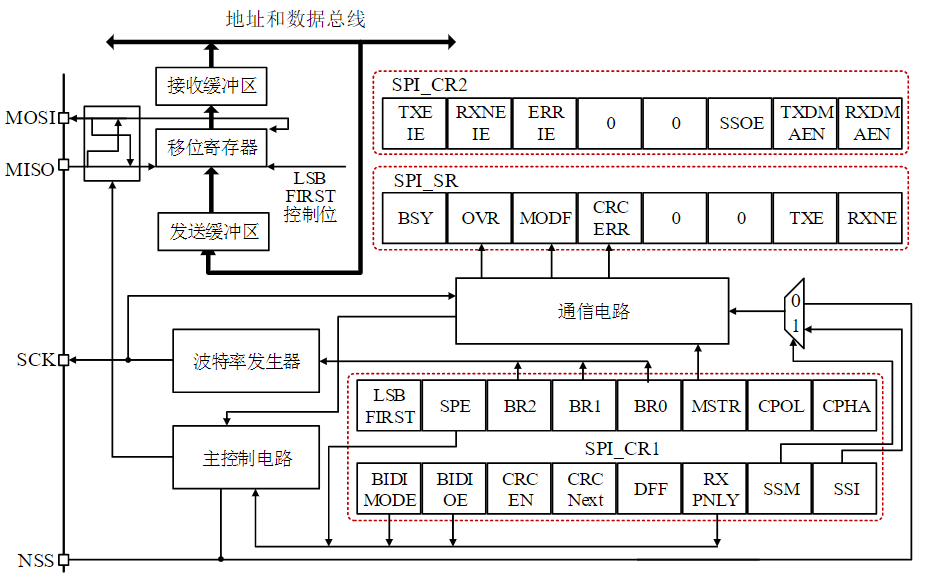
- 发送缓冲区、移位寄存器、接收缓冲区的设计在一般串行通信接口电路中大体一致
- 状态寄存器SPI_SR、控制寄存器SPI_CR1、SPI_CR2、波特率控制寄存器BR虽然在不同厂家的SPI接口电路中也都有,但是寄存器比特定义往往略有差异
SPI数据传输过程
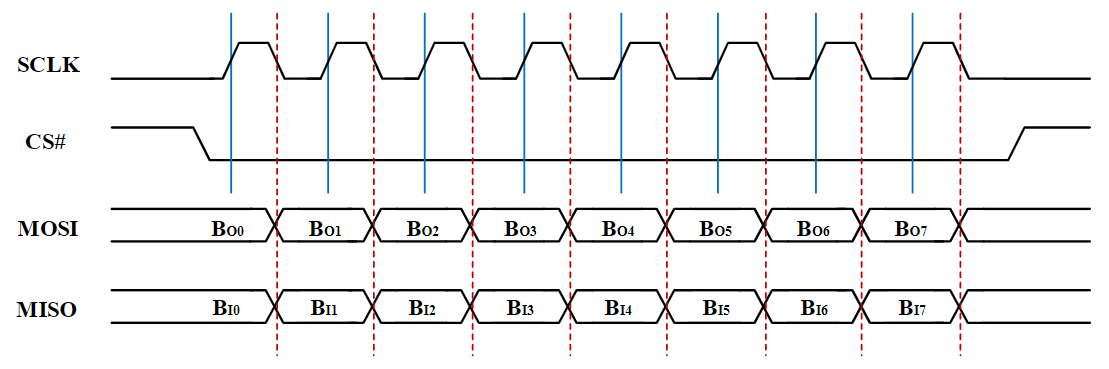
通信过程由主设备发起,从设备参与
当一个主设备需要向从设备发送数据,或者希望读取从设备数据的时候,主设备通过拉低对应从设备的CS#来告知从设备
对于主设备来说,发送数据就是把比特逐个放到MOSI信号线上,而读取数据就是在MISO信号线上进行采样
SPI的四种工作模式
SPI工作状态简单,只有工作和空闲两个状态
根据空闲状态对应时钟的高电平还是低电平,以及时钟上升沿和下降沿的动作,可以形成不同四种工作方式
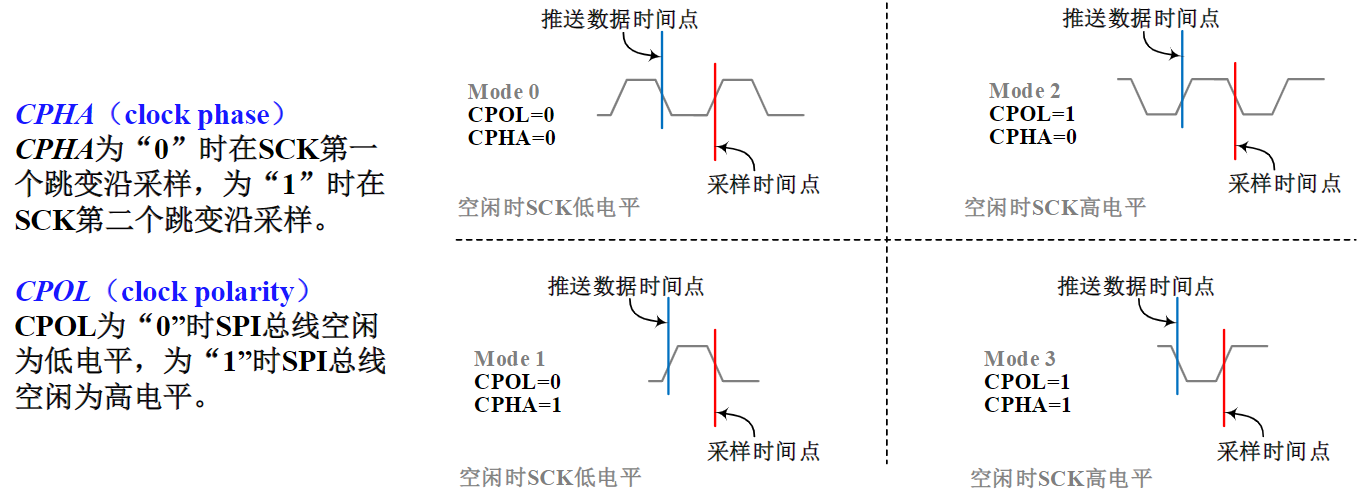
5. ARM处理器体系结构和编程模型
5.1. ARM体系结构与ARM处理器概述
5.1.1. 指令集体系结构与微架构
CA(Computer Architecture):计算机体系结构
CA是堆计算机系统的设计思想、逻辑特征、原理特征、结构特征和功能特征的一种抽象
广义CA=指令集系统结构ISA+微架构μarch+硬件实现
狭义CA=指令集系统结构ISA
指令集体系结构ISA
描述软件如何使用硬件的一种规范和约定,是程序员眼中的概念结构和功能特征,具体地就是程序员编程时能看到或者能用到的资源以及使用方式,包括:
- 可执行指令集合,包括指令格式、操作种类以及每种操作所对应的操作数规范
- 指令可接受的操作数类型
- 寄存器组结构,包括名称、编号、长度和用途
- 存储空间的大小和编址方式
- 操作数寻址方式及操作数存放格式
- 指令执行控制方式,包括程序计数器、条件码定义等
微架构μarch
ISA的硬件实现方式。亦即以何种方式来实现处理器的各种功能,包括运算器、控制器、流水线、超标量和存储系统结构等,属于计算机的组织和实现技术
相同ISA的处理器可以有不同的微架构,如:
ARM9T和ARM7Y
- 5级流水线哈佛结构vs.3级流水线冯诺依曼结构
AMD和Intel
- 都支持x86 ISA,但微架构不同
只要ISA相同,则软件兼容
处理器体系结构的分类
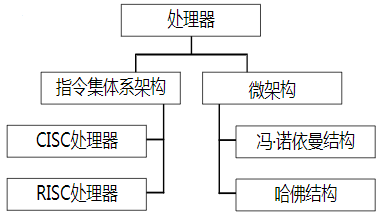
ISA偏于处理器的软件层面,微架构偏于处理器的硬件层面
基于ISA分类:CISC、RISC
基于微架构分类:冯诺依曼结构、哈佛结构
哈佛结构:
- 一种并行体系结构
- 程序和数据存储在不同的存储空间中,每个存储器独立编址,使用两套总线单独访问
- 可提高数据吞吐率,消除流水线上取指和取操作操作的资源相关,处理器性能高于冯·诺依曼结构
- 哈佛结构较为复杂,实现难度较大,早期较少采用
简化哈佛结构:
Intel MCS-51单片机,指令和数据分别存储两个独立的存储模块,但仍共用一条公共总线,仍须分时访问
有些内部使用两条独立总线分别访问指令和数据(如Cortex-M系列处理器),有些内部分别配置指令和数据Cache或者TCM。但对外只有一条总线,外部指令和数据仍然存储在一个存储器中,旨在减少硬件复杂性
- TCM(Tightly Coupled Memory,紧耦合内存),通过专用总线与CPU相连的高速存储器,性能与Cache相当,常与处理器集成在一起,早先也有片外的。与Cache的主要区别:具有物理地址、需占用内存空间、无Cache的不可预测性
- 用途:存放必须快速执行的中断服务程序和实时任务处理程序,以及不适合存放在Cache中的重要数据,如中断向量表和堆栈
5.1.2. ARM处理器体系结构简介
ARM体系结构版本特性简介
v1版
与ARM1原型机同时诞生,仅用于ARM1原型机
32位处理器,地址总线只有26条,内存寻址空间64MB,只提供了一些基本指令,如:
基本数据处理指令,没有乘法运算指令
数据存取指令,可以对字节、半字和字数据进行存取
控制转移指令,包括子程序调用及链接指令
- 链接指令:一种转移指令,转移时将转移指令的下一条指令存入R14寄存器。需要返回时,使用MOV指令将R14寄存器的内容写入PC,就可实现程序的返回
供操作系统使用的软件中断SWI指令
v2版
ARM 2的内存寻址空间仍然只有64MB,为了提高数据处理能力,v2版增加了:
- 乘法运算和乘加运算指令
- 若干协处理器操作指令
- 快速中断模式FIQ(优先级高于普通IRQ)
- 存储器与寄存器之间进行数据交换的SWP(swap)指令,包括字交换指令SWP和字节交换指令SWPB
基于ARMv2版架构的处理器有ARM2、ARM2aS和ARM39
v3架构
有较大改进和完善,32位地址,内存寻址空间扩展到4GB,增加了Cache、新的寄存器和新的指令:
增加了CPSR,不再使用R15寄存器保存程序执行状态
增加了SPSR,用于异常处理时保存CPSR,以便恢复
增加了访问CPSR等特殊寄存器的MRS和MSR指令
增加了从异常处理返回指令的功能
新定义了abort和Undefined两种异常及相应的工作模式
将乘法和乘加运算指令扩展为32位
- 长乘法运算:32位×32位=64位
- 长乘加运算:32位×32位+32位=64位
v4架构
基于ARMv4的处理器主要是ARM8和Strong ARM
ARMv4T版本——ARM体系架构的一个里程碑
- 引入16位Thumb指令集:ARM指令集中常用指令经重新编码压缩后的子集
- 执行时被实时且透明地解压,仍然是32位指令
- 具有ARM指令集的大部分功能但不如ARM指令集全面,实现某些复杂操作可能需要使用较多的Thumb指令
- 可提高代码密度,减少存储开销;在数据总线位宽为16位或8位的SOC系统中,可获得更优的性能
- 新增Thumb状态,与ARM状态可通过指令随意切换
v4T版在v3版的基础上所做的完善和扩展:
- 微架构开始采用流水线方式
- 增加了系统(System)模式,在该模式下可以使用用户模式寄存器运行具有特权级的系统管理任务
- 对软件中断指令SWI的功能做了完善
- 增加了无符号字节以及半字数据的加载/存储指令,如LDRB/STRB(字节)、LDRH/STRH(半字)
- 增加了有符号字节及半字的加载指令LDRSB/LDRSH
- 把没有使用的指令空间都作为“未定义指令”,并在UND异常中对其进行处理
ARM7T和ARM9T产品系列都基于v4T版
v5架构
微架构方面
- 增加了DSP,MCU和DSP可以合二为一
- 可选配矢量浮点处理器(Vector Float Processor,VFP)
- 增加JazelleDBX (Direct Bytecode eXecution) 的Java硬件加速器(ARMv5TEJ),可直接运行Java虚拟机字节码程序
- 带有AHB或者AHB Lite总线接口
- 引入(包括指令和数据)TCM或者TCM接口
- v5版名称后缀中的字母T、E和J分别表示支持Thumb指令、增强的DSP指令和Java硬件加速技术
ISA方面的改进和完善
- 增加了DSP指令,为协处理器提供了更多可选择的指令
- 更加严格定义了乘法指令对条件标志位的影响
- 增加了支持有符号数的加减饱和运算指令(饱和运算是指出现溢出时,结果等于最大或者最小可表示范围)
- BLX指令,将可返回的转移指令与状态切换合二为一
- CLZ指令,计算寄存器操作数最高位0(前导0)的个数,可提高归一化运算、浮点运算以及整数除法运算的性能,也使中断优先级排队操作更为有效
- BRK指令,软件断点指令
基于ARMv5版架构的ARM处理器包含ARM7EJ、ARM9E和ARM10E三个系列产品
v6版
发布于2001年,ARM体系结构又一个重要里程碑
支持ARMv5TEJ所有指令,在多媒体处理、存储器管理、多处理器支持和异常响应等方面引入许多新技术
微架构实现:流水线级数增至8或9级(v6T2),采用动态和静态组合的转移预测方式,准确率可达85%
内核与Cache以及与协处理器之间的数据通路为64位,每个流水线周期可读入2条指令或存放2个连续字数据
增加了增强型的数字信号处理器以及用于功耗管理的IEM(Intelligent Energy Management)部件,在性能和功耗两个方面又有新的突破
在ISA方面,ARMv6版架构增加了以下功能和指令:
- Thumb-2指令集(v6T2增强版),可以混合执行AMR指令和Thumb指令,兼具两者的优点,可认为是v6版大的进步
- 新增SIMD指令,使多媒体信号(如左右声道、三基色像素)的处理能力提高了2~4倍
- 支持混合大小端(Mixed-endian)和非对准(Unaligned)存储访问
- 采用了名为Trust Zone安全解决方案,在硬件层面划分可信区域和不可信区域,分别运行经认证的代码和未经认证的代码,不同代码具有不同的访问权限
v7版
发布于2004年,ARM体系结构的分水岭
- 全面支持Thumb-2技术。Thumb-2指令集包括了16位和32位指令,较先前的ARM指令集减少了31%的内存使用量,较原有的Thumb指令集提升了38%性能,并且无需在ARM指令集和Thumb指令集之间来回切换
- 引入名为NEON的多媒体处理引擎,支持128 位SIMD扩展,性能提升了4倍,以迎合3D图形与手游应用
- 在处理器的工作状态与操作模式、寄存器组织、异常和中断管理、对操作系统的支持等方面有许多变化,与以往版本有较大的区别,同时也兼顾了与经典ARM处理器软件保存较好的兼容
v8版
首款支持64位指令集的处理器架构
- 新增加64位指令集,称作A64,并继续支持原有的ARM指令集和Thumb-2指令集,但是改称为A32和T32指令集
- 新定义AArch64和AArch32两种运行状态,分别执行64位和32位指令集
- 在ARMv7安全扩展的基础上,新增加了安全模式,支持与安全相关的应用需求
- 在ARMv7虚拟化扩展的基础上,提供完整的虚拟化框架,在硬件层面上提供对虚拟化的支持
- AArch64对异常等级赋予新的内涵,并重新解释处理器运行模式和特权等级概念
继续分为ARMv8-A、ARMv8-R和ARMv8-M三种类型
- v8-A:支持AArch64和AArch32两种运行状态,两种运行状态之间进行切换。除了智能手机和平板电脑传统应用领域之外,开始向通用计算应用领域拓展
- v8-R:具有快速中断响应能力和确定的中断响应时延,采用容错设计和MPU,支持A32和T32指令集,应用领域均为对实时性和可靠性有着极高的要求的场合
- v8-M:使用与其他类型不同的异常处理模型,并且只支持T32指令集。主要面向低成本、小体积、低功耗、低中断延迟以及高性能的嵌入式应用
- 基于上述三种体系结构类型的处理器产品,仍然分为Cortex-A、Cortex-R和Cortex-M三个系列
ARM体系结构的增强型版本
每个基础版还有增强版,支持的指令有区别。在v7版之前,增强版用版本号的字母后缀表示,如:
T增强版:表示该版本支持Thumb指令集
E增强版:支持增强的DSP算法
J增强版:支持Java加速
S增强版:提供用于多媒体信号处理的SIMD指令
F增强版:支持矢量浮点处理单元
V6版还有:
- T2增强版:支持Thumb-2指令集
- Z增强版:支持TrustZone安全增强
- K增强版:支持多核
- M增强版:超低功耗,用于Cortex-M0/M0+/M1
v7版本之后,不再使用
小结
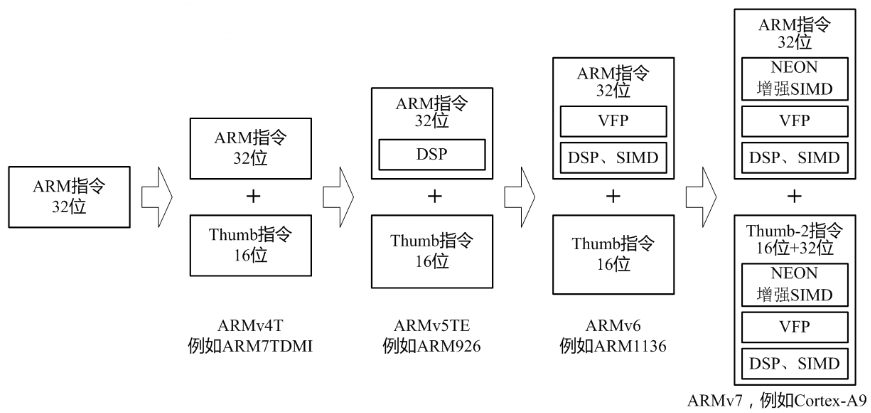
- ARM指令集:32位
- Thumb指令集:16位,可提高代码密度,减少存储开销,是ARM指令集中常用指令经重新编码压缩后的子集,执行时被实时且透明地解压,仍然是32位指令
- Thumb-2指令集:混合执行AMR指令和Thumb指令,兼具两者的优点,无需在ARM指令集和Thumb指令集之间来回切换
5.1.3. ARM处理器主要产品系列简介
5.1.3.1. ARM处理器的特点
- 固定长度操作码,简化了指令译码,便于流水线设计
- 具有多个通用寄存器,指令不局限在某个特定的寄存器上执行,可以实现寄存器组的均匀访问
- 操作数地址由寄存器内容或者指令码的位域指定,具有地址自动增减寻址模式,寻址方式灵活,可以优化程序循环结构,程序执行效率高
- 每条数据处理指令都可对算术逻辑单元和移位器进行控制,实现ALU和移位器的最大利用
- 具有多寄存器加载和存储指令,可实现大数据吞吐量
- 所有指令都可以条件执行,以提高代码执行速度
- 支持精巧的Thumb指令集(包括Thumb和Thumb-2),提高代码密度,减少所需的系统存储容量
5.1.3.2. ARM处理器相关产品的层次关系
从内到外分为:ARM内核、ARM处理器、MCU或者SOC、以及嵌入式系统四个层级
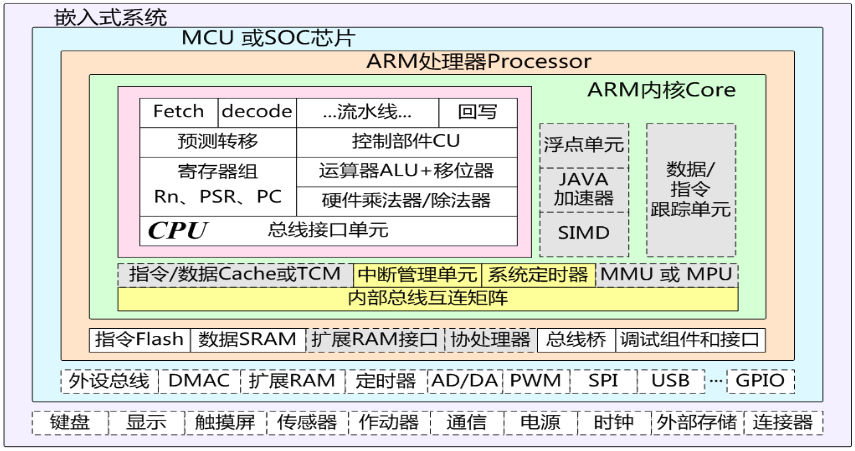
ARM内核
必备部件
- CPU,v4T之后均采用流水线技术+转移预测
- 总线互连矩阵,提供多种数据的并行传送能力
- 中断管理部件,提供周期确定的低时延中断响应
- 系统定时器,多任务操作系统必不可少的部件
可选部件
- 指令和数据Cache或TCM
- MMU或者MPU
- 数据/指令跟踪单元
- 浮点单元、Java硬件加速器、多媒体处理部件
ARM处理器
ARM内核的基础上,通过系统总线连接了:
- 指令存储器,一般是flash
- 数据存储器,一般是SRAM
- 协处理器或者协处理器接口部件
- 扩展RAM控制器,扩展存储器不能与系统总线直接相连,必须通过存储器扩展接口
- 外设总线桥接器
- 部分调试跟踪组件
通过外设总线连接
- 调试访问接口
- 内核私有外设
MCU和SoC
以ARM处理器为核心,增加了
- 扩展存储器
- DMAC
- ADC、DAC
- 脉宽调制PWM
- 实时时钟RTC
- 电源监测BOD
- 串行接口UART
- ……
5.1.3.3. ARM处理器产品命名规则
体系结构版本与处理器采用两种标识方式,对应关系开始变得较为复杂
常见以及仍在使用的产品与ISA的对应关系:
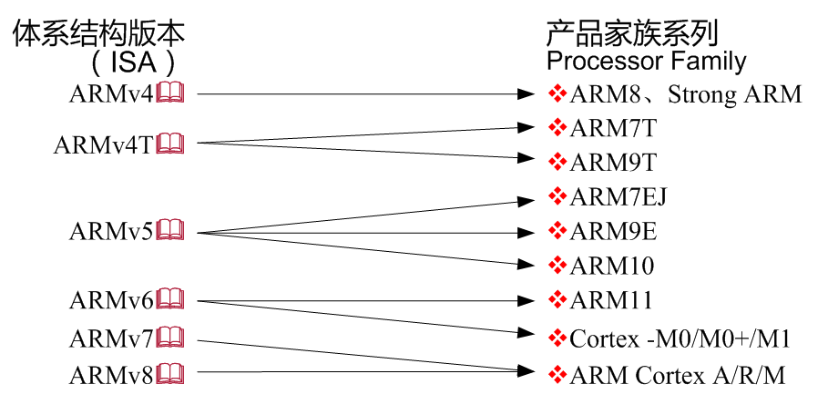
v7版之前的产品命名规则
处理器名称后缀中的英文字母含义
- T、E、J、S、F、T2、Z和K等字母表示所基于体系结构增强版本
- 基于v4T的产品(如ARM7TDMI )中还出现过D、M和I,分别表示带有Debug调试接口、硬件乘法器和嵌入式ICE,后来成为标准配置,不再另外表示
第一个数字的舍义
表示产品系列,如ARM7TDMI和ARM920T分别对应ARM7系列和ARM9系列
- ARM10和ARM11产品系列中,10和11各占两位数字
第二个数字的含义
2:表示带有MMU,如ARM720T和ARM920T
3:改良型MMU
4:表示带有MPU,如ARM946ES
6:无MMU和MPU,如ARM966E-S和ARM968EJ-S
- ARM1156T2(F)-S中的“5”表示可选指令和数据MPU
- ARM1176JZ(F)-S中的“7”表示增加了IEM能源管理组件
第三个数字的含义
- 0:表示标准容量Cache
- 2:表示减小容量的Cache
- 6:表示带有紧耦合内存TCM5)
名称最后的“-S”表示软核(HDL描述的产品)
5.1.3.4. ARM7系列
分为ARM7(基于v3)和ARM7T(基于v4)两个子系列,获得广泛应用的是ARM7T
ARM7T系列基本型产品是ARM7TDMI(-S),同系列其他产品都是在其基础上增加了Cache、MMU或者MPU、以及ASB总线接口
MMU和MPU都是用于内存管理,两者的功能和主要区别如下:
- MMU:内存分页管理+虚拟地址VA到物理地址PA的转换+分区域访问权限管理,适用于多用户系统
- MPU:内存分区域访问权限管理,适用于要求对处理时间有明确要求的实时系统
5.1.3.5. ARM9系列
分为ARM9T和ARM9E两个子系列
ARM9T基于v4T版本架构(与ARM7T相同),但是微架构有不一样,采用的是哈佛结构,流水线为5级
ARM9E采用的也是哈佛结构,分为v5TE和v5TEJ两个子版本,从版本号后缀可以看出:
- T:支持Thumb指令
- E:支持增强的DSP指令
- J:支持Java硬件加速
从ARM9E开始增加TCM,性能与Cache相当,可以对TCM进行寻址访问
5.1.3.6. ARM11系列
ISA大版本都是v6,有四款处理器产品(全是软核),每款处理器的ISA小版本各不相同
ARM1136J(F)-S,基于ARMv6版本,主要特性:
- SIMD、Thumb、Jazelle、MMU以及可选配的VFP
ARM1156T2(F)-S,基于ARMv6T2版本,主要特性:
- Thumb-2指令集、SIMD、可选配MPU以及VFP,主要应用在高可靠性和实时嵌入式应用领域
ARM1176JZ(F)-S,基于ARMv6Z版本,主要特性:
- 在ARM1136J(F) -S基础上增加了TrustZone和IEM部件
ARM11MPCore,主要特性:
- 可配置1~4颗ARM1136J(F)-S的SMP处理器,后期的升级产品为基于ARMv7A系列的Cortex-A5处理器
ARM 11流水线仍属于单发射标量流水线,但是:
- 流水线的后几级,算逻单元ALU、乘积累加单元MAC和数据加载/存储单元LSU采用并行部署,属于一种分叉或者分支结构的流水线
- 当指令完成译码和取操作数之后,不同类型的任务被分发到不同的流水线分支上执行,每一级操作更加简单,执行速度更快,可以减少流水线周期,从而可提高流水线时钟频率
- ARM11的工作时钟频率在500MHZ以上,最高可达到1GHz,取决于不同的工艺制程,尺寸越小速度越快
设计理念:在性能、功耗、芯片面积和成本之间进行均衡,支持休眠模式、待机模式和关机模式
ARM11流水线结构:
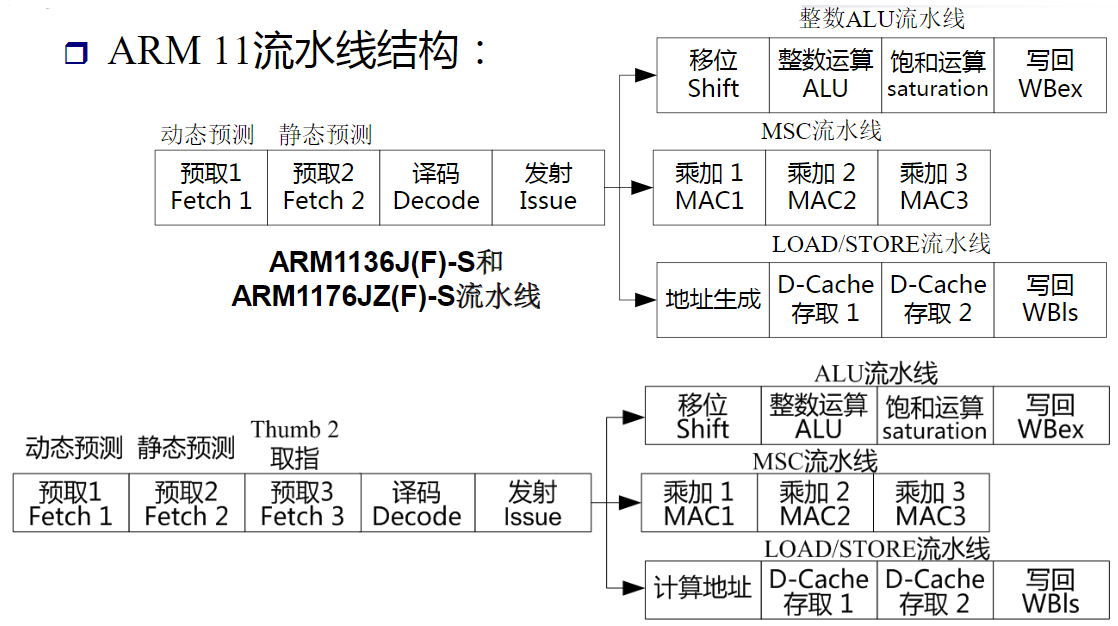
5.1.3.7. Cortex-A
Cortex-A系列处理器应用场景:
- 移动计算、智能手机、平板电脑、数字电视、企业网络、通用计算和服务器
主要特性:
- 支持可伸缩的异构或者同构多核的高性能处理器,内置VFP和NEON(DSP+SIMD),支持浮点运算和SIMD多媒体数据处理,时钟频率超过1 GHz,支持Linux、安卓和微软视窗操作系统
产品:从A5~A77共计20款,其中A5~A17为基于v7-A版本的32位处理器;A32虽然基于v8-A,但只有AArch32运行状态;A34以后产品基于64位v8-A版本结构,同时支持AArch32和AArch64两种运行模式
big.LITTLE(bL) 技术
允许拥有两种不同类型的内核,相同类型的内核组成一个簇(cluster),轻负载时运行低功耗内核,高负载时运行高性能内核,在性能和节能之间寻求平衡
采用bL结构的SOC芯片案例:
- 华为海思麒麟950:4A72+4A53+GPU+ISP+Modem+DSP
- 华为海思麒麟960:4A73+4A53+GPU+ISP+Modem+DSP
DynamIQ大小核技术
bL技术升级版,允许最多8个内核构成一个簇,单个处理器最多可实现32个簇和256个内核
Cortex-A55(2017年),第一款采用DynamIQ技术的小核,基于ARMv8.2架构,“具有深远影响的产品”
- 利用神经网络算法提高转移预测准确性
- 对NEON、VFP和缓存结构做了改进,低功耗设计
可作为高性能低功耗的64位处理器单独使用,应用于数字电视、VR和AR
但A55的设计目标是作为DynamIQ结构中的小核,目前许多高端手机处理器中,有些虽然采用了自研的大核,但小核几乎都毫无例外地选用了A55
A76(2018年)和A77(2019年),基于DynamIQ技术的“大核”,设计目标是利用DynamIQ技术与更多的同构或者异构内核集成,提供更强大的计算能力和实现更高效的能源利用效率
- A76:使用了可以乱序执行的超标量结构,拥有4个解码发射单元和8条并行流水线,流水线级数为13级。采用7nm制程工艺时,峰值时钟频率可达3GHz
- A77:基本配置与A76基本相同。但在微体系结构做了许多改进,例如采用更大带宽的前端(取指+译码+转移预测+发射)、新的指令缓存技术、新的整数ALU单元和改进的加载/存储队列,在相同制程工艺和时钟频率条件下,A77的IPC比A76提高了20%,可以看作是A76的改良版
A76应用举例:华为海思麒麟980/990手机处理器
- A76+A55,基于DynamIQ技术的异构多核架构
- CPU:两种内核,三种频率,兼顾性能与续航时间
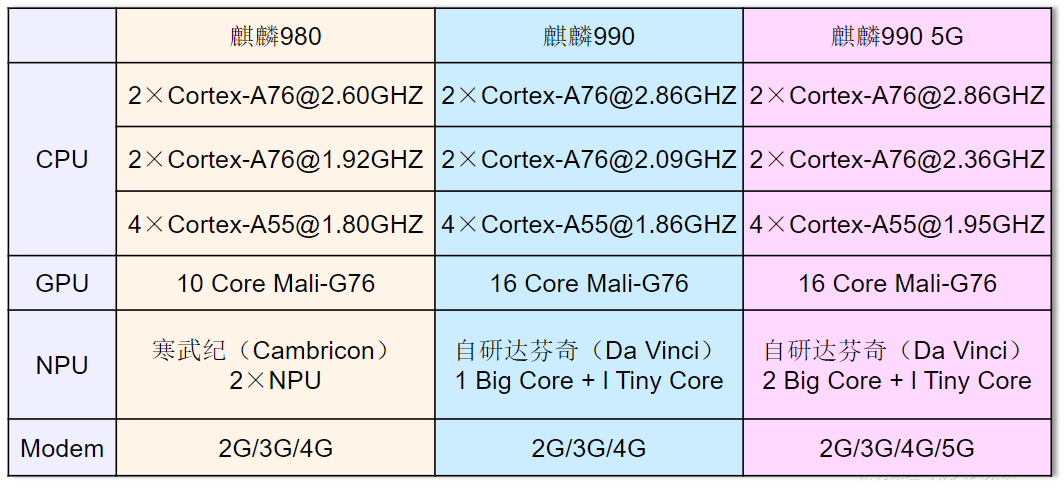
5.1.3.8. Cortex-R
聚焦于高性能实时应用,设计目标包括:高性能、低延时、高可靠、可信赖、安全性和容错性,以确保嵌入式系统的时间确定性和行为确定性
- 时间确定性:有硬性的处理截止时间(Deadline)要求,必须在规定的时间内完成规定的操作
- 行为确定性:绝不允许出现因处理器或数据错误而导致的误操作。为此,软硬件必须具备一定的容错能力
Cortex-R应用领域:
- 手机基带调制解调器、硬盘驱动器、企业级网络设备、汽车电子、医疗设备和工业控制装置等,而后面几种应用对安全稳健(Safety-Critical)有极高要求
目前Cortex-R系列处理器共有5款:
- 基于v7-R版本架构的R4、R5、R7和R8
- 基于v8-R版本架构的R52,但只能运行AArch32状态
- 都支持A32和T32指令集,可以实现二进制代码兼容
容错设计:多处理器锁步(lock-step)技术
双处理器锁步:主处理器和监控处理器在时间上严格同步地执行相同的指令。主处理器承担系统处理任务并负责驱动输出,监控处理器连续监控主处理器总线上的数据、地址和状态等信息
- 如果发现两个处理器不一致,则说明某个处理器出现了差错,本次计算结果不输出,实现故障静默
- 但是,双处理器锁步无法实现故障恢复
多处理器锁步:单颗处理器出现故障时,可通过硬件表决方式判断出现故障的处理器并将其屏蔽,由其他处理器负责任务执行,可实现故障的实时恢复
所有Cortex-R处理器都支持锁步技术
- R4是单内核处理器,锁步配置需要使用两颗独立的R4
- R5升级为一主一备的异构双核,单处理器就可实现能够独立运行的锁步双核
- R7在异构双核中增加了QoS(服务质量保证),另外增加一对同构双核,以提高处理器的性能
- R8和R52中可锁步配置的内核数增至3颗或者4颗,可实现故障恢复,同时也增加了同构内核的数量
数据纠错/检错:ECC和奇偶校验
- 奇偶校验:每个数据(字节或半字或字)后面增加一位,使“1”或“0”的总数为奇数或偶数。若错码位数为奇数则可被发现,但是只能检错,无法纠错
- ECC:存储数据时,利用编码算法在每个数据后面增加若干冗余位,读出时对其进行检查,不仅可以检错还可以纠错,纠错/检错能力与冗余位长度有关
R系列处理器的Cache或TCM都支持ECC和或奇偶校验,可实现2bit的检错和1bit的纠错
除R4外,R5~R52还支持对总线接口的ECC纠错和检错,R52增加了对互连交叉总线的错误防护功能
为满足实时性要求,Cortex-R处理器都采用指令和数据分离的哈佛结构,都带有指令和数据Cache、TCM存储器、硬件除法器、双精度FPU、MPU、内存和中断控制器,此外:
- R4~R8处理器配置了SIMD单元和DSP
- R52处理器增加了NEON引擎
- R5~R52配置了低时延外设接口(Low Latency Peripheral Port ,LLPP),可实现快速外设读取和写入
面向实时应用的处理器一般不采用虚拟地址,R系列处理器都没有配置MMU,但是都带有MPU
ISR一般都存在私有TCM中,以减少中断响应延迟
5.1.3.9. Cortex-M
面向低成本、低功耗和高性能应用领域,虽然在性能、可靠性和实时性方面不如Cortex-A和Cortex-R系列,但目前是ARM公司销售量最大的产品
2019年第4季度ARM处理器的总出货量为64亿片,其中有42亿片属于Cortex-M系列,占比达66%
Cortex-M系列第一款产品是基于v7-M版本架构的Cortex-M3(2005年)。为减小功耗,流水线只有三级(取指、译码、执行),但带有NVIC、硬件除法器、支持Thumb-2指令集、丰富的调试和跟踪功能
2010年发布的Cortex-M4与Cortex-M3基本相似,但增加了DSP,并且可选配FPU
v7-M出现3年后,ARM继续推出v6-M架构,相关产品有Cortex-M1(面向FPGA设计)、M0和M0+,目标市场是低功耗、小体积和高性价比应用,例如:
- M0/M0+采用冯.诺依曼结构,3级流水线,带有NVIC、硬件乘法器、能源管理部件和AHB Lite总线接口,可选配WIC,功耗仅为5.3 μW(M0)和3.8μW(M0+)/MHz @1.1v/25°C,属于极低功耗处理器
Cortex-M7(2014年9月),基于v7-M,6级流水线,带有双精度浮点单元、可选Cache或者TCM,以迎合高端微控制器和密集型数据处理的需求
基于v8-M的M系列处理器:M23、M33和M35P,支持新的增强指令集,增加了Trust Zone安全扩展
- M23具有与M0类似的低成本和小体积特点
- M33与M3和M4类似,但系统设计更灵活,能效比更高
- M35P产品型号中的“P”表示具有物理(Physical)防篡改(tamper-resistant)功能,包含了多项防范物理攻击的安全特性
面向未来的物联网中的高端应用,2020年2月10日,ARM公司正式发布了基于ARMv8.1-M版本架构的Cortex-M55处理器(预计2021年才有产品问世),可看作Cortex-M33的下一代产品
M55首次使用了基于MVE(M-Profile Vector Extension,矢量扩展)技术的Helium引擎,将执行SIMD指令和DSP处理能力提升了5倍,机器学习能力提升了15倍
同时,ARM还发布了一款与Cortex-M55配套使用的嵌入式NPU,Ethos-U55(此前已有Ethos-N37、N57和N77),Ethos-U55是专为下一代Cortex-M处理器定制的,具有低功耗和低成本的特性
M55+U55,未来物联网应用领域的利器
5.2. Cortex-M3/M4处理器结构
5.2.1. Cortex-M3/M4处理器概述及指令集架构
5.2.1.1. Cortex-M3/M4主要特性
基于v7M版本架构,三级流水线(取指、译码和执行),哈佛结构。主要特性如下:
- 32位处理器,可以处理8位、16位和32位数据;
- 本身不包含存储器,但提供了连接不同存储器的总线接口;
- 多种总线接口,可分别连接存储器、外设以及调试接口;
- 紧耦合的NVIC,能以确定的周期快速响应中断;
- 丰富的调试和跟踪组件以及外部调试接口;
- 可选配MPU,实现内存的分区保护;
- 低功耗,低成本,具有丰富的开发调试工具;
- 但是,作为低成本低功耗处理器,没有Cache或TCM,没有协处理器以及接口,也不支持虚拟地址(没有MMU)
带有系统节拍定时器Systick,可为操作系统所需的定时提供周期性的定时中断
双堆栈指针,操作系统和应用任务使用不同的堆栈
- 主栈指针MSP,供操作系统和中断处理使用
- 进程栈指针PSP,用户程序使用
- 对于不使用操作系统的简单应用,可以只使用MSP
特权和非特权访问等级
- 限制非特权等级访问某些寄存器,提高系统安全性
- 与MPU配合,限制非特权访问某些内存区域,防止破坏操作系统或者其他任务数据;即使用户程序出现问题,不会对其他任务带来影响,提高系统的健壮性
Cortex-M4可以选配单精度FPU,其功能主要包括:
- 提供多条浮点运算指令,以及多条浮点数据转换指令
- 支持融合MAC运算,以提高MAC结果的精度
- 若不需要浮点单元,可以将其关闭从而降低功耗
Cortex-M4指令集增加了DSP扩展,例如:
- 8位和16位SIMD指令,允许对多个数据同时进行并行操作,包括寄存器的高低16位多种组合乘法
- 支持多个饱和运算指令,包括SIMD运算,避免在出现上溢出和下溢出时计算结果产生大的畸变
- 单周期16位、双16位以及32位的乘累加(MAC)运算
Cortex-M3也有几条MAC指令,但不是单周期的
5.2.1.2. Cortex-M3/M4所支持的指令集
Cortex-M4可看作Cortex-M3的增强版,两者都支持Thumb-2技术,但所支持的指令集有差异
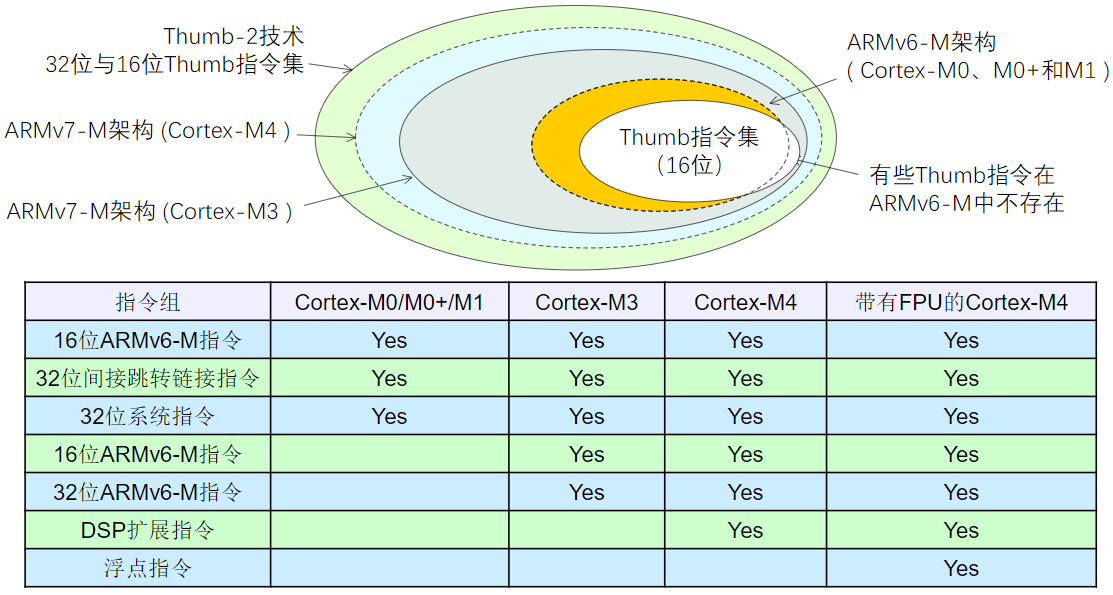
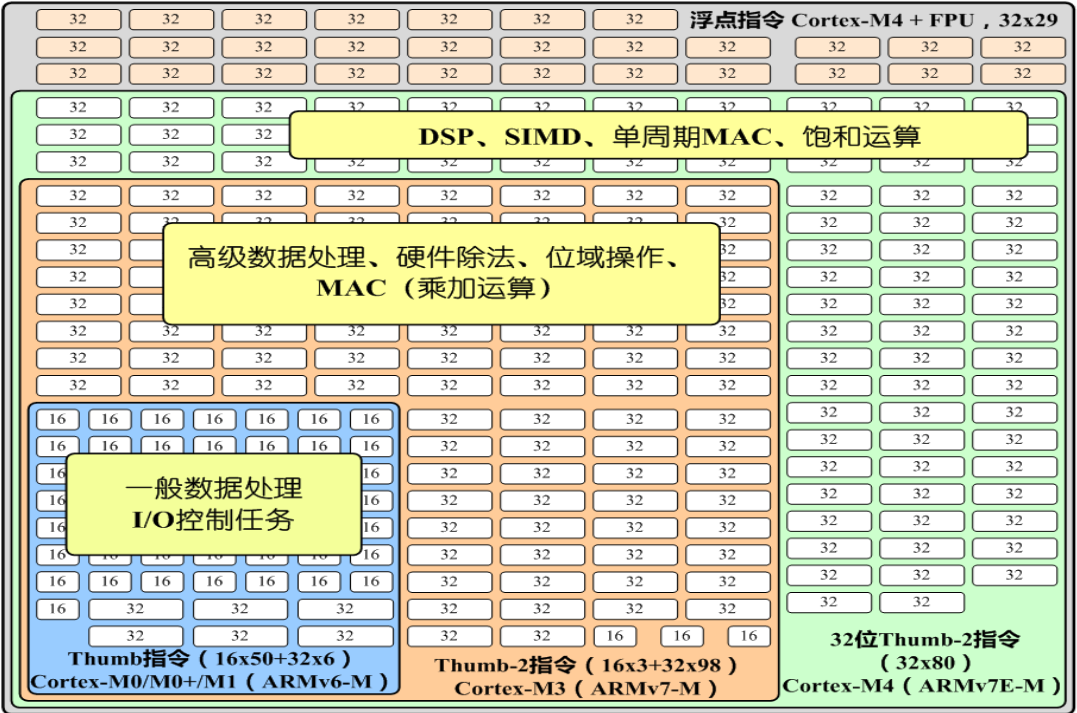
5.2.2. Cortex-M3/M4处理器结构
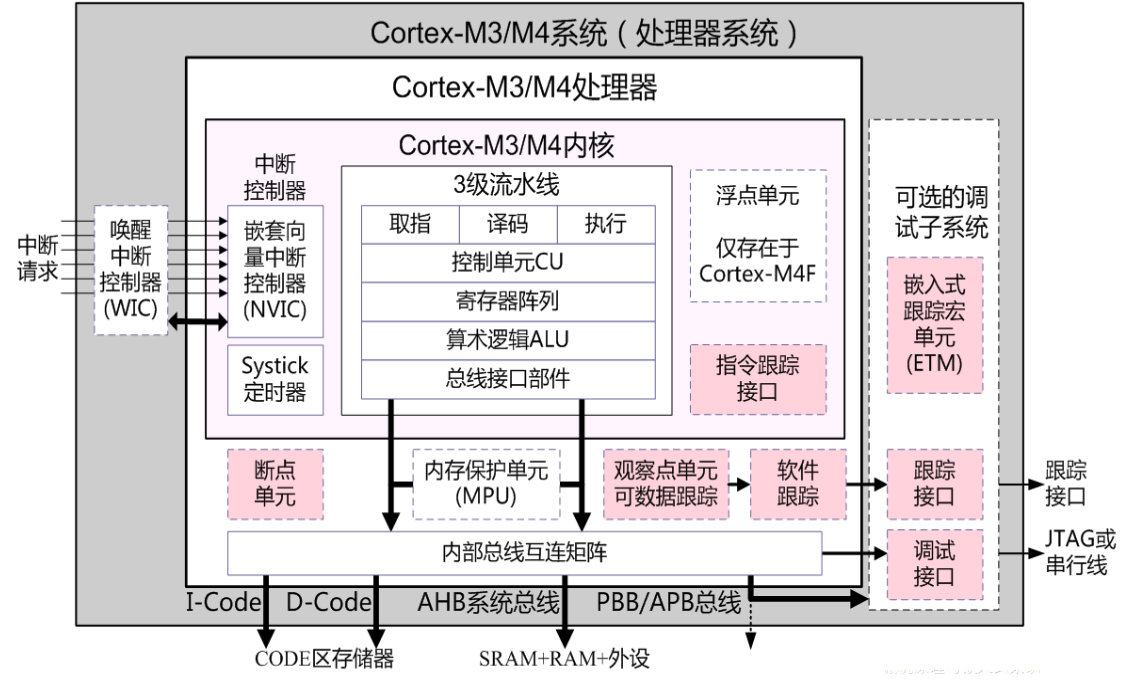
按各部件作用以及与总线系统的连接关系,整个处理器系统可以分为内核、处理器和系统三个层级
5.2.2.1. 内核
包括CPU、NVIC、Systick以及可选的指令跟踪接口
Cortex-M4内核可选配FPU
CPU
- 32位微处理器,取指、译码、执行三级流水线
- 哈佛结构,指令和数据两条总线
- 三个关键部件:ALU、控制单元CU和寄存器阵列
NVIC和Systick
- 经典ARM处理器只有9中异常类型和6级优先级

- 若IRQ不止1个,经典ARM处理器需要另配VIC
- Cortex-M系列处理器的异常/中断处理较经典ARM处理器有很大改进,内核集成了一个与CPU紧耦合的NVIC,可对大多数系统异常、所有外部中断(最多240个)以及一个NMI进行全面管理
- 此外,内核还集成了一个简单的倒计时计数器Systick,负责产生类型号为15的系统定时异常(中断)
FPU
Cortex-M4可选配FPU,支持符合IEEE 754-2008标准的单精度浮点运算,该浮点单元主要特性包括:
- 由32个32位寄存器组成的浮点寄存器组,可以单独用作32个寄存器,也可以被成对用作16个双字寄存器
- 支持的转换指令包括“整数↔单精度浮点”、“定点↔单精度浮点”、“半精度↔单精度浮点”
- 浮点寄存器组和存储器之间的单精度和双字数据的传输
- 浮点寄存器组和整数寄存器组之间的单精度数据的传输
Cortex-M4的FPU不支持双精度浮点运算、浮点余数以及二进制与十进制之间的转换,如若需要只能另外编写程序实现
Cortex-M4的浮点运算指令的助记符都是以v开头
FPU一般位于处理器内核与协处理器之间,带有状态控制寄存器,用以标明FPU当前运行状态,并可通过编程对其进行控制
为了与其他协处理器的管控方式一致,FPU被看作协处理器,并通过协处理器访问控制寄存器CPACR(Co-processor Access Control Register)对其进行管理和控制
CPACR寄存器中CP10和CP11两位负责对FPU进行管理,所以有时也将FPU看作协处理器CP10和CP11
通过对CPACR寄存器中CP10和CP11两位的置位或者复位操作,可以使能或禁用FPU
经典ARM处理器有单独的特殊寄存器访问指令MCR和MRC,实现对协处理器的操作控制和数据交换
与经典ARM处理器不同,Cortex-M4拥有专门的浮点运算和数据传送指令,实现浮点的读取、运算和写回
在Cortex-M4的三级流水线中,FPU和CPU共用取指阶段,在译码和执行阶段则二者并行执行
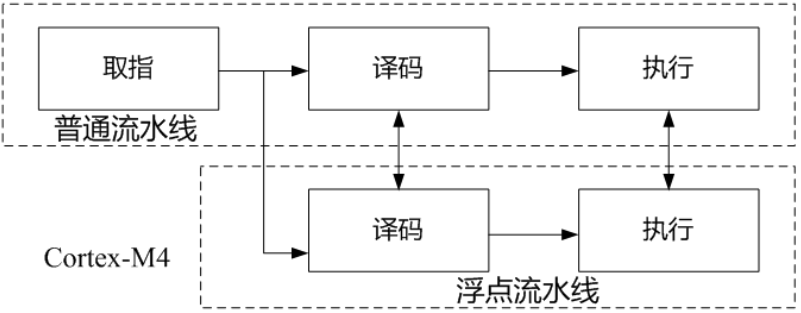
5.2.2.2. 处理器
总线交换矩阵
- 基于AHB总线协议的交换网络
- 通过总线矩阵,Cortex-M3/M4面向各种存储器、片上和片外不同类型的设备、以及调试组件提供了多条总线,可以让数据和指令在不同的总线上并行传送(只要不是访问同一个器件)
- Cortex-M3/M4的总线矩阵还包含一个写缓冲区,可以加快存储器写操作的速度
- Cortex-M3/M4处理器的系统总线基于AHB-Lite总线协议,总线上只有一个主设备,无需使用总线仲裁
MPU
- Cortex-M3/M4都可以选配
- 通过MPU可以把存储空间划分为最多8个Regina(区域),但是区域之间可以重叠
- 各个区域的存储特性和访问权限可以通过编程定义
- 如果使用了嵌入式操作系统,MPU由操作系统管理,给每个任务分配不同的存储区域以及访问权限,防止某个应用任务对操作系统或者其他任务的数据造成破坏
- 在没有操作系统的简单应用中,也可以通过MPU设定需要保护的存储区域和访问权限。例如,把某些存储空间设置为只读属性或只有特权用户才能访问,以提高系统的安全性和可靠性
5.2.2.3. 处理器系统
在处理器基础上,再选配唤醒中断控制器WIC以及若干调试组件之后,就构成Cortex-M3/M4处理器系统
WIC
为了减少功耗,Cortex-M处理器引入“睡眠”和“深度睡眠”两种模式
- 处于睡眠模式时,关闭大部分模块/部件的时钟
- 在深度睡眠模式时,系统时钟和Systick也被关闭
- 有些产品还采用了SRPG(State Retention Power Gating)电路。深度睡眠模式时包括内核和NVIC在内大部分电路都处于掉电状态,以进一步减少功率消耗
不同工作状态下的电流消耗

WIC的电路非常小巧,通过专有接口与NVIC以及电源管理单元PMU(Power Management Unit)相连
只有在处理器处于深度睡眠模式时,WIC才会使能,此时,如果出现NMI或者未被屏蔽的IRQ时,WIC触发PMU单元,将整个系统唤醒
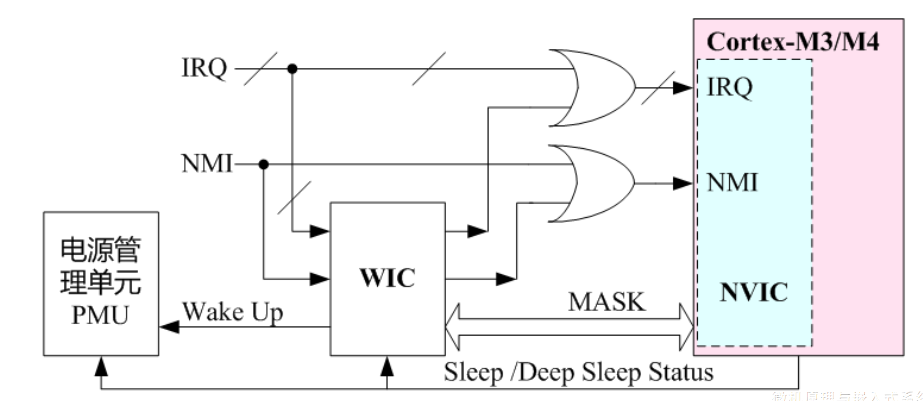
调试组件
经典ARM处理器也有多种调试组件,大都带有JTAG接口,并通过JTAG接口实现对寄存器和存储器的访问
从v7开始,ARM处理器采用了一种命名为Core Sight全新的调试架构。Core Sight调试架构涵盖了调试接口协议、调试总线协议、调试部件控制、安全特性以及跟踪接口等
在Cortex-M3/M4处理器中,调试过程是由NVIC和若干调试组件协作完成的。NVIC中有一些用于调试的寄存器,通过这些寄存器对处理器的调试动作进行控制,如停机(halting)和单步执行(stepping)等
Cortex-M3/M4可以选配多种调试组件,这些调试组件提供了指令断点、数据观察点、寄存器和存储器访问、性能分析(profiling)以及各种跟踪机制,如:
- ETM:嵌入式跟踪宏单元 Embedded Trace Macro-cell
- ITM:指令跟踪宏单元 Instrumentation Trace Macro-cell
- DWT:数据观察点和跟踪单元 Data Watchpoint and Trace
- FPB:Flash地址重载和断点单元 Flash Patch and Breakpoint Unit
- TPIU:跟踪端口接口单元 Trace Port Interface Unit
- ROM表:类似于调试组件的“注册表”
Cortex-M3/M4处理器中的调试组件
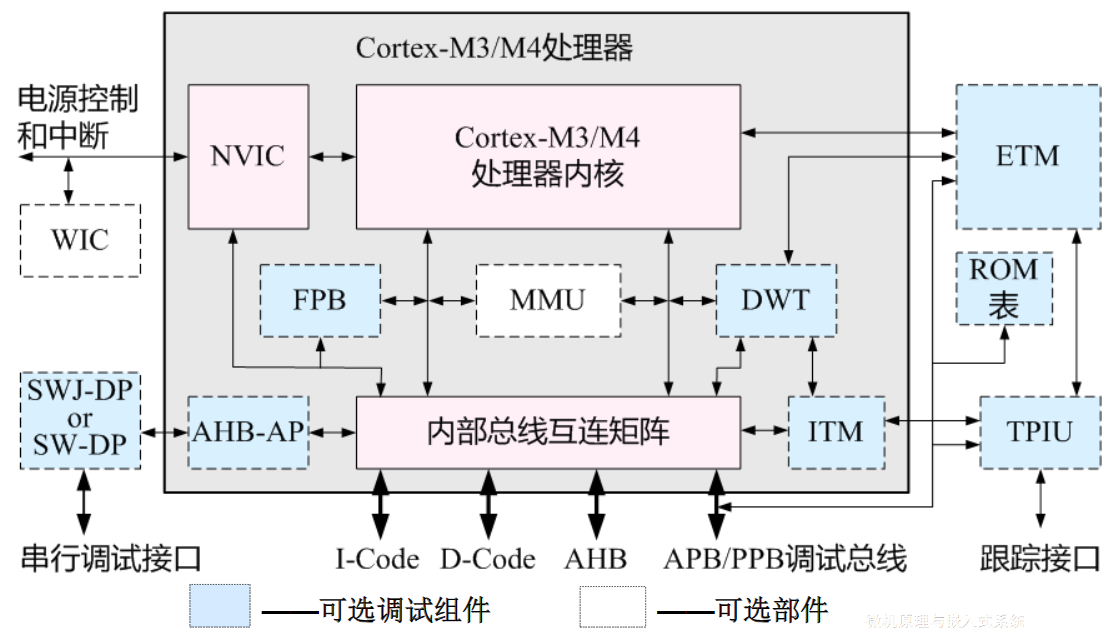
调试(Debug):是指通过调试接口读取或修改处理器内部的寄存器或存储器的内容,或者发布一些调试命令,让处理器执行某些调试动作,如暂停、单步执行或者断点执行等
跟踪(Trace):是指在程序运行期间,无需停止处理器正常的指令执行流程,由相关的跟踪组件实时收集处理器在指令执行过程中产生的各种运行信息,并通过跟踪接口实时输出到外部调试主机中,再由调试分析软件(如Keil)对这些信息进行分析
在Core Sight的调试架构中,ETM、DWT和ITM等调试组件都属于跟踪数据源(Trace Source),负责收集处理器运行过程中产生的各种调试信息
TPIU属于调试信号汇集点部件,负责将汇集的调试信息进行格式转换和打包之后,再通过跟踪端口输出到外部的调试主机(PC机)
Cortex-M3/M4处理器中的调试信息流向图:
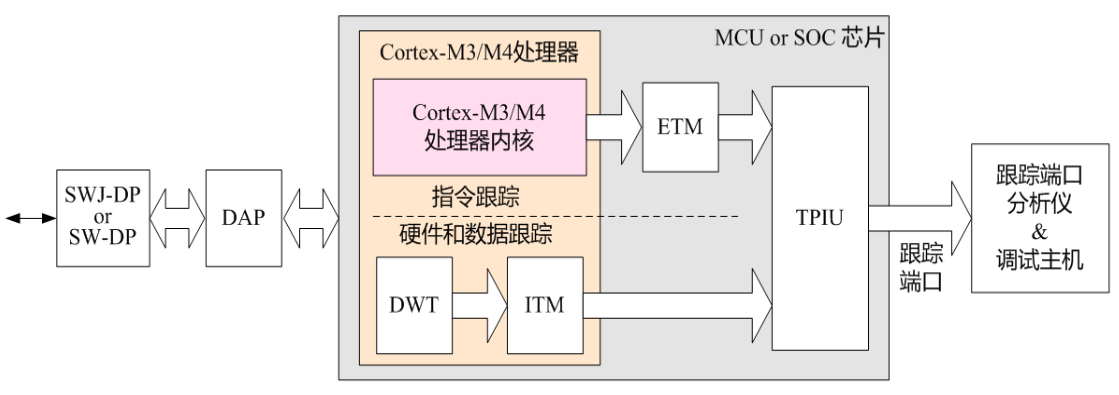
DAP(Debug Access Port)
- 在CoreSight调试架构中,定义了处理器内部的调试访问接口AP与外部调试端口DP。AP接收来自DP的调试命令,并将这些命令转换成对处理器内部各寄存器和存储单元的访问。DP和AP合称为调试访问端口
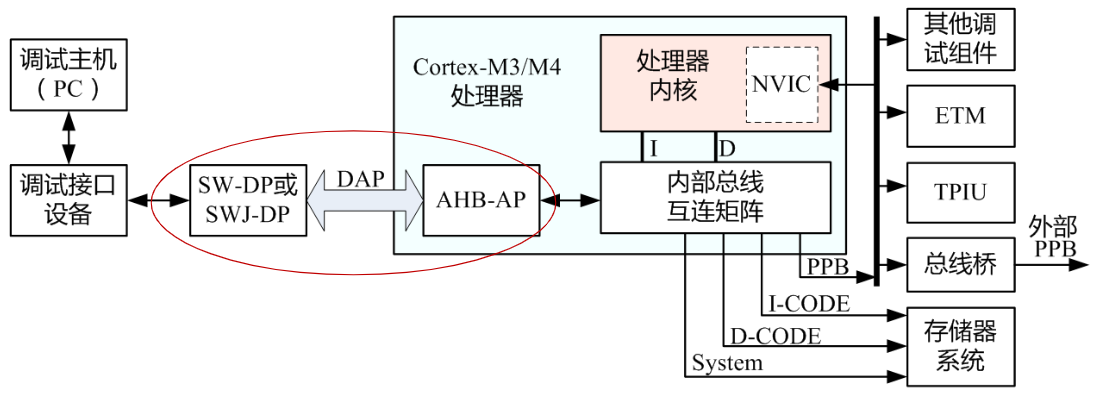
SWJ-DP和SW-DP
- SWJ-DP(Serial Wire JTAG DP):基于JTAG协议的串行调试接口,有4条线
- SW-DP(Serial Wire DP):CoreSight调试架构新增加的串行接口,只有2条线
- Cortex-M3/M4支持以上两种调试接口,芯片制造商可以根据需要选择其中的一种或者两种

5.2.3. 存储器管理
Cortex-M3/M4没有Cache或者TCM,而是通过多条总线连接片上各种不同类型和容量的存储器件
如果需要进一步扩展存储容量,还可以通过存储器接口控制器,连接片外大容量存储器
5.2.3.1. 存储器管理特性
4GB线性地址空间,可通过存储器接口控制器连接32位、16位和8位的存储器件
定义了明确的存储器映射关系,4GB存储空间被划分为多个区域,分别用于不同的存储器和外设
支持小端和大端,但芯片制造商只能选择一种类型
可选位带(Bit-Band Operations)操作,也称为位段或者位域操作
- 传统处理器中,如需修改某个存储单元或寄存器的一个bit位,而不影响其他位,需要读出、修改和写入三个步骤
- 位带操作:在某个区域内,每个bit位可以使用地址直接对其进行操作。但是具体MCU或者SOC芯片是否带有位带操作特性由芯片制造商决定
内置写缓冲,可以提高程序的执行速度
可选MPU,支持8个可编程区域,可提高系统健壮性
所有基于ARNv7M的Cortex-M系列处理器都支持非对准传送,但是非对准传送将增加总线传送次数
5.2.3.2. 存储器映射
所有基于ARMv7M的Cortex-M系列处理器,都采用相同的存储器映射关系方式(存储区域划分)
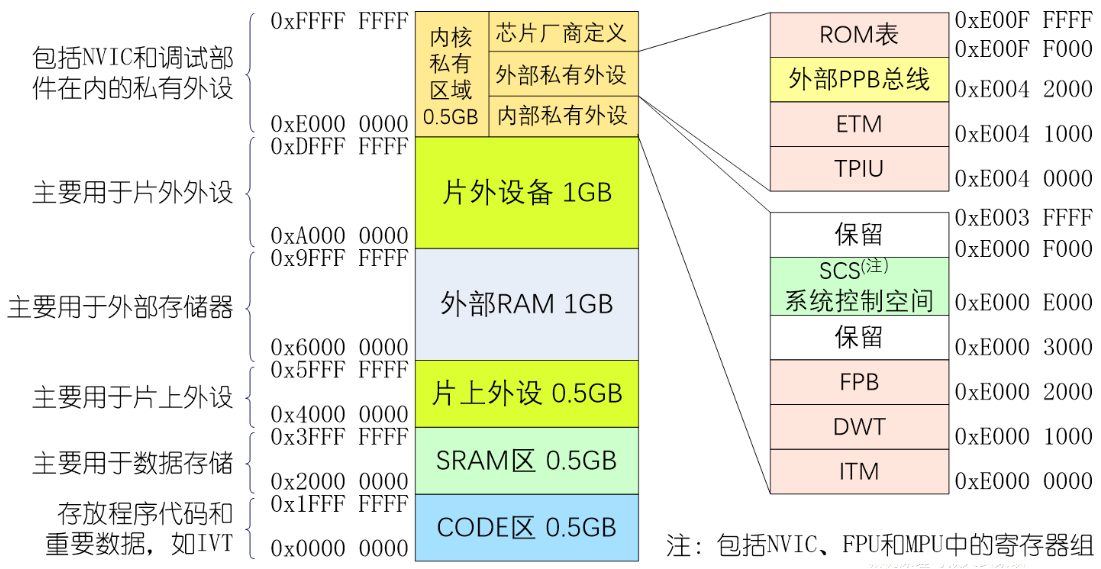
CODE区
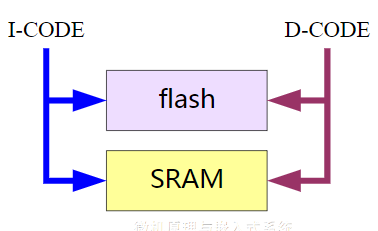
- 只能被I-Code和D-Code总线访问,为使两条总线能够同时访问,CODE区可使用两个独立的存储器
- 最低端部分使用flash器件,用于存储程序代码
- 另外一部分使用SRAM,存储重要数据I-Code和D-Code对CODE区的所有空间都能访问
- 只要不是同时访问同一个存储器,两条总线上可以同时传输数据
- 但是,为了降低成本,许多SOC芯片并没有在CODE区部署SRAM
SRAM区
- 片上主存储区,存放数据
- 由AHB-Lite系统总线管理
- 许多芯片制造商只使用SRAM区存放数据
外设区
- 片上外设连接到系统总线上
- 片外设备与APB总线相连,APB与AHB之间有一个总线桥
外部RAM区
- 通过RAM控制器连接片外扩展RAM,可使用的RAM类型取决于RAM控制器
内核私有区域
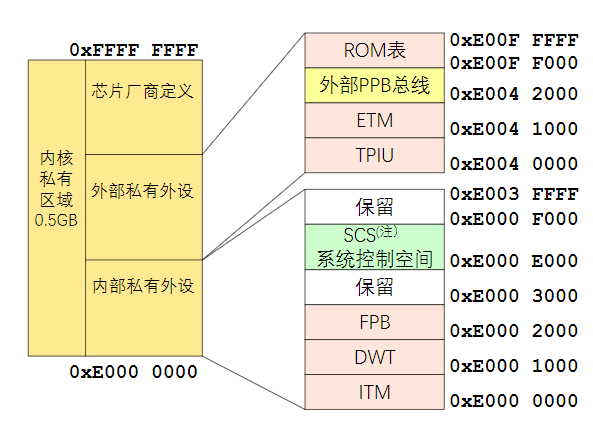
内部私有外设,包括调试组件ITM、DWT和FPB,以及系统控制区SCS
系统控制空间SCS
- 位于内核私有区域,0xE000 E000~0xE000 EFFF,64KB
- 该区域集中了NVIC、Systick、FPU和MPU等在内的各种系统部件的寄存器组,只有特权访问等级才能访问
外部私有外设,包括调试组件ETM、TPIU和ROM表,以及外部PPB总线
芯片厂商定义的存储区
Cortex M系列处理器采用这种统一的地址映射方案,有助于提高设备之间的软件可移植性和代码可重用性
虽然有明确的存储区域划分,但仍具灵活性,例如:
- 程序代码既可以存放CODE区域,也可以存放在AHB总线所连接的SRAM中,但影响指令执行性能
- 芯片制造商也可以在CODE区域使用SRAM存储器
5.2.4. 总线系统
Cortex-M3/M4总线结构
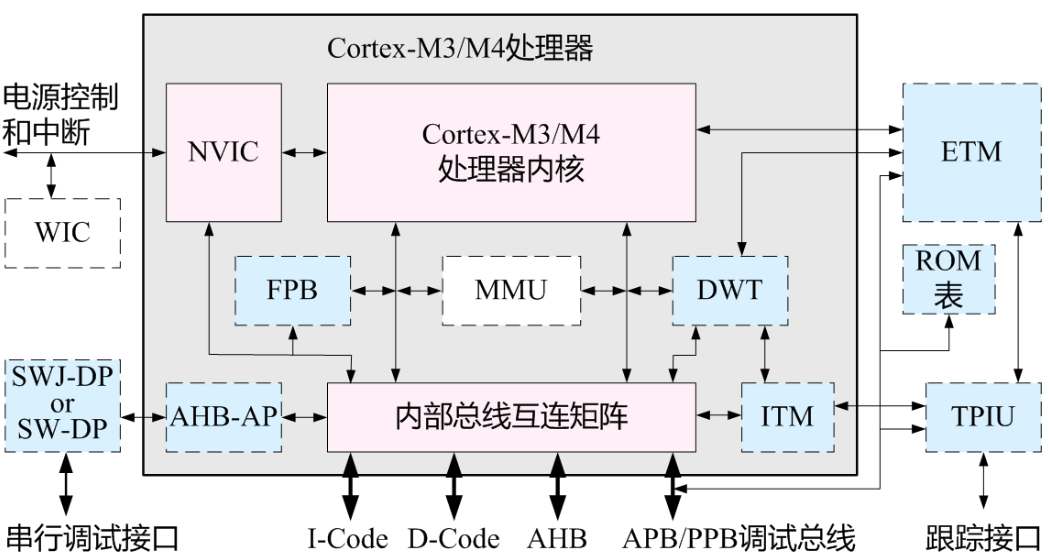
5.2.4.1. 总线系统结构
核心:基于AHB总线协议的内部总线互连矩阵。其所连接的各类总线的作用以及主要特性简介如下
- I-Code总线,基于AHB-Lite总线协议的32位总线,负责在0x0000 0000~0x1FFF FFFF之间的取指操作。取指是以字为单位,对于16位的Thumb指令,一次取指操作可以取出两条指令
- D-Code总线,与I-Code基本相同,但只负责数据读写
- I-Code总线与D-Code在物理上彼此独立,但两者之间有一个仲裁器,当I-Code和D-Code同时访问同一区域时,D-CODE优先
System,基于AHB-Lite规范的32位系统总线

访问区域
- 0x2000 0000~0xDFFF FFFF
- 0xE010 0000~0xFFFF FFFF
包括:
- SRAM区
- 片上外设
- 外部RAM
- 片外设备
- 芯片厂商定义的区域
APB/PPB总线,32位APB总线
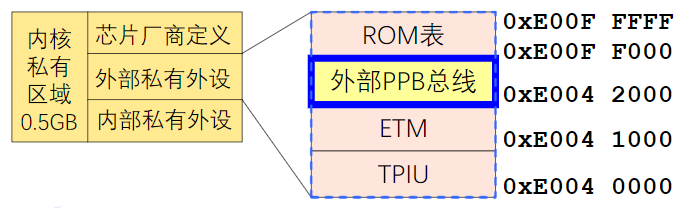
访问区域
- 外部私有外设子区域:0xE004 0000~0xE00F FFFF
- 在外部私有外设子区域中,有一部分空间已被ETM、TPIU和ROM表等调试组件所占用,只有0xE004 2000 ~0xE00F EFFF之间可用于连接外部私有设备
- 由于内核私有区域需要特权访问权限,该总线一般是专门用于连接调试组件,不用于普通的外设,否则将会出现因特权管理导致的各种错误
四条总线各自管理的区域
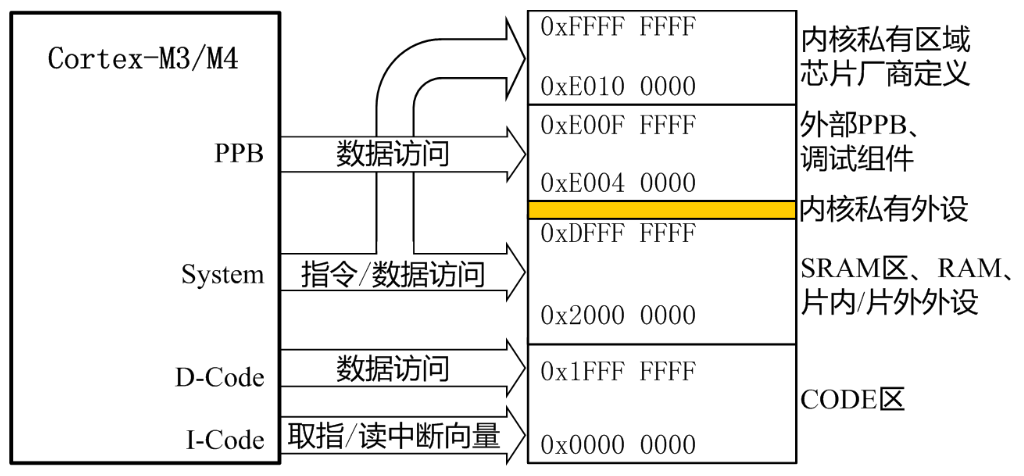
CPU通过内部总线互连矩阵直接访问内核私有外设,不经过四条总线
调试访问端口DAP
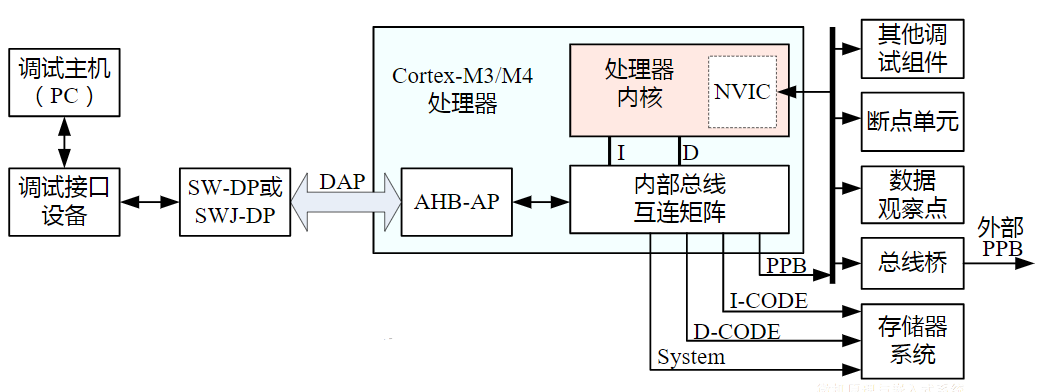
- 基于“增强型APB”总线规范的32位总线
- 主要用于连接处理器内部的调试访问接口AP与外部调试端口DP,如SWJ-DP和SW-DP
5.2.4.2. 各类总线的连接对象

AHB总线互联矩阵属于处理器内核设备
CODE区的总线矩阵或者总线复用器是ARM公司提供的两种不同的选件,其作用是让I-Code和D-Code都能够访问CODE区的flash和SRAM
- 如果选用总线矩阵,I-Code对flash的取指操作与D-Code对SRAM的数据存取操作可以同时进行
- 如果选用总线复用器,I-Code和D-Code对CODE区的访问只能分时进行,数据传送不再有具有并行性
- 有些芯片CODE区没有配置SRAM,利用SRAM区存储数据,通过系统总线与I-Code总线的并行性传送数据,虽然浪费了一点存储空间,但可以降低成本
片上SRAM也称为主SRAM,应该连接到系统总线上,使其位于SRAM区,以便可以使用位带操作
5.2.5. 异常与中断处理
5.2.5.1. 嵌套向量中断控制器NVIC
Cortex-M3/M4处理器集成了一个与CPU紧耦合的嵌套中断控制器NVIC总共可以管理:
- 240个外部中断,从IRQ#0 到IRQ#239
- 1个不可屏蔽中断NMI
- 多个系统异常
- NVIC是内核不可分割的一部分,可对240个外部中断以及大部分系统异常进行优先级设定、中断屏蔽、嵌套(抢占)管理、中断挂起(Pending)和解挂等事务进行全面并且细腻的集约化管理
支持的异常与中断处理种类
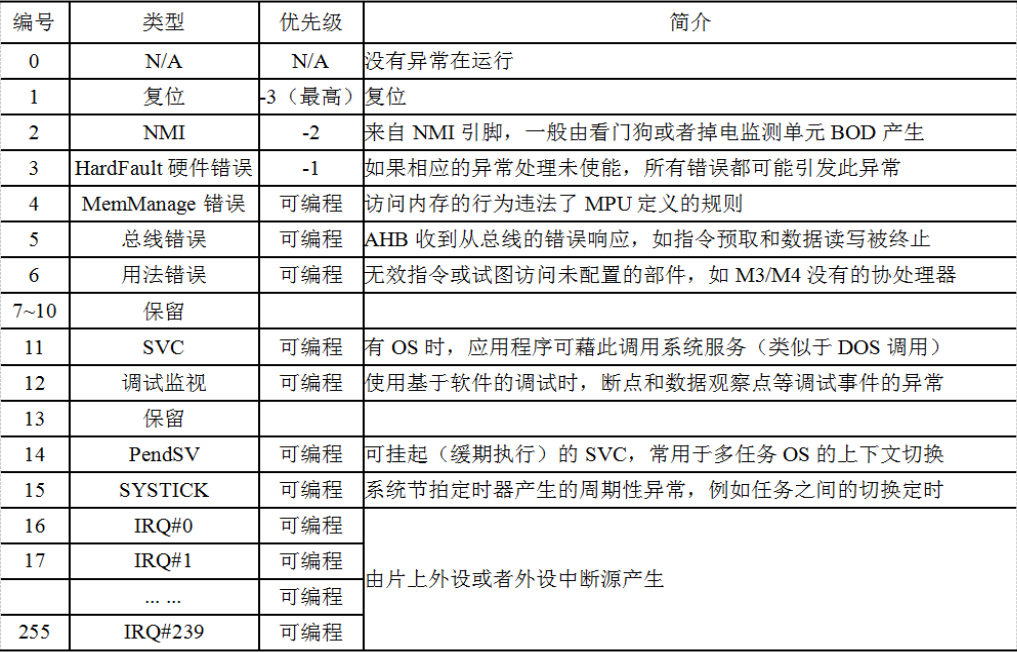
异常与中断处理
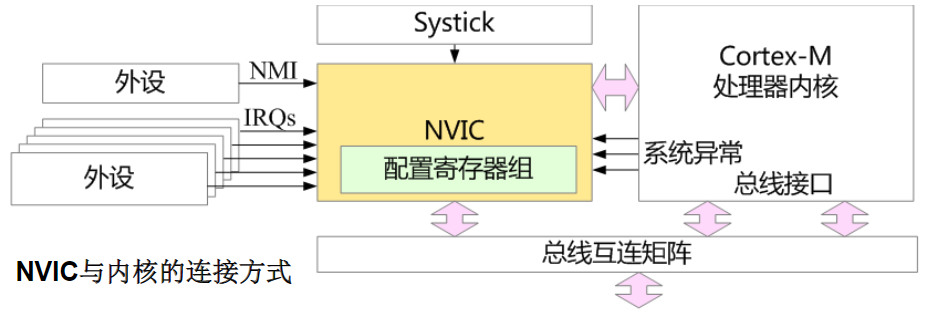
注意:CMSIS的中断编号0对应的是IRQ#0,中断编号239对应的是IRQ#239;而编号为负数的-15到-1依次对应的是复位到SYSTICK等系统异常
- CMSIS,(Cortex Microcontroller Software Interface Standard,微控制器软件接口标准),由ARM公司联合多家芯片和软件供应商合作定义,包含多个组件。其中,内核和设备访问库函数CMSIS-core提供了多种函数,可对CPU内部各种寄存器以及内核设备进行访问
配置了NVIC之后,Cortex-M3/M4具有以下异常处理特性:
除了复位和NMI之外,所有异常都可以被屏蔽
除了复位、NMI和硬件错误之外,所有异常都可单独使能或禁止
除复位、NMI和硬件错误具有固定的(高)优先级之外,所有异常/中断都具有多达256级可编程优先级,以及最多128个可抢占(嵌套)优先级
支持优先级的动态修改(Cortex-M0/M0+无此特性)
向量中断方式,中断响应时自动从中断向量表中获取中断处理程序(ISR)入口地址
向量表可以重定位在存储器中的其他区域
低中断处理延迟,对于零等待的存储器系统,中断处理延迟仅为12个时钟周期
中断和多个异常可由软件触发
可以按照优先级对中断进行屏蔽
进入中断/异常服务程序时,自动保存包括PSR在内的多个寄存器;异常返回时自动恢复,无需另外编程
可选配唤醒中断控制器WIC,支持睡眠以及深度睡眠模式
硬件自动抢占管理
- 当前正在处理的异常/中断优先级被存储专用寄存器中,如果允许抢占(嵌套),自动对新出现的异常与正在处理的异常进行比较,判断是否可以抢占
Cortex-M3/M4 和NVIC使用了多个可编程寄存器
- 可通过地址(大都在SCS区)和汇编指令对其进行访问
- 利用CMSIS-Core提供的调用函数(API)
关于中断嵌套
- 在经典ARM处理器中,所有IRQ同属一个优先级,彼此之间的中断嵌套只能通过软件编程实现
- Cortex-M3/M4最多可以设置128个可抢占(嵌套)优先级,可通过NVIC对所有的外部中断和大多数系统异常实现硬件嵌套管理,无需另外编程控制
- 当前正在处理的异常/中断优先级被存储在程序状态寄存器的专用字段中,如果允许抢占(嵌套),当出现新的异常/中断时,硬件电路自动将其可抢占优先级与当前正在处理的异常/中断进行比较,如果新异常/中断的抢占优先级更高,就会中断当前正在执行的中断服务程序,转而处理新的异常/中断,从而实现中断嵌套
5.2.5.2. 中断向量表
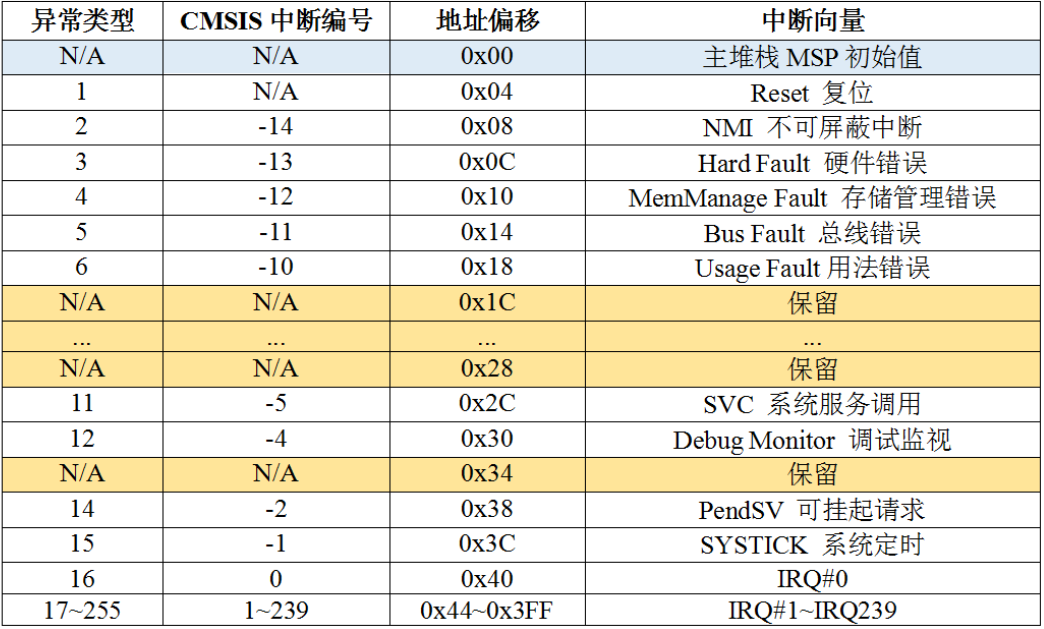
经典ARM处理器的中断向量表中还包含了跳转到中断服务程序入口的转移指令,而Cortex-M3/M4处理器的中断向量表只有异常/中断服务程序的入口地址
Cortex-M3/M4处理器的每个异常服务程序的入口地址为32位,占用4个字节
Cortex-M3/M4处理器总共有256个异常/中断异常类型,所以中断向量表的容量为4x256=1024个字节(1 KB)
中断向量表作为一类系统表,起始地址默认位于存储器空间最开始位置(地址0x0)
Cortex-M3/M4支持中断向量表
- 重定位中断向量表重定位:IVT的存放位置可以改变(relocate)
在中断响应时,若中断类型号为n,只需计算n×4(左移两位),立刻得到对应的中断向量在中断向量表中存放地址,可以快速获取中断服务程序的入口地址
中断响应时,读取中断向量以及ISR的取指操作可以与寄存器压栈操作同时进行;前者由I-Code完成,后者交由D-Code或者系统总线实现,以充分发挥哈佛结构的优势
由于中断向量表位于存储空间最开始的位置,而这片区域属于CODE区,由I-Code总线负责管理
理论上中断响应时的压栈操作可由D-Code或者系统总线完成,但是有些芯片制造商为了减少一片CODE区的SRAM,把数据都存放在由系统总线负责管理的SRAM区,这种情况下压栈操作只能由系统总线完成
5.2.5.3. 系统节拍定时器SysTick
在多任务系统中,CPU在不同的时间片为不同的任务进行进行服务,因此需要一个定时器来产生周期性的定时信号,“提醒”操作系统对任务进行切换
计算机中还有其他系统事务也需要定时信号,例如DRAM的定时刷新操作
为了支持多任务操作系统,Cortex-M系列处理器集成了一个系统节拍定时器SysTick,其作用是产生周期性的SYSTICK中断(异常号#15)
如果没有使用操作系统,SysTick定时器可以作为普通定时器使用,用于产生定时信号和进行时间测量
SysTick定时器是和NVIC捆绑在一起的,可认为是NVIC的一部分,都属于内核设备,非特权用户程序不能访问
内部有一个24位递减计数器和4个寄存器:
- 状态控制寄存器STCSR(Control and Status Reg.)
- 加载值寄存器STRVR(Reload Value Reg.)
- 当前计数值寄存器STCVR(Current Value Reg.)
- 校准值寄存器STCR(Calibration Value Reg.)
- 定时过程:SysTick被使能后,便从STRVR中的初值开始,按照时钟周期就那些递减计数,减至0后产生一个异常,在下个时钟周期又从STRVR中重新加载初值,重复递减计数过程,从而产生周期性的定时中断
- 改变STRVR的加载初值,即可改变定时周期
- 除了汇编指令外,CMSIS-Core也提供了对SysTick配置和管理的函数
5.3. Cortex-M3/M4的编程模型
所谓处理器的编程模型(Programmer’s model),就是程序员所看到的处理器的工作状态、操作模式以及以寄存器为主的各种资源
Cortex-M3/M4处理器的编程模型与经典ARM处理器有较大差别,例如:
- 以ARM7T系列为代表经典ARM处理器,具有ARM和Thumb两种工作状态,在不同的状态下有各自不同的指令系统。两种状态可以切换,但是状态切换会有一定的时间开销
- 而Cortex-M3/M4支持16位和32位指令并存的Thumb-2技术,不再有ARM和Thumb两种工作状态之分,也不再有状态切换导致的时间开销
经典ARM处理器支持以下7种运行模式:
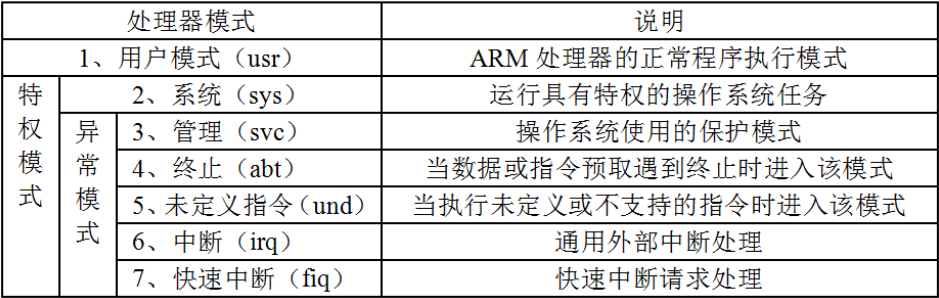
Cortex-M3/M4对这些模式进行了化简与合并
5.3.1. 操作状态与操作模式
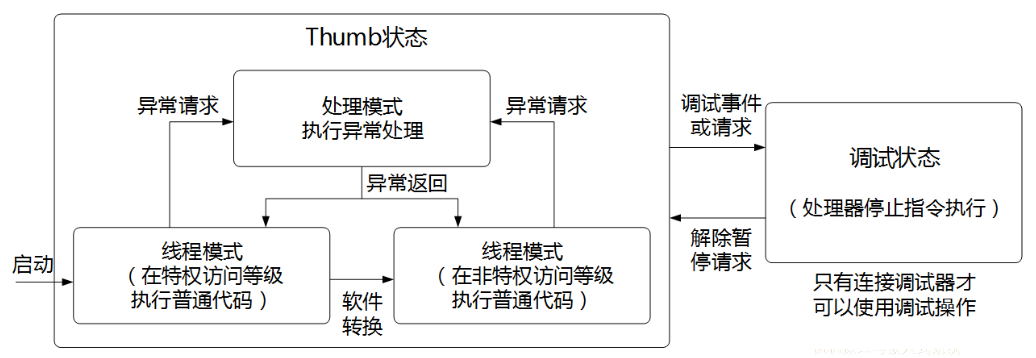
5.3.1.1. 操作状态
Cortex-M3/M4有两种操作状态,分别是:
- Thumb状态,执行Thumb指令的状态。由于Cortex-M系列处理器不支持ARM指令集,所以没有ARM状态
- 调试状态,当处理器被暂停后(例如通过调试器或触发断点后)就会进入调试状态,并停止指令执行
调试状态仅用于调试操作,可以通过两种方式进入调试状态:
- 调试器发起暂停请求
- 处理器中的调试部件产生的调试事件
在调试状态下,调试器可以访问或修改处理器中寄存器的数值
无论在Thumb状态还是调试状态下,调试器都可以访问系统存储器,包括位于处理器片内和片外的各种外设
5.3.1.2. 操作模式和特权等级
操作模式也称为处理器工作模式或者运行模式,Cortex-M3/M4把经典处理器的7种运行模式归并为两种:
- 处理模式,类似于经典处理器中的异常模式,执行的是中断服务程序(ISR),此时处理器具有特权访问等级
- 线程模式,除处理模式以外的所有模式,又分为特权线程模式(类似于经典处理器sys模式)和非特权线程模式(类似于经典处理器usr模式)
关于特权访问等级和非特权访问等级
一种最基本的安全模型,对关键区域提供必要的保护
例如:为了防止不可靠的应用任务破坏操作系统内核以及其他任务使用的存储器和外设,可以通过特权等级划分限制应用程序可访问的区域;即使是某个应用程序出现了崩溃,也不至于影响到操作系统内核和其他应用任务的继续运行
非特权与特权访问等级在编程模型方面的差异:
- 有几条指令不能使用,否则引起用法错误异常
- 不能访问内核私有区域以及由MPU设定的保护区域
- 不能访问某些特殊寄存器,如NVIC内部的各种寄存器
系统启动后处于特权线程模式,在此模式下,可以对特殊寄存器CONTRL的写操作,将处理器从特权线程模式切换到非特权线程模式
但是非特权线程模式不能访问CONTRL寄存器,因此不能采用类似方式回到特权线程模式
处理模式和线程模式的编程模型也很类似,不过线程模式可以切换使用独立的进程栈指针PSP,使应用任务的栈空间和操作系统的主栈空间相互独立,可提高系统的健壮性和可靠性
Cortex-M系列处理器启动后默认处于特权线程模式以及Thumb状态
对于简单应用,一般都使用特权线程模式和主栈指针
基于ARMv6-M版本架构的Cortex-M0处理器不支持非特权线程模式,Cortex-M0+处理器只是将其作为一个可选项
5.3.2. 常规寄存器
Cortex-M3/M4处理器种常规寄存器共有16个,其中13个为32位通用寄存器,其他3个为堆栈指针、链接寄存器和程序计数器
经典ARM处理器的寄存器:
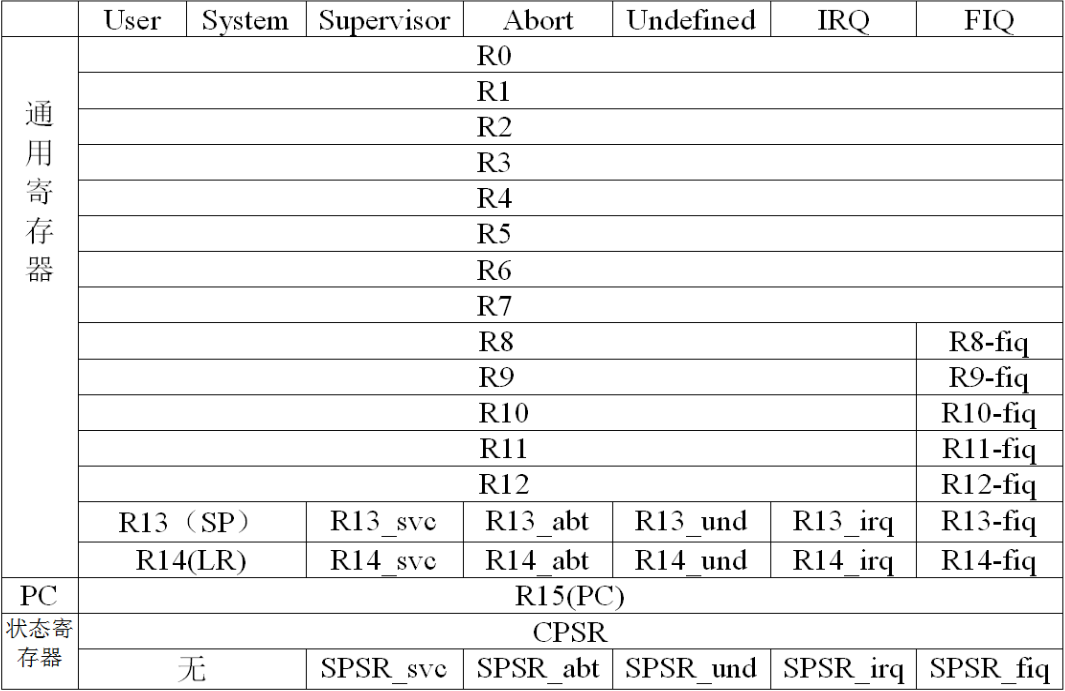
Cortex-M3/M4处理器中常规寄存器的分组
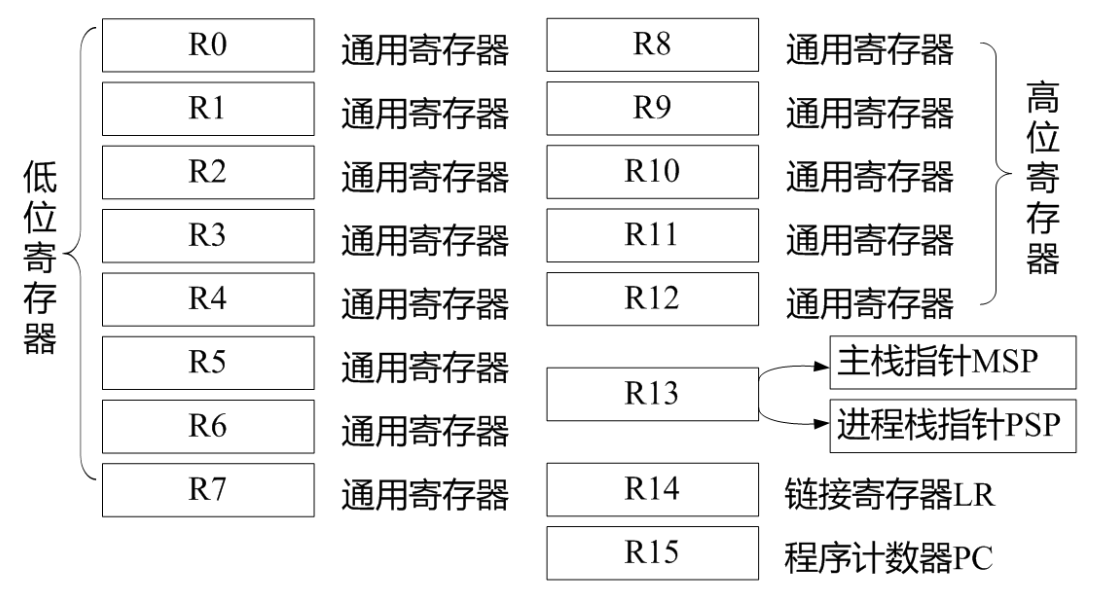
5.3.2.1. 通用寄存器:R0~R12
分为2组:
- R0~R7,8个低位寄存器,因受指令编码空间限制,许多16位Thumb指令只能访问低位寄存器
- R8~R12,5个高位寄存器,可用于32位指令和少数几个16位指令(如MOV指令)
系统复位后,R0~R12的初始值均未定义
为实现汇编程序与C语言程序的相互调用,AAPCS(ARM Architecture Procedure Call Standard)规定:
- R0~R3用于子程序之间的参数传递
- R4~R11用于保存子程序的局部变量
- R12作为子程序调用中间寄存器
5.3.2.2. 栈指针:R13
Cortex-M3/M4处理器采用双堆栈设计,有两个物理上的栈指针,也就是有两个R13寄存器,一个是主栈指针MSP,另一个是进程栈指针PSP,对于一般程序而言,两个栈指针只有一个可见
MSP为默认栈指针,在系统复位后或处理器处于处理模式时,处理器使用MSP;PSP只能用于线程模式,栈指针的选择是通过特殊寄存器CONTROL设定的
在大多情况下,对于不使用操作系统的许多简单而言,没有必要使用PSP,只需使用MSP即可
系统复位之后,PSP的初值未定义,而MSP的初值存放在整个存储空间最开始(中断向量表)处第一个字中,在系统初始化时,需要将其取出并对MSP进行赋值
尽管v8版架构之前的ARM处理器都是32位的,PUSH和POP操作也是以字为单位进行的,堆栈采用字(4字节)对齐方式即可
考虑到64位双精度浮点数的压栈问题,AAPCS规范要求堆栈应该采用双字(8字节)对齐方式
在Cortex-M3/M4处理器中,通过对系统控制块SCB(System Control Block)中的配置控制寄存器CCR(Configuration Control Register)进行操作,可以使能或禁止双字栈对齐特性
无论是采用字对齐还是双字对齐,MSP和PSP的最低两位总是为00,对这两位的写操作不起作用
5.3.2.3. 链接寄存器:R14
用于保存函数或子程序调用时的返回地址,在函数或子程序结束时,LR中的数值用于调用返回
在异常处理时,LR中将自动保存返回地址EXC_ RETURN,异常处理结束用于异常/中断返回
如果是嵌套调用,调用时需将LR中的数值压栈保存
由于Cortex-M3/M4中有16位指令,指令有时会对齐到半字地址,即便如此,返回地址总是偶数,LR的最低位默认为是0
- 但LR第0位可读可写,有些转移/调用操作将LR的第0位置1以表示Thumb状态。但是作为返回地址,无论最低位是0还是1,总是认为最低位是0
5.3.2.4. 程序计数器:R15
在基于x86处理器的PC机中,不允许对代码段寄存器CS以及指令指针IP进行写操作,CS和IP不能作为数据传送和数据处理指令的目的操作数,程序转移或者过程调用只能通过专门的指令来实现
但是在ARM处理器中,PC不仅可读而且可写
- 读PC时返回的是当前指令地址加4,这是因为流水线的特性以及与ARM7T系列处理器兼容的需要
- 对PC的写操作可以使用MOVE指令以及数据处理指令来实现,以实现程序的跳转
- 在大多数情况下,跳转和调用操作都通过专用指令实现,利用数据传输和数据处理指令更新PC的情况较为少见
- 在访问位于程序存储器中的字符数据时,经常将PC作为基地址寄存器,而偏移地址由指令中的立即数给出
在Cortex-M3/M4中,由于指令必须对齐半字或字,作为代码地址,PC的最低位总是认为是“0”
需要注意的是,无论使用跳转指令还是直接写PC寄存器,写入值必须是奇数,确保其最低位是“1”,以表示其处于Thumb状态,否则将被认为试图转入ARM模式,从而导致出现错误异常
当使用高级编程语言(包括C和C++)时,编译器会自动将跳转目标的最低位置“1”,无需担心出错
再次强调:PC最低位为“1”,只是表示处于Thumb状态,作为指令地址,PC最低位始终被认为是“0”
关于寄存器的名称
使用ARM汇编指令编程时,在汇编代码中出现的上述寄存器可以使用不同的名称,如大写、小写或者大小写混用,常用的汇编工具(如Keil MDK-ARM和ARM ADS)都能对其进行识别
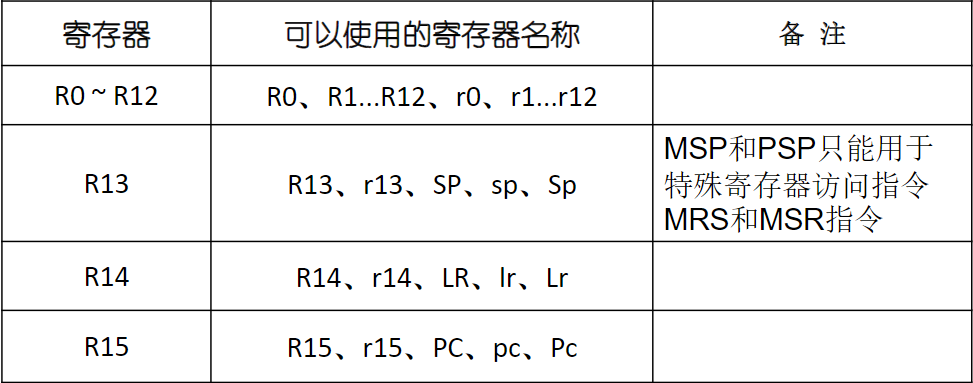
5.3.3. 特殊寄存器
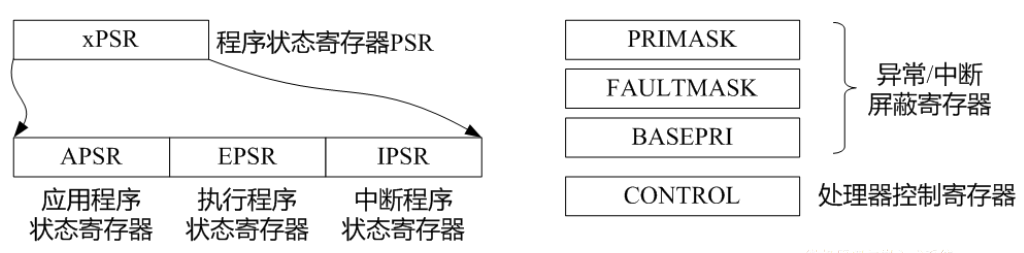
除了常规寄存器,Cortex-M3/M4处理器中,还有多个特殊寄存器,分别是:
xPSR:程序状态寄存器,包括:
- APSR:应用程序状态寄存器
- EPSR:执行程序状态寄存器
- IPSR:中断程序状态寄存器
PRIMASK
FAULTMASK
BASEPRI(以上三个均为中断屏蔽设置寄存器)
CONTROL 控制寄存器,定义处理器的操作状态
特殊寄存器没有映射到内存空间,只能利用MSR/MRS指令通过名字对其进行访问,例如:
xxxxxxxxxxMRS <reg>, <special_reg> ;读special_reg到通用寄存器regMSR <special_reg>, <reg> ;将reg内容写入special_reg
注意特殊寄存器与“特殊功能寄存器(SFR)”的区别,后者一般用于I/O控制的寄存器
CMSIS-core也提供了用于访问特殊寄存器的函数。在使用C或C++等高级开发简单应用时,可能不太需要这些特殊寄存器;如果开发需要在嵌入式操作系统环境下运行的应用程序,并且需要高级中断屏蔽特性时,就需要访问这些特殊寄存器
5.3.3.1. 程序状态寄存器
在ARM7TDMI为代表的经典ARM处理器中,采用了CPSR和SPSR两个程序状态控制器。CPSR保存当前程序状态,SPSR用于在异常/中断处理时保存CPSR的状态,以便异常返回后能够恢复处理器的工作状态
从ARMv7版架构开始,ARM采用了新的程序状态寄存器PSR,读取PSR的结果实际包含了APSR、EPSR和IPSR三个状态寄存器内容,因此,有时也将PSR称为xPSR(表中GE[3:0]只有Cortex-M4中有)

PSR中各个标志位的含义如下:
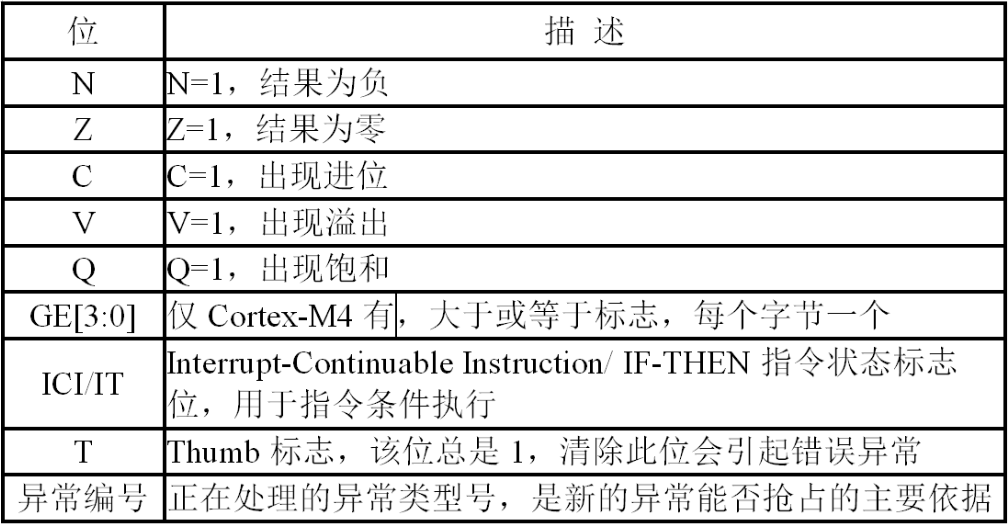
Cortex-M3/M4的PSR与经典ARM处理器的CPSR有较大差异,下图给出几种ARM处理器PSR的对比:
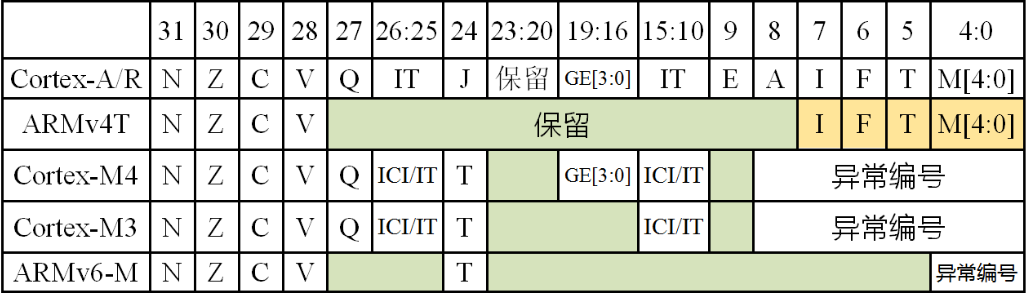
与ARM7TDMI的CPSR相比:
- 取消了反映工作模式的M[4:0]位
- T标志位的位置发生变化
- 中断标志I和F被新的PRIMASK所取代
5.3.3.2. 三个中断屏蔽寄存器
PRIMASK、FAULTMASK和BASEPRI三个寄存器的用途是为了实现基于优先权等级的异常/中断屏蔽
关于Cortex-M3/M4处理器的异常优先级:
- 复位、NMI和Hard Fault硬件错误三个系统异常具有固定的优先权等级
- 复位优先权等级为-3,数字最小,具有最高优先权
- NMI优先权等级为-2,优先权等级仅次于复位
- 硬件错误优先权等级为-1,优先权等级排行第三
- 除了上述三个系统异常之外,其它所有异常和中断的优先级均可编程设置,优先权等级数值范围从0~255,数值越小,优先级越高;反之优先权越低
下图为三个中断屏蔽寄存器的编程模型,可以看出PRIMASK和FAULTMASK都只有一位

PRIMASK
- 当最低位被置位(写入1)后,将屏蔽除复位、NMI和硬件错误以外所有的(优先级数值大于0的)系统异常和外部中断,类似于x86系统中的关中断(IF=0),以便处理紧急事务
- 当紧急事务处理完毕,要及时将PRIMASK的最低位进行复位,类似于x86系统的“开中断”
FAULTMASK
- 当最低位被置位后,硬件错误异常也被屏蔽,相当于把异常/中断的优先级门槛提高到“-1”
- 常用于执行负责错误处理的中断服务程序。因为既然出现了错误并且正在处理,就无需理会此刻出现的包括硬件错误在内的其他异常(只有几种),以便错误处理程序能够“专心致志”地进行错误修复
- 与PRIMASK不同的是,FAULTMASK无需主动清理,当错误处理程序运行结束返回时,会自动复位FAULTMASK
- FAULTMASK是ARMv7-M版架构引入的,Cortex-M0系列处理器没有FAULTMASK寄存器
BASEPRI
也是ARMv7-M版架构新增的,可以按照具体优先数值对中断屏蔽进行管理
BASEPRI寄存器的最低8位采用了“可伸缩”设计,具体宽度取决于芯片制造商实际设计的中断优先级数量
一般而言,芯片制造商设计的中断优先级不少于8级,此时BASEPRI中7:5这3位用于设置中断屏蔽
如果设计了32级中断,BASEPRI的宽度为7:3共5位,假如7:3这5位的数值是0b1 0000,将屏蔽优先级数值大于等于0b1 0000的所有中断
如果7:3这5位的数值是0 0000,其含义则是对所有中断都不屏蔽
中断屏蔽寄存器属于特殊寄存器,只有特权访问等级才可以进行读写访问。非特权状态下的写操作会被忽略,而读操作返回数值为0
使用汇编指令访问三个中断屏蔽寄存器示例:
xxxxxxxxxxMRS r0, BASEPRI; 将BASEPRI寄存器读入R0MRS r0, PRIMASK; 将PRIMASK寄存器读入R0MRS r0, FAULTMASK; 将FAULTMASK寄存器读入R0MSR BASEPRI, r0; 将R0写入BASEPRI寄存器MSR PRIMASK, r0; 将R0写入PRIMASK寄存器MSR FAULTMASK, r0; 将RO写人FAULTMASK寄存器中断设置示例:
x;关中断命令MOV R0, #1MSR PRIMASK, R0;开中断命令MOV R0, #0MSR PRIMASK, R0;假设系统中共有16级中断,BASEPRI寄存器的宽度;为7:4共4位,现在需要屏蔽优先级大于等于4的所有中断MOV R0, #0b100MSR BASEPRI, R0;取消BASEPRI寄存器的中断屏蔽设置MOV R0, #0MSR BASEPRI, R0CMSIS-Core提供的访问函数:
xxxxxxxxxxx = _get_BASEPRI(); //读BASEPRI寄存器x =_get_PRIMARK(); //读PRIMASK寄存器x =_get_FAULTMASK(); //读EAULTMASK寄存器_set_BASEPRI(x); //设置BASEPRI的新数值_set_PRIMASK(x); //置位PRIMASK_set_FAULTMASK(x); //置位FAULTMASK_disable_irq(); //置位PRIMASK,禁止异常,//相当于_set_PRIMASK(1)_enable_irq(); //清除PRIMASK,使能异常,//相当于_set_PRIMASK(0)利用修改处理器状态CPS指令,也可以方便地设置或清除PRIMASK和FAULTMASK的数值,例如:
xxxxxxxxxxCPSIE I; 使能异常(清除PRIMASK位)CPSID I; 禁止异常(置位PRIMASK位)PSIE f; 使能异常(清除FAULTMASK位)CPSID f; 禁止异常(置位FAULTMASK位)对比上述指令,可以看出来
- PRIMASK类似于经典ARM处理器CPSR中的“I”标志位,置位后禁止IRQ中断
- FAULTMASK类似于经典ARM处理器CPSR中的“F”标志位,置位后禁止FIQ中断
5.3.3.3. CONTROL寄存器
用于选择线程模式的特权访问等级以及栈指针
Cortex-M3/M4和Cortex-M0/M0+的CONTROL寄存器的编程模型如下图所示
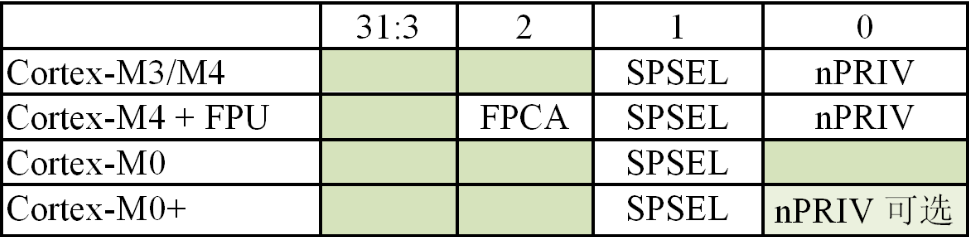
- Cortex-M3/M4都只有SPSEL和nPRIV两位,配置了FPU的Cortex-M3/M4增加了一位FPCA
- Cortex-M0没有nPRIV ,Cortex-M0 M0+只是选项
CONTROL寄存器各位的含义:
nPRIV:设置线程模式的特权访问等级,该位为0/1,处理器进入特权线程模式/非特权线程模式
SPSEL:选择线程模式中的堆栈指针
- 当该位为0时,线程模式使用主栈指针MSP
- 当该位为1时,线程模式使用进程栈指针PSP
- 在处理模式下,该位始终为0,并且忽略对其的写操作
FPCA:配置FPU的Cortex-M4才有此位。当发生异常时,若该位为1,浮点单元中的寄存器内容被压栈保存。执行浮点指令时FPCA位自动置位,在异常处理程序入口处该位被硬件自动清除
复位后,CONTROL寄存器被恢复成默认值0
- 这意味着复位之后,处理器处于线程模式、具有特权访问等级、并且使用主栈指针
- 在特权线程模式下,可以通过写CONTROL寄存器进入非特权线程模式
- 不过,当CONTROL寄存器的最低位nPRIV位被置位后,非特权线程模式下不能继续访问CONTROL寄存器了,也无法再切换回特权线程模式了
- 如果需要将非特权线程模式切换回特权线程模式,只能借助于异常处理。处理模式具有特权访问等级,可以清除nPRIV位,再在从异常返回线程模式后,处理器就进入特权线程模式
特权线程模式与非特权线程模式的切换过程:
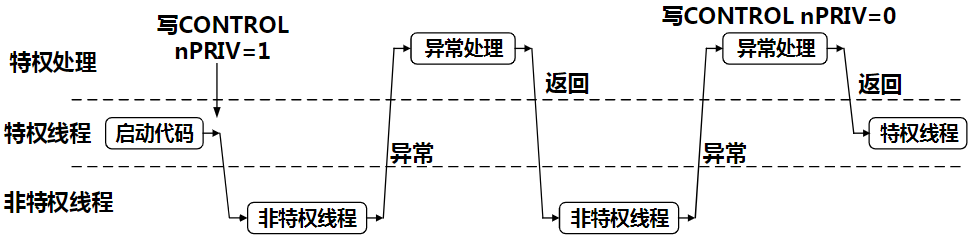
对于简单应用,可以一直运行在特权线程模式下,无须修改CONTROL寄存器的数值,并且只使用MSP

5.3.3.4. 系统控制块SCB
系统控制块SCB是由多个寄存器组成的一个数据结构,属于Cortex-M3/M4内核的一部分并被综合到NVIC中
SCB中各类寄存器的作用包括:
- 对处理器进行配置。如之前所述的双字栈对齐使能控制,以及低功耗模式设置等
- 提供错误状态信息。SCB中包含多个反映不同类型错误的状态寄存器
- 异常和中断管理。例如异常的挂起与解挂控制、优先级设置和优先级分组以及中断向量表的重定位
- 有多个反映处理器特性、指令集特性、存储模块特性以及调试特性的只读寄存器
- 对于配置了FPU的Cortex-M4处理器,还有一个协处理器访问控制寄存器
SCB的各类寄存器被映射到SCS中,地址范围:0xE000 ED00 ~ 0xE000 ED88
如果使用汇编语言,只能通过地址访问这些寄存器
但是CMSIS-Core为每个寄存器分配了一个符号,类似给这些寄存器赋予一个名称,例如:
- 中断控制和状态寄存器:SCB->ICSR
- 系统控制寄存器:SCB->SCR
使用C语言并利用CMSIS-Core定义的这些符号,可以更方便地对SCB中的各个寄存器进行访问
5.3.4. 堆栈结构
5.3.4.1. 堆栈的作用和堆栈类型
堆栈简介
- 堆栈是一种特殊的数据结构,是一种只能在一端进行插入和删除操作的线型表
- 堆栈的数据存取操作按照“后进先出(LIFO)”的原则,并通过堆栈指针指示当前的操作位置
- 压栈指令PUSH向堆栈中增加数据,出栈指令POP指令从堆栈中提取数据
- 每次PUSH和POP操作后,当前使用的堆栈指针都会自动进行调整
- 在32位系统中,堆栈操作至少是以字为单位,所以堆栈至少应该做到“字对齐”(在Cortex-M系列处理器中,为了遵守AAPCS的规范,堆栈需要采用双字对齐)
堆栈的作用
在异常/中断响应时,保存被中断程序的下一条指令的地址,以及处理器状态寄存器的内容(保护断点),以便在异常/中断返回后,处理器能够从断点处继续运行
异常/中断服务程序,或者正在执行的函数或者子程序如果需要使用某些寄存器,可以使用堆栈保存这些原来的内容(保存现场),以便异常返回或者函数或子程序处理结束时可以恢复现场
实现主程序与函数或者子程序之间的参数传递
- 函数或者过程调用有多种参数传递方式,堆栈传递是一种最安全的方式,并且对参数数量几乎没有限制
用于存储局部变量
堆栈的类型
按照堆栈区在存储器中的地址增长方向,可分为:
- 递增栈(Ascending Stack):向堆栈写入数据时,堆栈区由低地址向高地址生长
- 递减栈(Descending Stack):向堆栈写入数据时,堆栈区是由高地址向低地址生长
按照堆栈指针SP所指示的位置,又分为:
- 满堆栈(Full Stack):堆栈指针SP始终指向栈顶元素,也就是指向堆栈最后一个已使用的地址
- 空堆栈(Empty Stack):SP始终指向下一个将要放入元素的位置,也就是指向堆栈的第一个没有使用的地址或者空位置
组合上述两种地址增长方向和两种堆栈指针指示位置,可以得到4种基本堆栈类型:
- 满递增(FA):SP指向最后压入的数据,且由低地址向高地址生长
- 满递减(FD):SP指向最后压入的数据,且由高地址向低地址生长
- 空递增(EA):SP指向下一个可用空位置,且由低地址向高地址生长
- 空递减(ED):SP指向下一个可用空位置,且由高地址向低地址生长
5.3.4.2. Cortex-M处理器的堆栈模型
许多经典ARM处理器及ARM T32指令集可支持四种堆栈类型,但是,Cortex-M系列处理器只能使用满递减(FD)类型
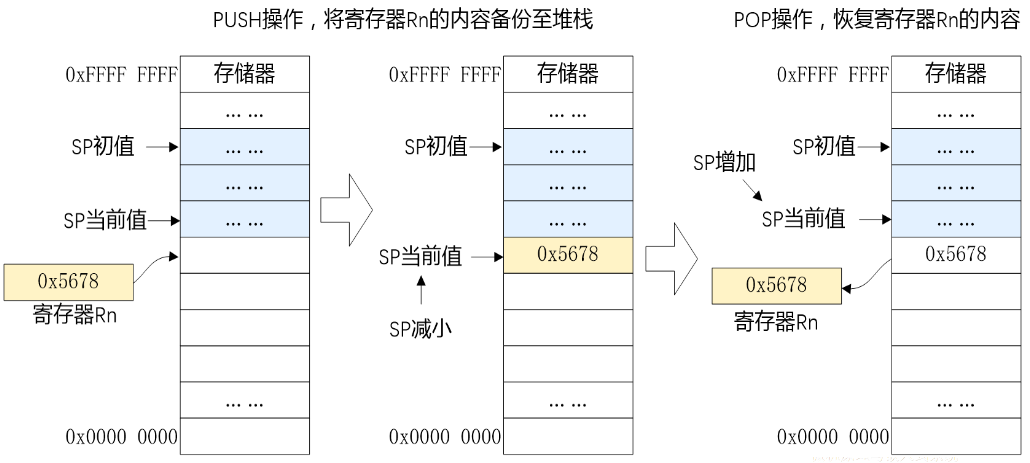
处理器在启动或者复位后,系统初始化程序从位于内存最开始处的flash中,取出地址为0x0000 0000的第一个字,作为主栈指针MSP的初始值
每次PUSH操作时,处理器将SP的值减去4,然后将需要压栈保存的数据存储在SP指向的位置
每次POP操作,SP所指向的存储器数据被读出,然后SP的数值自动加4,指向POP之后新的栈顶位置
- 出栈后,原来存放在堆栈中的数据依然存在,但无需理会,因为随后可能出现的PUSH操作将会将其覆盖
PUSH和POP操作应“匹配”,防止“张冠李戴”导致系统混乱甚至崩溃
如果Cortex-M3/M4处理器使能了双字栈对齐模式,当出现异常时,假如压栈操作之后堆栈指针没有对齐到双字边界,将如何处理?
- 处理器会自动插入一个“空”字,强制堆栈对齐在双字边界上。同时,已经入栈保存的xPSR寄存器的第9位(未使用)被置为1,表示堆栈指针发生过调整
- 出栈时硬件电路对xPSR第9位进行检查,若为1则说明最后入栈的字是为了双字对齐插入的,应将其丢弃
- 虽然双字对齐可能会造成堆栈空间的一点点浪费,但是为了提高软件的标准化程度以及便于程序之间的相互调用,建议使用双字对齐模式
5.3.4.3. Cortex-M3/M4处理器中的双堆栈
Cortex-M3/M4的双堆栈设计有MSP和PSP两个堆栈指针,分别服务于不同的操作模式和特权访问等级
CONTROL寄存器中nPRIV和SPSEL的不同组合,两个堆栈共有4种场景,其中前三种比较常见

如果使用双堆栈,应通过MPU在SRAM中建两个区域
- 一个定义为特权级,其中一部分用作主栈存储区
- 另一个定义为非特权级,其中一部分用于进程栈
Cortex-M3/M4的堆栈是满递减类型,因此两个栈指针的初始值应该是两个区域的最大地址
如果采用双字对齐,栈顶应位于双字边界上,MSP和PSP最低3位为000
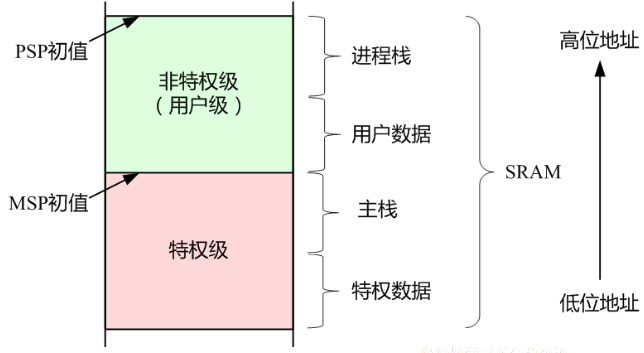
Cortex-M系列处理器的堆栈空间一般位于系统主存储器SRAM区(也可以放置在CODE区中通过D-Code总线的连接的SRAM中)
用于堆栈的存储区需要事先做好规划,预留足够的空间,以防出现堆栈溢出
MSP的初始值事先存放在0x0000 0000处,该位置通常位于I-Code总线所连接的flash中,系统上电或者复位之后,系统初始化程序完成MSP的初始化
PSP的初始化需要另外编程实现,PSP的初始化宜使用汇编指令代码,简单高效而且不易出错
示例:
xxxxxxxxxxBL Mpusetup ;调用MPU设置子程序,建立region,并使;能存储器保护LDR r0, =PSP_TOP ;读取进程栈栈顶MSR PSP, r0 ;初始化进程栈指针MOV r0,#0x3 ;准备置位CONTROL寄存器的SPSEL和;nPRIVMSR CONTROL, r0 ;完成CONTROL寄存器的更改,切换到;非特权线程模式B UserAppStart ;已进入非特权线程模式,跳转到用户;程序入口
5.4. Cortex-M处理器存储系统
5.4.1. 存储器映射
所有基于ARMv7M的Cortex-M系列处理器,都采用相同的存储器映射关系方式(存储区域划分)
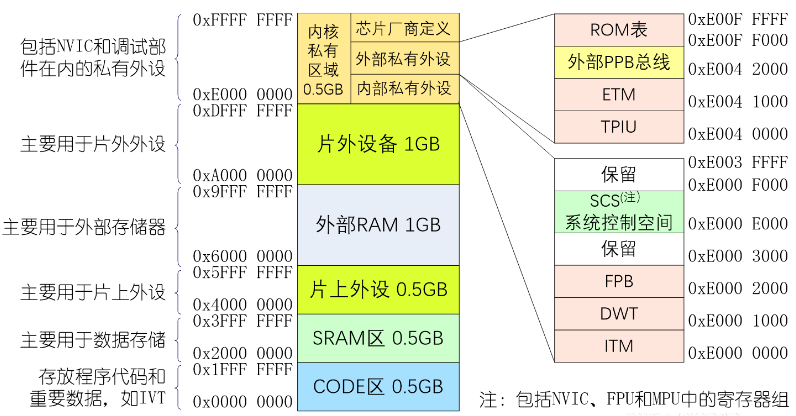
位段区
Cortex-M3/M4在SRAM区和片上外设区,各有一个位段区和位段别名区
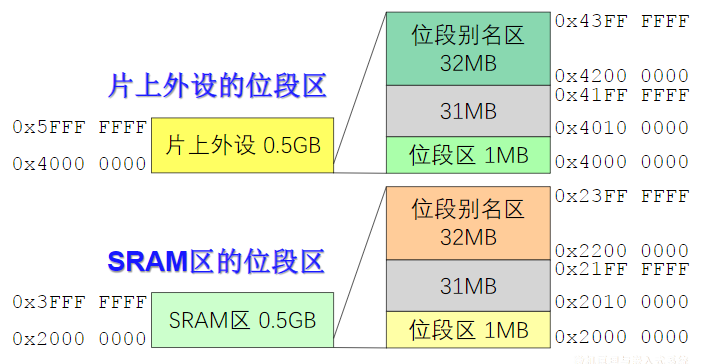
系统控制区SCS
4KB,早期归属于NVIC,所以也称为NVIC区
除NVIC以外,SCS还映射了SysTick、MPU、SCB和FPU等部件的寄存器
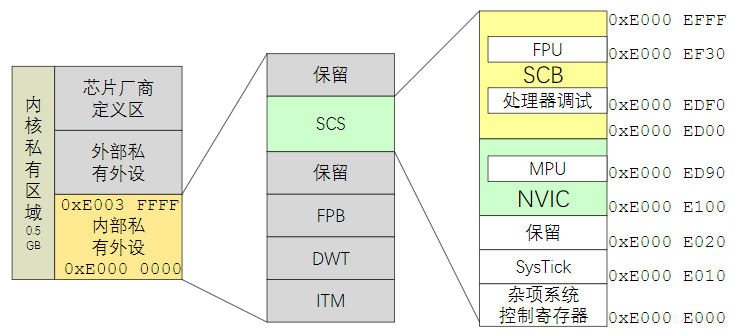
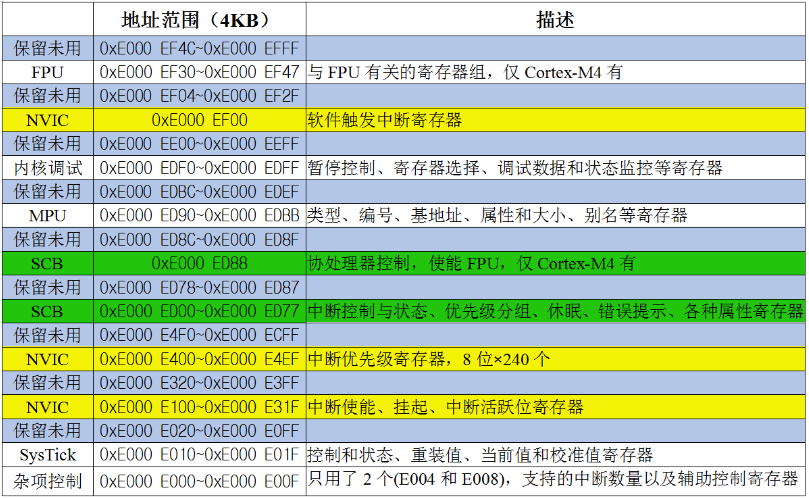
不同存储器区域的用途

5.4.2. 连接存储器和外设
为提高性能,CODE区使用专门的I-Code和D-Code总线,I-Code、D-Code和系统总线可以并行执行
该结构也会加快中断响应速度,中断响应时,读取中断向量、取指和压栈操作可以同时执行
此外,一些芯片制造商也会在MCU中增加自行设计的Flash访问加速器
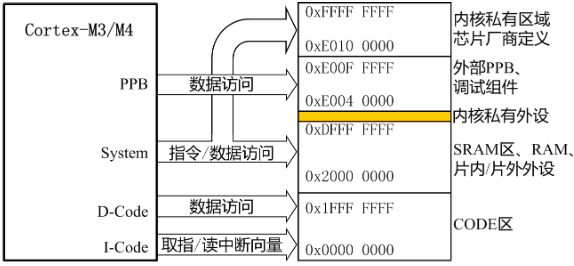
示例:Flash访问加速器
意法半导体(ST Microelectronics)的STM32F2(基于Cortex-M3的微控制器)和STM32F4(基于Cortex-M4的微控制器),在I-Code和D-Code总线接口处实现了Flash访问加速器
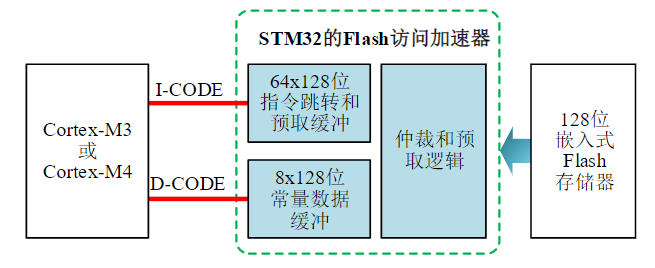
总线矩阵示例:NXP公司LPC1700
AHB Lite协议仅适用于单主控设备的情形,有些产品用“总线矩阵”或“多层AHB”等术语来描述芯片内部支持多主控设备总线系统。对多主控设备的支持未在AHB Lite协议中定义
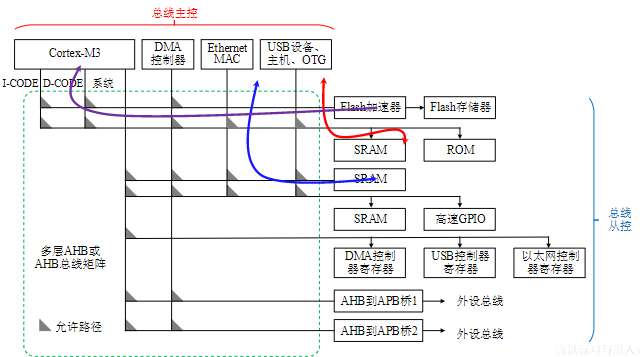
5.4.3. 存储器的端模式
网路传输、文件存储均有大端小端问题
在C语言下如果使用指针也需要注意大小端的问题
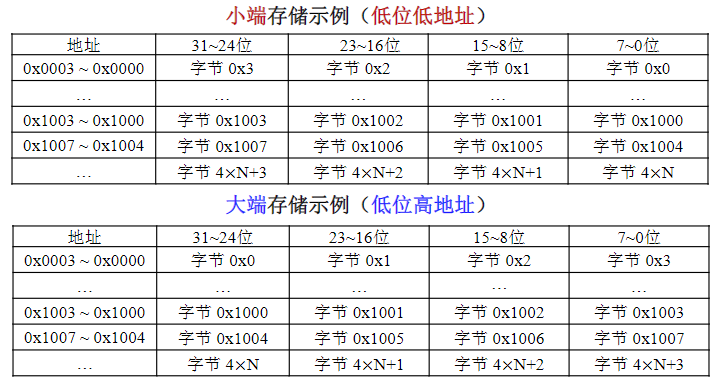
Cortex-M3/M4支持两种端模式
大端:字节不变大端和字不变大端
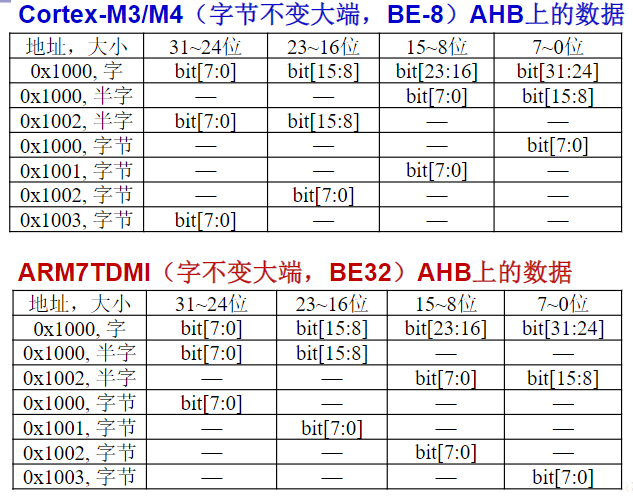
区别:数据传输时字节通道不同。字节通道指高低字节与总线上高低位数据线的映射关系,字节通道与存储系统设计相关
Cortex-M缺省支持小端模式
小端模式下,Cortex-M3/M4和经典ARM处理器的字节通道都是相同的
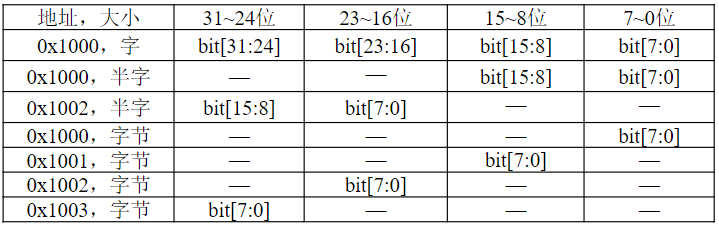
Cortex-M处理器中:
- 取指令总是采用小端模式
- 访问包括系统控制区SCS、调试部件和私有外设总线(PPB)在内的0xE000 0000 ~ 0xE00F FFFF区域,总是小端模式
- 采用小端格式的MCU,若需要处理大端数据,可使用REV、REVSH和REV16等指令将数据做大端和小端转换
5.4.4. 非对齐数据的访问
Cortex-M的存储器系统是32位的,但处理器访问或处理的数据大小可能是32位(字)、16位(半字)或者8位(字节)的
大部分经典ARM处理器只允许对齐传输
Cortex-M3和Cortex-M4处理器中,大部分存储器访问指令还支持非对其数据传输
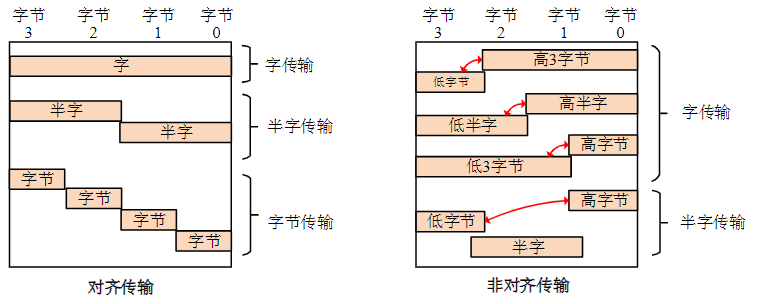
非对齐的注意事项:
非对齐的问题:非对齐传输会被拆分为两个对齐传输,导致数据访问花费更多的时间,降低了存储器的访问效率。在高性能应用中,确保数据的对齐存放是必要的
并非所有Cortex-M3和Cortex-M4的存储器访问指令都支持非对齐的数据传输。例如,多加载/存储指令、栈操作指令、排他访问指令必须是对齐的;位段操作也不支持非对齐传输
可设置Cortex-M3或Cortex-M4处理器在非对齐传输出现时触发异常
- 需要在配置控制寄存器CCR中置位UNALIGN_TRP(非对齐陷阱)位
- 软件开发过程中,程序员如果需要测试程序是否会产生非对齐传输,也可设置CCR的UNALIGN_TRP位
5.4.5. 位段操作
5.4.5.1. 位段与位段别名
位段(也称作位带)操作:一次存储器操作只访问一个位
Cortex-M3/M4处理器中,有两个位段区域:
- SRAM区域的最低1MB(0x2000 0000 ~ 0x200F FFFF)
- 外设区域的最低1MB(0x4000 0000 ~ 0x400F FFFF)
- 位段特性在Cortex-M3和Cortex-M4上是可选的
位段别名& 位段别名区域
- 位段区域中特定存储单元的某一位,映射为一个位段的别名地址(一个字)
- 一个字的32个比特被映射到32个位段别名地址(32个字)
位段别名地址数据的LSB位段区存储单元的某一个位
位段区域的存储单元可以像普通存储器一样访问,还可以通过名为位段别名的一块独立的存储器区域进行位段访问
使用位段别名地址访问存储器时,所得到字数据的最低位LSB即对应位段区域中某个特定的位
1 MB位段区映射为32 MB位段别名区域。如0x2000 0000地址的字节数据的8个比特被映射到0x2200 0000 ~ 0x2200 001C处的别名区域
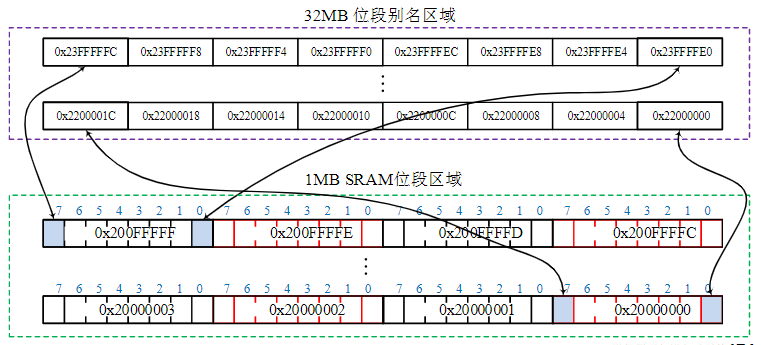
外设区域的位段别名地址如图所示,若读取别名地址0x4200002C,则返回结果可能是0x00000000或0x0000 0001,分别代表0x4000 0000位置字数据的第11位取值为“0”和“1”
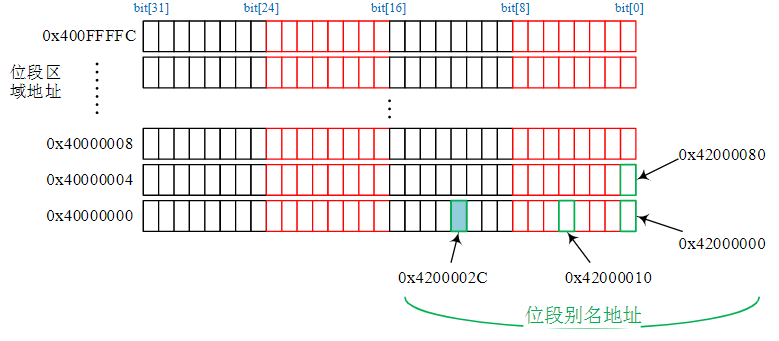
修改某一位
没有位段特性时,只能”读 → 改 → 写“
位段操作可以帮助用户完成“读改写”
示例:将地址为0x2000 0000的字数据的第2位置1

读取特定位
没有位段特性时,只能先读取字节/半字/字数据,再使用其他指令提取某一位,至少需要两次操作
位段操作可以简化程序
例:读取地址为0x2000 0000字数据的第2位

5.4.5.2. 位段操作的优点
操作的原子性:操作过程不会被其它事务打断
- 原子性是位段操作的一个重要优点
- 无位段特性时,“读改写”流程可能会被其它行为打断(例如异常/中断处理、多任务切换),从而会有潜在的数据冲突风险
- 位段操作可以避免这种竞态现象,这是因为位段操作所完成的“读改写”是由硬件保障的,具有原子性
简化转移决断过程
- 假如程序是否转移执行是依据I/O端口某个状态寄存器中的某一位,位段操作可以直接读取该位数值,迅速完成判断
5.4.5.3. C程序实现位段操作
C编译器本身不支持位段操作,其原因是:
- 不知道可以用两个不同的地址来寻址同一个存储器位置
- 也不了解对位段别名的访问只操作存储器数值的LSB
但是可以编程实现位段操作
- 例:写地址为0x40000000的某端口寄存器的bit[1]
可以在C程序中声明存储器位置的地址和位段别名
xxxxxxxxxx...DEVICE_REG0 = DEVICE_REG0 | 0x2;//未使用位段特性设置bit[1]...DEVICE_REG0_BIT1 = 0x1;//利用位段特性通过位段别名地址设置bit[1]5.4.6. 存储器访问权限
- Cortex-M3/M4的处理器映射具有默认的存储器访问权限配置,除了个别寄存器以及芯片厂商定义区之外,不允许非特权用户程序访问包括SCS(NVIC)在内的内核私有区域,否则将引起总线错误异常
- 如果系统配置了MPU并且使能,MPU设置所定义的其他访问权限也会决定是否允许用户访问其他的存储器区域
- 在没有MPU时,或者有MPU但未使能时,将使用默认的存储器访问权限设置
Cortex-M3/M4默认的存储器访问权限
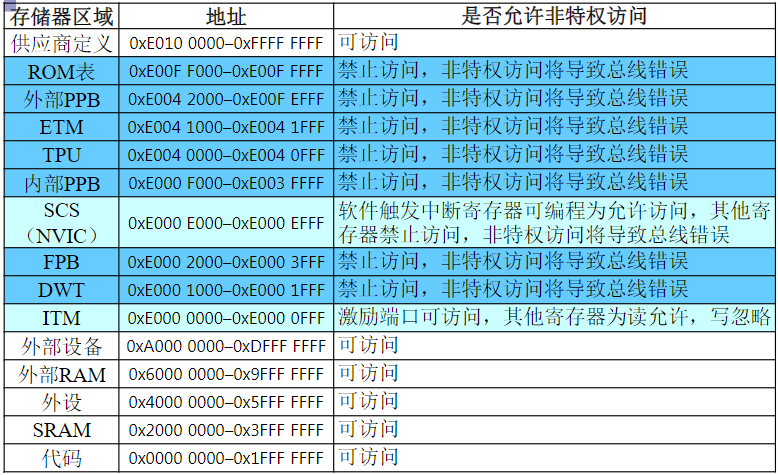
5.4.7. 存储器访问属性
Cortex-M3/M4处理器的存储器访问属性:
- 可缓冲(Bufferable):存储器写操作可能无法在一个流水线周期内完成,如果配置了写缓存,但剩下的工作交由写缓冲执行,处理器继续执行下一条指令
- 可缓存(Cacheable):读存储器所得到的数据可被复制到缓存,下次再访问时可以从缓存中取出这个数值从而加快程序执行
- 可执行(Executable):处理器可以从本存储器区域取出并执行程序代码
- 可共享(Sharable):存储器区域的数据可被多个总线主设备共用。但是,存储器系统需要在不同总线主设备之间,确保可共享存储器区域数据的一致性
可缓冲
Cortex-M3/M4支持总线接口的写缓冲
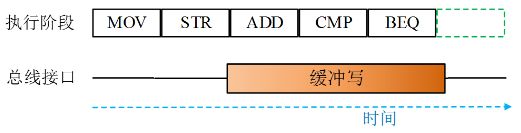
即使总线接口上的实际传输需要多个时钟周期才能完成,对可缓冲存储器区域的写操作可在单个时钟周期内执行,处理器可继续执行后续指令
代价:
- 虽然存储器系统不会改变指令执行顺序,但是,并不能确保多条顺序执行指令中的存储器访问完成顺序与指令顺序一致
- 存储器屏障指令,保证指令执行顺序与存储器访问结束顺序一致
可缓存与可共享
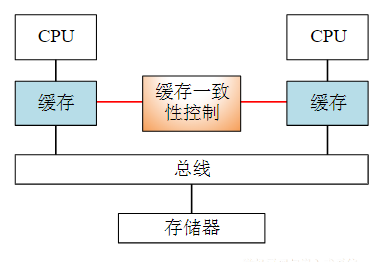
- 可缓存属性需要硬件支持,Cortex-M3/M4处理器本身没有缓存存储器或缓存控制器,但芯片制造商可在MCU增加缓存单元,支持可缓存属性
- 若系统中存在多个处理器,并且缓存控制器具有缓存一致性管理功能,就需要用到可共享属性
- 缓存控制器用来确保共享数据在各个缓存单元是一致的,从而保证共享内存中的数据一致性
存储器按访问属性分类
按照可缓冲和可缓存属性,存储器分为以下三类:
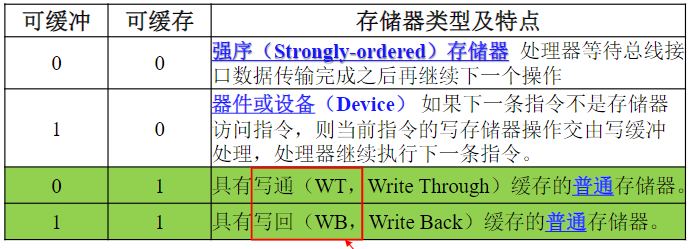
- 其中后两种都属于普通型,算作一类
现有多数基于Cortex-M3/M4的微控制器,只有可执行和可缓冲属性会影响到应用程序的执行
代码顺序存储器操作完成顺序
A1和A2是两条前后相连的存储器访问指令,A1指令在前,A2指令在后,当A1、A2指令所访问的存储器类型不同时,这两条指令实际存储器访问的先后顺序如表所示
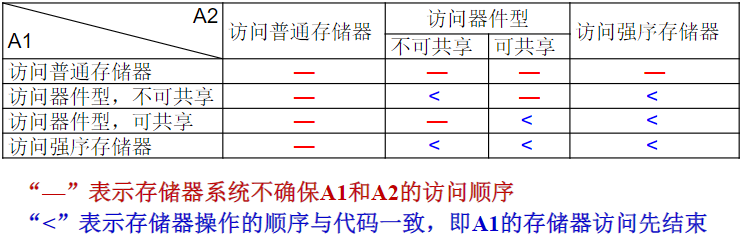
存储器系统会确保”强序“类型存储器和”器件“类型存储器的访问顺序
各存储器区域的默认访问属性
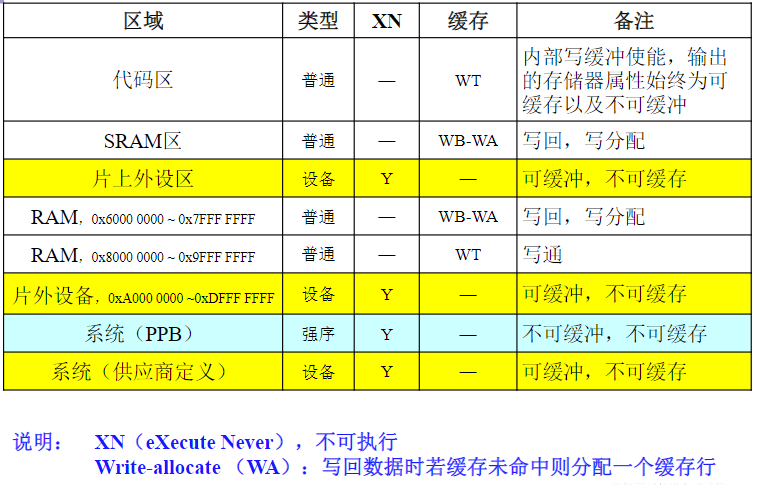
5.4.8. 排他访问
在多用户操作系统中,当多个用户共享某个特定资源时,常利用信号量(semaphore)进行协调。若某共享资源只能满足一个用户使用时,被称为互斥体(Mutex)
- 若某资源已被用户占用,就会被锁定至该用户,在锁定解除前无法用于其他用户。每个用户在使用资源前,需要先检查资源是否已被锁定,若未被使用,则设置为锁定状态,再开始使用资源
- 在传统ARM处理器中,锁定状态访问由SWP指令执行,以确保读写锁定状态的原子性,避免资源被两个用户同时锁定,但SWP指令只适用于读写位于同一总线的场景
- 在Cortex-M3/M4,读/写访问可由独立的总线执行,此时使用SWP指令就无法保证存储器访问的原子性,所以采用了新的排他访问指令(Cortex-M3/M4 取消了SWP指令)
排他写过程
排他访问需要软硬件配合才能完成,一次排他写过程需要先用排他读指令获取拟访问地址是否被锁定的信息;未被锁定时才可进行排他写并设置锁定状态
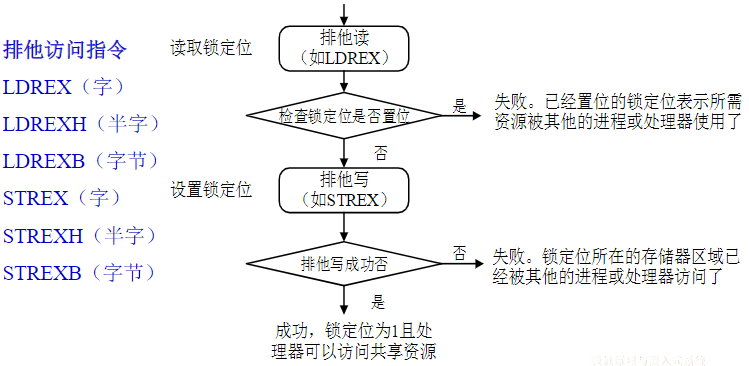
5.4.9. 存储器屏障
利用存储器屏障指令,程序员可以控制不同指令存储器访问的先后顺序
Cortex-M处理器不会调整程序中指令执行的顺序(在超标量处理或支持乱序执行的高性能处理器中可能会出现调整),同时,AHB Lite和APB协议较为简单,不允许在前面的传输还未完成时就开始新的传输
- 通常情况下,存储器操作的先后顺序也是和指令的先后顺序一致的
但是,为提高处理器性能,Cortex-M3/M4增加了写缓冲,写操作可能会和下一条指令的操作同步执行
- 如果程序员需要保证下一条指令的操作不会在当前指令写存储器操作完成前执行,需要使用存储器屏障指令
存储器屏障指令可以用于:
- 确保存储器访问顺序
- 确保存储器访问和另外一个处理器操作之间的顺序
- 确保系统配置发生在后序操作之前
Cortex-M3/M4支持三种存储器屏障指令:
- DBM:数据存储器屏障。确保执行新的存储器操作之前所有的存储器操作都已经完成
- DSB:数据同步屏障。确保下一条指令执行前所有的存储器访问都已经完成
- ISB:指令屏障。清空流水线,确保在执行新的指令前,之前所有的指令都已经完成
5.4.10. MCU中的存储器系统
在许多MCU中,芯片制造商还集成了其他一些存储器特性,以提高存储器映射的灵活性,例如:
- Bootloader(上电复位后的第一段代码)
- 存储器重映射
- 存储器别名
很多情况下,MCU中除了CODE区的Flash之外,还有一个单独的ROM(也可能是Flash),其中包含了Bootloader,其功能包括:
- Flash编程功能,可以通过UART对Flash进行编程
- 通信协议栈,便于开发者通过API调用
- 通过芯片内部的自检功能
对于具有Bootloader ROM的芯片,系统上电时执行的是Bootloader ROM中的引导程序,因此Bootloader ROM应该位于地址0x0
但是,系统再次启动时,可能不再运行Bootloader ROM中的程序,而是运行Flash中的程序。因此,可以使用下图所示电路修改存储器的映射关系
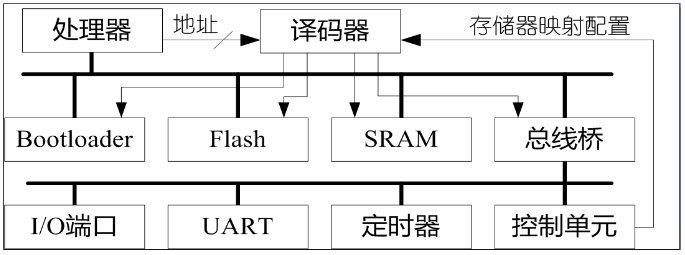
以上切换操作称为存储器重映射(Memory Remap),由Bootloader实现。但是,在重映射切换的同时无法跳到Bootloader新地址。因此,可采用一种名为“存储器别名”的方法,从两个不同的位置访问Bootloader
有多种存储器配置方法,下图只是其中的一种
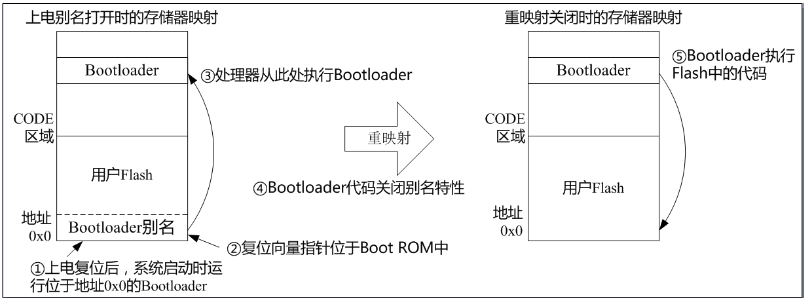
5.5. Cortex-M处理器的异常处理
5.5.1. Cortex-M异常管理模型
5.5.1.1. 异常类型
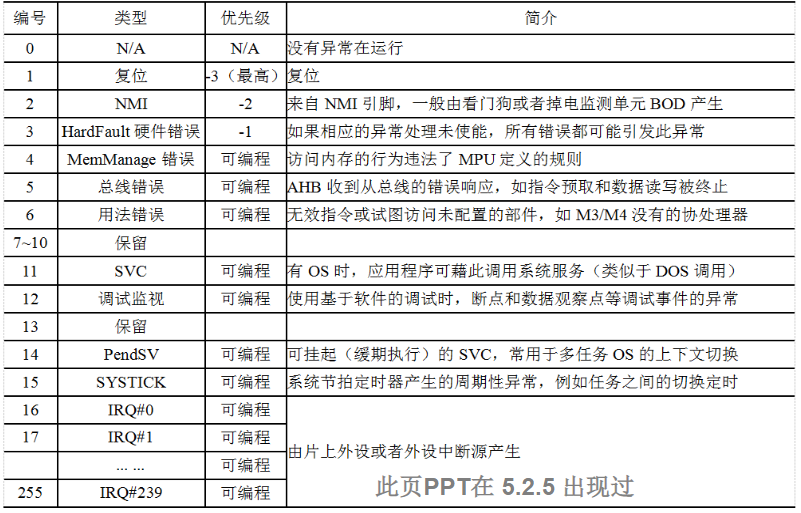
5.5.1.2. 异常状态
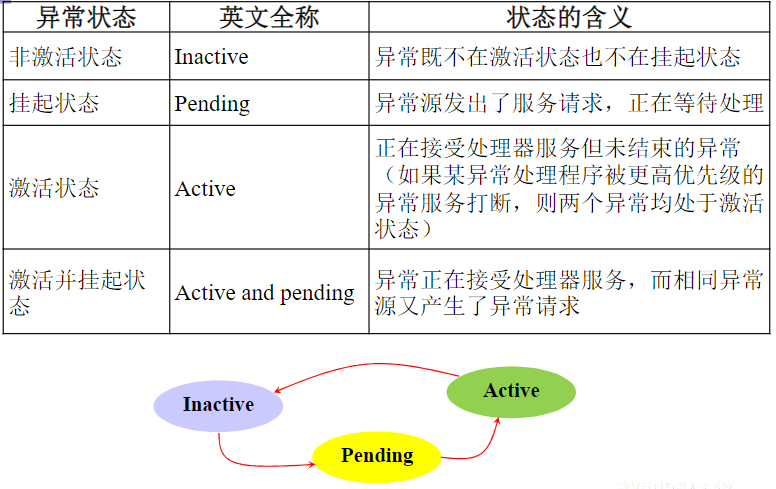
5.5.1.3. 异常处理程序

5.5.1.4. 异常向量表
当Cortex-M处理器接受了某异常请求后,处理器需要确定该异常对应的异常处理程序的起始地址。该信息位于存储器内的异常向量表中,向量表默认从地址0x0000 0000开始,按照异常类型号依次存放各个异常的入口地址
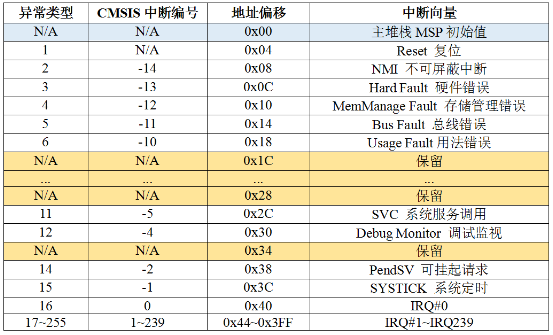
- Thumb-2指令有16位和32位两种长度,指令代码至少对齐在半字边界,程序入口地址的LSB应是“0”
- 但是异常向量的LSB必须是“1”,表示异常处理程序处于Thumb状态,否则将引起总线错误
5.5.1.5. 异常的优先级
Cortex-M3/M4中,每一个中断都有一个8位的中断优先级(配置)寄存器(0xE000E400~ 0xE000E4EF,位于NVIC中),实际使用位数3~8位,取决于MCU设计的中断数量
优先级的减少通过去除优先级配置寄存器的最低位(LSB)实现,有两种不同的移除方法:
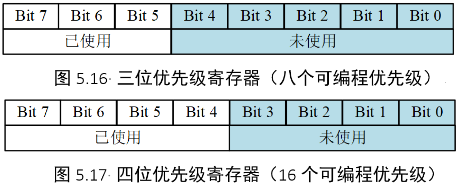
每一个中断的优先级由各自的中断优先级寄存器定义,中断优先级寄存器可以按照字节/半字/字进行访问
- 若MCU设计了3位优先级,则有8个可编程优先级
- 若设计了4位优先级,会得到16个可编程优先级
- ARMv7-M架构,宽度最少为3位
若设计中实现了4位优先级,优先级配置寄存器如下,会得到16个可编程优先级

实际使用的位数越多,可用的优先级越多
若出现优先级相同的异常同时发生,处理器将优先处理异常类型号低的,称之为”自然顺序优先级“
- 例如,假设IRQ#0和IRQ#1的优先级被设为相同数值,当IRQ#0和IRQ#1同时出现或均处于挂起状态时,处理器会先处理IRQ#0的ISR
复位后的初识状态:
- 所有可配置中断处于禁止状态,默认优先级为0
- 固定不变:复位为-3、NMI为-2、硬件错误为-1
5.5.1.6. 中断优先级分组
优先级寄存器3~8位又分为两部分(以8位为例)
分组优先级(group priority),过去称为抢占优先级(preempt priority)
- 后来的中断能否产生嵌套,由该中断的分组优先级决定
子优先级(subpriority)
- 两个具有相同分组优先级的异常同时出现时,首先处理子优先级(数值更小)高的异常

AIRCR(0xE000 ED0C)的PRIGROUP位域(AIRCR[10:8]),使用3位定义优先级分组的8种配置方案
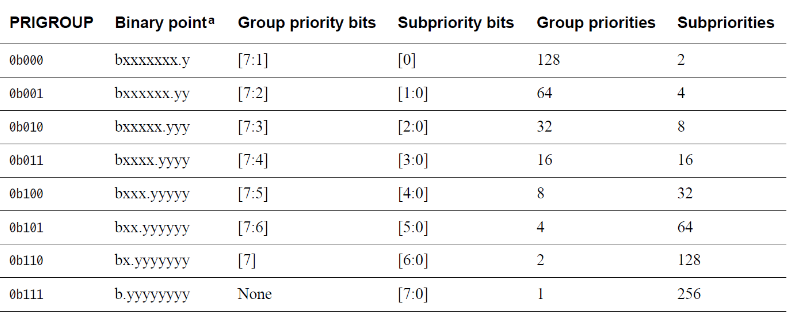
若优先级配置寄存器的宽度不同,设置优先级分组的方法:
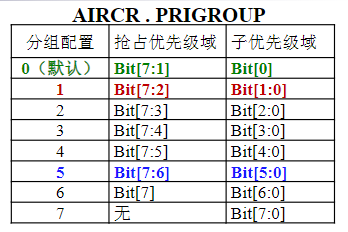
优先级配置寄存器的宽度为8,优先级分组为配置0

优先级配置寄存器的宽度为3,优先级分组为配置1

优先级配置寄存器的宽度为3,优先级分组为配置5

5.5.1.7. 异常流程
异常处理的过程包括:中断响应、中断处理和中断返回
- 中断响应:CPU确定响应某中断后,根据中断类型码查找中断向量表中对应的表项,获得中断服务子程序入口地址;接下来保护断点(将标志寄存器和断点地址等信息压入堆栈);随后(粗糙描述)中断向量被装入PC寄存器,下一个指令周期即进入中断服务子程序
- 中断处理:就是执行中断服务子程序的过程,处理之前需要保护现场(保护现场的执行主体是ISR)
- 中断返回:包括从堆栈中恢复现场和恢复断点,恢复现场需要编程实现,而恢复断点由硬件电路自动完成
异常请求的接受
处理器接受请求的条件:
- 处理器处于运行状态
- 异常处于使能状态
- 异常的优先级高于当前等级
- 异常没有被屏蔽(如没有设置PRIMASK)
注意:若异常处理程序中出现了SVC指令,而该异常的优先级不低于SVC的优先级,就会发出硬件错误,从而进入硬件错误的处理程序
异常进入流程
异常进入流程包括如下操作:
多个寄存器的值和返回地址被压入当前使用的栈
- 在不保护浮点运算寄存器组情形下,被压入堆栈的寄存器包括PSR、PC、LR、R0~R3、R12,共8个字
- 如果需要保护浮点运算单元状态,则有26字的状态会被压栈
- 若处理器处于线程模式且正在使用进程栈指针(PSP),则PSP指向的堆栈区域就会用于该压栈过程,否则就会使用主栈指针(MSP)指向的堆栈区域
从向量表中取出异常向量
取出异常处理程序中的指令
更新多个NVIC寄存器(后续介绍)和内核寄存器(PSR、LR、PC及SP)
根据压栈时实际使用的栈,MSP或PSP的数值会在异常处理开始前自动调整。PC也会被更新为异常处理的起始地址,而LR则会被更新为名为EXC_RETURN的特殊值
EXC_RETURN服务于异常返回,其数值为32位,高28位为1,低4位用于指示进入异常是保存的状态信息(即指示使用的是MSP还是PSP,哪些寄存器被压入栈),其可能的数值如下所示
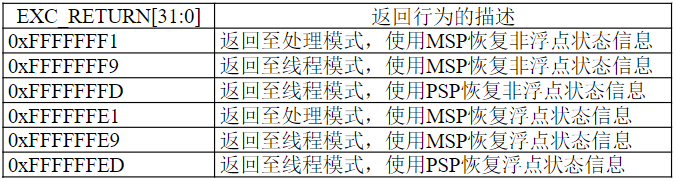
在异常进入过程中,硬件自动完成的处理有:
- 根据压栈时实际使用的栈,MSP或PSP的数值会在异常处理开始前自动调整
- PC被更新为异常处理的起始地址
- LR被更新为EXC_RETURN
- R0~R3、R12,LR、PC(返回地址)和PSR共8个寄存器被压栈(注意:压栈顺序和栈帧结构不同)
- 如果需要压栈保存FPU状态,则共有26字
- 如果使能双字栈对齐,可能还会修改已入栈的PSR[9]
为加快中断执行速度,需要调整压栈顺序:
压栈时为了尽快更新PC,首先压栈的是PC(返回地址)和PSR,出栈时为了尽快恢复处理器状态和返回主程序,出栈时也应先出栈PSR和PC,这时需要根据压栈时实际使用的栈,MSP或PSP的数值会在异常处理开始前自动调整

此外,如果中断向量位于CODE区,压栈的同时可以使用I-Code总线取中断向量,以充分利用哈佛结构的优点;如果中断向量位于SRAM区或者RAM区,压栈和取向量只能都是用系统总线,会略微增加中断响应延迟
执行异常处理程序
- 进入异常处理程序内部后,处理器进入处理模式,并运行于特权访问等级,栈操作使用MSP
- 此过程中如果有更高优先级的异常产生,处理器会接受新的中断,当前正在执行的处理被更高优先级的处理抢占而进入挂起状态,此即异常嵌套
- 若执行过程中产生的其他异常具有相同或更低的优先级,新产生的异常就会进入挂起状态,待当前异常处理完成后才可能被处理
在异常处理的结尾,程序代码执行的返回会引起EXC_RETURN数值被加载到程序计数器PC中,并触发异常返回机制
异常返回
Cortex-M处理器的异常返回机制由EXC_RETURN触发,该数值在异常入口处产生且被存储在LR中
EXC_RETURN写入PC时,就会触发异常返回流程
异常返回可由表中所示的指令产生。异常返回机制被触发后,进入异常期间被压入栈中的寄存器数值会被恢复到寄存器组中,因而多个NVIC寄存器和处理器内核中的寄存器(如PSR、SP和CONTROL)都会被更新

加速中断处理速度——咬尾中断
情形描述:
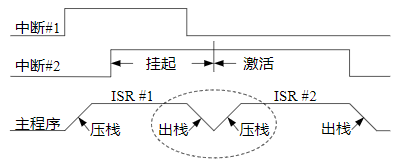
- 中断#1正在服务,又出现中断#2,因优先级问题,中断#2被挂起
- 当中断#1结束后,一般的流程是:中断#1返回(一系列的出栈操作,恢复现场和恢复断点),紧接着响应中断#2,又有一系列的入栈操作(保护断点和保存现场)
咬尾中断:
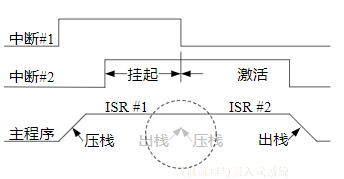
- 流程优化思想:中断#1结束后,读取中断#2的中断向量,立即为中断#2服务,减少中断#2的时延
加速中断处理速度——晚到中断
情形描述:
- 当优先级较低的中断#n刚刚被响应,正在进行压栈,但是尚未取中断向量和进入ISR,此时又有优先级更高的中断#m到达
- 一般流程:响应中断#n时关中断,进入ISR后开中断,再响应优先级更高的中断#m,中断#m的服务可能被延误
晚到中断:
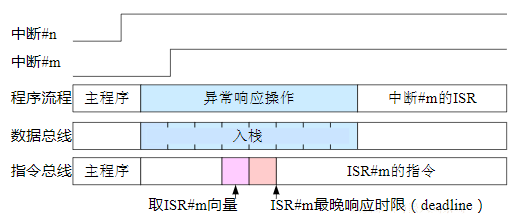
- 仍然压栈保护断点,但是取ISR#m的中断向量,提前为中断#m服务
5.5.2. 向量表重定位机制
向量表重定位简介
- 向量表默认位置位于CODE区最开始处,MCU制造商在此区域一般配置的是存放启动代码的Flash或者是ROM型存储器,这些器件运行时无法修改,而有些应用需要修改或者增加中断向量。一种解决方案是将向量表“迁移”到CODE区或者SRAM区其他可以修改的SRAM或者RAM型器件中
- 在有些MCU中,包含Bootloader的ROM就位于CODE区的最开始位置,而且没有使用存储器重定位特性或者存储器别名,这样就挤占了中断向量表原来应该的存放位置,中断向量表只能“背井离乡”,重新择址“安家”
- 上述中断向量表的迁移称为“向量表的重定位”
向量表重定位的实现
在Cortex-M3/M4 处理器所集成的NVIC中,有一个名为VTOR(Vector Table Offset Register,地址为0x0E000 ED08)的寄存器,修改VTOR的值就能实现中断向量表的重定位
对中断向量起始地址的要求:
- 起始地址必须能够被大于等于(中断向量数×4)的最小2的整数次幂整除
- 例如:CM3/M4最少中断数是8个,再加16个系统异常,8+16=24,24×4=96,大于96的最小2的整数次幂是128(=27),所以向量表的起始地址应该是0x80的整数倍,换言之,向量表起始地址低7位为000 0000
VTOR的格式
r2p0版本之前的Cortex-M3,向量表只能“迁移”CODE区或者SRAM区;而新版Cortex-M3和所有Cortex-M4取消了上述限制
- 如前所述,VTOR的最低7位[6:0]为000 0000
- r2p0版本之前的Cortex-M3最高两位没有意义,位[29]为0或1表明中断向量表位于CODE区还是SRAM区
- 在Cortex-M4和新版本的Cortex-M3中,最后7位没有变化,但是其他位是向量表起始地址的高25位

应用示例:
具有Bootloader的设备
- MCU启动时,首先执行ROM中的Boot loader代码
- 在跳转到Flash中的用户程序前,设置VTOR指向用户Flash存储器的开始处(此处放置重定位后的向量表)
- 向量表切换为用户Flash中的向量表
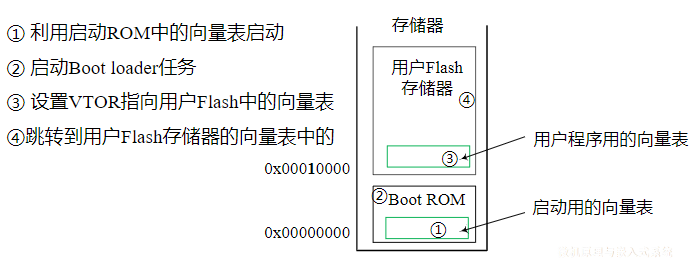
应用程序是从外部加载到RAM中执行
- 存储在片上存储器的启动程序初始化相关硬件,把外部设备(如SD卡或U盘)中的应用程序复制到RAM(包括SRAM)中
- 更新VTOR,指向位于RAM中新的向量表
- 最后执行已加载到RAM的程序
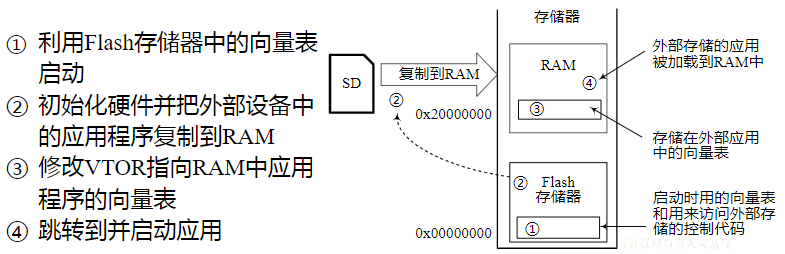
5.5.3. 中断请求和挂起
在传统ARM处理器中,若设备产生了中断请求,在得到处理前需要一直保持中断请求信号。在NVIC中设计了用于保存中断请求的挂起请求寄存器,即使请求中断的源设备取消了请求信号,已产生的中断仍会被处理
如果处理器空闲,处于挂起状态的中断请求会马上得到处理,此时,中断的挂起状态被自动清除。但如果处理器正在处理另外一个更高优先级或同等优先级的中断,或者产生请求的中断源被屏蔽了(通过设置中断屏蔽寄存器),那么在其他中断处理结束前或中断屏蔽被清除前,该中断会一直保持在挂起状态
某个中断被处理时就会进入激活状态。在NVIC中,中断激活状态寄存器保存每个中断的激活状态,只有在中断服务完成,处理器执行了异常返回后,中断激活状态寄存器中对应已完成服务中断的位才会被清除(自动完成)
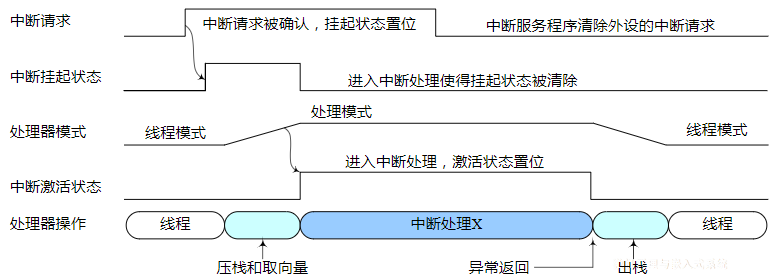
中断的状态:请求挂起激活
挂起状态、挂起状态清楚、进入激活状态、清除激活状态
线程模式处理模式线程模式
- 从线程模式切换到处理模式时,多个寄存器会被自动压栈,并从向量表取出ISR的起始地址
- 从处理模式回到线程模式时,之前自动压栈的寄存器会被恢复,继续此前被打断的程序
在Cortex-M3/M4中,出现中断请求之后,如果没有得到服务,就一直被挂起。即使中断源因某种原因撤销了请求,仍然会被处理——在编写ISR时,应先读取中断源相关状态,若的确需要服务,继续执行ISR;否则退出
一般而言,需要中断服务的外设,应该设置专门的“中断请求触发器”,在得到服务前,一直维持请求信号有效,在中断响应之后再撤销
5.5.4. NVIC寄存器
NVIC中的寄存器组只能管理类型16~255的外部中断,管理NMI和Systick等系统异常需要SCB中的寄存器
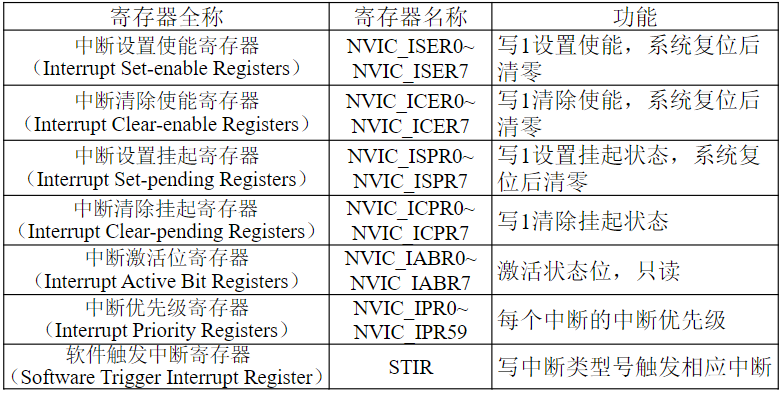
5.5.4.1. 中断的使能和禁止
中断使能和禁止是通过对2个寄存器(中断设置使能寄存器Interrupt Set-enable Registers和中断清除使能寄存器Interrupt Clear-enable Registers)进行写操作,实际是对一个物理寄存器进行配置
- 设置中断势能需要写入NVIC_ISERn寄存器的相应位
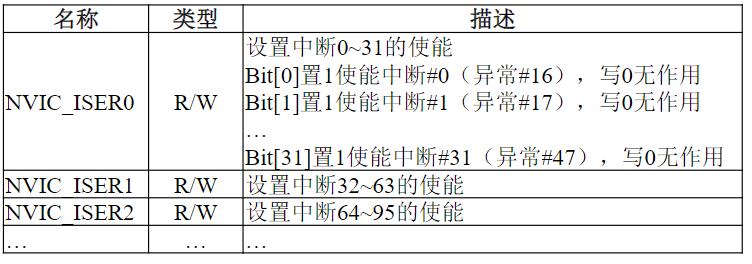
注意:中断使能和禁止使用两个地址,操作的是同一个物理寄存器
清除使能(禁止中断)需要写入NVIC_ICERn寄存器的相应位
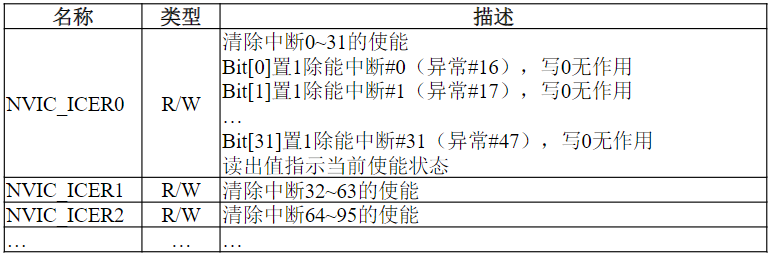
- 每个ISER/ICER寄存器都是32位,每位对应一个中断输入,若外部中断源超过32个,ISER和ICER寄存器不止一个
- ISER/ICER分开设置,操作的是同一个寄存器,某位置1无需担心其他位被置零;没有“读-改-写”过程,操作具有原子性
5.5.4.2. 中断挂起和中断清除
若中断请求产生但没有立即执行,就会进入挂起状态
设置中断挂起状态或者读取中断挂起状态,可以通过访问中断设置挂起寄存器(Interrupt Set-pending Registers,NVIC_ISPRn)实现
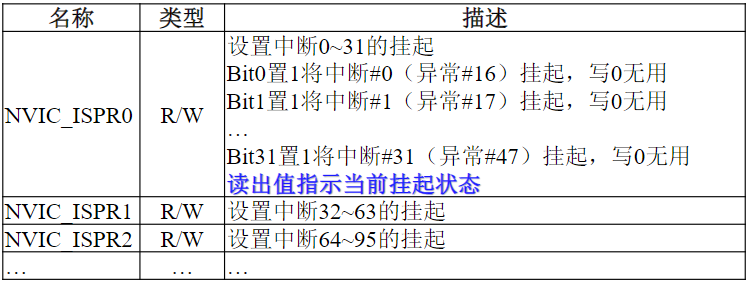
通过写ISPR将某个中断设置为挂起状态,该中断就进入了等待中断服务的队伍中
清除中断挂起状态可以通过中断清除挂起(Interrupt Clear-pending Registers,NVIC_ICPRn)寄存器实现
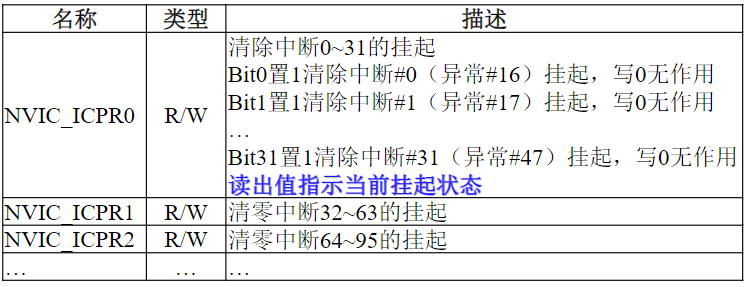
每个ISPR/ICPR寄存器也是32位,每位对应一个中断输入,若外部中断源超过32个,ISPR和ICPR寄存器也不止一个
中断的激活状态
- 只要进入中断服务子程序,中断激活状态寄存器(Interrupt Active Bit Registers,NVIC_IABR)中的对应位就置1
- 如果发生中断嵌套,会出现多个中断处于激活状态(尽管处理器在执行优先级高的中断处理,之前执行的较低优先级的中断仍处于激活状态)
- NVIC_IABR为只读类型

中断优先级配置寄存器
- 每个中断都有各自的优先级寄存器(Interrupt Priority Registers),每个优先级寄存器位宽为8位(实际位宽为3~8位),一个32位的NVIC_IPRn管理4个中断
- 每个优先级寄存器又分成分组优先级和子优先级两部分
- 优先级寄存器的数量取决于芯片实际的外部中断数
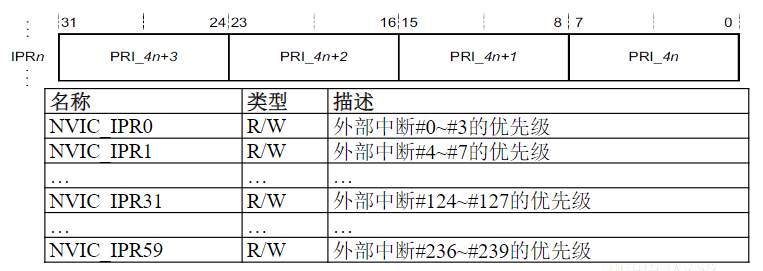
软件触发中断寄存器
除了写ISPR以外,还可以向软件触发中断寄存器(Software Trigger Interrupt Register,STIR)写类型号来触发相应中断(写ISPR是置位对应位)
- 可以通过设置CCR,允许非特权程序访问STIR
- 但是只有特权访问等级才可以访问ISPR

5.5.5. SCB寄存器
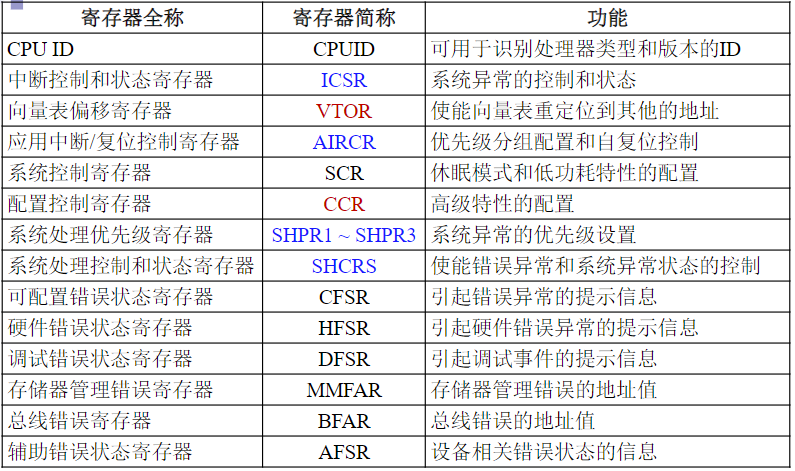
中断控制和状态寄存器
ICSR: Interrupt Control and State Register
用于设置和清除系统异常的挂起状态,包括NMI、SysTick和PendSV
通过ICSR可以获知当前正在处理的异常的类型号、当前挂起异常中优先级最高者的类型号、是否发生了抢占信号等信息
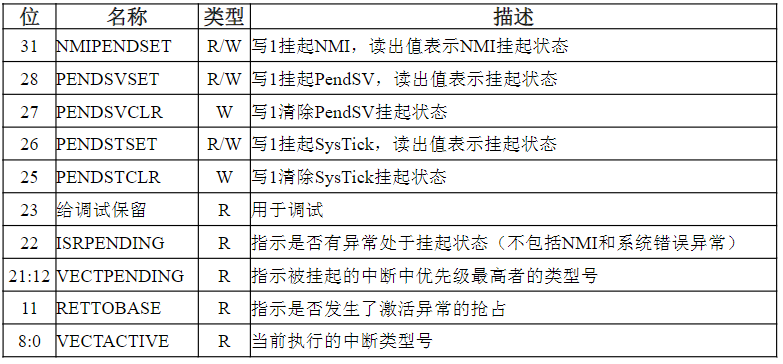
应用中断和复位控制寄存器
AIRCR: Application Interrupt and Reset Control Register
用于控制异常/中断优先级管理中的优先级分组,指示系统的端配置信息,提供自复位特性
VECTRESET和VECTCLRACTIVE位域是为调试器设计的。软件可利用VECTRESET触发处理器复位,但它不会复位外设,若需要产生系统复位,应该使用SYSRESETEREQ
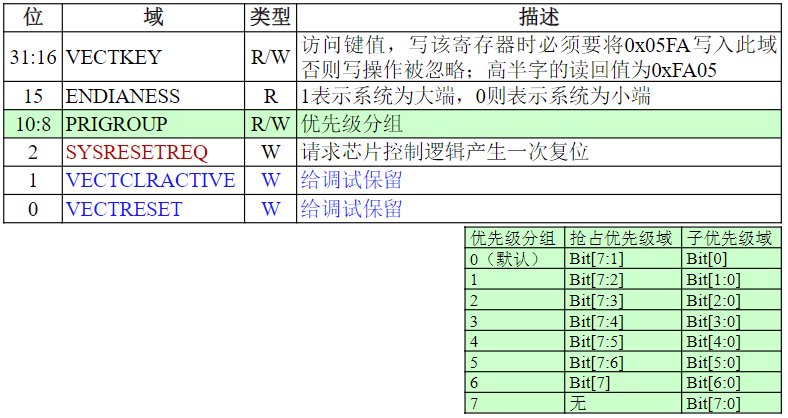
系统处理优先级寄存器
SHPR: System Handler Priority Register
共3个,SHPR1到SHPR3,SHPR的位域定义与中断优先级寄存器定义相同,差别在于SHPR用于(除了复位、NMI和硬件错误以外的)系统异常
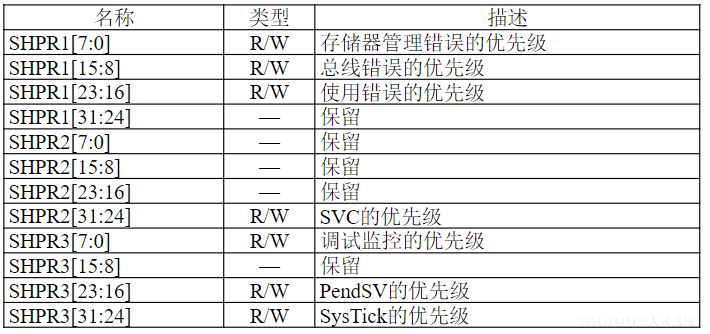
系统处理控制和状态寄存器
SHCSR: System Handler Control and State Register
可以使能的异常包括:使用错误、存储器管理错误和总线错误异常
上述异常和多数系统异常的激活状态也可从SHCSR获得
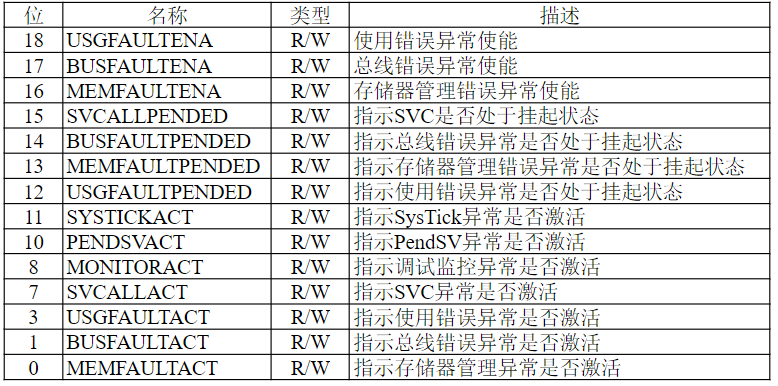
6. ARM指令系统
6.1. ARM处理器指令集概述
指令集体系架构:描述处理器指令及其功能、组织方式和规范
指令系统:计算机系统中所有机器指令的集合
机器指令:
- 表示一条指令的二进制代码(即比特串,或称位串)称为指令字,简称指令
- 指令字可以是固定长度的,也可以是可变长度的
- 指令字需要包含操作码、操作数(可能有多个)和操作数地址等字段
- 所有指令字的相关信息在指令集中予以规定
6.1.1. ARM的不同指令集
ARM处理器的指令集
ARM Instruction Set Architecture
不同时期的ARM处理器指令集存在较大差异
- ARM公司在多个体系结构版本的基础上,还定义了若干增强型版本,配合相应的硬件部件以支持协处理器、DSP、VFP、Java和SIMD多媒体信号处理等功能
目前,ARM公司将其不同系列处理器所支持的指令集架构ISA统一为三个
- A64:与现有A32指令集相似,仍然是32位宽,具有相似的语法,支持64位处理器
- A32:即原来的ARM指令集,指令长度固定为32比特
- T32:即原来的Thumb-2指令集,16位和32位指令共存
各个版本架构所支持的指令集

说明:
- 自ARMv6-M之后,所有版本都支持T32指令集
- 不同处理器设计(配置的功能部件不同),增加了不同的指令集扩展(也称扩展指令)
6.1.2. ARM指令集扩展
指令集扩展
除基本指令集以外,为满足具体应用需求,ARM处理器可选配一些功能部件,并增加与之“配套”的指令,构成扩展指令集(Arm Architecture Extensions)
例如:
- DSP extensions 数字信号处理
- Floating-point Extension 浮点数运算(如Cortex-M4)
- Neon: 单指令多数据(SIMD)
- Helium: Armv8.1-M引入的M-Profile Vector Extension,矢量处理,用于Cortex-M系列
- ......
ARM指令集的扩展过程
ARMv8-A的的指令集扩展过程:先后增加了Jazelle、VFP、TrustZone、SIMD 、NEON以及可选密码扩展
ARM的指令集扩展
DSP 扩展
- 单周期16×16 和32×16 MAC 实现
- 零开销饱和运算扩展支持
- 用于加载和存储寄存器对的新指令,包含增强的寻址模式
- CLZ 指令,改善归一化以及除法运算性能
浮点数运算扩展
- 半精度、单精度和双精度浮点运算支持
- 运算指令:Add、Sub、Mult、Neg-Mult、Negate、Abs Value、Compare、Div、Square Root
- FMAC:Multiply-Add、Multiply-Subtract、Neg-Multiply-Add、Neg-Multiply-Subtract、类型转换、加载/存储标量和矢量,64 位/周期
多媒体SIMD 扩展
- 小数运算
- 用户可定义的饱和模式(任意字宽)
- 同时计算2×16位或4×8位操作数
- 双16×16 乘加/减和32×32 小数MAC
NEON 是SIMD的128 位升级版,具有32个64 位宽(也可以看作16个128位宽)寄存器
- 寄存器被视为同一数据类型的元素的矢量
- 数据类型:8 位、16 位、32 位、64 位单精度浮点
- 指令在所有通道中执行同一操作
JAVA加速
- ARM Jazelle 包括在任何现有JVM 和Java 平台中支持Jazelle 硬件的技术
安全计算的指令扩展
- ARM TrustZone 技术是系统级的安全方法,针对高性能计算平台上的大量应用,包括安全支付、数字版权管理(DRM) 和基于Web 的服务
虚拟机有关的指令扩展
- ARM架构的虚拟化扩展(Virtualization Extensions )提供了在ARM处理器基础上建立虚拟机(virtual machines )的基本支持
Cortex-M支持的指令集
部分Cortex-M系列处理器所支持的指令集以及扩展指令功能如下:
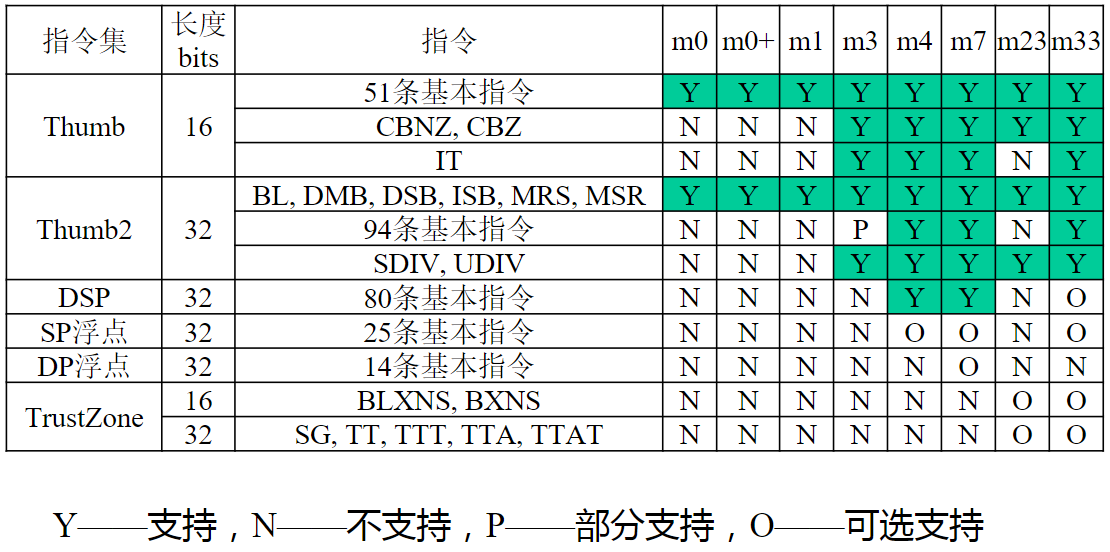
Cortex-M处理器的兼容性
- 由上图可见,在Cortex-M0/M0+/M1上编译过的代码可在Cortex-M3/M4上直接运行
- Cortex-M3/M4不支持ARM指令,不能向后兼容传统ARM处理器(如ARM7TDMI),亦即Cortex-M处理器不能直接运行ARM7TDMI的二进制代码
- 但是,Cortex-M3/M4的Thumb-2指令是Thumb指令的超集,大部分ARM7TDMI的指令可以移植为等价的32位Thumb-2指令,因此传统ARM处理器上的应用软件可以重新编译后再移植到Cortex-M3/M4上
- 虽然指令有16位和32位之分,对于同一个操作,不同长度的指令执行时间相同
Cortex-M处理器的适用场景
对于一般的数据处理和I/O控制,Cortex-M0/M0+完全可以胜任(性能达2.15 Core Mark/MHz)
如果需要进行复杂的数据处理和快速乘加运算,就应该升级到Cortex-M3/M4处理器
如果需要DSP功能,则应该选择Cortex-M4
如果还需要计算浮点数,Cortex-M4还应该选配FPU
需要特别指出的是:
- 虽然Cortex-M3/M4支持的指令较多,但是C编译器也能生成高质量的代码,CMSIS-DSP库提供了较丰富的应用函数,现代大多数嵌入式软件都使用C或C++语言开发,因此无需过于关注汇编指令的细节
6.2. T32指令格式
6.2.1. 16比特指令二进制格式
T32的指令由半字对齐的序列构成
- 若为16比特Thumb指令,则指令中含有一个半字
- 若为32比特Thumb指令,则指令中含有两个半字
通过半字的最高5个比特来区分是16比特指令还是32比特指令。若一个半字的最高五个比特(bits[15:11])为如下三种情况则该半字为一个32位比特指令的第一个半字:
- 0b11101
- 0b11110
- 0b11111
其他情况的半字均为16比特指令

16比特指令的二进制位串编码格式如下:

高六比特为操作码,操作码定义了不同的指令类别:
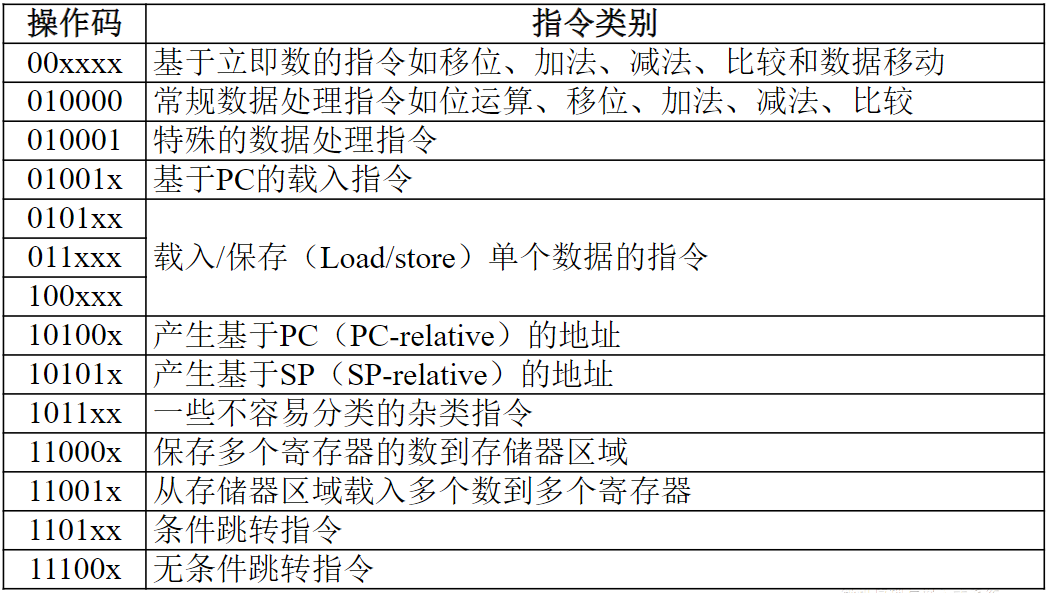
6.2.2. 32比特指令二进制格式
T32指令集中32比特指令的二进制编码格式如下:

操作码被分成三段:”op1“、”op2“、”op“
当”op1==0b00“时,表示是该指令T32指令集中的16比特指令
当”op1!=0b00“时,根据”op1“、”op2“、”op“可对32比特指令进行分类
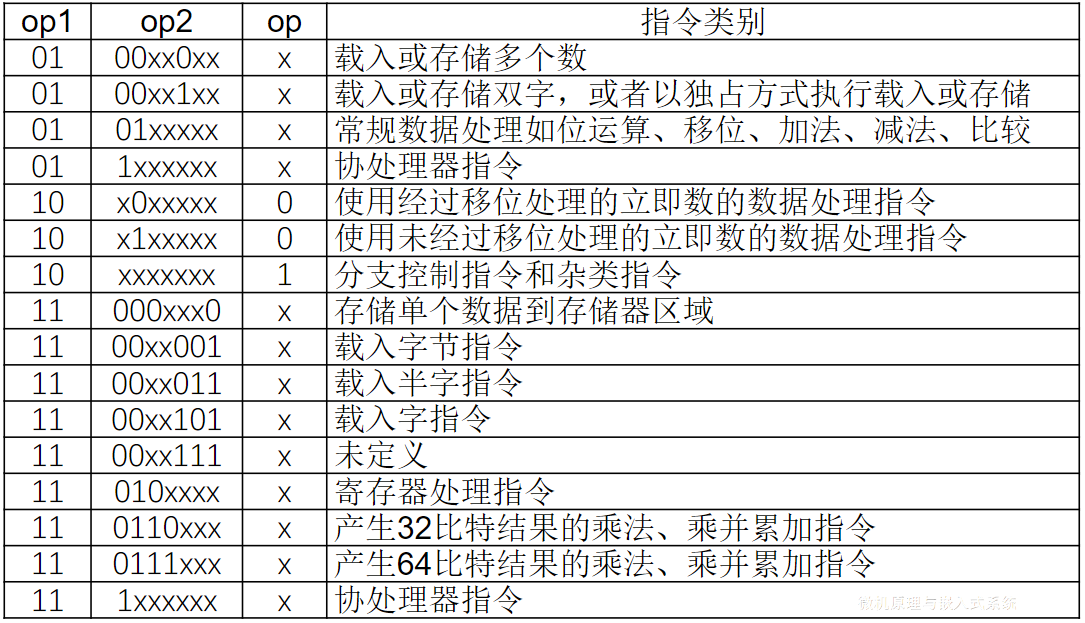
6.2.3. T32指令的汇编语法
在定义一条机器指令的时候,需要将指令的功能、源操作数、目标操作数、操作数地址等信息予以明确。ARM处理器中汇编指令的通用格式构成要素如下:
xxxxxxxxxx<opcode> [cond] [q] [S] _<Rd>, _<Rn> [,_Oprand2]
其中,<>内的参数是必选参数,而[]内参数是可选参数
opcode,操作码,也称为助记符。说明指令需要执行的操作类型cond,条件码(可选后缀),描述指令的执行条件q,可选后缀,指令宽度选择,“N”表示指令为16比特,“W”表示指令为32比特S,可选后缀,加上“S”,在指令执行完毕后自动更新APSR中的标志位的值- 早期产品,几乎所有数据操作指令都会更新APSR5中的标志位
Rd,ARM指令中的目标操作数,总是一个寄存器Rn,存放第一个源操作数寄存器,该操作数必须是寄存器Oprand2,第二源操作数,不仅可以是寄存器,还能是立即数,且能用经过偏移量计算的寄存器和立即数
6.2.4. T32的条件执行指令
T32中多数Thumb指令可以根据应用程序状态寄存器APSR中的标志位决定当前指令是否被执行
这种在特定条件满足时才执行的指令被称为条件执行指令
APSR寄存器的标志位定义为:

处理器执行指令的时候,其运算过程可能会改变APSR中的标志位
APSR寄存器的各标志位定义为:
Nbit[31] 负数标志位。N==1 表示上一次运算结果为负数,否则为正数或零Zbit[30] 零标志位。Z==1 表示上一次运算结果为零Cbit[29] 进位标志位。C==1 表示上一次运算结果产生了进位Vbit[28] 溢出标志位。V==1 表示上一次运算结果产生了溢出Qbit[27] 饱和标志位。Q==1 表示上一次运算结果产生了饱和操作GE[3:0]bits[19:16],DSP扩展指令中SIMD类指令指示上一次运算结果信息
在Thumb指令中,只要条件码不为“1110”,均为条件执行指令:
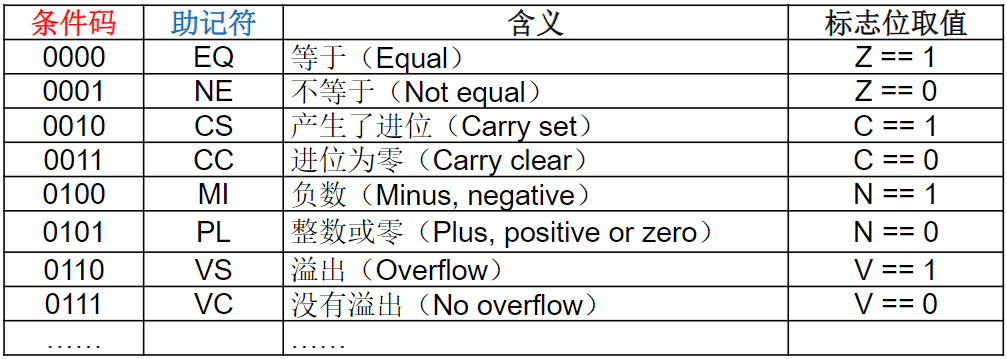
6.2.5. T32指令格式示例
指令一般由操作码字段和操作数字段两部分组成
xxxxxxxxxx操作码字段 操作数字段 ... 操作数字段
操作码字段:指示计算机要执行是什么操作
操作数字段:指令执行操作过程中所需要的操作数,该字段可以是:
- 操作数本身
- 操作数地址或是地址的一部分
- 指向操作数地址的指针
- 或其他有关操作数的信息(如寄存器名称)
ARM处理器绝大多数算逻运算指令支持3操作数,也有1~2个操作数,少数隐含多个操作数(如LDM指令),还有若干指令无操作数
6.3. T32指令集寻址方式
寻址:根据指令内容确定操作数地址的过程
- 确定当前指令中的操作数地址,称为数据寻址
- 确定下一条待执行指令的地址,称为指令寻址
寻址方式:如何寻找操作数的方法。不同的寻址方式实质上是构成操作数地址的方法不同
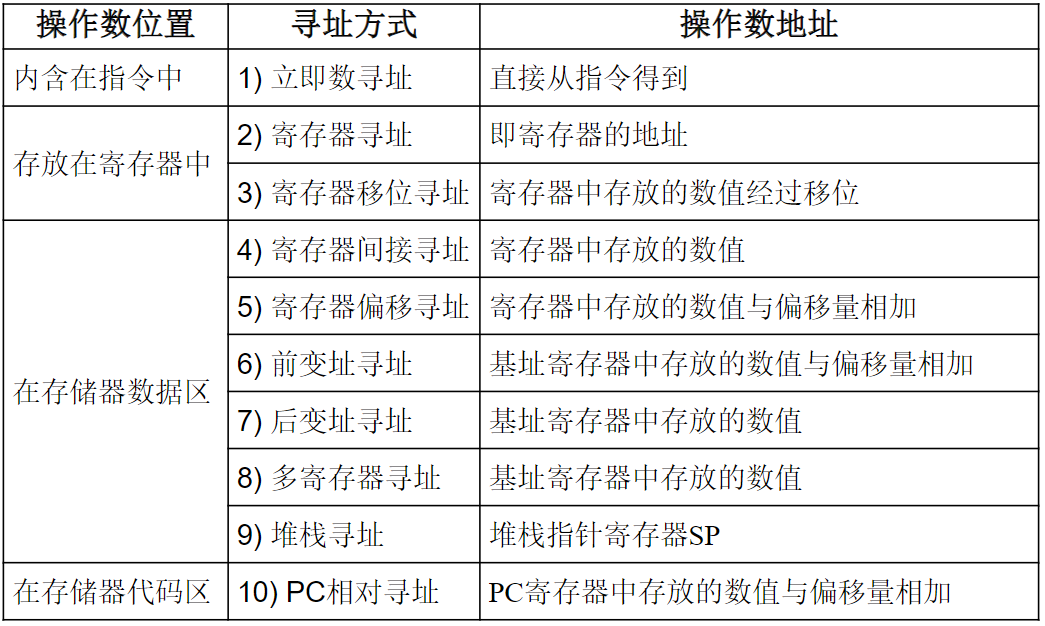
6.3.1. 立即数寻址
立即数寻址也叫立即寻址,是一种特殊的寻址方式
操作数本身包含在指令中,只要取出指令也就取到了操作数
这个操作数叫做立即数,对应的寻址方式叫做立即寻址,如
xxxxxxxxxxMOV R0, #66 ;将立即数66传送到寄存器R0ADD R0, R0, #66 ;R0+66→R0SUB R0, R0, #0x33 ;R0-0x33→R0
在立即数寻址中,要求立即数以“#”为前缀,对于以十六进制表示的立即数,要求在“#”后加上“0X”或“&”或“0x”
Cortex-M3/M4支持的T32指令集中,指令长度要么是16比特,要么是32比特,指令长度有限 → 立即数取值只能在一定范围内
对立即数的限制
在传统ARM处理器所使用的32位ARM指令中,要求32位立即数必须是一个“位图”数据
- 位图数据:一个任意的8位立即数经过偶数次循环左移得到的数据
在16位Thumb指令集中,可以将任意8位立即数通过左移得到一个32位立即数
满足格式“0x00XY00XY”或“0xXY00XY00”或“0xXYXYXYXY”的数是合法的立即数,其中X和Y为16进制数
6.3.2. 寄存器寻址
寄存器寻址(或称为寄存器直接寻址)就是利用寄存器中的数值作为操作数
在各类微处理器经常被采用,执行效率高
xxxxxxxxxxADD R0,R1,R2 ;将R1和R2相加结果送入R0
寄存器仅限于通用寄存器,不可以是PC
6.3.3. 寄存器间接寻址
寄存器间接寻址就是把寄存器中存放的数值作为操作数,通过这个地址去取得操作数,操作数本身存放在存储器中
xxxxxxxxxxLDR R0, [R1];以寄存器R1的值作为操作数地址,取得操作数后加载到R0;常常记为[R1]→R0ADD R0, R1, [R2];基于寄存器R2间接寻址取得操作数后与R1相加,结果存入R0;常常记为R1+[R2]→R0
6.3.4. 寄存器移位寻址
寄存器移位寻址是ARM指令集特有的寻址方式
寻址方式为:先由寄存器寻址得到操作数,对该操作数再进行移位操作后得到最终的操作数
xxxxxxxxxxMOV R0, R2, LSL #3 ;R2<<3, → R0MOV R0, R2, LSL R1 ;R2<<R1,→ R0
支持的移位方式:
LSL:逻辑左移,寄存器中字的低端空出的位补零LSR:逻辑右移,寄存器中字的高端空出的位补零ASR:算术右移,移位过程中符号位不变,即如果源操作数是正数,则字的高端空出的位补零,否则补“1”ROR:循环右移,由字的低端移出的位填入字的高端空出的位RRX:带扩展的循环右移,操作数右移一位,高端空出的位用进位标志C的值来填充,低端移出的位填入进位标志位
6.3.5. 寄存器偏移寻址
寄存器偏移寻址:操作数地址由一个寄存器中存放的数值与指令中给出的地址偏移量相加得到
寻址过程:将寄存器(基址寄存器)中的基址与指令中给出的地址偏移量相加,得到一个新的地址,通过这个地址取得操作数
汇编语法:
xxxxxxxxxxopcode Rd [<Rn>,<offset>]
指令中给出的地址偏移量有三种形式:
- 立即数,偏移量是一个立即数,该数值与基址寄存器相加或相减得到操作数地址
- 寄存器,偏移量是另外一个寄存器的数值,该数值与基址寄存器中数值相加或相减得到操作数地址
- 寄存器移位,偏移量是另外一个寄存器中数值经过移位运算得到的数值,并与基址寄存器中数值相加或相减得到操作数地址
LDR:从存储器特定位置读取32比特数值后存入指定的寄存器
STR:把指定寄存器的数值保存到存储器的特定位置
举例:
xxxxxxxxxxLDR R0, [R1, #4] ;将R1中的值加4形成操作数的地址,取得的操作数送入R0,R1值不变LDR R0, [R1, R2] ;R1中的值加上R2中的值形成操作数地址,取得的操作数送入R0,R1和R2值不变STR R0, [R1, -R2, LSL #4];R1中的数值减去R2中的值x16,形成操作数地址,取得的操作数送入R0,执行后R1和R2的值不变
采用寄存器偏移寻址的LDR指令的典型汇编语法可存在如下三种形式:
LDR <Rt>, [<Rn> {,#<imm>}]LDR <Rt>, [<Rn>, <Rm>]LDR <Rt>, [<Rn>, <Rm> {,LSL #<shift>}]
其中,<Rn>表示基址寄存器,而<offset>表示偏移量,偏移量可以是:
- 5位立即数
<imm5>或8位立即数<imm8>或12位立即数<imm12> - 寄存器值
<Rm> - 寄存器值移位
#<shift>
6.3.6. 前变址寻址
前变址寻址方式:在执行指令的时候自动把基址与偏移加和形成的操作数地址写回到基址寄存器
前变址:基址寄存器中的数值和立即数偏移量的加和计算发生在寻址前
汇编语法:
xxxxxxxxxxopcode Rd[<Rn>, <offset>]!
"!"后缀表示指令完成时更新存放基地址的基址寄存器(写回)
举例:
xxxxxxxxxxLDR R0,[R1,#4] ;将R1中的值加4形成操作数的地址,取得的操作数送入R0,R1不变LDR R0,[R1,#4]! ;与上一条指令的区别:执行后R1=R1+4LDR R0,[R1,R2] ;R1中的值加上R2中的值形成操作数地址,取得的操作数送入R0LDR R0,[R1,R2]! ;与上一条指令的区别:执行后R1=R1+R2
6.3.7. 后变址寻址
后变址寻址:在执行指令的时候,操作数地址从基址寄存器获取,指令执行后再将操作数地址加上偏移量生成一个新的地址,并将该新地址写入基址寄存器
后变址:指令中的偏移量在存储器访问期间不会用到,而是在数据传输后更新基址寄存器
汇编语法:
xxxxxxxxxxopcode Rd [<Rn>],<offset>
示例:
xxxxxxxxxxLDR R0,[R1,#4] ;将R1中的值加4形成操作数的地址,取得的操作数送入R0LDR R0,[R1,#4]! ;与上一条指令的区别:“!”表示指令执行后操作数地址存入R1LDR R0,[R1],#4 ;R1中的值做操作数地址,取得操作数送入R0,R1=R1+4
6.3.8. 多寄存器寻址
从一块连续的存储器区域装载多个数据到多个寄存器中
汇编语法:
xxxxxxxxxxLDM/STM{addr_mode} <Rn>{!},<registers>
其中,<Rn>为基址寄存器,<registers>为需要载入数据的寄存器集合,可选项{!}表示需要将修改后的地址写入基址寄存器<Rn>。可选后缀{addr_mode}可选择如下四种方式(Cortex-M3/M4只支持IA和DB方式)
- IA(Increment address After each access),每取一个操作数后基址寄存器递增
- IB(Increment address Before each access),每取一个操作数前基址寄存器递增
- DB(Decrement address Before each access),每取一个操作数前基址寄存器递减
- DB(Decrement address After each access),每取一个操作数后基址寄存器递减
LDM:可以从连续的存储区域转载多个数据
STM:将一组寄存器中的数值保存到连续的存储器区域
举例:
xxxxxxxxxxLDMIA R0!,{R1,R2,R3,R4} ;将连续存储单元的32比特数值传送到R1~R4LDMIA R0!,{R1-R4} ;与上一条指令功能完全相同STMIA R0!,{R1-R7} ;R1~R7的数保存到R0指向的地址,每取一个数后R0递增4STMIB R0!,{R1-R7} ;R1~R7的数保存到R0指向的地址,每取一个数前R0递增4STMDA R0!,{R1-R7} ;R1~R7的数保存到R0指向的地址,每取一个数后R0递减4STMDB R0!,{R1-R7} ;R1~R7的数保存到R0指向的地址,每取一个数前R0递减4
6.3.9. 堆栈寻址
如果把前述多寄存器寻址方式中LDM和STM指令中的基址寄存器更换为堆栈指针寄存器SP,并添加{!}(意为每次存/取操作数就更新一下SP),则寻址操作数为堆栈中存放的数值,寻址方式变成堆栈寻址
LDM:每次取操作数自动POP堆栈中的数据到指定寄存器
STM:每次将寄存器中的数自动PUSH到堆栈中
Cortex-M系列处理器支持满递减类型的堆栈,可以使用LDMFD指令从堆栈装载数据,使用STMFD指令保存数据到堆栈(如果堆栈类型是满增、空减或空增,则后缀应该为FA,ED或EA)
举例:
xxxxxxxxxxSTMFD SP!,{R1-R7} ;将R1~R7寄存器中的数压入堆栈LDMFD SP!,{R1-R7} ;将堆栈中的数取出存入R1~R7寄存器
6.3.10. PC相对寻址
PC相对寻址是一种特殊的基址变址寻址,常简称为相对寻址
PC相对寻址以程序计数器PC寄存器的当前值作为基地址,指令中的地址标号作为偏移量,将两者相加获得操作数的地址
偏移量的表示方法:
- 汇编语句标号(Label)
- 存储器代码区数据块(文本池)相对当前代码的位置
示例1:
用BL指令跳转到“MY_SUB”标号对应的语句执行
xxxxxxxxxxBL MY_SUB ;相对寻址,跳转到MY_SUB处执行... ;其他指令MY_SUB ADD R0,R0,R1 ;转移目标指令... ;其他指令
示例2:
用ADR指令获取PC相对寻址结果
xxxxxxxxxxstart MOV R0,#10 ;start是标号... ;其他指令ADR R2,start ;将标号为“start”语句的地址送入R2
示例3:
利用LDR指令将相对当前代码位置后1-2字节位置的一个字数据(32位)传送到R0寄存器
xxxxxxxxxxLDR R0,[PC,#0xC]
6.4. Cortex-M3/M4指令集
6.4.1. 处理器内的数据传送指令
实现处理器内部不同电路单元之间的数据传送
- 将数据从一个寄存器送到另外一个寄存器
- 通用寄存器和特殊功能寄存器之间传送数据
- 将立即数送到寄存器
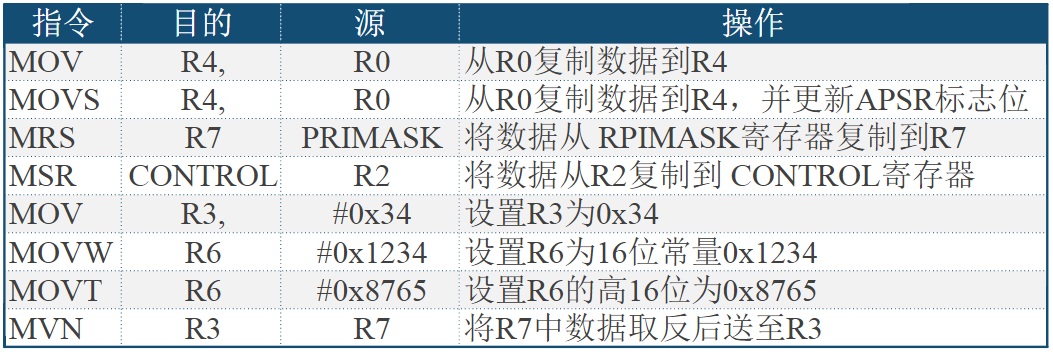
MOVW:把16位任意立即数传送到目的寄存器的低16位,高16位清0
MOVT:把16位任意立即数传送到目的寄存器的高16位,低16位不变
使用MOVW和MOVT指令可以将任意的32位立即数传送到32位寄存器
- 有些汇编器会根据立即数的大小,如果是9-16位,MOV和MOVS会自动转成MOVW
6.4.2. 存储器访问指令
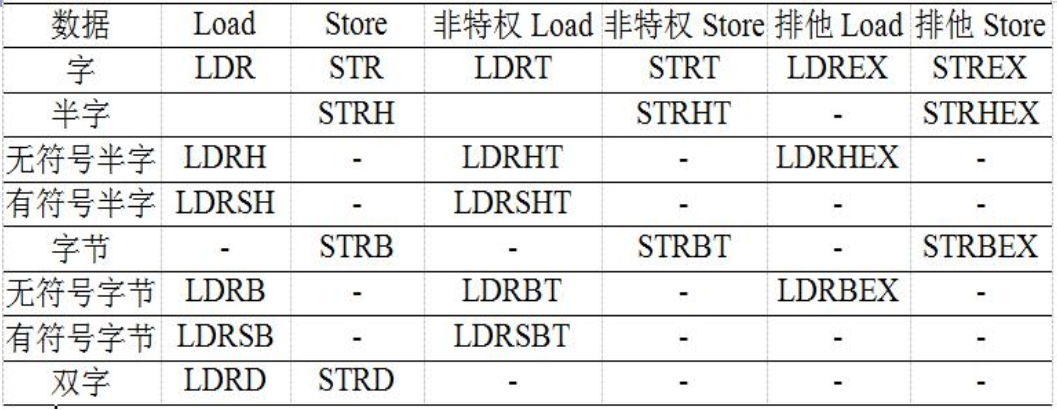
有多条Load/Store指令用于存储器访问
寻址模式:立即数寻址、寄存器寻址、寄存器移位寻址、寄存器间接寻址、基址变址寻址、多寄存器寻址(块拷贝寻址)、堆栈寻址、PC相对寻址
安全性增强:即使是特权访问等级程序,如果使用非特权的LDRT或者STRT指令,也只能访问非特权访问等级才能访问的区域,否则将引起Fault异常
排他访问增强
操作数类型
操作数类型:
- 无符号:字节(8bits)、半字(16bits)、字(32bits)、双字(64bits)、多字
- 有符号:字节(8bits)、半字(16bits)、字(32bits)、双字(64bits)
可存储的数据类型:字节、半字、字
读/写存储器操作支持的数据类型:
- 32-bit指针
- 无符号/有符号的32位整数
- 无符号的16-bit或8-bit整数,需要零扩展
- 有符号的16-bit或8-bit整数,需要符号扩展
- 无符号/有符号的64-bit整数,由2个寄存器保存的多个32-bit数
零扩展:在高位补零,如1000 1010 → 0000 0000 1000 1010
符号扩展:用于保护有符号数的符号位,如
- 0000 1010 → 0000 0000 0000 1010
- 1000 1010 → 1111 1111 1000 1010
使用LDRSB或LDRSH将一个字节或半字数据加载到32位寄存器,会对被加载数据自动执行符号位扩展,如
LDRSB R7, 0x83,数据加载前会被转换为0xFFFF FF83LDRSB R7,0x03,数据加载前会被转换为0x0000 0003
不同的寻址方式——以LDRB为例
偏移寻址(Offsetaddressing)模式
xxxxxxxxxxLDRBRd,[Rn,#offset];从存储器位置[Rn]+offset读取字节前变址(Pre-indexedaddressing)寻址模式
xxxxxxxxxxLDRBRd,[Rn,#offset]!;从[Rn]+offset读取字节,然后更新Rn为Rn+offset后变址(Post-indexedaddressing)寻址模式
xxxxxxxxxxLDRBRd,[Rn],#offset;读取[Rn]处的字节到Rd,然后更新Rn为Rn+offset寄存器移位寻址(Shiftsappliedtoaregister)模式
xxxxxxxxxxLDRBRd,[Rn,Rm,LSL#n)];从存储器位置Rn+(Rm<<n)处读取字节
多加载和多存储指令

ARM处理器的一个重要特性,可以读(LDM指令)或者写(STM指令)存储器中的多个连续数据
- Cortex-M3/M4只支持IA和DB两种地址变更方式
- 只能支持32位传送
- EA和FD表示“空递增”和“满递减”两种堆栈类型
堆栈操作
对于FD型堆栈,以下两条指令等价(Equivalent)
xxxxxxxxxxPUSH<cond><q><registers>STMDB<cond><q>SP!,<registers>例如:
xxxxxxxxxxPUSH{R0,R4-R6,R8};将R0、R4、R5、R6和R8压入栈中
对于FD型堆栈,以下两条指令等价
xxxxxxxxxxPOP<cond><q><registers>LDMIA<cond><q>SP!,<registers>例如:
xxxxxxxxxxPOP{R1,R2};将栈中内容存入R1和R2
PC相对寻址模式
如果使用PC寄存器作为基地址,再加上偏移量形成待访问操作数地址。常用于将立即数加载到寄存器中,如前述的文本池(Literal Pool)访问
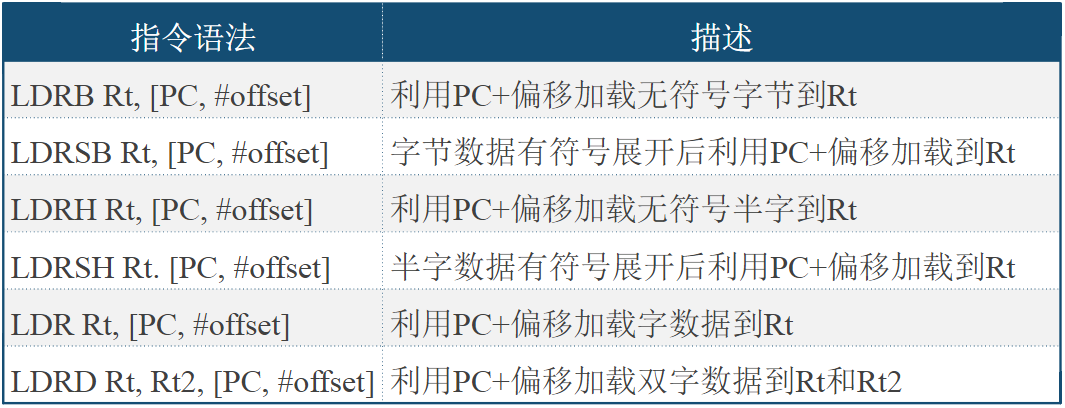
非特权等级加载和存储
ARM中提供了一组特殊的加载和存储指令,在特权访问等级程序中使用这些指令加载或保存的数据,如同非特权访问等级程序的访问效果
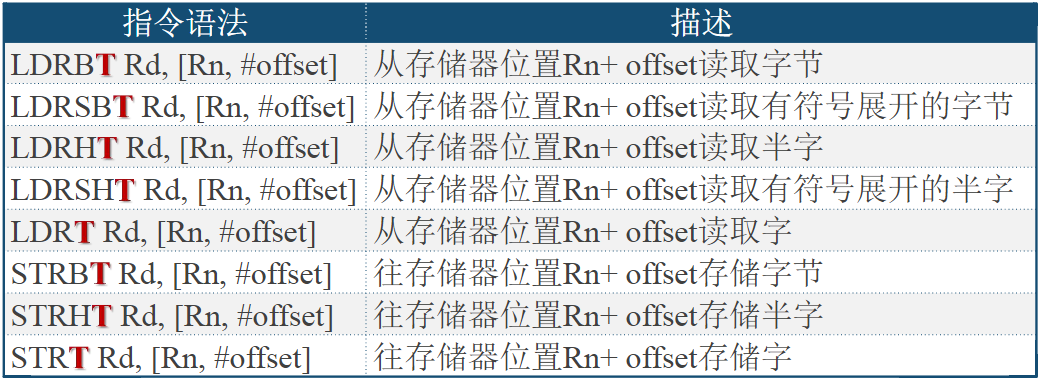
排他式访问
xxxxxxxxxxLDREX Rx,[Ry];排他加载,[Ry]→Rx,同时对Ry指向的内存区域标记独占访问,如果执行时发现已被标记,对指令执行没有影响
xxxxxxxxxxSTRRx,Ry,[Rz];排他存储,Ry→[Rz],如果成功,则将Rx更新为0;若不成功,则将Rx置1
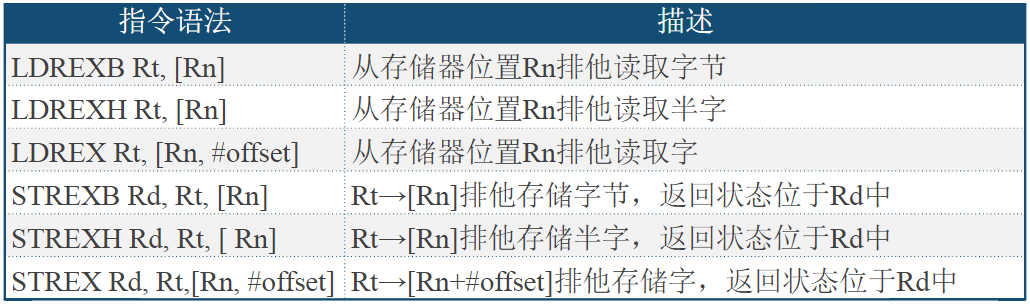
6.4.3. 算术运算指令
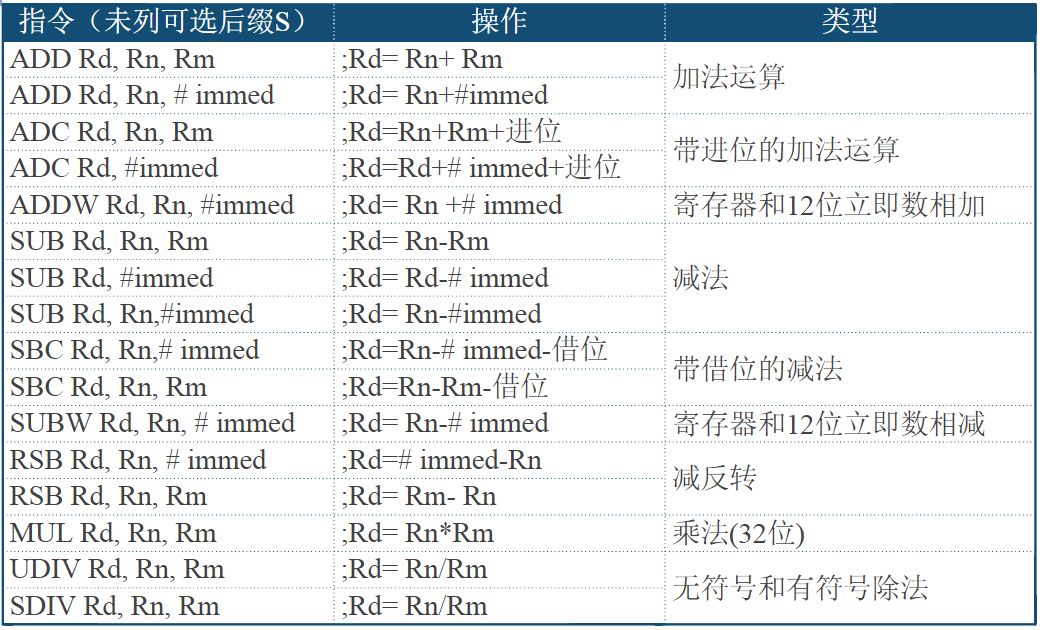
- 后缀不同,进位方式以及对APSR标志位的影响不一样,对应的二进制机器码也不同
- 按照传统的Thumb汇编语法,在使用16位Thumb代码时,ADD指令将修改APSR中的标志
- 32位Thumb-2指令可以修改这些标志,也可以不修改
- 为区分这两种操作,建议使用统一汇编语言UAL语法,如需更新ASPR标志位,应使用S后缀
xxxxxxxxxxADD R0,R0,R1 ;R0=R0+R1,不修改APSRADDS R0,R0,0x12 ;R0=R0+0x12,更新APSRADC R0,R1,R2 ;R0=R1+R2+进位,不修改APSR
Cortex-M3/M4都支持具有32位和64位结果的32位乘法指令和乘加(MAC)指令,APSR标志不受这些指令的影响。Cortex-M4处理器还支持额外的快速MAC指令
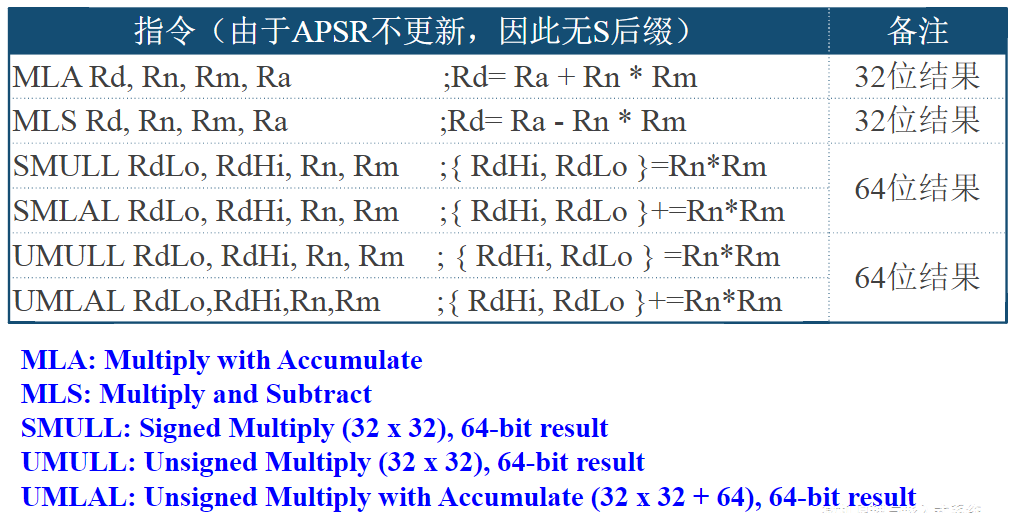
6.4.4. 逻辑运算指令
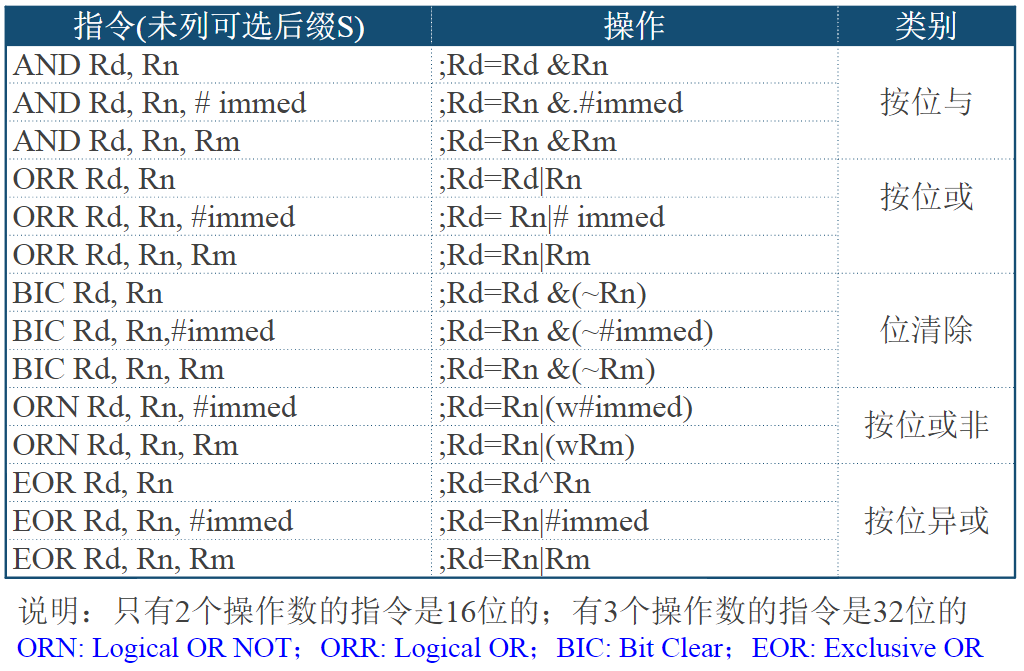
BIC(位清除)指令的一般格式:
xxxxxxxxxxBIC{条件}{S} Rd,Rn,Operand2
该指令将Rn与Operand2的反码按位相“与”,结果存入Rd,该指令常用于将Rn的某些位清零
- 例1:
BIC R1,R1,#0xF0000000 ;将R1高4位清零 - 例2:
BIC R2,R3,#0x0F;将R3低4位清0结果存入R2
- 例1:
说明:如果使用16位指令,只要2个操作数,目的操作数必须是源操作数之一,而且只能是低位寄存器(R0~R7)
ORN(按位或非)没有16位指令,该指令将源操作数按位取反后,再执行按位进行逻辑或运算
6.4.5. 移位运算
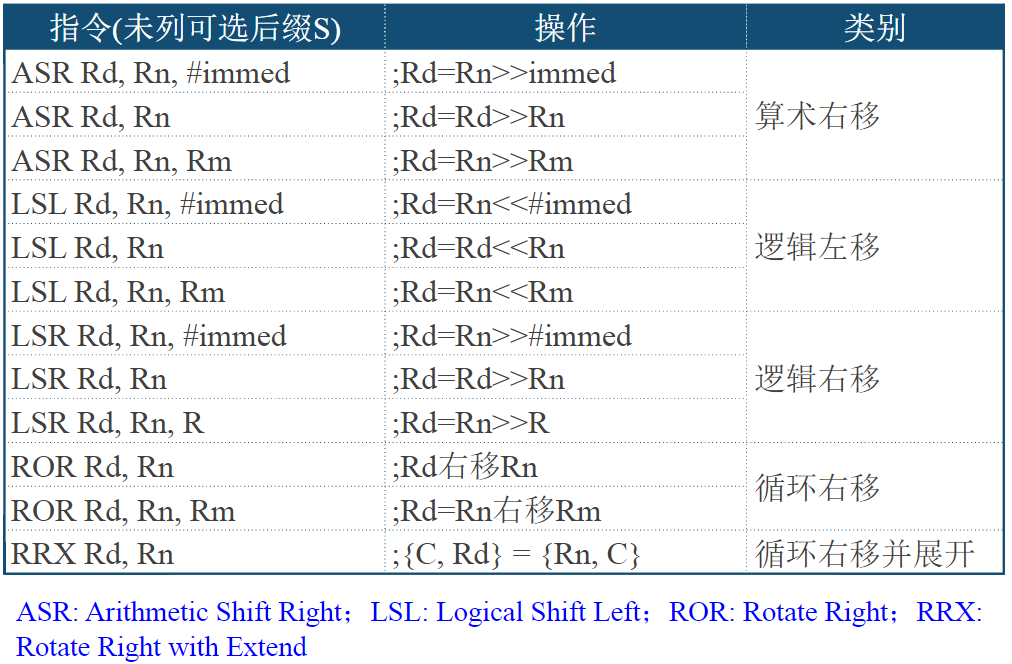
若使用S后缀,循环和移位指令也会更新APSR中的进位标志位;多位移位运算之后,进位位为最后移出寄存器的哪一位
只有循环右移而没有循环左移的原因:
- 循环左移可以使用一定次数的循环右移代替
- 例如,循环左移6位可以使用循环右移26位代替,目的寄存器中的内容相同,执行时间也相同,只是标志位可能不同
除了RRX(包含进位位的循环右移)指令以外,移位与运算指令还有16位版本,但是16位版本只能使用低位寄存器(R0~R7)
6.4.6. 数据格式转换
符号扩展与无符号扩展

上述指令也有16位和32位两种形式,16位指令只能访问低位寄存器,32位可以访问高位寄存器
例:若R0为0x55AA8765,以下指令执行后R1的数值:
xxxxxxxxxxSXTB Rl,R0`;R1=0x00000065,只转换R0中的0x65SXTH R1,R0`;R1=0xFFFF8765,只转换R0中的0x8765UXTB Rl,R0`;R1=0x00000065,只转换R0中的0x65UXTH R1,R0`;R1=0x00008765,只转换R0中的0x8765
上述指令的32位形式还可以选择在有符号扩展运算之前将Rn循环右移

数据反转指令:常用于大小端数据转换

示例:
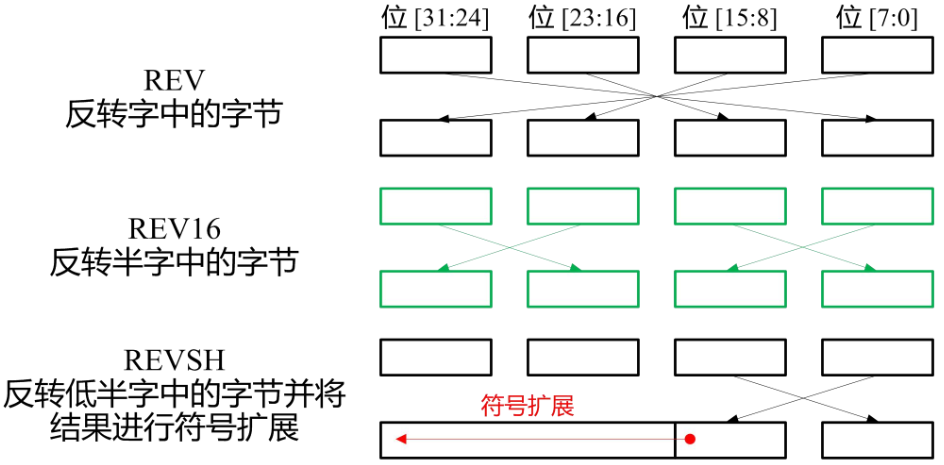
例:假设R0为0x12345678,则有:
xxxxxxxxxxREV R1,R0 ;R1变为0x78563412REVH R2,R0 ;R2则会变为0x34127856REVSH R3,R0 ;R3则会变为0x0000785684
6.4.7. 位域处理指令
位域处理指令用于控制类用于
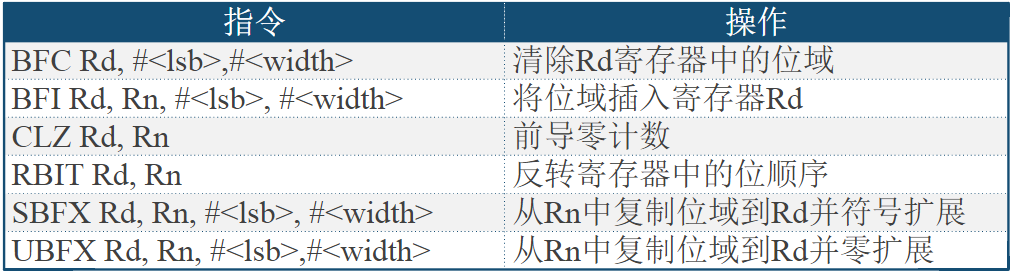
BFC(位域清除)指令:清除Rd中位置由
<lsb>指定的宽度位<width>的相邻域例:假设R0=0x1234FFFF
xxxxxxxxxxBFC R0,#4,#8 ;执行后R0=0x1234F00F
BFI(位域插入)指令:将Rn中的1~31位(
#width)插入到Rd中由#lsb(最低位)指定的位置例:假设R0=0x24681357,R1=0x89ABCDEF
xxxxxxxxxxBFI R0,R1,#8,#16 ;将R1的[15:0]插入R0[23:8]中;执行后R0=0x24CDEF57
CLZ指令:计算Rn中前导零的个数,结果存入Rd
- 常用于数据归一化处理之前,确定需要移位的位数
- 如果Rn全为1,Rd=0;若Rn全为0,Rd=32
RBIT(反序)指令:将Rn中的字数根据反序后存入Rd
例如:假设R1=0b1100 0011 1010 0101 1011 1101 1000 0001
xxxxxxxxxxRBIT R0,R1 ;R0=0b1000 0001 1011 1101 1010 0101 1100 0011
SBFX/UBFX指令:将Rn中从
#lsb起提取宽度为#width的位域复制到Rd中,并进行符号展开/零展开
6.4.8. 比较和测试指令
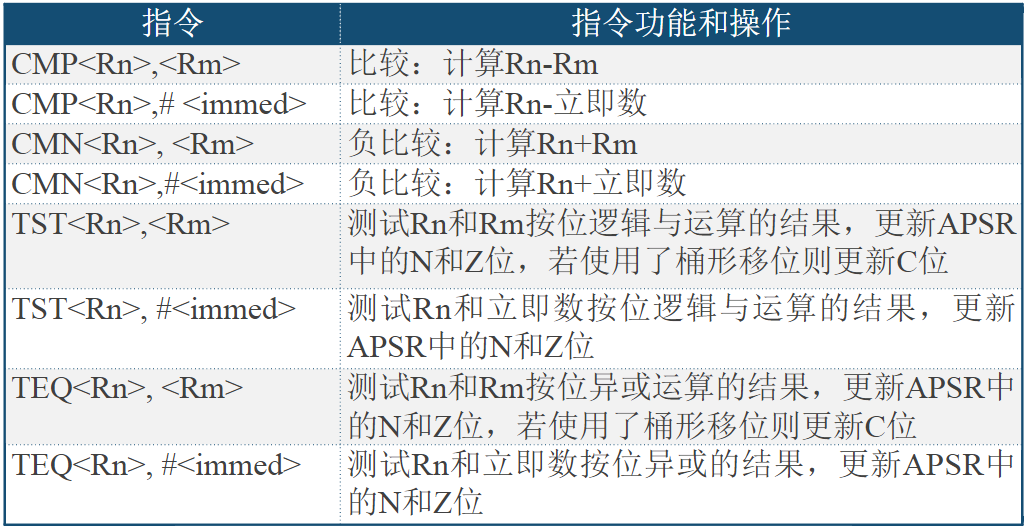
上述指令运行后将更新APSR而不保存运算结果
这些指令的后续指令往往是条件跳转和条件执行指令
6.4.9. 程序流控制指令
包括无条件跳转和函数调用、条件跳转、比较和条件组合跳转、条件执行(IF-THEN)、以及表格跳转等
6.4.9.1. 无条件跳转和函数调用指令
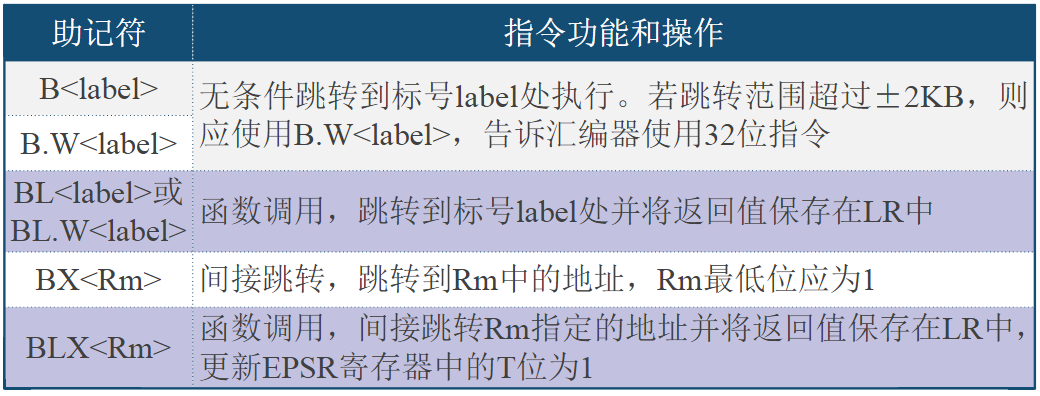
更新PC的数据处理指令(如MOV、ADD),或写入PC的加载指令(如LDR、LDM、POP)也可以引起跳转,但不常用
关于函数调用指令的说明
- BL和BLX指令将返回地址存入LR(R14)之后,会覆盖LR原来的内容,如果原来LR的内容需要保护,则应在执行函数调用指令之前将LR的内容压栈保存
- 如果调用的是按照AAPCS(ARM架构过程调用标准)编写的C语言函数,可能还会用到R0~R3和R12寄存器,这些寄存器的内容也需要压栈保存
- 注意:传统ARM处理器中有一条
BLX<label>指令,(不同于Cortex-M3/M4的BLX<Rm>),该指令执行跳转并总是切换状态。由于Cortex-M3/M4只有Thumb状态,所以不支持BLX<label>指令
6.4.9.2. 条件跳转
基于APSR当前的标志位决定是否跳转

cond为以下14个可能的条件后缀之一

6.4.9.3. 比较和跳转
ARMv7架构增加了两条比较跳转指令

说明:相当于CMP和BEQ/BNE的组合。只能向前跳转,不能向后跳转,跳转范围为当前指令后的4~130字节,且只能使用R0~R7,常用于小范围的循环控制,如:

6.4.9.4. 条件执行
IT指令允许跟随其后的最多四条指令是条件执行的,IT指令后的几条指令被称作一个IT块
IT指令的汇编语法为:
xxxxxxxxxxIT {x{y{z}}} cond
cond为IT块中第1条指令使用的条件码x指定IT块中第2条指令的是否执行的开关y指定IT块中第3条指令的是否执行的开关z指定IT块中第4条指令的是否执行的开关
x,y和z对应有两种开关:
- T-Then,条件成立则执行
- E-Else,条件不成立则执行
增加不同位数后缀的IT指令(IT+T和E的各种组合)
- 只有1个条件:IT,“If-Then”,以下1条指令条件执行
- 有2个条件:ITT、ITE,以下2条指令条件执行
- 有3个条件:ITTT、ITTE、ITET、ITEE,以下3条指令条件执行
- 有4个条件:ITTTT、ITTTE、ITTET、ITETT、ITTEE、ITEET、ITETE、ITEEE,以下4条指令条件执行
示例:
例1
xxxxxxxxxxIT EQ ;意为“If-Then”,下条指令条件执行ADDEQ R0,R1,R2 ;若Z=1,则(R1+R2)→R0例2
xxxxxxxxxxITETT NE ;“If-Then-Else-Then-Then”,随后四条指令条件执行ADDNE R0,R0,R1 ;若Z=0(不等),则(R0+R1)→R0ADDEQ R0,R0,R3 ;若Z=1,则(R0+R3)→R0ADDNE R2,R4,#1 ;若Z=0,则(R4+1)→R0MOVNE R5,R3 ;若Z=0,R3→R5
注意:
- 对于多个汇编工具,代码中无需使用IT指令!只要给普通指令增加条件后缀,汇编器(如MS-5以及KeilMDK-ARM)会在前面自动加入IT
- B指令的二进制编码格式中预留了4比特的条件码,故与一般的条件执行指令(如MOVEQ)不同,不需要与IT指令配合,条件跳转指令也可以执行
6.4.9.5. 按跳转表跳转
跳转表的意义:
- 汇编编程直接实现类似C语言中switch(case)的多分支跳转控制十分困难,因为跳转目标地址与某个变量有关
- 如果预先定义一个数组(跳转表),每个数组元素是一个目标地址,那么通过改变数组下标,就可以通过数组元素得到不同的目标地址
Cortex-M3/M4支持两条表格跳转指令:
- TBB:按照字节为单位的跳转表进行跳转
- TBH:按照半字为单位的跳转表进行跳转
6.4.10. 饱和运算
定点运算中经常遇到运算结果溢出的情况,有上溢和下溢两种
溢出运算:
- 传统运算方式(环绕式运算)的处理通常是自动回到计数零点
- 饱和运算:当达到最大值/最小值时不再增加/减少,而是保持在这个最大值/最小值上
- 只要加、减指令才有饱和方式
- 例如:在图像和图形处理中,用8位无符号数表示一个象素值或颜色分量值,最大数255表示亮度的最大值,如果运算结果超出这个范围,仍然表示为“最亮”是符合实际情况的
Cortex-M3支持以下两条饱和运算指令:
- SSAT:有符号数饱和运算指令
- USAT:无符号数饱和运算指令
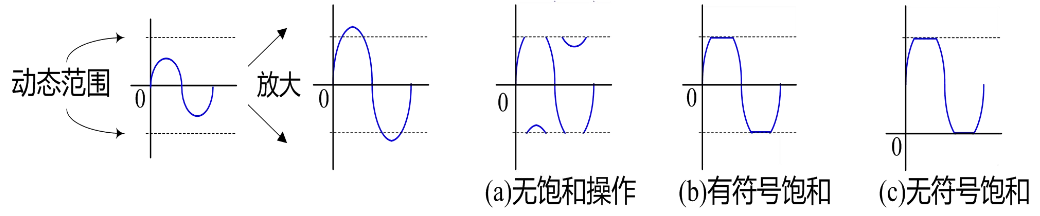
- 除了以上两条饱和运算指令以外,Cortex-M4还拥有十多条饱和运算指令,其中有些指令还支持SIMD
SSAT和USAT的汇编格式:
xxxxxxxxxxSSAT<Rd>,#<immed>,<Rn>,{,<shift>};有符号饱和USAT<Rd>,#<immed>,<Rn>,{,<shift>};无符号饱和
其中:
<Rn>为输入值<shift>为饱和前可选的移位操作,可为LSL #n或ASR #n<Rn>为目的寄存器#immed为执行饱和的位的位置
如果运算过程中出现了饱和,ASPR中的Q位置1
示例:
例1:如果需要将一个32位有符号数饱和为16位有符号数,可以使用如下指令
xxxxxxxxxxSSAT R1,#16,R0例2:如果需要将一个32位有符号数饱和为16位无符号数,可以使用如下指令
xxxxxxxxxxUSAT R2,#16,R0
当R0为不同数值时,SSAT和USAT指令执行后,R1和R2的值以及Q位如下表所示
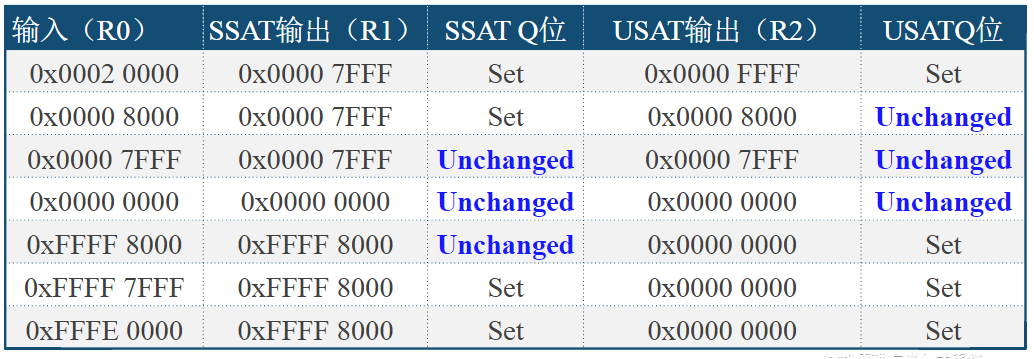
6.4.11. 其他杂项指令
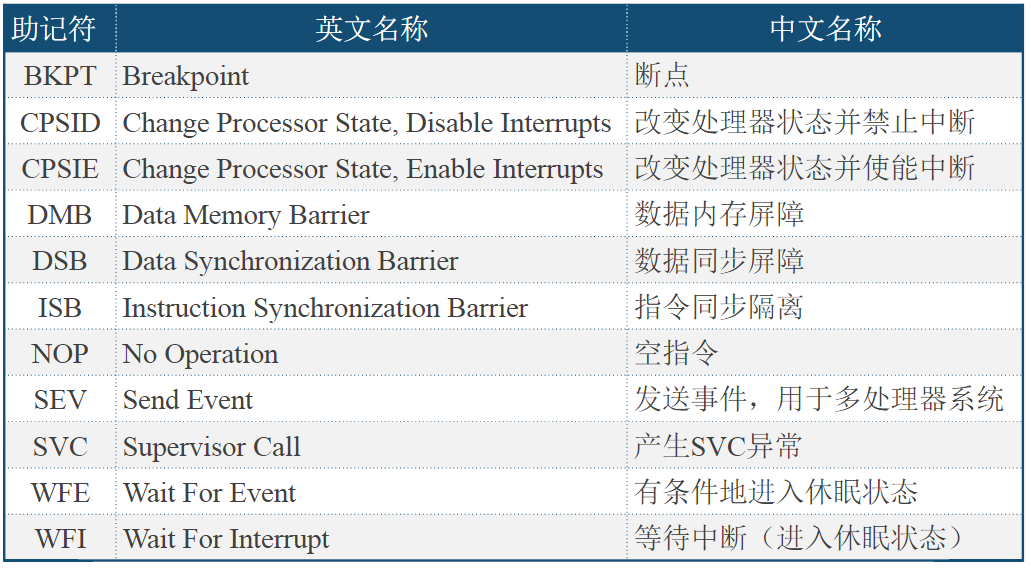
6.4.11.1. 休眠模式指令
- WFI指令会使处理器立即进入休眠模式,中断、复位或调试操作可以将处理器从休眠中唤醒
- WFE会使处理器有条件地进入休眠。在Cortex-M3/M4处理器内部,有一个只有一位的寄存器会记录事件。若该寄存器置位,WFE指令不会进入休眠而只是清除事件寄存器并继续执行下一条指令;若该寄存器清零,则处理器会进入休眠而且会被事件唤醒,事件可以是中断、调试操作、复位或外部事件输入的脉冲信号
- SEV指令可用于发送事件,多处理器系统中可用于向其他处理器传递信号。Cortex-M处理器的接口信号包括一个事件输入和一个事件输出。处理器的事件输入可由多处理器系统中其他处理器的事件输岀产生,因此,处于WFE休眠的处理器可由其他的处理器唤醒
6.4.11.2. 异常相关指令
管理调用(SVC)指令用于产生SVC异常(异常类型为11)。SVC一般用于嵌入式操作系统(OS),其中,非特权应用可以请求使用具有特权OS提供的服务(类似于x86系统中的系统功能调用)
SVC指令要求SVC的优先级高于当前优先级,并且没有被PRIMASK等寄存器屏蔽
SVC指令格式:
SVC #<immed>- 其中
immed为8位立即数,是OS定义的系统功能调用号
- 其中
另一个和异常相关的指令是CPS指令,用于改变处理器状态。使用这条指令可以设置或清除PRIMASK和FAULTMASK等中断屏蔽寄存器
6.4.11.3. 空指令和断电指令
Cortex-M支持NOP指令,用于产生指令对齐或延时
- 注意,NOP指令产生的延时在不同系统间可能会存在差异。若需精确延时,应使用硬件定时器
在软件开发/调试过程中,断点(BKPT:Breakpoint)指令用于实现应用程序中的软件断点
- 若程序在SRAM中执行,则该指令一般由调试器插入以替换原有的指令
- 当到达断点时,处理器会被暂停,然后调试器就会恢复原有的指令,用户也可以通过调试器执行调试任务
- BKPT指令也可以用于产生调试监控异常,它具有一个8位立即数,调试器或调试监控异常可以将该数据提取出来,并根据该信息确定要执行的动作
6.4.12. Cortex-M4特有指令
与Cortex-M3处理器相比,Cortex-M4支持的指令更多。新增的功能包括:单指令多数据(SIMD)、饱和指令、其他的乘法和MAC(乘累加)指令、打包和解包指令、可选的浮点指令等。这些指令可以让Cortex-M4可以更加高效地进行实时数字信号处理
- 往往对数组的不同元素做相同的运算
- 循环体内往往是两个操作数相乘之后进行累加
- 往往操作数动态范围很大,用的是浮点数
7. ARM程序设计
目前基于ARM处理器的程序大多采用C语言开发
- 无操作系统:while语句无限循环体内功能实现+中断
- 有操作系统:μC/OS、Linux、Android进行任务调度
特定场合下必须使用汇编语言(系统启动程序)
7.1. ARM程序开发环境
7.1.1. 常用ARM程序开发环境
分类
基于Windows平台
- SDT(ARM Software Development Kit)是ARM公司最早推出的开发工具
- ADS (ARM Developer Suite)由ARM公司约1999年推出,用来代替SDT
- RealView Developer Suite,是ARM公司继ADS之后推出的集成开发工具
- RealViewMDK(Microcontroller Development Kit)
- ARM Development Studio 5
基于Linux平台
- ARM-Linux-GCC
其他分类方法
- 开源软件,典型如ARM-Linux-GCC
- 商业软件,ARM公司推出的软件工具
ARM官方提供的软件
KeilMDK
- Software development package for Arm-based microcontrollers
Arm Development Studio
- Software development tool suite for any Arm-based project
Compiler
- Embedded C/C++ toolchain, from Armv6 M to Armv8-A 64-bit
KeilRTX5
- Real-time operating system implementing the CMSIS-RTOS APIv2
Software Test Libraries
- Efficient processor specific test suites enabling on-line processor testing
FuSaRTS
- Run-time system for embedded functional safety applications
ARM-Linux-GCC
GNU Compiler Collection(GCC)是一套由GNU开发的编译器集,不仅支持C语言编译,还支持C++、Ada、Object C等许多语言。GCC还支持多种处理器架构,包括X86、ARM、和MIPS等处理器架构,是在Linux平台下被广泛使用的软件开发工具
GNU:是“GNU is Not Unix”的递归缩写,是一个自由软件工程项目。这些软件在GNU通用公共许可的保护下允许任何人免费使用和传播(但必须同时提供源程序),GNU软件许可相当宽松,有很多公司利用GNU软件进行商业活动
ARM-Linux-GCC是基于ARM目标机的交叉编译软件,所谓交叉编译简单来说就是在一个平台上生成另一个平台上的可执行代码
- 平台实际上包含两个概念:体系结构(Architecture)和操作系统(OS)
- 同一个体系结构可以运行不同的操作系统;同样,同一个操作系统也可以在不同的体系结构上运行
- 一个常见的例子是:嵌入式软件开发人员通常在个人计算机上为运行在基于ARM、PowerPC或MIPS的目标机编译软件
ARM-Linux-GCC使用命令行来调用命令执行
- 相比于RVDS和MDK等IDE而言上手较难。但由于ARM-Linux-GCC不需要授权费用,因而受到使用Linux开发嵌入式系统应用工程师的欢迎
MDK
MDK由Keil公司推出
- Keil公司是一家业界领先的MCU软件开发工具的独立供应商,最流行的单片机开发工具KeilC51就是Keil公司出品的
MDK主要特点:
- 支持内核:ARM7,ARM9,Cortex-M4/M3/M1,Cortex-R0/R3/R4等ARM微控制器内核,后续可能变化
- IDE:μVision IDE
- 编译器:ARM C/C++编译器(armcc)
- 仿真器:μVision CPU & Peripheral Simulation
- 硬件调试单元:ULink/JLink
ARM Development Studio 5(DS-5)
DS-5是一款支持开发所有ARM内核芯片的IDE,主要特点如下:
- 支持内核:全部
- 定制的Eclipse IDE
- 编译器:ARM Compiler 6、ARM Compiler 5、GCC(LinaroGNU GCCCompiler for Linux)
- 调试器:DS-5调试器支持ETM指令和数据跟踪、PTM程序跟踪
- 仿真器:DS-5支持ULINK2、ULINKPRO和DSTREAM仿真器
MDK vs DS-5
不同的应用领域
- MDK可满足开发者基于ARM7/9,ARM Cortex-M处理器的开发需求,包括它自带的RTX实时操作系统和中间库,都是属于MCU应用领域的
- DS-5是用于创建Linux/Andriod的复杂嵌入式系统应用和系统平台驱动接口,DS-5支持设备添加,包括多核调试和支持,主要针对复杂的多核调试、片上系统开发而推出的
使用经验
- 如果需要做MCU应用,推荐用KEILMDK
- 如果需要做片上系统、Linux/Android驱动和应用开发,推荐使用DS-5+DSTREAM
- 用户可以根据自己的功能需求、使用习惯(比如很多从单片机开发转到嵌入式开发的开发者更习惯使用MDK)、开发用途等选择不同的开发环境
7.1.2. MDK开发环境简介
- MDK-ARM
- μVision IDE
Keil MDK的软件开发周期
- 创建工程,选择目标芯片,并且做一些必要的工程配置
- 编写C或者汇编源文件
- 编译应用程序
- 修改源程序中的错误
- 联机调试
μVision集成开发环境
μVision IDE是一款集编辑、编译和项目管理于一身的基于窗口的软件开发环境
μVision集成了C语言编译器,宏编译,链接/定位,以及HEX文件产生器。
μVision特性:
- 功能齐全的源代码编辑器
- 配置开发工具的设备库
- 用于创建工程和维护工程的项目管理器
- 所有的工具配置都采用对话框进行
- 集成了源码级的仿真调试器,包括高速CPU和外设模拟器
- 用于往Flash ROM下载应用程序和Flash编程工具
- 完备的开发工具帮助文档,设备数据表和用户使用向导
ARM仿真器
仿真器可以替代目标系统中的MCU,仿真其运行。它运行起来和实际的目标处理器一样,但是增加了其它功能,使用户能够通过计算机或其它调试界面来观察MCU中的程序和数据,并控制MCU的运行,它是调试嵌入式软件的一个经济、有效的手段
具有以下优点:
- 不使用目标系统或CPU资源
- 硬件断点、跟踪功能
- 条件触发
- 实时显示存储器和I/O口内容
- 硬件性能分析
7.2. ARM汇编程序中的伪指令
在ARM汇编语言程序里,有一些特殊指令助记符,这些助记符与指令系统的助记符不同,没有相对应的操作码,通常称这些特殊指令助记符为伪指令,他们所完成的操作称为伪操作
伪指令不像机器指令那样在处理器运行期间由机器执行,而是汇编程序对源程序汇编期间由汇编程序处理,包括:定义变量、分配数据存储空间、控制汇编过程、定义程序入口等,这些伪指令仅在汇编过程中起作用,一旦汇编结束,伪指令的使命就完成了
7.2.1. 符号定义伪指令
符号定义伪指令用于定义ARM汇编程序中的变量、对变量赋值以及定义寄存器的别名等操作。常见的符号定义伪指令有如下几种:
- 用于定义全局变量的GBLA、GBLL和GBLS
- 用于定义局部变量的LCLA、LCLL和LCLS
- 用于对变量赋值的SETA、SETL、SETS
- 为通用寄存器列表定义名称的RLIST
GBLA、GBLL和GBLS
语法格式:
xxxxxxxxxxGBLA (GBLL或GBLS) 全局变量名;
GBLA、GBLL和GBLS伪指令用于定义一个ARM程序中的全局变量,并将其初始化
其中:
- GBLA伪指令用于定义一个全局的数字变量,并初始化为0
- GBLL伪指令用于定义一个全局的逻辑变量,并初始化为F(假)
- GBLS伪指令用于定义一个全局的字符串变量,并初始化为空
以上三条伪指令用于定义全局变量,在整个程序范围内变量名必须唯一
举例:
xxxxxxxxxxGBLA Test1 ;定义一个全局的数字变量,变量名为Test1Test1 SETA 0xaa ;将该变量赋值为0xaaGBLL Test2 ;定义一个全局的逻辑变量,变量名为Test2Test2 SETL{TRUE} ;将该变量赋值为真GBLS Test3 ;定义一个全局的字符串变量,变量名为Test3Test3 SETS “Testing”;将该变量赋值为“Testing”
LCLA、LCLL和LCLS
语法格式:
xxxxxxxxxxLCLA (LCLL或LCLS) 局部变量名;
LCLA、LCLL和LCLS伪指令用于定义一个ARM程序中的局部变量,并将其初始化
其中:
- LCLA伪指令用于定义一个局部的数字变量,并初始化为0
- LCLL伪指令用于定义一个局部的逻辑变量,并初始化为F(假)
- LCLS伪指令用于定义一个局部的字符串变量,并初始化为空
以上三条伪指令用于声明局部变量,在其作用范围内变量名必须唯一
举例:
xxxxxxxxxxLCLA Test4 ;声明一个局部的数字变量,变量名为Test4Test3 SETA 0xaa ;将该变量赋值为0xaaLCLL Test5 ;声明一个局部的逻辑变量,变量名为Test5Test4 SETL {TRUE} ;将该变量赋值为真LCLS Test6 ;定义一个局部的字符串变量,变量名为Test6Test6 SETS “Testing”;将该变量赋值为“Testing”
SETA、SETL和SETS
语法格式:
xxxxxxxxxx变量名 SETA (SETL或SETS) 表达式;
伪指令SETA、SETL、SETS用于给一个已经定义的全局变量或局部变量赋值
其中:
- SETA伪指令用于给一个数字变量赋值
- SETL伪指令用于给一个逻辑变量赋值
- SETS伪指令用于给一个字符串变量赋值
其中,变量名为已经被定义过的全局变量或局部变量,表达式为将要赋给变量的值
举例:
xxxxxxxxxxLCLA Test3 ;声明一个局部的数字变量,变量名为Test3Test3 SETA 0xaa ;将该变量赋值为0xaaLCLL Test4 ;声明一个局部的逻辑变量,变量名为Test4Test4 SETL{TRUE} ;将该变量赋值为真
RLIST
语法格式:
xxxxxxxxxx名称 RLIST {寄存器列表};
RLIST伪指令可用于对一个通用寄存器列表定义名称,使用该伪指令定义的名称可在ARM指令LDM/STM中使用。在LDM/STM指令中,列表中的寄存器访问次序为根据寄存器的编号由低到高,而与列表中的寄存器排列次序无关
举例:
xxxxxxxxxxRegList RLIST {R0-R5,R8,R10};将寄存器列表名称定义为RegList,可在ARM指令LDM/STM中通过该名称访问寄存器列表
7.2.2. 数据定义伪指令
数据定义伪指令一般用于为特定的数据分配存储单元,同时可完成已存储单元的初始化。常见的数据定义伪指令有如下几种:
- DCB用于分配一段连续的字节存储单元并用指定的数据初始化
- DCW(DCWU)用于分配一段连续的半字存储单元并用指定的数据初始化
- DCD(DCDU)用于分配一段连续的字存储单元并用指定的数据初始化
- DCFD(DCFDU)用于为双精度的浮点数分配一段连续的字存储单元并用指定的数据初始化
- DCFS(DCFSU)用于单精度的浮点数分配一段连续的字存储单元并用指定的数据初始化
- DCQ(DCQU)用于分配一段以8字节为单位的连续的存储单元并用指定的数据初始化
- SPACE用于分配一段连续的存储单元
- MAP用于定义一个结构化的内存表首地址
- FIELD用于定义一个结构化的内存表的数据域
DCB
语法格式:
xxxxxxxxxx标号 DCB 表达式;
DCB伪指令用于分配一段连续的字节(8位)存储单元并用伪指令中指定的表达式初始化。其中,表达式可以为0~255的数字或字符串,DCB也可用“=”代替
举例:
xxxxxxxxxxStr DCB "This is a test!" ;分配一段连续的字节存储单元并初始化
DCW(或DCWU)
语法格式:
xxxxxxxxxx标号 DCW(或DCWU) 表达式;
DCW(或DCWU)伪指令用于分配一段连续的半字(16位)存储单元并用伪指令中指定的表达式初始化。其中表达式可以为程序标号或数字表达式
用DCW分配的字存储单元是半字对齐的,而用DCWU分配的字存储单元并不严格半字对齐
示例:
xxxxxxxxxxDataTest DCW 1,2,3 ;分配3个连续的半字存储单元并用1,2,3初始化
DCD(或DCDU)
语法格式:
xxxxxxxxxx标号 DCD(或DCDU) 表达式;
DCD(或DCDU)伪指令用于分配一段连续的字(32位)存储单元并用伪指令中指定的表达式初始化。其中,表达式可以为程序标号或数字表达式,DCD也可用“&”代替
用DCD分配的字存储单元是字对齐的,而用DCDU分配的字存储单元并不严格字对齐
示例:
xxxxxxxxxxDataTest DCD4,5,6 ;分配3个连续的字存储单元并用4,5,6初始化
DCFD(或DCFDU)
语法格式:
xxxxxxxxxx标号 DCFD(或DCFDU) 表达式;
DCFD(或DCFDU)伪指令用于为双精度的浮点数分配一段连续的字存储单元并用伪指令中指定的表达式初始化,每个双精度的浮点数占据两个字单元
用DCFD分配的字存储单元是字对齐的,而用DCFDU分配的字存储单元并不严格字对齐
示例:
xxxxxxxxxxFDataTest DCFD 0.1,0.2,0.3 ;分配3个连续的双字存储单元并初始化为0.1,0.2,0.3的双精度数表达
DCFS(或DCFSU)
语法格式:
xxxxxxxxxx标号 DCFS(或DCFSU) 表达式;
DCFS(或DCFSU)伪指令用于为单精度的浮点数分配一段连续的字存储单元并用伪指令中指定的额表达式初始化,每个单精度的浮点数占据一个字单位
用DCFS分配的字存储单元是字对齐的,而用DCFSU分配的字存储单元并不严格字对齐
示例:
xxxxxxxxxxFDataTest DCFS-0.1,-0.2,-0.3 ;分配3个连续的字存储单元并初始化为-0.1,-0.2,-0.3的单精度数表达
DCQ(或DCQU)
语法格式:
xxxxxxxxxx标号 DCQ(或DCQU) 表达式;
DCQ(或DCQU)伪指令用于分配一段以8个字节为单位的连续存储区域并用伪指令中指定的表达式初始化
用DCQ分配的存储单元是字对齐的,而用DCQU分配的存储单元并不严格字对齐
示例:
xxxxxxxxxxDataTest DCQ 100,101,102;分配3个连续的双字内存单元,并用100D,101D,102D的16进制数据进行初始化
SPACE
语法格式:
xxxxxxxxxx标号 SPACE 表达式;
SPACE伪指令用于分配一片连续的存储区域并初始化为0,其中,表达式为要分配的字节数,SPACE也可用“%”代替
示例:
xxxxxxxxxxDataSpace SPACE 100 ;分配连续100字节的存储单元并初始化为0
MAP
语法格式:
xxxxxxxxxxMAP 表达式 {,基址寄存器};
MAP伪指令用于定义一个结构化的内存表的首地址,可以用“^”代替
表达式可以为程序中的标号或数学表达式,基址寄存器可为可选项,当基址寄存器选项不存在时,表达式的值即为内存表的首地址,当该选项存在时,内存表的首地址为表达式的值与基址寄存器的和
示例:
xxxxxxxxxxMAP 0x100, R0 ;定义结构化内存表首地址的值为0x100+R0
FIELD
语法格式:
xxxxxxxxxx标号 FIELD 表达式;
FIELD伪指令常与MAP伪指令配合使用来定义结构化的内存表。MAP伪指令定义内存表的首地址,FIELD伪指令定义内存表中的各个数据域,并可以为每个数据域指定一个标号供其他的指令引用
表达式的值为当前数据域在内存表中所占的字节数
注意:MAP和FIELD伪指令仅用于定义数据结构,并不实际分配存储单元
示例:
xxxxxxxxxxMAP 0x100 ;定义结构化内存表首地址的值为0x100A FIELD 16 ;定义A的长度为16字节,起始位置为0x100B FIELD 32 ;定义B的长度为32字节,起始位置为0x110S FIELD 256 ;定义S的长度为256字节,起始位置为0x130
7.2.3. 汇编控制伪指令
汇编控制伪指令用于控制汇编程序的执行流程,常用的汇编控制伪指令包括:
- IF、ELSE、ENDIF
- WHILE、WEND
- MACRO、MEND
- MEXIT
IF、ELSE、ENDIF
语法格式:
xxxxxxxxxxIF 逻辑表达式指令序列1ELSE指令序列2ENDIF
IF、ELSE、ENDIF可嵌套使用
示例:
xxxxxxxxxxGBLL Test ;声明一个全局的逻辑变量,变量名为Test......IF Test=TRUE指令序列1ELSE指令序列2ENDIF
WHILE、WEND
语法格式:
xxxxxxxxxxWHILE 逻辑表达式指令序列WEND
WHILE和WEND可以嵌套使用
xxxxxxxxxxGBLA Counter ;声明一个全局的数学变量,变量名为CounterCounter SETA 3 ;由变量Counter控制循环次数......WHILE Counter<10指令序列WEND
MACRO、MEND
语法格式:
xxxxxxxxxxMACRO{$标号} 宏名 {$参数1, $参数2,......}指令序列MEND
MACRO、MEND伪指令可以将一段代码定义为一个整体,两条指令称为宏指令,需要时可以在程序中通过宏指令多次调用这段代码
其中,$标号在宏指令被展开时会被替换成用户定义的符号。宏指令可以使用一个或多个参数,当宏指令被展开时,这些参数被相应的值替换
包含在MACRO和MEND之间的指令序列称为宏定义体,在宏定义体的第一行应声明宏的原型(包含宏名、所需的参数),然后就可以在汇编程序中通过宏名来调用该指令序列。在源程序被编译时,汇编器将宏调用展开,用宏定义中的指令序列代替程序中的宏调用,并将实际参数的值传递给宏定义中的形式参数
宏指令的使用方式和功能与子程序有些香相似,子程序可以提供模块化的程序设计、节省存储空间并提高运行速度。但在使用子程序结构时需要保护现场,从而增加了系统开销。因此,在代码较短且需要传递的参数较多时,可以使用宏指令代替子程序
MACRO、MEND伪指令可嵌套使用
示例:
xxxxxxxxxxMACRO ;宏指令开始$label test $p1,$p2,$p3 ;宏的名称为test,有三个参数p1,p2,p3;宏的标号$label可用于构造宏定义体内的其他标号名称CMP $p1,$p2 ;比较参数p1和p2的大小BHI $label.save ;无符号比较后若p1>p2,跳转到$label.save标号处,;$label.save为宏定义体的内部符号MOV $p3,$p2B $label.end$label.save MOV $p3,$p1$label.end ;宏定义功能即将参数p1,p2无符号比较后的大值存入参数p3MEND ;宏定义结束
上述代码中,宏名为test,标号为$label,有三个参数$p1,$p2,$p3。标号和参数在实际调用中可根据需要替换成不同的符号,而宏名是唯一确定的
调用上述宏的方法:
xxxxxxxxxxabc test R0,R1,R2 ;通过宏的名称test调用宏,宏的标号为abc;三个参数为寄存器R0,R1,R2
汇编处理宏时会展开还原成一段代码,结果如下:
xxxxxxxxxxCMP R0,R1BHI abc.saveMOV R2,R1B abc.endabc.save MOV R2,R0abc.end......
采用宏定义的方法可以用一条语句代替一大段指令序列,提高编程效率
MEXIT
语法格式:
xxxxxxxxxxMACRO ;宏定义开始{$标号} 宏名 {$参数1,$参数2,......}指令序列;IF condition1MEXITELSE指令序列;ENDIF...MEND
7.2.4. 其他常用的伪指令
AREA
语法格式:
xxxxxxxxxxAREA 段名 属性1,属性2,......
AREA伪指令用于定义一个代码段或数据段,段名若以数字开头,则该段名需用“|”括起来,如|1_test|
属性字段表示该代码段(或数据段)的相关属性,多个属性用逗号分隔。常用属性如:
- CODE属性:用于定义代码段,默认为READONLY
- DATA属性:用于定义数据段,默认READWRITE
- READONLY属性:指定本段为只读,代码段默认为READONLY
- READWRITE属性:指定本段为可读可写,数据段默认为READWRITE
- ALIGN属性:使用方式为ALIGN
- COMMON属性:该属性定义了一个通用的段,不包含任何的用户代码和数据。各个源文件中同名的COMMON段共享一段存储单元。一个汇编语言的程序至少要包含一个段,当程序太长时,也可以将程序分为多个代码段和数据段
示例:
xxxxxxxxxxAREA RESET,CODE,READONLY...;该伪指令定义了一个代码段,段名为RESET,属性为只读
ALIGN
语法格式:
xxxxxxxxxxALIGN{表达式{,偏移量}};
ALIGN伪指令可以通过添加填充字节的方式,使当前位置满足一定的对齐方式
表达式的值用于指定对齐方式,可能取值为2的幂,如1,2,4,8,16等。若未指定表达式,则将当前位置对齐到下一个字的位置
偏移量也为一个数字表达式,若使用该字段,假设N=表达式,则当前位置的对齐方式为:2N+偏移量
示例:
xxxxxxxxxxAREA RESET,CODE,READONLY,ALIGN=3 ;指定后面的指令为8字节对齐......END
CODE16、CODE32
语法格式:
xxxxxxxxxxCODE16(或CODE32);
- CODE16:伪指令通知编译器,其后的指令序列为16位的Thumb指令
- CODE32:伪指令通知编译器,其后的指令序列为32位的ARM指令
若在汇编源程序中同时包含有ARM指令和Thumb指令,可用CODE16伪指令通知编译器其后的指令序列为16位的Thumb指令,CODE32伪指令通知编译器其后的指令序列位32位的ARM指令
在使用ARM指令和Thumb指令混合编程的代码中,可用这两条伪指令进行切换,注意他们只通知编译器其后指令的类型,并不能对处理器的状态进行切换
示例:
xxxxxxxxxxAREA RESET,CODE,READONLY......CODE32 ;通知编译器其后的指令为32位的ARM指令LDR R0,=NEXT+1 ;将跳转地址放入寄存器R0BX R0 ;程序跳转到新的位置执行,并将处理器切换到Thumb工作状态......CODE16 ;通知编译器其后的指令为16位的Thumb指令NEXT LDR R3,=0x3FF......END ;程序结束
ENTRY
语法格式:
xxxxxxxxxxENTRY;
ENTRY伪指令用于指定汇编程序的入口点。在一个完整的汇编程序中至少要有一个ENTRY,但在一个源文件里最多只能有一个ENTRY
示例:
xxxxxxxxxxAREA RESET,CODE,READONLYENTRY ; 指定应用程序的入口点......
END
语法格式:
xxxxxxxxxxEND;
END伪指令用于通知编译器已经到达源程序的结尾
示例:
xxxxxxxxxxAREA RESET,CODE,READONLY......END ;指定应用程序的结尾
EQU
语法格式:
xxxxxxxxxx名称 EQU 表达式{,类型};
EQU伪指令用于为程序中的常量、标号等一个等效的字符名称,类似于C语言中的#define。其中EQU可用“*”代替
示例:
xxxxxxxxxxTest EQU 50 ;定义标号Test的值为50
EXPORT(或GLOBAL)
语法结构:
xxxxxxxxxxEXPORT 标号 {[WEAK]};
EXPORT伪指令用于在程序中声明一个全局的标号,该标号可在其他文件中引用。EXPORT可用GLOBAL代替。标号在程序中区分大小写,[WEAK]选项声明其他的同名标号优先于该标号被引用
示例:
xxxxxxxxxxAREA RESET,CODE,READONLYEXPORT Stest ;声明一个全局的标号Stest.....END
IMPORT
语法格式:
xxxxxxxxxxIMPORT 标号 {[WEAK]};
IMPORT伪指令用于通知编译器要使用的标号在其他源文件中的定义,但要在当前源文件中引用,而且无论当前源文件是否引用该标号,该标号均会被加入到当前源文件的符号表中
标号在程序中区分大小写,[WEAK]选项表示当所有的源文件都没有定义这样一个标号时,编译器也不给出错误信息,在多数情况下将该标号置为0,若该标号被B或BL指令引用,则将B或BL指令置为NOP操作
示例:
xxxxxxxxxxAREA RESET,CODE,READONLYIMPORT MAIN ;通知编译器当前文件要引用标号MAIN,但MAIN在其他源文件中定义......END
EXTERN
语法格式:
xxxxxxxxxxEXTERN 标号 {[WEAK]};
EXTERN伪指令用于通知编译器要使用的标号在其他的源文件中定义,但要在当前源文件中引用。如果当前源文件实际并未引用该标号,该标号就不会被加入到当前源文件的符号表中
示例:
xxxxxxxxxxAREA RESET,CODE,READONLYEXTERN Main ;通知编译器当前文件要引用标号Main,但Main在其他源文件中定义......END
GET(或INCLUDE)
语法格式:
xxxxxxxxxxGET 文件名;
GET伪指令用于将一个源文件包含在当前的源文件中,并将被包含的源文件在当前位置进行汇编处理。可以使用INCLUDE代替GET
汇编程序中常用的方法是在某源文件中定义一些宏指令,用EQU定义常量的符号名称,用MAP和FIELD定义结构化的数据类型,然后用GET伪指令将这个源文件包含到其他的源文件中。使用方法与C语言中的“INCLUDE”相似
GET伪指令只能用于包含源文件,包含目标文件需要使用INCLUDE伪指令
示例:
xxxxxxxxxxAREA RESET,CODE,READONLYGET a1.s ;通知编译器当前源文件包含当前目录下的a1.s文件GET C:/a2.s ;通知编译器当前源文件包含C盘根目录下的a2.s文件......END
INCBIN
语法格式:
xxxxxxxxxxINCBIN 文件名;
INCBIN伪指令用于将一个目标文件或数据文件包含到当前的源文件中,被包含的文件不作任何变动的存放到当前文件中,编译器不对文件内容进行编译,编译器从其后开始继续处理
示例:
xxxxxxxxxxAREA RESET,CODE,READONLYGET a1.sINCBIN a1.dat ;通知编译器当前源文件包含a1.datINCBIN C:/a2.txt ;通知编译器当前源文件包含C盘根目录下文件a2.txt......END
RN
语法格式:
xxxxxxxxxx名称 RN 表达式;
RN伪代码用于给一个寄存器定义一个别名
其中,名称为给寄存器定义的别名,表达式为寄存器的编码
xxxxxxxxxxTemp RN R0 ;将R0定义一个别名Temp
ROUT
语法格式:
xxxxxxxxxx{名称} ROUT
ROUT伪指令用于给一个局部变量定义作用范围
在程序中未使用该伪指令时,局部变量的作用范围为所在的AREA,而使用ROUT后,局部变量的作用范围为当前ROUT和下一个ROUT之间
7.2.5. 汇编语言中常用的符号
汇编语言程序设计的符号定义应遵循的约定:
- 符号区分大小写,同名的大、小写符号会被编译器认为是两个不同的符号
- 符号在其作用范围内必须唯一
- 自定义的符号不能与系统的保留字相同
- 符号名不应与指令或伪指令同名
程序中的变量
程序中的变量是指其值在程序的运行过程中可以改变的量。ARM(Thumb)汇编程序所支持的变量有数字变量、逻辑变量和字符串变量。
数字变量用于在程序的运行中保存数字值,但注意数字值的大小不应超出数字变量所能表示的范围。
逻辑变量用于在程序的运行中保存逻辑值,逻辑值只有两种取值情况:真或假。
字符串变量用于在程序的运行中保存一个字符串,但注意字符串的长度不应超出字符串变量所能表示的范围
在ARM汇编语言程序设计中,可以使用GBLA、GBLL、BGLS伪指令声明全局变量,使用LCLA、LCLL、LCLS伪指令声明局部变量,并可使用SETA、SETL、SETS进行初始化
示例:
xxxxxxxxxxLCLS S1 ;LCLS S2 ;定义局部字符串变量S1和S2S1 SETS "Test!" ;字符串变量S1的值为"Test!"S2 SETS "Hello!";字符串变量S2的值为"Hello!"
程序中的常量
程序中的常量是指其值在程序的运行过程中不能被改变的量。ARM(Thumb)汇编程序所支持的常量有数字常量、逻辑常量和字符串常量
数字常量一般为32位的整数,当作为无符号数时,其取值范围为0~232-1,当作为有符号数时,其取值范围为-231~232-1
逻辑常量只有两种取值情况:真或假
字符串常量为一个固定的字符串,一般用于程序运行时的信息提示
示例:
xxxxxxxxxxNUM EQU 64abcd EQU 2 ;定义abcd符号的值为2abcd EQU label+16 ;定义abcd符号的值为(label+16)abcd EQU 0x1c,CODE32 ;定义abcd的符号的值为绝对地址值0x1c,而且此处为ARM32指令
对比:EQU指令 vs “=”
- 使用EQU伪指令定义的符号名不能与其他符号名重合,符号名必须唯一,且不能被重新定义;而使用等号伪指令“=”定义的符号名可以重名,可以被重新定义,可被重新赋值
- 使用EQU伪指令定义的符号名不仅可以代表某个常数或常数表达式,还可以代表字符串、关键字、指令码、一串符号(如:WORD、,PTR),等等;而使用等号伪指令“=”定义的符号名仅仅用于代表数值表达式
程序中的变量代换
程序中的变量可以通过代换操作取得一个常量。代换操作符为"$"
如果在数字变量前面有一个代换操作符“$”,编译器会自动将该数字的值转换为十六进制的字符串,并将十六进制的字符串代换“$”后的数字变量
如果在逻辑变量前面有一个代换操作符"$",编译器会将该逻辑变量代换为它的取值(真或假)
如果在字符串变量前面有一个代换操作符“$”,编译器会将该字符串变量的值代换“$”后的字符串变量
示例:
xxxxxxxxxxLCLS S1 ;定义局部字符串变量S1和S2LCLS S2S1 SETS "Test!"S2 SETS "This is a $S1" ;字符串变量S2的值为"This is a Test!"
7.2.6. 汇编语言中常用运算符和表达式
运算次序与优先级:
- 优先级相同的双目运算符的运算顺序为从左到右
- 相邻的单目运算符的运算顺序为从右到左,且单目运算符的优先级高于其他运算符
- 括号运算符的优先级最高
数学表达式及运算符
| 运算符 | 用法 | 作用 |
|---|---|---|
+ | X+Y | X与Y的和 |
- | X-Y | X与Y的差 |
x | XxY | X与Y的乘积 |
/ | X/Y | X除以Y的商 |
MOD | X:MOD:Y | X除以Y的余数 |
ROL | X:ROL:Y | 将X循环左移Y位 |
ROR | X:ROR:Y | 将X循环右移Y位 |
SHL | X:SHL:Y | 将X左移Y位 |
SHR | X:SHR:Y | 将X右移Y位 |
AND | X:AND:Y | 将X和Y按位作逻辑与的操作 |
OR | X:OR:Y | 将X和Y按位作逻辑或的操作 |
NOT | :NOT:Y | 将Y按位作逻辑非的操作 |
EOR | X:EOR:Y | 将X和Y按位作逻辑异或的操作 |
逻辑表达式及运算符
| 运算符 | 用法 | 作用 |
|---|---|---|
= | X=Y | X等于Y |
> | X>Y | X大于Y |
< | X<Y | X小于Y |
| `>=` | X>=Y | X大于等于Y |
| `<=` | X<=Y | X小于等于Y |
/= | X/=Y | X不等于Y |
<> | X<>Y | X不等于Y |
LAND | X:LAND:Y | 将X和Y作逻辑与操作 |
LOR | X:LOR:Y | 将X和Y作逻辑或操作 |
LNOT | :LNOT:Y | 将Y作逻辑非操作 |
LEOR | X:LEOR:Y | 将X和Y作逻辑异或操作 |
字符串表达式及运算符
| 运算符 | 用法 | 作用 |
|---|---|---|
LEN | :LEN:X | 返回字符串长度 |
CHR | :CHR:M | 将0~255之间的整数转换为一个字符 |
STR | :STR:X | 将一个数字表达式或逻辑表达式转换为一个字符串 |
LEFT | X:LEFT:Y | 返回某个字符串左端的一个字串 |
RIGHT | X:RIGHT:Y | 返回某个字符串右端的一个字串 |
CC | X:CC:Y | 用于将两个字符串连接成一个字符串 |
与寄存器和程序计数器PC相关的表达式及运算符
| 运算符 | 用法 | 作用 |
|---|---|---|
BASE | :BASE:X | 返回基于寄存器的表达式中寄存器的编号 |
INDEX | :INDEX:X | 返回基于寄存器的表达式中相对于其基址寄存器的偏移量 |
其他运算符
| 运算符 | 用法 | 作用 |
|---|---|---|
? | ?X | 返回某代码行所生成的可执行代码的长度 |
DEF | :DEF:X | 判断是否定义某个符号 |
7.3. ARM汇编语言程序设计
7.3.1. ARM汇编语言的语句格式
RM汇编中语句中所有标号必须在一行的顶格书写,其后面不要添加“:”,而所有指令均不能顶格书写。ARM汇编器对标识符大小写敏感,书写标号及指令时字母大小写要一致,在ARM汇编程序中,一个ARM指令、伪指令、寄存器名可以全部为大写字母,也可以全部为小写字母,但不要大小写混合使用
ARM汇编语句的格式如下:
xxxxxxxxxx[LABEL] OPERATION [OPERAND] [;COMMENT];标号域 ;操作助记符域 ;操作数域 ;注释域
标号域
- 标号域用来表示指令的地址、变量、过程名、数据的地址和常量
- 标号是可以自己起名的标识符,语句标号可以是大小写字母混合,通常以字母开头,由字母、数字、下划线等组成
- 语句标号不能与寄存器名、指令助记符、伪指令(操作)助记符、变量名同名
- ARM汇编规范规定:语句标号必须在一行的开头书写,不能留空格;指令则在行开头必须要留出空格
操作助记符域
- 操作助记符域可以为指令、伪操作、宏指令或伪指令的助记符。
- ARM汇编器对大小写敏感,在汇编语言程序设计中,每一条指令的助记符可以全部用大写、或全部用小写,但不允许在一条指令中大、小写混用。
- 所有的指令都不能在行的开头书写,必须在指令的前面有空格,然后再书写指令
- 指令助记符和后面的操作数或操作寄存器之间必须有空格,不可以在这之间使用逗号
操作数域
- 操作数域表示操作的对象,操作数可以是常量、变量、标号、寄存器名或表达式,不同对象之间必须用逗号“,”分开
7.3.2. ARM汇编语言程序结构
在ARM(Thumb)汇编语言程序中,通常以段为单位来组织代码段是具有特定名称且功能相对独立的指令或数据序列根据段的内容,分为代码段和数据段
一个汇编程序至少应该有一个代码段,当程序较长时,可以分割为多个代码段和数据段
一个汇编语言程序段的基本结构如下所示:
xxxxxxxxxxAREA Buf, DATA, READWRITE ;定义一个可读写属性的数据段Num DCD 0x11Nums DCD 0x22 ;分配一片连续存储单元并初始化;本节及下节所有汇编代码程序都是利用MDKIDE编写,Device设置为STM32F407ZG,;代码段放在IROM中起始地址为0x08000000,数据段放在IRAM中起始地址为0x20000000AREA RESET,CODE,READONLY ;只读的代码段,RESET为段名ENTRY ;程序入口点START LDR R0,= Num ;取Num地址赋给R0LDRR1,[R0] ;取Num中内容赋给R1ADD R1,#0x9A; R1=R1+0x9ASTR R1,[R0] ;R1内容赋给Num单元LDR R0,= Nums ;......LDR R2,[R0]ADD R2,#0xABSTR R2,[R0]LOOP B LOOP ;无限循环反复执行END ;段结束
7.3.3. ARM汇编程序设计实例
顺序结构
顺序结构是一种最简单的程序结构,这种程序按指令排列的先后顺序逐条执行
示例:对数据段中数据进行寻址操作
xxxxxxxxxxAREA BUF,DATA,READWRITE ;定义数据段BufArray DCB 0x11,0x22,0x33,0x44DCB 0x55,0x66,0x77,0x88DCB 0x00,0x00,0x00,0x00 ;定义12个字节的数组ArrayAREA RESET,CODE,READONLYENTfRYLDR R0,=Array ;取得数组Array首地址LDR R2,[R0] ;从数组第1字节取32位数据给R2即R2=0x44332211MOV R1,#1 ;R1=1LDR R3,[R0,R1,LSL#2] ;将存储器地址为R0+R1x4的32位数据读入寄存器R3,;R3=0x88776655LOOP B LOOPEND
分支结构
一般情况下,程序按指令的先后顺序逐条执行,但经常要求程序根据不同条件选择不同的处理方法,利用条件指令或条件转移指令根据当前CPSR中的状态标志值选择路径,使用带有条件码的指令实现的分支程序段
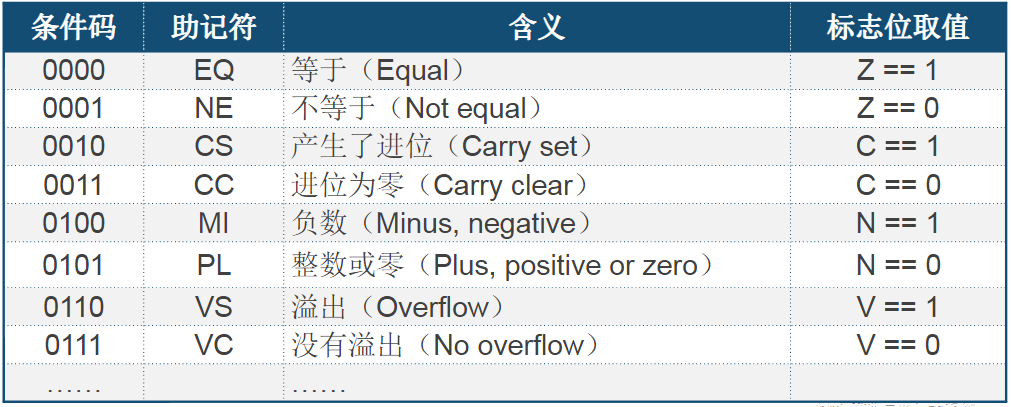
分支结构中经常使用的条件码助记后缀:
- HI:无符号数大于
- LS:无符号数小于或等于
- GT:带符号数大于
- LE:带符号数小于或等于
例如寄存器中R0和R1分别保存两个数,如果R0小于R1,将R1值传给R0,实现代码如下:
xxxxxxxxxxCMP R0,R1 ;比较R0和R1MOVLT R0,R1 ;MOVLT=MOV+LT LT是有符号数比较小于
分支结构的几种实现方法:
利用条件码可以很方便地实现IF ELSE分支结构地程序
xxxxxxxxxxMOV R0,#76 ;初始化R0的值MOV R1,#88 ;初始化R1的值CMP R0,R1 ;判断R0>R1?MOVHI R2,#100 ;R0>R1时,R2=100MOVLS R2,#50 ;R0<=R1时,R2=50......B(Branch)条件转移及衍生指令实现分支结构
B指令
格式:
xxxxxxxxxxB(条件)+目标地址用法:B指令是最简单的跳转指令,一旦遇到一个B指令,ARM处理器将立即跳转到给定的目标地址,从那里继续执行
示例:
xxxxxxxxxxB Label ;程序无条件跳转到标号Label处执行示例:
xxxxxxxxxxCMP R1, #0BEQ Label ;当CPSR寄存器中Z条件码置位时,程序跳转到标号Label处执行......
BL指令
格式:
xxxxxxxxxxBL{条件}+目标地址用法:BL是一个跳转指令,但跳转之前,会在寄存器R14中保存PC当前的内容。因此,可以通过将R14的内容重新加载到PC中,来返回到跳转指令之后的那个指令处执行。这个指令是实现子函数调用的一个基本且常用的手段
xxxxxxxxxxBL Label ;让程序无条件跳转到标号是Label处执行,同时将当前的PC值保存到R14(LR)中。BL实现子函数调用时完成如下的三个操作:
- 将子程序的返回地址(当前PC)保存在R14(LR)中
- 将PC指向子程序的入口即跳转(也即BL后面的目标指令)
- 子程序执行完毕之后需要返回时,只需将R14中的LR赋给PC
使用BL调用子程序后,通常在子程序的尾部添加MOV PC,LR来返回
循环结构
循环结构可以减少源程序重复书写的工作量,用来描述重复执行某段算法的问题,这是程序设计中最能发挥计算机特长的程序结构
for循环结构实现
C语言形式:
xxxxxxxxxxfor(int i=0;i<1-;i++)x++;ARM汇编语言形式:R0为x,R2为i,均为无符号整数
xxxxxxxxxxMOV R0,#0 ;初始化R0=0MOV R2,#0 ;初始化R2=0LOOP CMP R2,#0 ;判断R2<10?BCS FOR_E ;若条件失败(即R>=10),退出循环ADD R0,R0,#1 ;执行循环体,R0=R0+1,即x++ADD R2,R2,#1 ;R2=R2+1,即i++B LOOPFOR_E......while循环结构实现
C语言形式:
xxxxxxxxxxwhile(x<=y)x*=2;ARM汇编语言形式:x为R0,y为R1,均为无符号整数
xxxxxxxxxxMOV R0,#1 ;初始化R0=1MOV R1,#20 ;初始化R1=20W1 CMP R0,R1 ;判断R0<=R1,即x<=yMOVLS R0,R0,LSL#1 ;循环体,R0*=2BLS W1 ;若R0<=R1,继续循环体W_END
子程序调用与返回
在ARM汇编语言中,子程序的调用一般是通过BL指令来完成的
BL指令的语法格式如下:
xxxxxxxxxxBL SUB
SUB是被调用的子程序的名称
BL指令完成2个操作,即将子程序的返回地址放在LR寄存器中,同时将PC寄存器指向子程序的入口点,当子程序执行完毕需要返回主程序时,只需将存放在LR中的返回地址重新赋给指令指针寄存器PC即可。通过调用子程序,能够完成参数的传递和从子程序返回运算的结构(通常使用寄存器R0-R3来完成)
BL调用子程序的经典用法如下:
xxxxxxxxxxBL NEXT ;跳转NEXT......NEXT......MOV PC, LR ;从子程序返回
当子程序需要使用的寄存器与主程序使用的寄存器发生冲突(即子程序与主程序都要使用同一组寄存器时),为了防止主程序这些寄存器中的有用数据丢失,在子程序的开始应该把这些寄存器数据压入堆栈以保护现场,在子程序返回之前需要把保护到堆栈的数据自堆栈中弹出以恢复现场
- 保存和恢复数据可以用PUSH/POP指令实现,
PUSH{R4,LR}将寄存器R4入栈,LR也入栈。POP{R4,PC}将堆栈中的数据弹出到寄存器R4及PC中 - 如果需要保存数据较多即需要入栈和出栈多个寄存器时,可以用
PUSH{R0-R7,LR}将寄存器R0-R7全部入栈,LR也入栈;POP{R0-R7,PC}将堆栈中的数据弹出到寄存器R0-R7及PC中 - ARM汇编指令中还有与PUSH/POP功能类似的压栈和出栈指令:
STMFD SP!,{R0-R7,LR};功能是满递减入栈,将寄存器R0-R7、LR压栈,SP不断减4,执行后SP=SP-9*4[SP]=R0,[SP+4]=R1,....,[SP+4*8]=LR
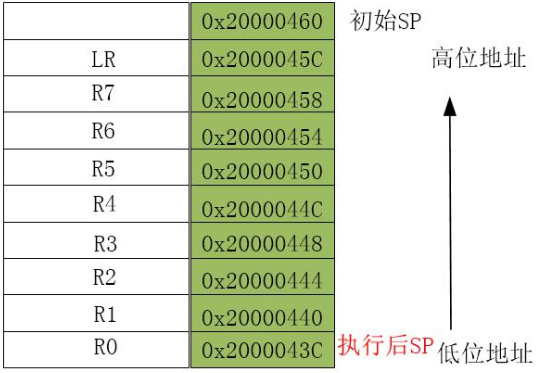
LDMFD SP!,{R0-R7,PC};满递减出栈,给寄存器R0-R9出栈,并使程序跳转回函数的调用点,SP不断增4;同理,LDMFD是STMFD的逆操作,[SP]->R0,[SP+4]->R1,...,[SP+4*8]->PCSP=SP+4*9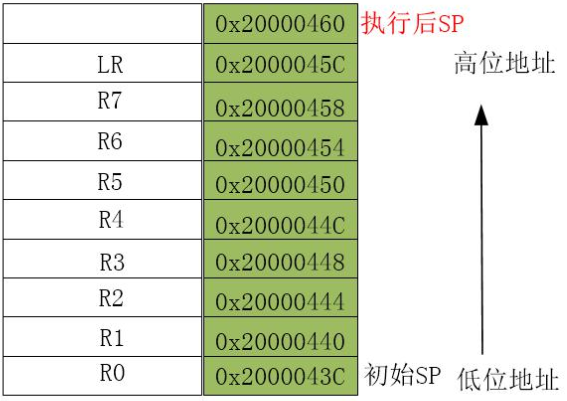
注意:BLSUB...MOVPC,LR这种调用子程序结构在一些情况下是会出现问题的,例如当出现子程序嵌套调用时,LR寄存器中内容在第二次子程序调用时会被覆盖,如果仍使用常用调用方式会出现无法返回现场的问题,这个时候使用STMFD/LDMFD指令可以有效避免LR被覆盖而出现错误
示例:
xxxxxxxxxxAREA RESET,CODE,READONLYENTRYSTART LDR SP,=0x20000460MOV R0,#0x03MOV R1,#0x04MOV R7,#0x07BL POWLOOP B LOOPPOW STMFD SP!, {R0-R7,LR}MOVS R2,R1MOVEQ R0,#1BEQ POW_ENDMOV R1,R0SUB R2,R2,#1POW_L1 BL DO_MUL ;子程序调用嵌套,这个时候如果不用指令会出现LR覆盖,FD/LDMF,影响子程序调用返回SUBS R2,R2,#1BNE POW_L1POW_END LDMFD SP!,{R0-R7,PC}DO_MUL MUL R0,R1,R0MOV PC.LREND
7.4. ARM汇编语言与C/C++的混合编程
7.4.1. C语言与汇编语言之间的函数调用
ATPCS概述
为了使单独编译的C语言程序和汇编程序之间能够相互调用,必须为子程序之间的调用制定一定的规则。ATPCS就是ARM程序和Thumb程序中子程序调用的基本规则
ATPCS(ARM-ThumbProcedureCallStandard,基于ARM指令集和Thumb指令集过程调用规则)规定了一些不同语言撰写的函数之间相互调用(mixcalls)的基本规则,这些基本规则包括子程序调用过程中寄存器的使用规则、数据栈的使用规则、以及参数的传递规则
TPCS规定了在子程序调用时的一些基本规则,主要包括以下3方面的内容:
各寄存器的使用规则及其相应的名字;
数据栈的使用规则(FD);
参数传递的规则;
- 当参数个数不超过4个时,可以使用寄存器R0~R3来传递参数,如果参数多于4个,则将剩余的字数据通过堆栈传递,入栈顺序与参数传递顺序相反,即最后一个字数据先入栈,第一个字数据最后入栈
C程序调用汇编函数实例
ARM编译器使用的函数调用规则就是ATPCS标准,也是设计可被C程序调用的汇编函数的编写规则。为了保证程序调用时参数传递正确,C程序调用的汇编函数时必须严格按照ATPCS规则
如果汇编函数和调用函数的C程序不在同一个文件中,则需要在汇编语言中用EXPORT声明汇编语言起始处的标号为外部可引用符号,该标号应该为C语言中所调用函数的名称
例:调用汇编函数,实现把字符串srcstr复制到dsstr中
xxxxxxxxxx//main.cextern void strcopy(char*d,char*s);//需要调用的汇编函数原型并加extern关键字int main(){char* srcstr="0123456";chardststr[]="abcdefg";strcopy(dststr,srcstr);return 0;}
汇编语言源程序Scopy.s,汇编文件和*.c文件在同一工程中
xxxxxxxxxxAREA Scopy,CODE,READONLYEXPORTstrcopystrcopy;必须与EXPORT后面标号一致LOOP LDRB R2,[R1],#1;R1指向源地址STRB R2,[R0],#1;R0指向目标地址CMP R2,#0BNE LOOP;先执行后判断,源字符串的终止符‘\0’;也复制到目的字符串MOV PC,LREND
汇编程序调用C函数实例
在汇编程序中调用C语言函数,需要在汇编程序中利用IMPORT说明对应的C函数名,按照ATPCS的规则保存参数。完成各项准备工作后利用跳转指令跳转到C函数入口处开始执行。跳转指令后所跟标号为C函数的函数名
例:汇编程序中调用C函数实现求5个整数相加的和;test.s,工程设置为基于汇编的工程,不需要从main函数启动,代码段名称必须设为RESET
xxxxxxxxxxPRESERVE8AREA RESET,CODE,READONLYENTRYIMPORT CAL;LDR SP,=0x20000460;设置堆栈指针MOV R0,#1;R0=1ADD R1,R0,R0;R1=2ADD R2,R1,R0;R2=3ADD R3,R0,R2;R3=4ADD R4,R0,R3;R4=5STR R4,[SP,#-4]!BL CALLDR R4,=0x20000000;结果R0存入内存单元STR R0,[R4]END
xxxxxxxxxx//C源程序example.c和汇编文件在同一个工程中int CAL(int a, int b, int c, int d, int e){return (a+b+c+d+e);}
7.4.2. C/C++语言与汇编语言的混合编程
嵌入式系统开发中,目前使用的主要编程语言是C和汇编,C++已经有相应的编译器,但是现在使用还是比较少的。在稍大规模的嵌入式软件中,大部分的代码都是用C编写的
C语言中使用内嵌汇编代码,可以在C/C++程序中实现C/C++不能完成的一些操作,同时程序的代码效率也会更高
在C语言程序中嵌入汇编指令
如果要在C程序中嵌入汇编有两种方法:内联汇编和内嵌汇编。嵌入汇编使用的标记是__asm或者asm关键字,用法如下:
xxxxxxxxxx__asm{instruction [;instruction]...[instruction]}asm(“instruction[;instruction]”);
内联汇编的示例代码如下:
xxxxxxxxxxint Add(int i){int R0;__asm{ADD R0,i,1EOR i,R0,i}return i;}内嵌汇编的示例代码如下:
xxxxxxxxxx#include<stdio.h>__asm void my_strcpy(const char*src,char*dst){LOOP LDRB R2,[R0],#1;R0保存第一个参数STRB R2,[R1],#1;R1保存第二个参数CMP R2,#0BNE LOOP BLX LR;返回指令须要手动加入}xxxxxxxxxxint main(void)//主程序{constchar*a="Helloworld!";char b[20];my_strcpy(a,b);//调用内嵌汇编程序return 0;}
由两种方法的示例可以看出:内联汇编可以直接嵌入C代码使用,而内嵌汇编更像一个函数。由于内联式汇编只能在ARM状态中进行,而Cortex-M3/M4只支持Thumb-2,所以Cortex-M3/M4只能使用内嵌汇编的方式,也就是第二种方法
在C语言中内嵌汇编指令与汇编程序中的指令有些不同,存在一些限制,主要有下面几个方面:
- 不能直接向PC寄存器赋值,程序跳转要使用B或者BL指令
- 在使用物理寄存器时,不要使用过于复杂的C表达式,避免物理寄存器冲突
- R12和R13可能被编译器用来存放中间编译结果,计算表达式值时可能将R0到R3、R12及R14用于子程序调用,因此要避免直接使用这些物理寄存器
- 一般不要直接指定物理寄存器,而让编译器进行分配
示例:在C程序中使用内联汇编代码实现字符串复制
xxxxxxxxxx#include<stdio.h>void my_strcpy(constchar*src,char*dest){charch;__asm//注意是双下划线{LOOP:LDRB ch,[src],#1STRB ch,[dest],#1CMP ch,#0BNE LOOP}}int main(){char* a="ok!";char b[64];my_strcpy(a,b);return 0;}
在汇编中调用C语言定义的函数和全局变量
- 使用内联或者内嵌汇编不用单独编辑汇编语言文件使用起来比较方便,但是有诸多限制
- 当汇编文件较多的时候就需要使用专门的汇编文件编写汇编程序,在C语言和汇编语言进行数据传递的最简单的形式是使用全局变量
8. 基于ARM微处理器硬件与软件系统设计开发
8.1. 嵌入式硬件与软件系统设计与开发综述
8.1.1. 概述
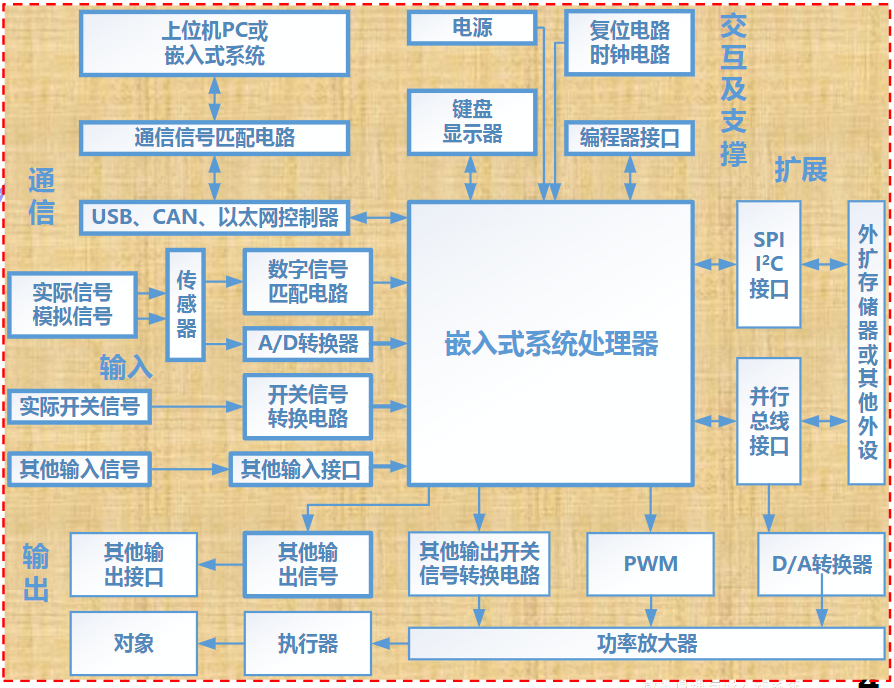
硬件平台:
- 嵌入式处理器
- 存储器:SDRAM、ROM、Flash等
- 通用设备接口和I/O接口:A/D转换器、D/A转换器、I/O接口控制卡
核心控制模块:嵌入式处理器+电源电路、时钟电路、存储器电路
软件平台:应用层、操作系统OS层、驱动层
8.1.2. 嵌入式生态系统
硬件
- 仿真器,如:J-LINK、ULINK
- 开发板,如:ARM/KEIL的STM32专用评估板
软件
开发工具(如:ARM/KEIL MDK和IAR EWARM)
软件资源,包括:
- 底层驱动(如:标准外设驱动库、DSP库等)
- 固件协议
- 应用模块(如:电机控制、音频应用等)
文档
8.1.3. 开发环境、开发工具和调试方式
开发环境
宿主机(如:通用PC,用于:编写、编译、链接等,生成可在目标机上执行的二进制代码)
目标机(系统实际运行环境,如:ARM处理器)
宿主机和目标机之间的连接
- 物理连接(如:串口、以太网接口和JTAG)
- 逻辑连接(如:通信协议)
开发工具
- 硬件(如:PCB、PCL等设计开发)
- 软件(编辑器、交叉编译器、链接器、调试下载工具;集成开发环境IDE;如:KEIL MDK)
嵌入式软件开发阶段及其工具:
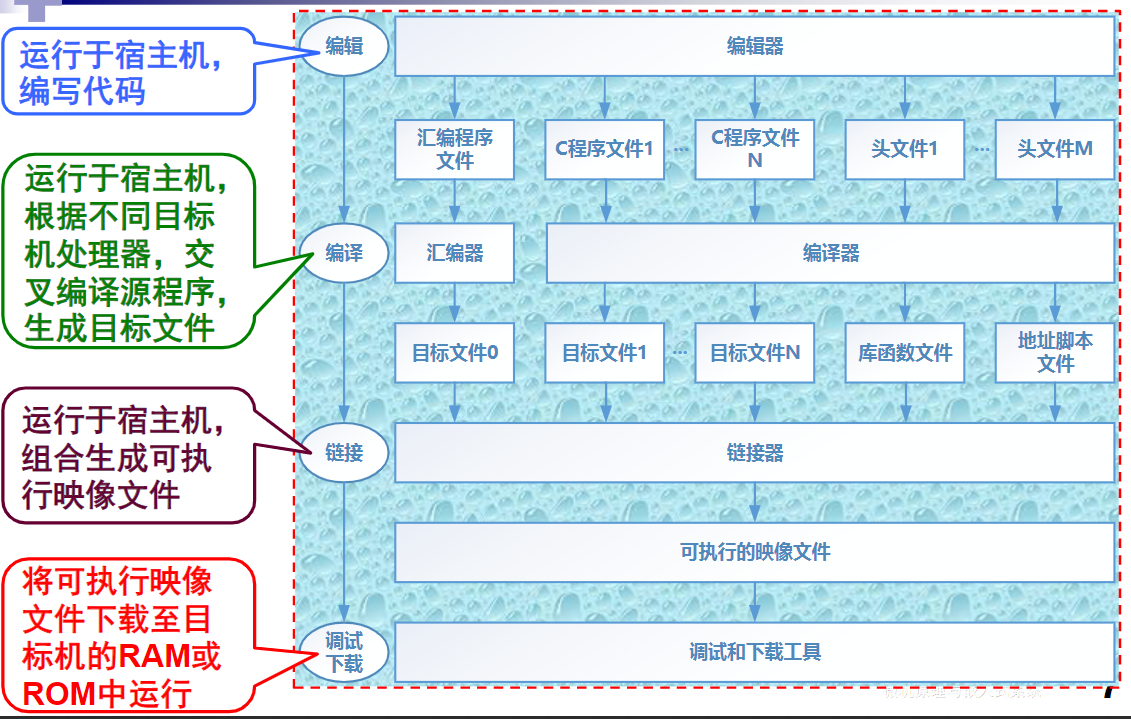
集成开发工具KEIL MDK的组成
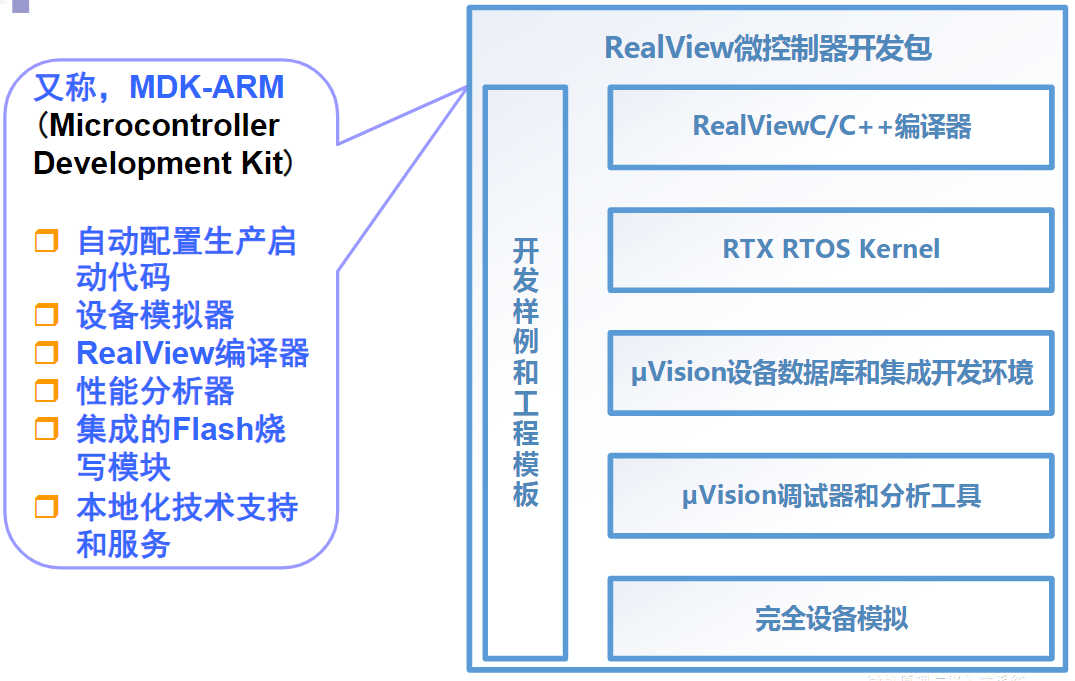
调试方法
- 软件模拟器(分为:指令集和系统调用级模拟器)
- ROM监控器。由三部分构成:宿主机的调试器、目标机的监控器及两者间物理/逻辑连接
- ROM仿真器。替代目标机上ROM芯片(映射、仿真)两端分别与目标机和宿主机相连
- 在线仿真器ICE。模拟目标机上CPU(含RAM/ROM)
- 片上调试OCD。内置于目标板CPU芯片内的调试模块;如:JTAG仿真器ULINK和J-LINK
片上调试OCD图示:
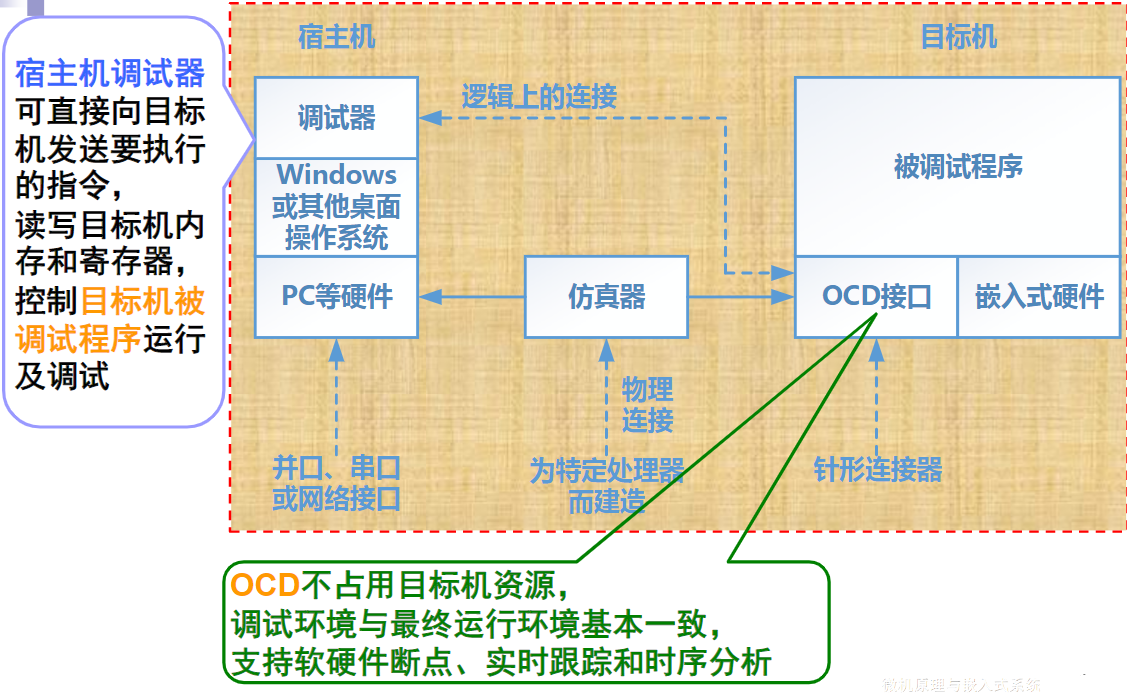
基于JTAG的嵌入式调试环境:
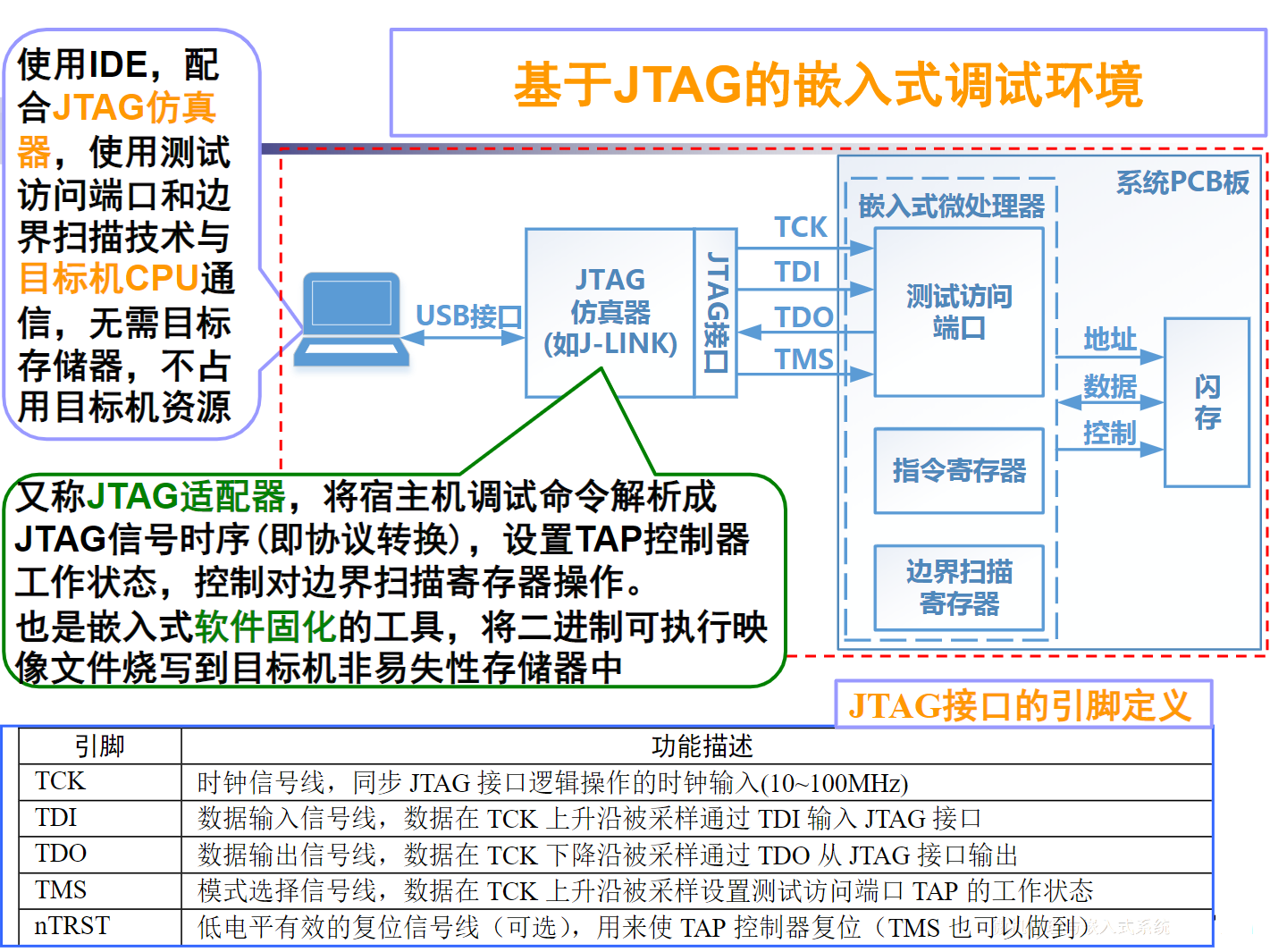
8.1.4. 嵌入式系统开发过程
需求分析(系统规格说明书,含功能性/非功能性需求)
系统设计(也称总体/概要设计)
- 体系架构设计
- 软硬件划分
- 硬件划分(处理器、外设、器件及开发工具的选择)
- 软件设计(软件架构设计和软件模块划分)
系统实现(又称详细设计,包括硬件和软件实现)
系统测试(包括:测试方法、工具及步骤)
系统发布
8.2. ARM内核常用微处理器
8.2.1. 三星S3C2440A
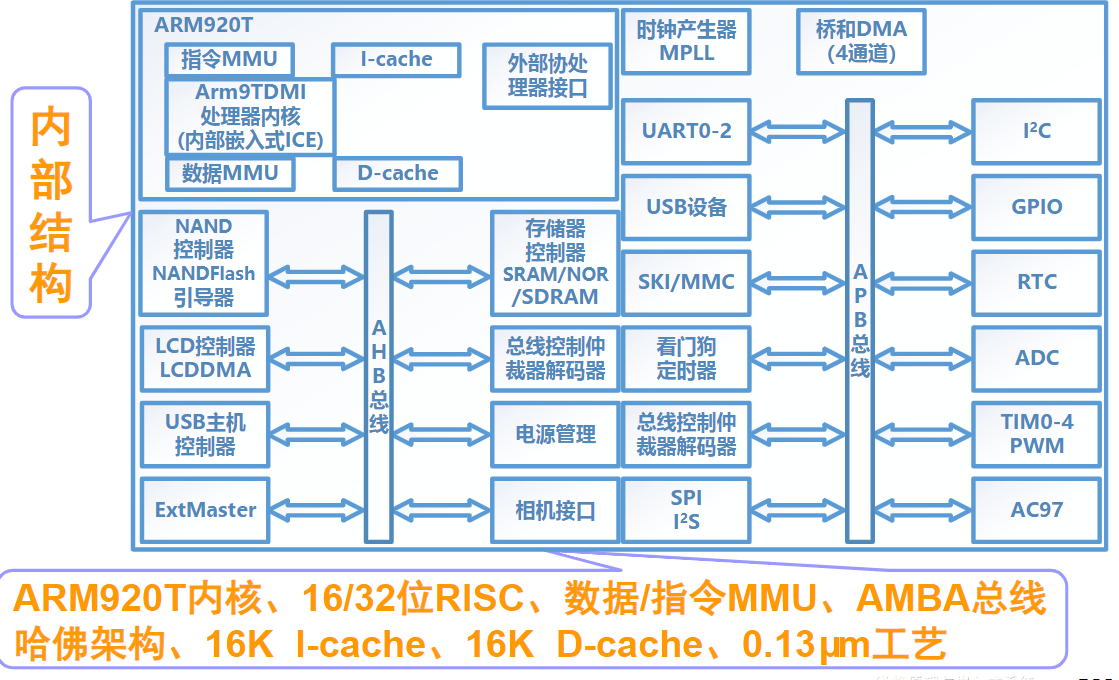
8.2.2. 恩智浦LPC2132
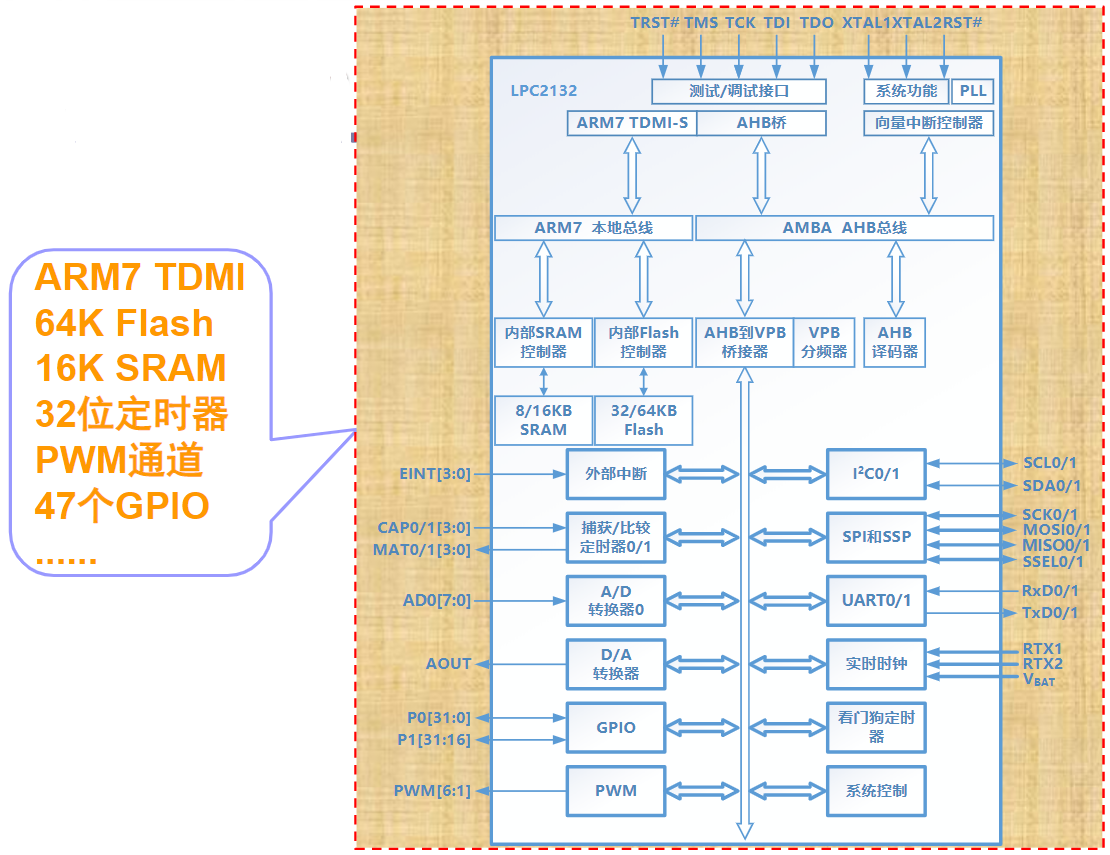
特性:
- 小型LQFP64封装,可在系统/在应用编程(ISP/IAP)
- 嵌入式跟踪接口可实时调试
- 47个GPIO、1个A/D、2个UART、2个I2C、SPI、NVIC
- 片内晶振频率1~30MHz,PLL实现最大60 MHz
- 2个低功耗模式:空闲和掉电
- 可禁止外部功能和降低外部时钟频率优化功耗
- 通过外部中断从掉电模式中唤醒
- 单电源供电,CPU电压范围3.0~3.6 V
结构原理
- 支持仿真的ARM7 TDMI-S CPU、与片内存储器控制器接口的ARM7局部总线、与中断控制器接口的AHB和连接片内外设功能的VPB。默认访问模式为小端字节顺序
- AHB连接VIC、外存储器访问控制器EMC;AHB外设共分配2 MB地址范围,位于4GB存储器空间最顶端;每个AHB外设分配16KB地址空间;AHB桥用于微处理器与AHB总线信号与时序协议的桥接与适配
- VPB连接其他外设;VPB外设共分配2MB地址范围,从3.5GB地址点开始;每个VPB外设分配16KB地址空间AHB到VPB的桥将VPB总线与AHB总线相连
- 片内外设与器件引脚的连接由引脚连接模块控制,须由软件控制以符合应用中的需求
引脚及连接模块
- 引脚:引脚功能复用,将某几个功能分配到一个引脚
- 引脚连接模块结构原理:配置引脚具体功能;利用PINSELx,可控制多路开关,连通引脚与某功能模块
端口寄存器与操作
3个32位用于引脚功能选择寄存器,即:
- PINSEL0:选择P0[15:0]各引脚功能;每2个对应一个引脚,选择约定具体应用功能
- PINSEL1:选择P0[31:16]各引脚功能,每2位一个
- PINSEL2:选择P1[31:26]、P1[25:16]两引脚簇功能
控制寄存器操作时,建议采用:“读→修改→写回”方式
好处是:
- 不会改变原来不相关引脚的功能属性
- 不会影响到寄存器中保留位的数据
8.2.3. 意法半导体STM32
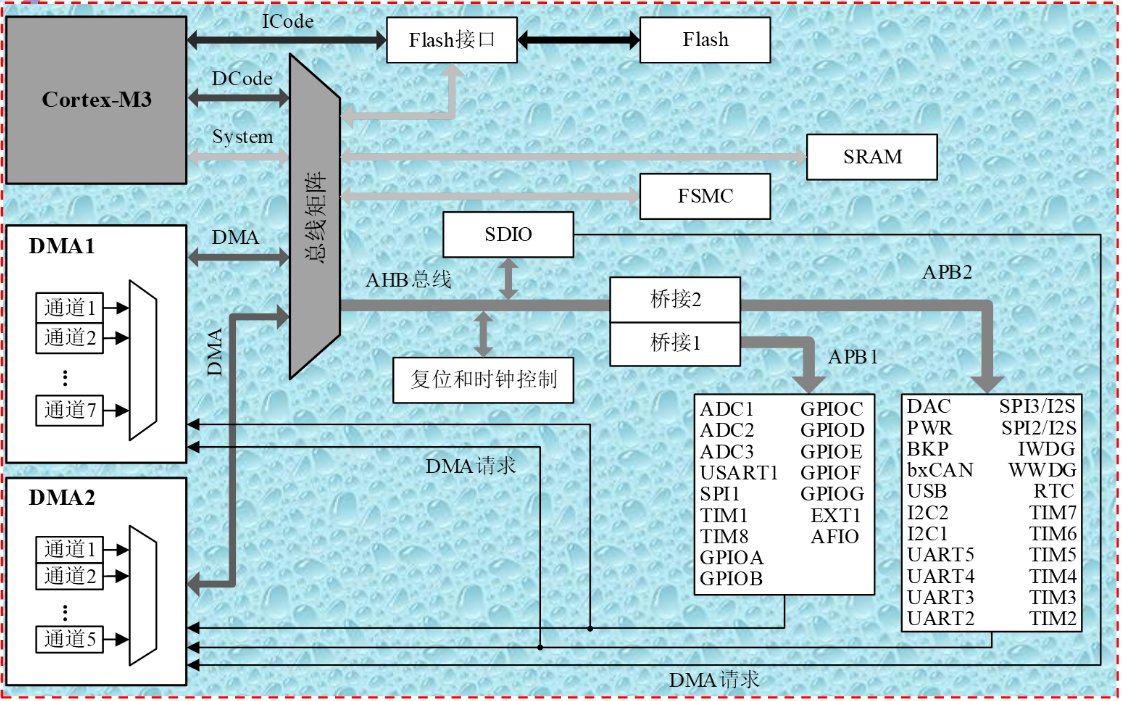
系统总线
I-Code总线;指令预取
D-Code总线;数据加载和调试访问
系统总线
DMA总线
总线矩阵;含:
4个驱动部件(CPU的D-Code、系统总线、DMA1/2总线)
4个被动部件(FLITF、SRAM、FSMC和AHB-APB桥)
AHB-APB桥;共两个,AHB和两个APB总线间连接
程序、数据存储器、所有外设都统一编址(4GB);各自有固定存储空间区域,使用不同总线进行访问
Cortex-M3内核,视为CPU,通过相应总线再经总线矩阵与程序、数据存储器、所有外设相接并控制其读写访问
外设分为高速/低速两类,各自通过桥接再通过AHB系统总线连至总线矩阵,实现与内核的接口;外设时钟可各自配置;两种访问操作方式:CPU直接操作和DMA方式
系统时钟,均由复位与时钟控制器RCC产生,为系统和各外设提供所需时钟以确定各自工作速度
功能模块
系统模块
辅助和维护正常工作,如:电源、外部晶振、内部RC振荡器、锁相环PLL、复位和时钟控制RCC、实时时钟、看门狗Watchdog和循环冗余校验CRC等
通信模块
与标准通信接口外设间数据交换,如:USART、SPI、I2C、USB、CAN和SDIO
虚拟模块
对模拟信号的处理,如:ADC、DAC
控制模块
对电机等设备控制和操作,如:定时器
性能简介
- 基于ARM Cortex-M3核心,32位,LQFP-144封装
- 512KB片内Flash(类似硬盘,程序存储),64KB片内RAM(类似内存,数据存储)
- 72MHz系统频率,片内双RC晶振(8MHz/40kHz),片外高速晶振(8MHz)/低速晶振(32kHz)
- 数据、指令分别走不同流水线
- 带后备电源引脚,用于掉电后时钟行走;42个16位后备寄存器,利用外置电池,实现掉电数据保存功能
- 支持JTAG、SWD调试;在线程序烧写(ISP)
- 80个GPIO;4个通用定时器,2个高级定时器,2个基本定时器;3个SPI;2路I2S;2个I2C;5个USART;1个USB;1个CAN;1个SDIO;可兼容SRAM、NOR和NAND Flash16位总线可变静态存储控制器FSMC
- 3个16通道12位ADC,2个2通道12位DAC,支持片外独立电压基准
- CPU工作电压范围:2.0~3.6V
8.3. 最小硬件系统
8.3.1. 微处理器最小硬件系统
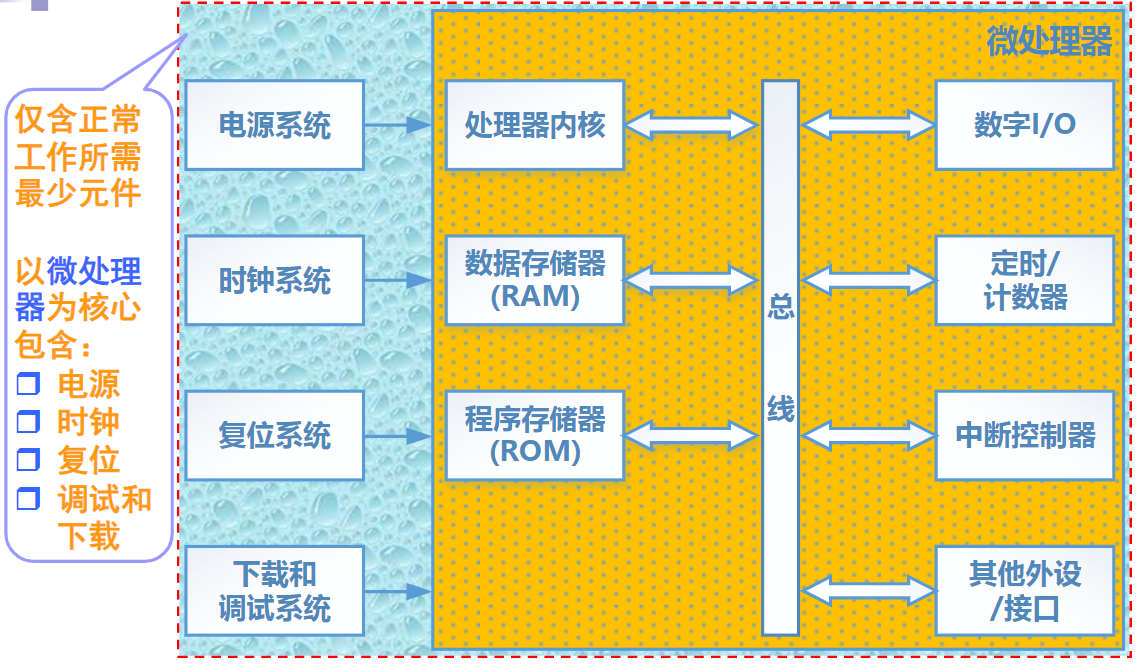
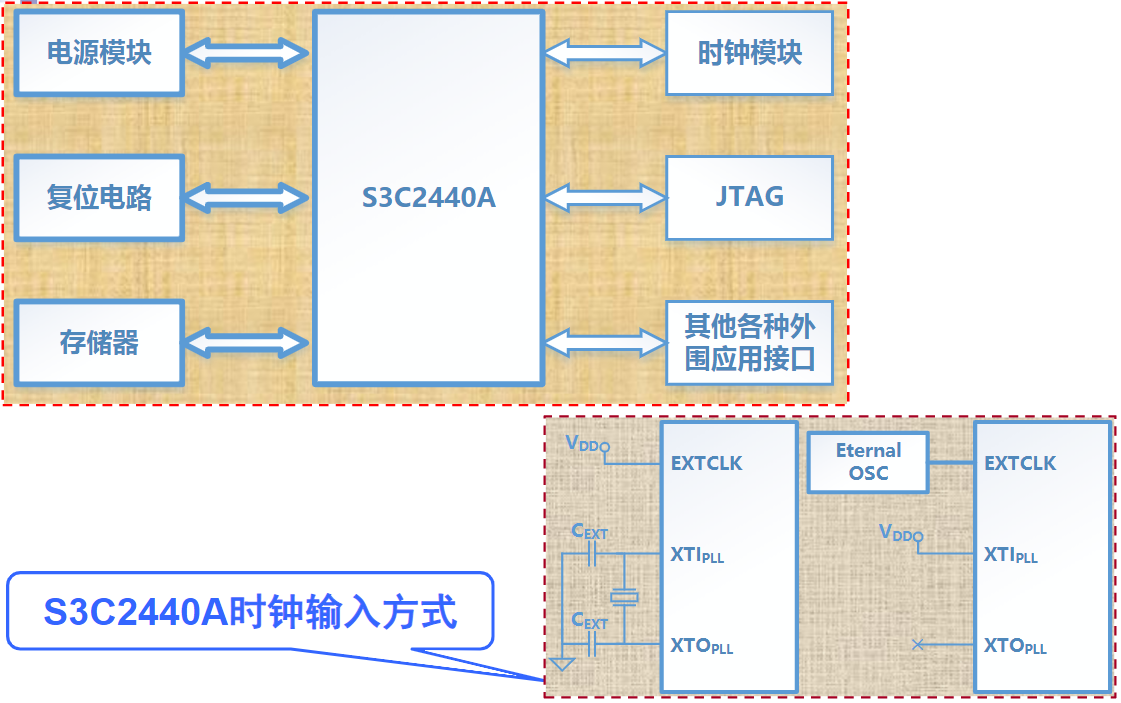
8.3.2. S3C2440A最小硬件系统

- 电源模块;内核和IO接口能量来源,电压、纹波、内阻、驱动能力、防干扰等性能直接影响系统工作稳定性
- 时钟模块;提供同步工作信号,频率较高系统主时钟和频率较低实时时钟,倍频和同步处理后不同频率时钟信号,供各模块使用
- 复位模块;3种:加电和手动复位(信号来自外部复位电路,从nRESET引脚输入),内部复位(信号来自系统内部事务处理,如看门狗复位)
- JTAG调试接口模块;完成基本调试工作
- 外部存储器模块;保存和运行系统程序,如SRAM(引导)、SDRAM(程序运行)、NAND Flash(存放程序)
8.3.3. STM32最小硬件系统
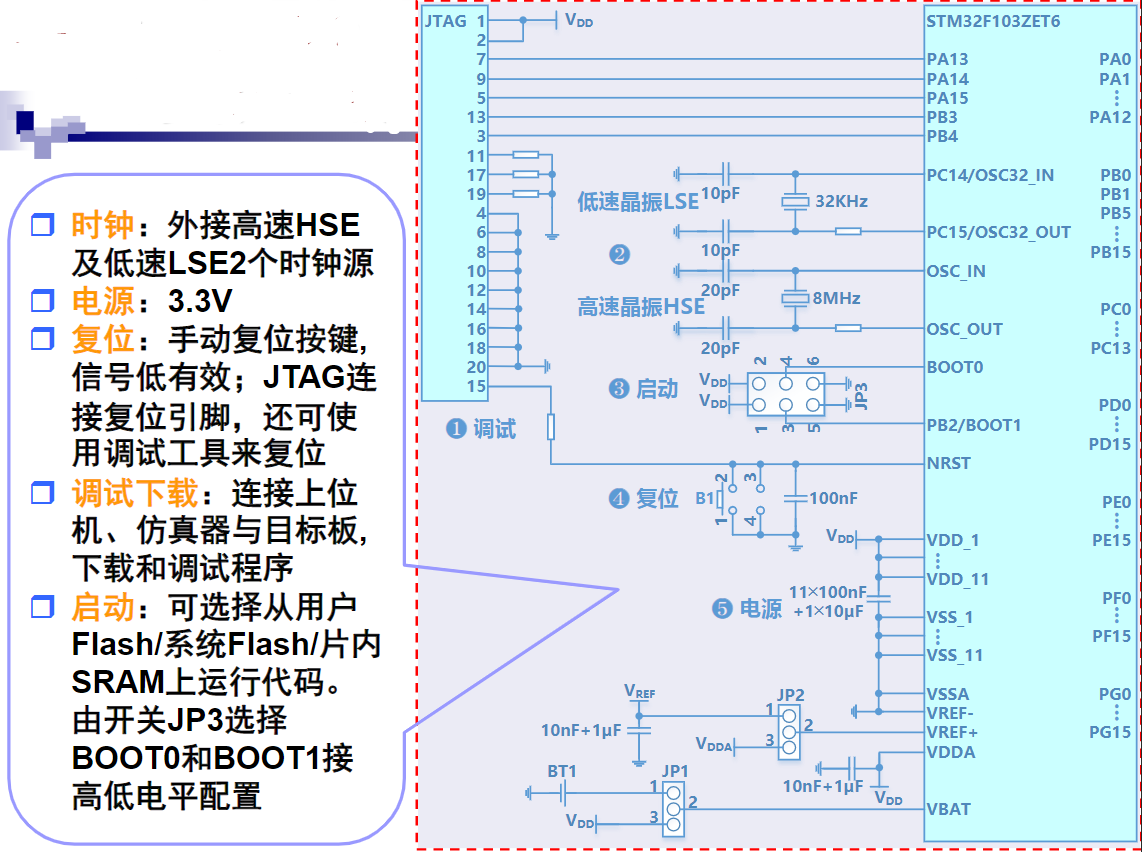
8.3.4. MCU及其周围电路设计
8.3.4.1. 电源电路
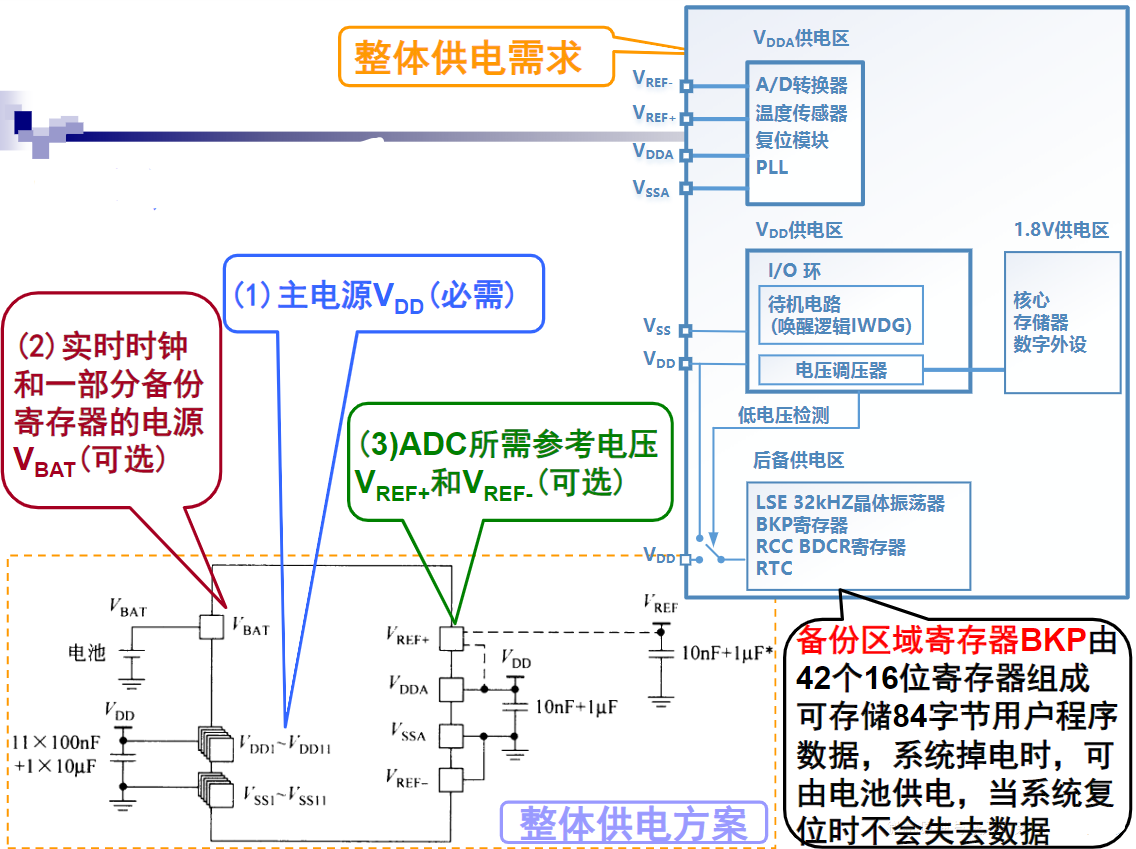
8.3.4.2. 复位电路
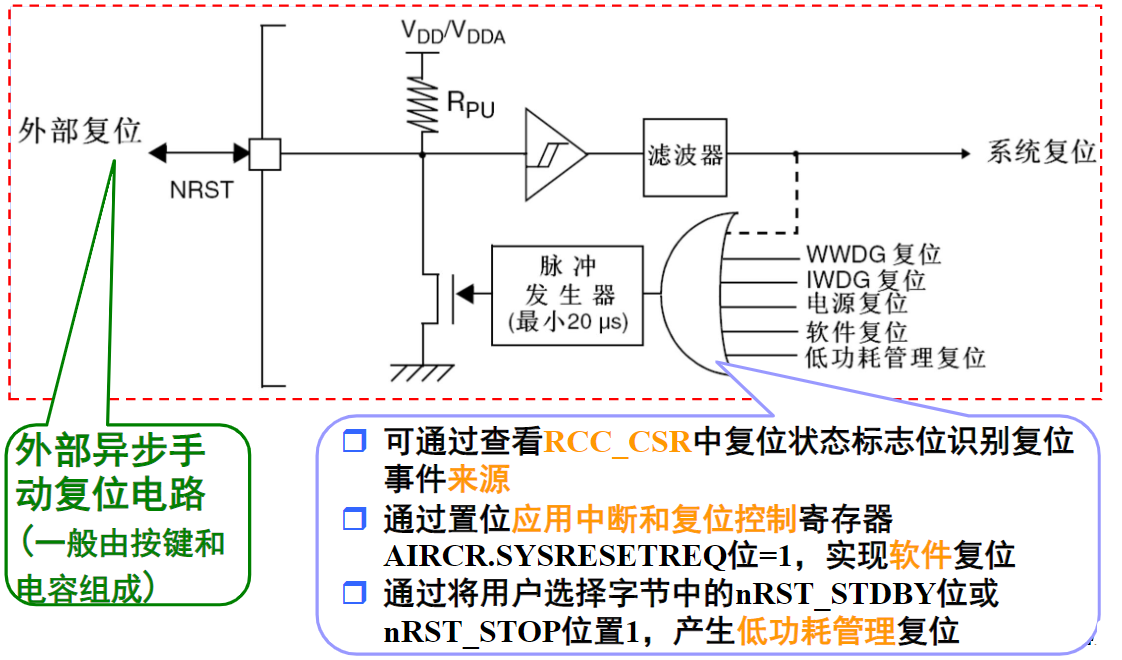
系统复位
复位除备份区域的寄存器以外所有寄存器
(时钟控制状态寄存器RCC_CSR中复位标志不会复位)
触发一个系统复位有数种方式:
- WWDG看门狗复位(窗口看门狗计数终止)
- IWDG(Independent Watch Dog)看门狗复位(独立看门狗计数终止)
- 软件复位(SW复位)
- 低功耗管理复位
- 外部手动复位
电源复位
- 当上电/掉电复位POR和PDP(VDD小于特定阈值VPOR/VPDR时)发生或从待机模式返回时,产生电源复位
- 复位除备份区域外的所有寄存器
- 复位源最终作用于复位引脚,并在复位过程中保持低电平
- 复位入口矢量被固定在地址0x00000004
备份区域复位
仅影响备份区域,有两个专门的复位:
- 在软件复位时,设定RCC_BDCR.BDRST位产生
- 当电源VDD和电池VBAT都掉电前提下,VDD或VBAT重新上电时产生
复位电路:延时,使CPU保持复位,暂不进入工作状态(防止执行错误指令),确保其及各部件处于确定的初始状态,直至电压稳定复位电路直接影响系统稳定性和可靠性
8.3.4.3. 时钟电路
内部RC振荡器与外部晶振的选择
内部RC振荡器:可为PLL提供时钟,不够准确稳定,误差1%左右,精度通常比外部晶振低10倍以上
外部主时钟源:高速外部时钟HSE,两种时钟源产生
- 外部晶体/陶瓷谐振器(常选用8MHz)和负载电容组成精确而稳定,首选
- 用户提供的外部时钟信号(可为占空比50%的方波/正弦波/三角波,可达25MHz),须连至OSC32_IN引脚,OSC32_OUT引脚悬空
STM32时钟树
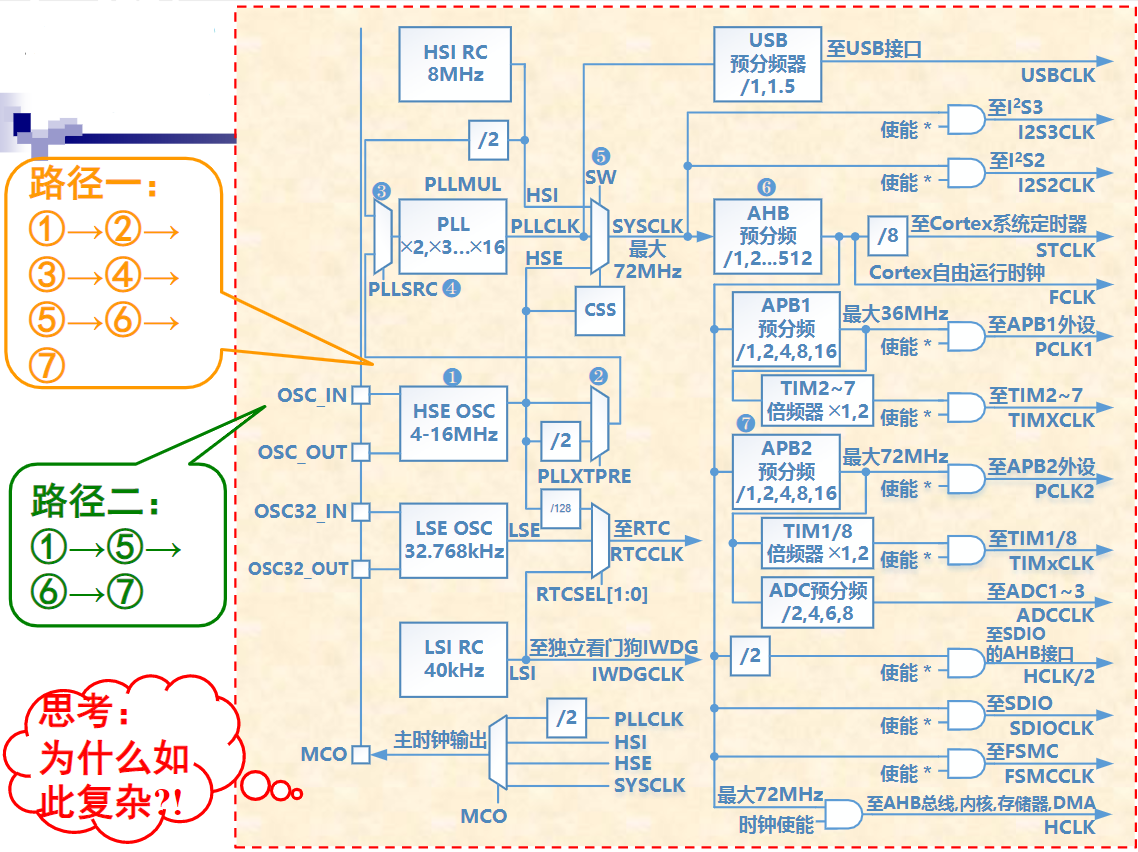
时钟树图中的序号解释:
①:输入,外部晶振HSE,可选为2~16MHZ
②:第一个分频器PLLXTPRE,可选1分频/2分频
③:时钟源选择,开关PLLSRC,可选其输出为:外部高速时钟HSE或内部高速时钟HSI
④:锁相环PLL,具有倍频功能(2~16),经过PLL的时钟称为PLLCLK(若设9倍频,即从8MHz的HSE变为72MHz)
⑤:开关SW,经过SW后即系统时钟SYSCLK。SW可选SYSCLK时钟源为:HSI、PLLCLK、HSE
⑥:AHB预分频器(分频系数为1/2/4/8/16/64/128/256/512)
⑦:APB2预分频器(分频系数为1/2/4/8/16)。若为1,则高速外设APB2(PCLK2)为72MHz(AHB输出为72MHz时)
时钟树从左至右,相关时钟可依次分为:
输入时钟
从时钟频率分:高速/低速时钟;从芯片角度分:内部时钟(片内时钟)/外部时钟源(片外时钟)。有以下5种:
- 高速外部时钟HSE:①→②→③→④→⑤得SYSCLK
- 高速内部时钟HSI:片内RC振荡器产生,不稳定,上电开始作为初始系统时钟,8MHz
- 低速外部时钟LSE:外部晶振,提供给实时时钟,32kHz
- 低速内部时钟LSI:片内RC振荡器产生,提供给实时时钟和看门狗,40kHz
- 锁相环倍频输出PLL:输入源可选HSI/2、HSE或HSE/2,倍频2~16倍,输出最大72MHz
系统时钟SYSCLK
- 由SW根据用户设置,选择PLLCLK、HSE或HSI中的一路输出而得,最高可达72MHz(通常即72MHz)
- 大部分部件时钟来源,由AHB预分频器分配至各部件
- 通常,上电开始,选用HSI作为初始系统时钟,完成初始化后,选用更加稳定可靠的HSE作为系统时钟来源
- 为了能实时检测时钟系统是否运行正常,专门提供引脚MCO(主时钟输出),通过软件编程,选择SYSCLK、PLLCLK、HSE或HSI中的一路在MCO上输出
由系统时钟分频所得其他时钟(即SYSCLK经过AHB预分频器输出)
- HCLK:AHB时钟(通常,预分频系数为1,常为72MHz),最高72MHz;为内核、存储器和DMA时钟信号
- FCLK:内核“自由运行”时钟,与HCLK互相同步,最大72MHz;HCLK停止时仍能继续运行,保证内核睡眠时也能采样到中断和跟踪休眠事件
- PCLK1:外设时钟;再经APB1预分频器(系数常为2)后得到,最高36MHz(常为36MHz);为APB1总线上(低速)外设时钟(如需使用外设,须先开启其时钟)
- PCLK2:外设时钟;类似PCLK1,最高72MHz(常为72MHz),为APB2总线上(高速)外设时钟信号
- SDIOCLK:SDIO外设时钟
- FSMCCLK:可变静态存储控制器时钟
- STCLK:系统时间定时器SYSTICK的外部时钟源;AHB输出再经过8分频后得到,等于HCLK/8
- TIMXCLK:定时器2~7内部时钟源,PCLK1经过倍频(*1或*2,由APB1分频系数是否为1判断得出)所得
- TIMxCLK:定时器1/8内部时钟源,PCLK2经过倍频(*1或*2,由APB2分频系数是否为1判断得出)所得
- ADCCLK:ADC1~ADC3时钟,PCLK2经过ADC预分频器(/2,4,6,8)所得
时钟输出的使能及其流程
- 连接在APB1上的设备(低速外设)有:电源接口、备份接口、CAN、USB、I2C1、I2C2、UART2~5、SPI2/I2S、SPI3/I2S、BKP、IWDG、WWDG、RTC、CAN、DAC、PWR、TIM2~7
- 连接在APB2上的设备(高速外设)有:GPIOA~G、TIM1、TIM8、USART1、ADC1~ADC3、SPI1、EXTI、AFIO
假设,使用HSE及ST库函数,配置时钟(参数)流程如下:
① 将RCC重新设置为默认值,
RCC_DeInit② 打开HSE,
RCC_HSEConfig(RCC_HSE_ON)③ 等待HSE工作,
HSEStartUpStatus=RCC_WaitForHSEStartUP④ 设置AHB时钟,
RCC_HCLKConfig⑤ 设置高速/低速AHB时钟,
RCC_PCLK2Config/RCC_PCLK1Config⑥ 设置PLL,
RCC_PLLConfig;打开PLL,RCC_PLLCmd(ENABLE)⑦ 等待PLL工作,
while(RCC_GetFlagStatus(RCC_FLAG_PLLRDY)==RESET))⑧ 设置系统时钟,
RCC_SYSCLKConfig⑨ 判断PLL是否是系统时钟,
while(RCC_GetSYSCLKSource()!=0x08)⑩ 打开要用外设时钟,
RCC_APB2PeriphClockCmd/RCC_APB1PeriphClockCmd时钟管理寄存器
时钟控制寄存器RCC_CR:使能外部时钟和内部时钟,使能PLL功能;在各种时钟就绪时,置位其中就绪标志并可配置内部时钟的校准和设置偏移量
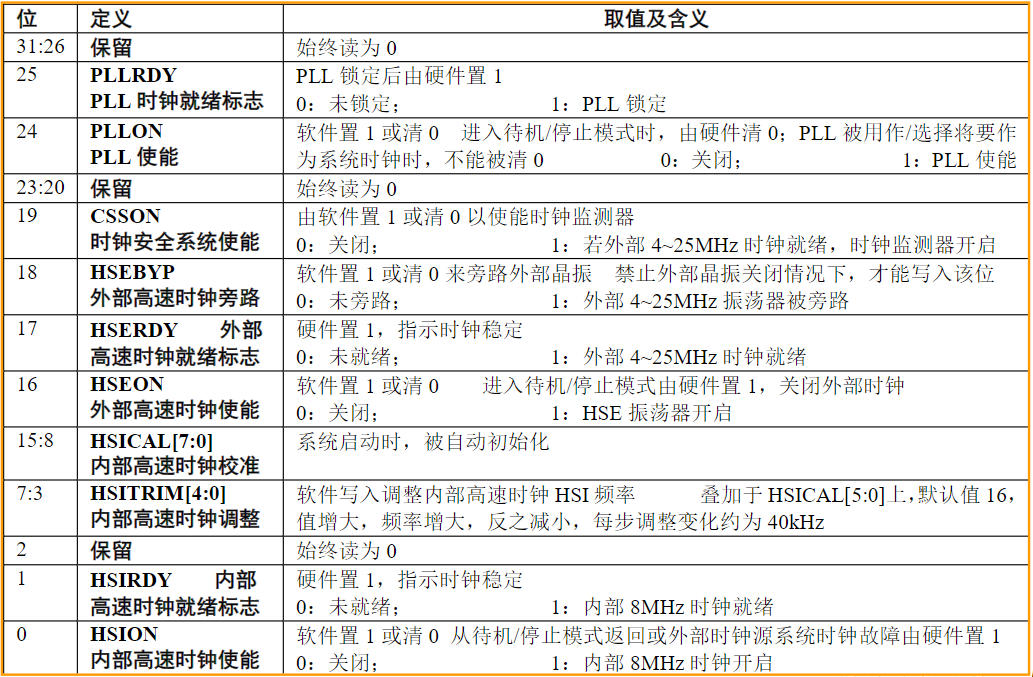
时钟配置寄存器RCC_CFGR:配置某时钟作为系统时钟SYSCLK;显示当前系统时钟源;配置AHB、APB、ADC的预分频(即配置其时钟频率);选择PLL时钟源,设置倍频系数;选择MCO时钟源
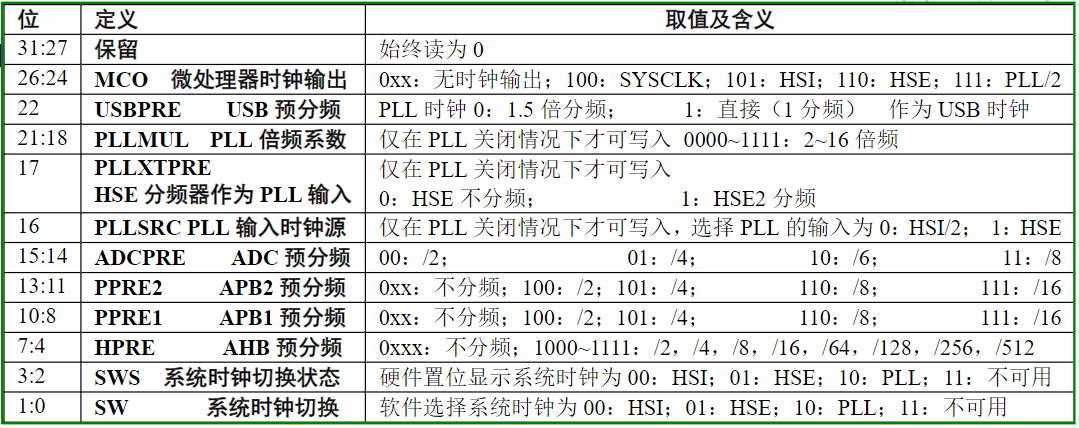
时钟中断寄存器RCC_CIR:使能PLL、HSE、HIS、LSE、LSI就绪中断,显示/清除其就绪中断标志

APB2外设复位寄存器RCC_APB2RSTR
APB1外设复位寄存器RCC_APB1RSTR
AHB外设时钟使能寄存器RCC_AHBENR
APB2外设时钟使能寄存器RCC_APB2ENR
APB1外设时钟使能寄存器RCC_APB1ENR
备份域控制寄存器RCC_BDCR,各位分别为:
- LSEON,外部低速时钟振荡器使能
- LSEBYP,外部低速时钟振荡器旁路
- RTCSEL,实时时钟RTC时钟源选择
- RTCEN,实时时钟RTC使能
控制/状态寄存器RCC_CSR,各位分别为:
- LPWRRSTF,低功耗复位标志
- WWDGRSTF,窗口看门狗复位标志
- IWDGRSTF,独立看门复位标志
- SFTRSTF,软件复位标志
- PORRSTF,上电/掉电复位标志
- PINRSTF,NRST引脚复位复位标志
- RMVF,软件将此位置1,可清除各复位标志
- LSIRDY,内部低速时钟LSI就绪标志
- LSION,使能内部低速时钟振荡器
各复位标志由硬件置1,由电源复位或软件置RMVF位为1清除;系统复位可清除其余位
时钟系统相关库函数
存放于
stm32f10x_rcc.h和stm32f10x_rcc.c中RCC_GetSYSCLKSource:返回用作系统时钟的时钟源RCC_GetClocksFreq:返回不同片上总线时钟频率RCC_AHBPeriphClockCmd:使能/禁止AHB总线上外设时钟RCC_APB2PeriphClockCmd:使能/禁止APB2总线上外设时钟RCC_APB1PeriphClockCmd:使能/禁止APB1总线上外设时钟
8.3.4.4. 调试和下载电路
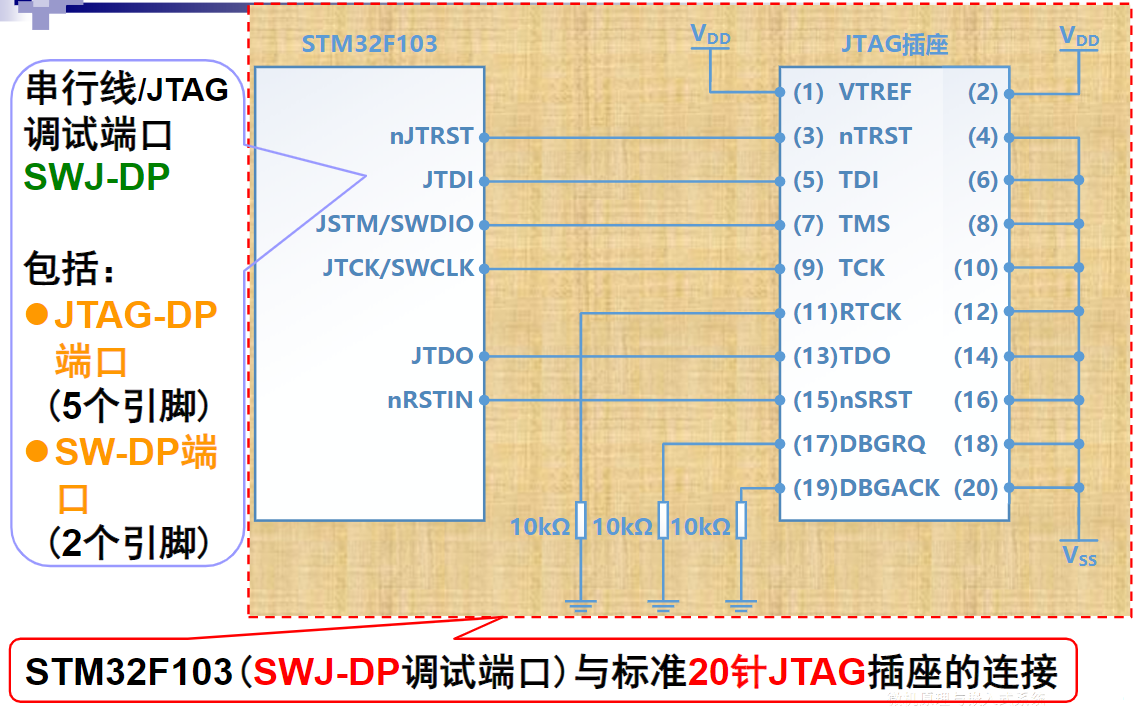
8.3.4.5. 启动电路
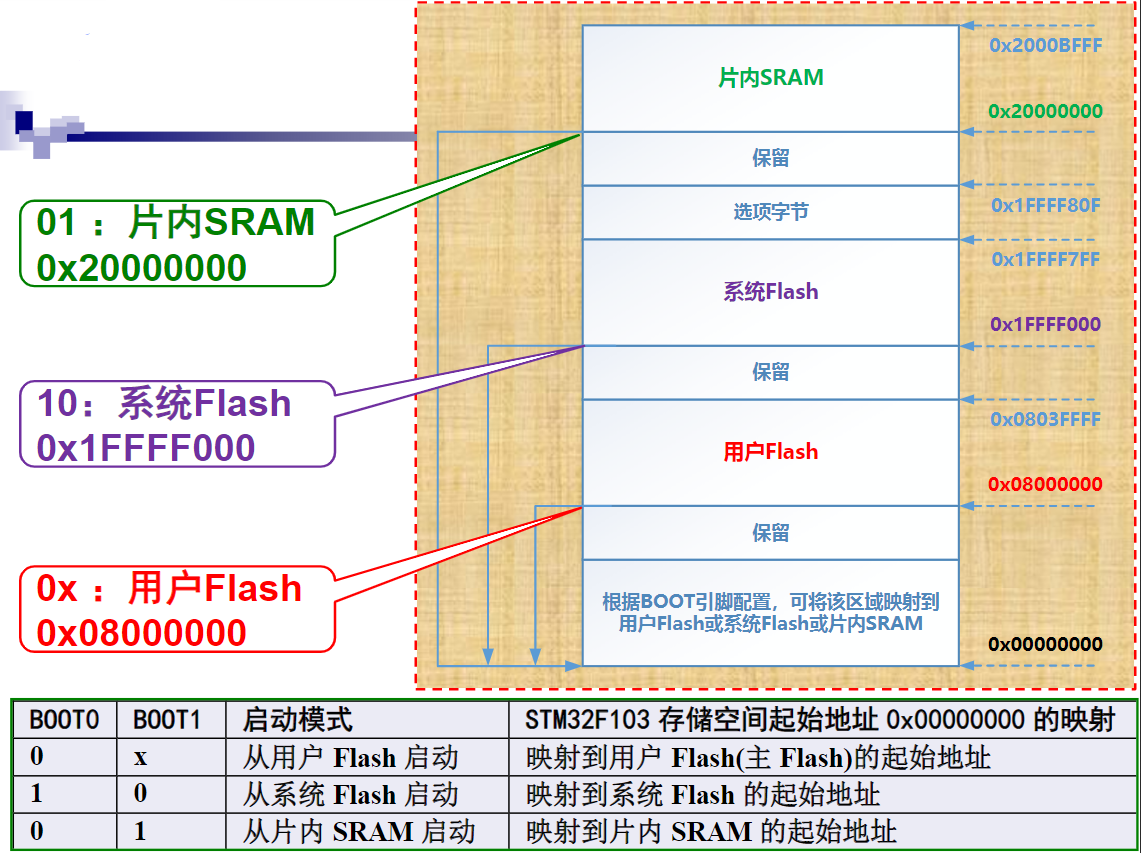
8.3.4.6. 启动代码和启动过程
启动代码:上电后程序执行的真正入口,通常包括初始化:异常向量表、时钟、存储器、堆栈,跳转到main函数等,为系统运行做好准备
启动过程:
- 根据BOOT0和BOOT1引脚,选择启动存储器映射
- 从地址0x0000 0000处,取出栈顶指针值放入MSP
- 从地址0x0000 0004处,取出复位异常服务程序入口地址放入PC
- 执行复位异常服务程序,跳转至main()函数
复位时,STM32F103存储空间和重要寄存器
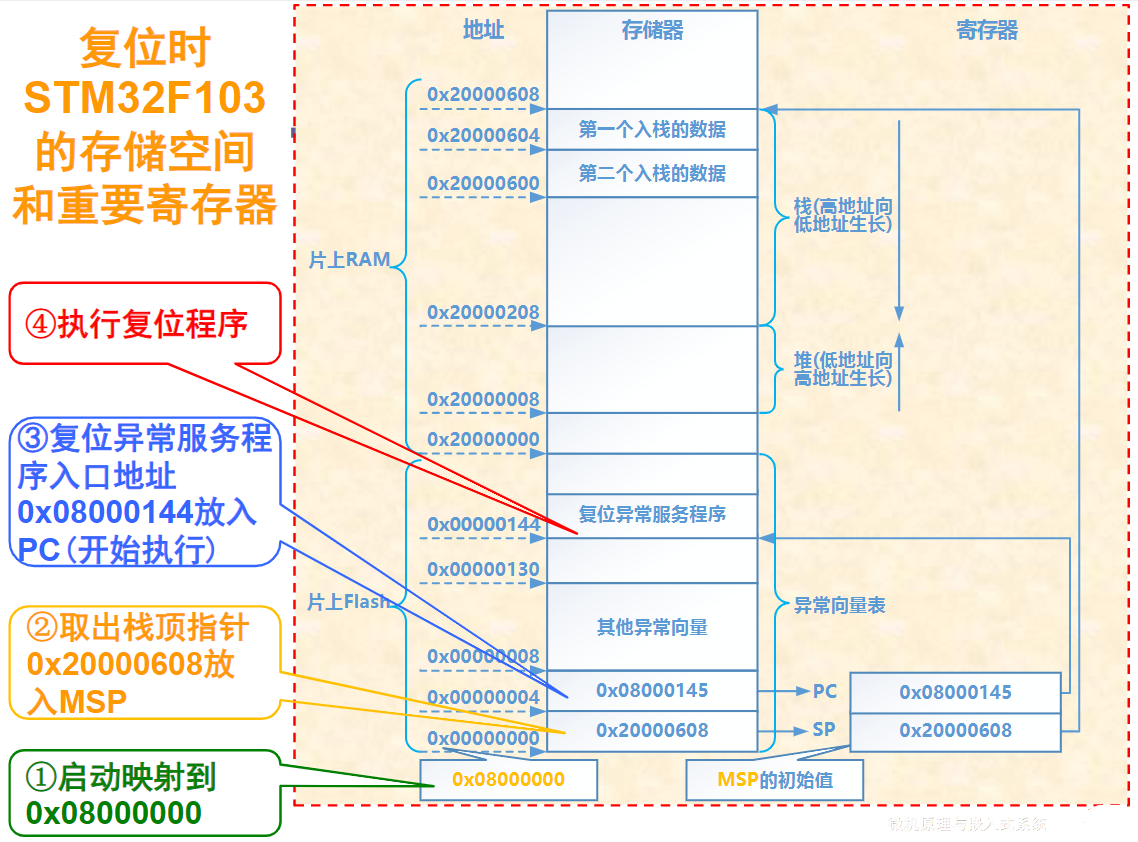
复位异常服务程序Reset_Handler的执行过程
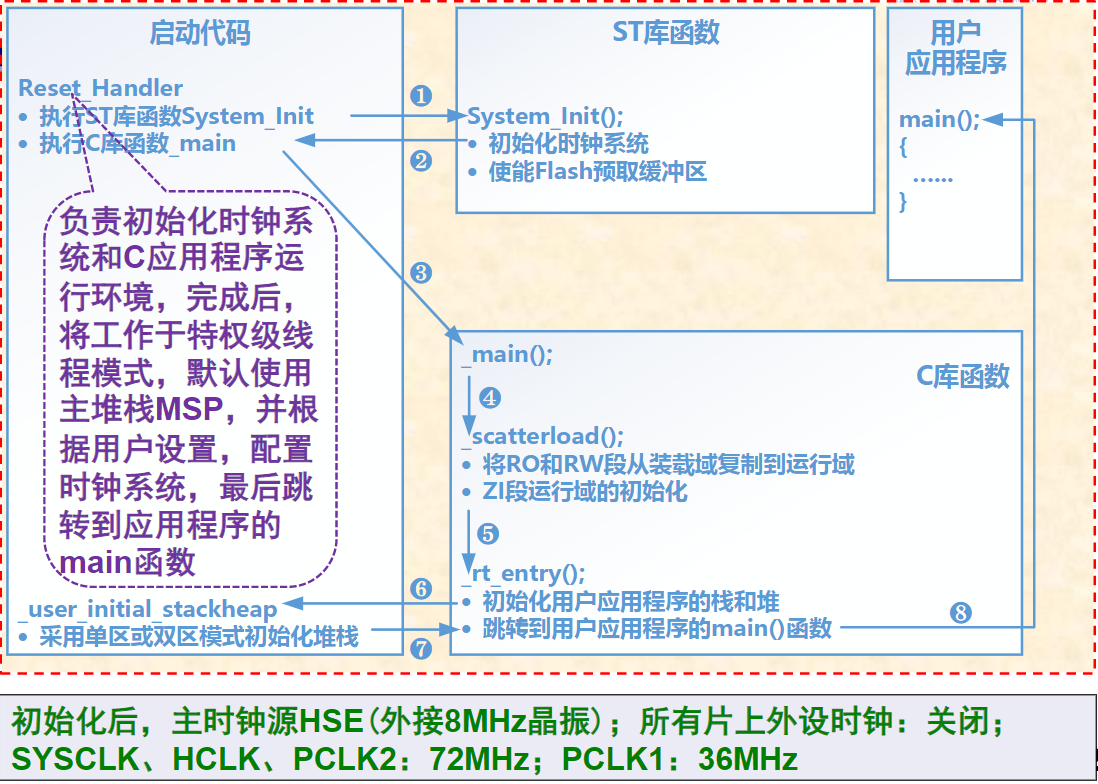
8.4. 嵌入式软件系统设计
8.4.1. 系统结构及工作流程
嵌入式软件系统结构
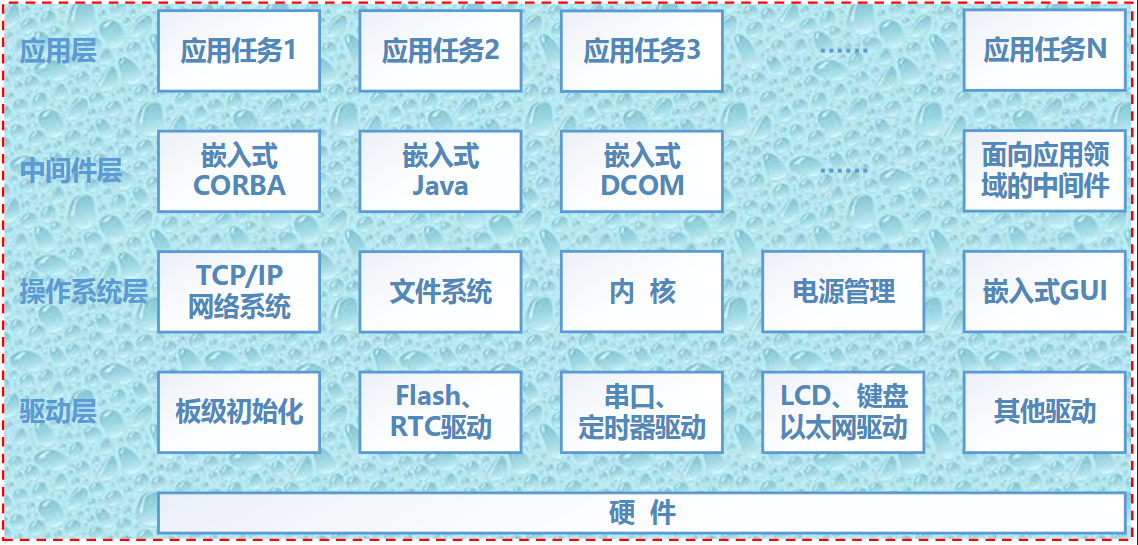
驱动层
板级初始化程序及与系统/应用软件相关的驱动
操作系统层
嵌入式内核、文件系统、TCP/IP网络系统、GUI系统和电源管理等
中间件层
嵌入式CORBA、Java等中间件软件
应用层
多个相对独立应用任务(如I/O、计算和通信等)组成
常使用操作系统作为软件平台,由专用引导程序在系统上电时进行系统引导,对底层硬件采用驱动程序方式进行调用,各类应用程序运行于操作系统之上
嵌入式软件系统工作流程
上电复位、板级初始化:堆栈指针寄存器、BSS段及CPU芯片级(如中断控制器和内存等)初始化
系统引导/升级:多种方式
系统初始化:
操作系统等所需:堆栈空间、数据空间,接口和外设等
按特定顺序:内核 → 网络、文件系统 → 中间件
应用初始化:应用任务、信号量和消息队列等创建
多任务应用:多任务状态,操作系统进行任务调度
嵌入式软件系统引导和加载
功能:初始化硬件,建立内存空间映射图,调用操作系统内核
过程:(一般指Bootloader的运行)
- 依赖于CPU体系结构的硬件初始化代码(汇编),依次任务为:硬件设备初始化、准备RAM空间、设置堆栈、跳转至步骤2入口(准备下一步)
- 加载操作系统内核映像与根文件系统,调用操作系统运行(C语言,但不能用glibc库中函数),依次任务为:初始化本阶段用到的硬件设备、检查系统内存映射、将核与根文件映像从Flash读入RAM、设置内核启动参数、调用操作系统内核
嵌入式软件特点
- 强调软硬件协同,理解系统和外围设备性能、结构、资源,高效发挥硬件性能,节约成本,易维护、移植
- 常需固化在目标系统存储器或处理器内部存储资源中
- 开发需使用:交叉编译环境及仿真器等开发工具、目标系统、示波器等测试设备支持
- 对实时性要求高,能对异常事件或命令做出迅速反应
- 对抗干扰性、稳定性和可靠性要求较高
- 需考虑代码大小(因存储空间有限),提高运行速度,降低系统功耗和成本
8.4.2. 嵌入式操作系统
EOS,屏蔽底层硬件差异,为运行其上的应用程序提供统一调用接口,主要完成:内存、多任务及外围设备等的管理
一般,嵌入到微处理器或其他存储载体中,负责全部软硬件资源的分配、调度、控制、协调,提供必要运行环境(各种系统服务供调用,如文件系统、内存分配、I/O存取、中断、任务服务、时间服务、多种通信协议和用户接口函数库等)
与硬件关系紧密,一般需移植/配置
核心体积很小,常需加载/卸载某些模块满足不同功能
(嵌入式系统将所有程序,包括操作系统、驱动及应用程序等均烧写进ROM里执行。EOS更像一套函数库)
EOS的特点:
- 强稳定性,弱交互性;运行后不需过多干预,因此需具有很强稳定性
- 较强实时性;用于各种设备控制
- 可伸缩性;具有开放、可伸缩性体系结构
- 外设接口统一性;提供各种设备驱动接口
RTOS(嵌入式实时操作系统ERTOS)
实时,能够在确定时间内完成特定系统功能或中断响应;当外界事件或数据产生时,能够接受并快速处理,其处理结果能在规定时间内控制或响应生产过程
特征主要包括:允许多任务、带有优先级的任务调度、资源的同步访问、任务间通信、定时时钟、所有实时任务受控协调一致运行等
应用RTOS的一般背景:
- 需并行运行多个较复杂任务,任务间需要进行实时交互
- 需为应用程序提供统一API,实现应用软件与硬件驱动独立开发,便于应用程序开发与维护
- 需满足工业控制、军事设备、航空航天等领域对系统响应时间的苛刻要求
- 硬件具备足够处理能力
8.4.3. 程序开发模式
基于寄存器
- 与硬件关系密切,直接面对底层部件、寄存器和引脚
- 程序代码比较紧凑,冗余较少,生成机器码较小
- 开发难度较大、效率较低、周期较长、调试烦琐、程序可读性差、维护升级较难、移植性较差
- 可帮助更加清晰了解和掌握STM32的架构、原理
基于(ST)固件库
- 底层硬件接口部分被封装(为函数),不需太关注硬件
- 库函数是位于寄存器与用户层间预定义代码API(包括一系列宏、数据结构和函数等),向下实现寄存器直接相关操作,向上为应用程序提供(配置寄存器的)标准接口
- 易上手、阅读、维护,开发难度降低,开发周期缩短
- 封装后程序更易编写、理解、维护、移植
基于操作系统
- 基于操作系统的API接口函数,完成开发
- 需较好把握操作系统、多任务等理论及应用
中间件
如STM32Cube,统一集成化开发平台,整合图形式配置器和初始化C代码生成器,向导功能帮助有效配置微处理器引脚、时钟树和外设接口。配置完成,自动生成初始化C代码
8.4.4. 软件开发流程
循环轮询系统架构
最简单的,由一个初始化函数和一个无限循环构成
- 周而复始依次检查每个输入条件,一旦满足某条件就进行相应处理
- 结构简单,易理解编程,但无法及时响应紧急事件(需等下轮循环)
- 适于规模较小简单嵌入式系统
前后台系统架构
- 前后台:在循环轮询基础上增加中断功能,又称中断驱动系统,由一个后台程序和多个前台程序构成
- 后台:循环轮询,不断依次检测条件并做相应处理
- 前台:由一些中断服务程序ISR组成,负责处理需快速响应的异步事件
- 后台持续运行(也称任务级/主程序),某前台事件(通常是外部事件)发生时,产生某中断,转入某前台(即中断程序)处理,完成后返回后台,继续执行
- 大多前台只完成基本操作,如标记、向后台发信号等;后台完成其他操作,如数据运算、存储和显示等
工程方式
- 从ST官网下载STM32F10x标准外设库
- 下载安装嵌入式开发工具(如KEIL MDK等)
- 以官方工程模板为基础,根据所用微处理器型号和软件编译设置,更改相关配置选项
- 编写程序代码,主要是User组中的main.c和stm32f10x_it.c
- 编译和链接工程
- 使用软件模拟仿真或下载硬件运行(仿真器跟踪运行)等方式调试程序
- 将可执行程序下载至目标微处理器内置ROM中,复位,运行
8.5. ARM中的GPIO
8.5.1. 概述
- 通用输入输出端口,实现数字交换及对外围设备(如LED和按键等)最简单直观监控,还可用于串行和并行通信、存储器扩展等
- 可提供最多112个多功能双向I/O引脚,分布在GPIOA、GPIOB、...、GPIOF和GPIOG等端口中
- 端口号以大写字母命名,A~G(最多7个)
- 每个端口有16个引脚,以数字命名,从0开始,依次,到15为止
- 例如,STM32F103RCT6的GPIOA有16个引脚,分别为PA0,PA1,PA2,...,PA15
8.5.2. 工作原理
8.5.2.1. 内部结构
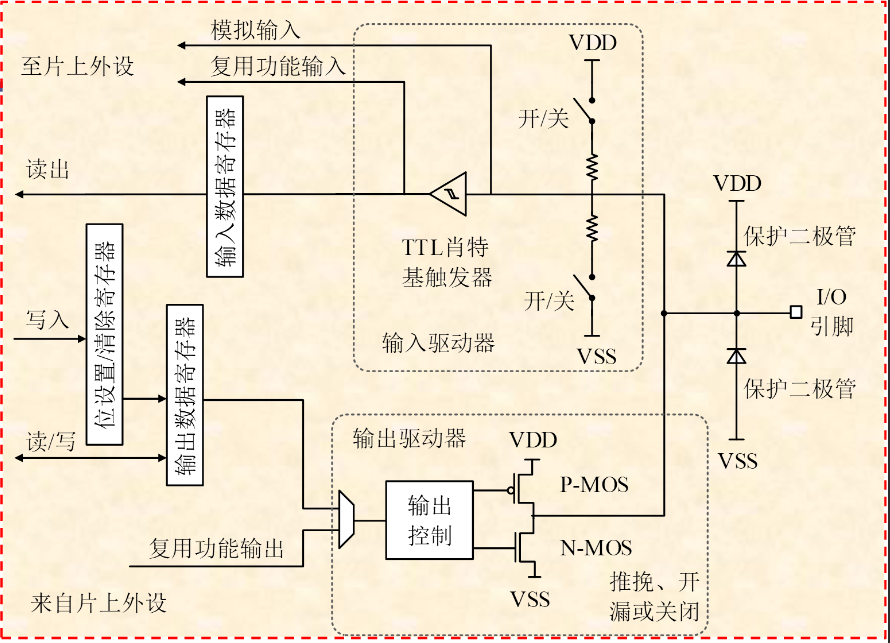
输出驱动器:多路选择器、输出控制和一对互补的MOS管组成
输入驱动器:TTL肖特基触发器、带开关的上拉电阻电路和带开关的下拉电阻电路组成
输出驱动器
多路选择器:根据设置决定该引脚是普通输出(来自GPIO的输出数据寄存器)还是复用功能AF输出(可能来自多个不同片上外设,同一时刻,一个引脚只能使用这些复用功能中的一个,其他复用功能都处于禁止状态)
输出控制逻辑和一对互补的MOS管:输出控制逻辑根据设置通过控制PMOS管和NMOS管的状态(导通/关闭)决定GPIO输出模式(推挽、开漏还是关闭)
- 推挽结构:一般指两个三极管分别受两个互补信号控制,总是一个导通时另一个截止,各负责正、负半周期的波形放大任务;导通损耗小、效率高;输出既可向负载灌电流,也可从负载抽取电流(拉电流);相比普通输出,推挽输出提高负载能力和开关速度
- 开漏输出:可提供灵活电平输出方式,即改变外接上拉电源的电压,便可改变输出电平电压高低;吸收电流能力相对较强(可达20mA),适合做电流型驱动(如驱动继电器)
输入驱动器
与输出驱动器不同,输入驱动器没有多路选择开关,输入信号送到输入数据寄存器的同时也送给片上外设,所以输入没有复用功能选项
根据TTL肖特基触发器、上拉电阻端和下拉电阻端两个开关的状态,GPIO的输入可分为以下4种:
- 模拟输入:TTL肖特基触发器关闭
- 上拉输入:GPIO内置上拉电阻,此时,上拉电阻端的开关闭合,下拉电阻端的开关打开。该模式下,引脚在默认情况下输入为高电平
- 下拉输入:GPIO内置下拉电阻,此时,下拉电阻端的开关闭合,上拉电阻端的开关打开。该模式下,引脚在默认情况下输入为低电平
- 浮空输入:GPIO内部既无上拉电阻也无下拉电阻,此时上拉和下拉电阻端的开关都处于打开状态。该模式下,引脚在默认情况下为高阻态(即悬空),其电平高低完全由外部电路决定
8.5.2.2. 工作模式
- 普通推挽输出PP:可输出低0/高VDD电平,较大功率驱动
- 普通开漏输出OD:只能输出低电平0;若想输出高电平(外接上拉电源的电压)需外接上拉电阻和电源;通常,连接到不同电平器件、线与输出或模拟I2C通信的I/O引脚
- 复用推挽输出AF_PP:不再是普通I/O,不仅具有推挽输出特点,还使用片内外设功能;常用作USART的Tx或SPI的MOSI、MISO、SCK
- 复用开漏输出AF_OD:不再是普通I/O,不仅具有开漏输出特点,还使用片内外设功能;常用作I2C的SCL或SDA
- 上拉输入IPU:默认上拉至高电平输入
- 下拉输入IPD:默认下拉至低电平输入
- 浮空输入IN_FLOATING:用于不确定高低电平输入;例如,连接外部按键或作为USART接收端Rx、I2C等
- 模拟输入AIN:用于外部模拟信号输入
注意事项:
对于复用输入功能,端口须配置成输入模式(浮空、上拉或下拉)且输入引脚须由外部驱动
对于复用输出功能,须配置成复用功能输出模式(推挽或开漏)
对于双向复用功能,须配置成复用功能输出模式(推挽或开漏)输入驱动器被配置成浮空输入模式
若端口配置成复用输出功能,则引脚和输出寄存器断开,并和片上外设的输出信号连接,若此外设未被激活,其引脚输出将不确定
GPIO的锁定机制允许冻结I/O配置。当在一个端口上执行了锁定(LOCK)程序,下一次复位前,将不能再更改端口配置
通过对GPIO寄存器编程,可设置每个端口工作模式,包括
- 端口配置低寄存器CRL
- 端口配置高寄存器CRH
- 端口输入寄存器IDR
- 端口输出寄存器ODR
- 端口位设置清除寄存器BSRR(又称置位/复位)
- 端口位清除寄存器BRR(又称复位)
- 端口锁定寄存器LCKR
例如,GPIOB_CRL就是B组GPIO端口的配置低寄存器,GPIOC_CRH即C组GPIO端口配置高寄存器
8.5.2.3. 输出速度
输出模式下,常需设置其输出速度(指I/O口驱动电路响应速度,非输出信号速度)
有多个响应速度不同的输出驱动电路,根据需要选择,达到最佳噪声控制和降低功耗目的
一般推荐I/O引脚的输出速度是其输出信号速度的5~10倍
3种选择:2MHz、10MHz和50MHz。常见应用参考:
- 2MHz:LED、蜂鸣器普通输出、USART复用功能输出
- 10MHz:I2C复用功能输出
- 50MHz:SPI、FSMC复用功能输出
8.5.2.4. 复用功能重映射
引脚复用有几种情况:
- 某I/O引脚除通用功能外,还可设置为一些片上外设的复用功能
- 某I/O引脚除可作为某默认外设复用引脚外,还可作为其他多个不同外设的复用引脚
- 某片上外设,除默认复用引脚外,还可有多个备用的复用引脚
引脚复用重映射:可把某外设复用功能从(某默认)引脚转移至(某备用)引脚上
可分时复用外设,虚拟增加端口数量,优化引脚配置和布线设计PCB,同时减少信号交叉干扰
复用重映射需设置:复用重映射和调试I/O配置寄存器AFIO_MAPR
复用功能重映射典型举例:
从I/O引脚角度看
- 如,引脚PB10,主功能是PB10,默认复用功能是I2C2时钟端SCL和USART3发送端Tx,重定义功能是TIM2_CH3。上电复位后,PB10默认为普通输出
- 若想使用PB10的默认复用功能USART3,则需编程配置PB10为复用推挽输出模式,同时使能USART3并保持I2C2禁止状态
- 若要使用PB10的重定义复用功能TIM2_CH3,则需编程对TIM2进行重映射,然后再按复用功能方式配置
从外设复用功能角度看
- 如,USART2,发送端Tx和接收端Rx默认映射到引脚PA2和PA3
- 若此时PA2已被另一复用功能TIM2_CH3占用,就需对USART2进行重映射,将Tx和Rx重新映射到引脚PD5和PD6
复用功能重映射的实现:
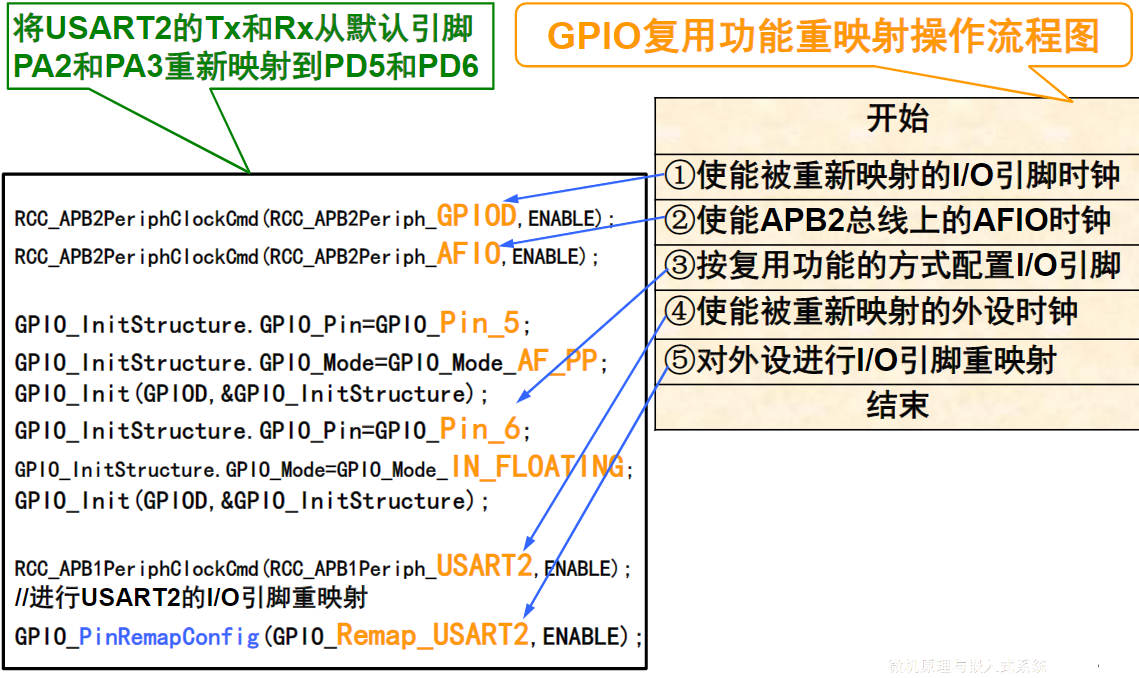
8.5.2.5. 外部中断映射和事件输出
外部中断映射
- 当某I/O引脚被映射为外部中断线后(须配置成输入模式)就可作为一个外部中断输入源,在其上产生外部中断
- 所有I/O引脚均具有输入外部中断能力,每个外部中断线EXTIn和所有GPIO端口GPIOA~Gn共享
事件输出
几乎每个I/O引脚(除端口F和G外)都可用作事件输出如,使用SEV指令产生脉冲,通过事件输出信号将STM32F103从低功耗模式中唤醒
8.5.2.6. STM32F10x的GPIO主要特性
- 提供最多112个多功能双向I/O引脚,80%利用率
- 除ADC外,均兼容5V,具有20mA驱动能力
- 最高18MHz翻转速度,50MHz输出速度
- 8种工作模式,在复位时和刚复位后,复用功能未开启,被配置成浮空输入模式
- 所有引脚均具备复用功能
- 某些复用引脚可通过复用功能重映射用作另一复用功能
- 所有引脚均可作为外部中断输入,同时可有16个
- 每个引脚(除端口F和G外)均可用作事件输出
- PA0可作为从待机模式唤醒引脚;PC13,入侵检测引脚
8.5.3. 相关库函数及寄存器
8.5.3.1. 库函数
存放于stm32f10x_gpio.h和stm32f10x_gpio.c中
常用库函数
GPIO_DeInit:将GPIOx端口的寄存器恢复为复位启动时的默认值GPIO_Init:根据GPIO_InitStruct中指定的参数初始化GPIOx端口GPIO_SetBits:将指定的GPIO端口的一个或多个指定引脚置位GPIO_ResetBits:将指定的GPIO端口的一个或多个指定引脚复位GPIO_Write:向指定的GPIO端口写入数据GPIO_ReadOutputDataBit:读取指定GPIO端口的指定引脚输出值(1b)GPIO_ReadOutputData:读取指定GPIO端口的输出值(16b)GPIO_ReadInputDataBit:读取指定GPIO端口的指定引脚的输入值(1b)GPIO_ReadInputData:读取指定GPIO端口的输入值(16b)GPIO_EXTILineConfig:选择被用作外部中断/事件线的GPIO引脚
初始化结构体

典型库函数——初始化函数GPIO_Init

8.5.3.2. 常用寄存器
- 每个GPIO端口(以x区分)共有7个寄存器,均为32位
- 两个配置寄存器(低CRL,高CRH)、两个位数据寄存器(输入IDR,输出ODR)、置位/复位寄存器BSRR、复位寄存器BRR和锁定寄存器LCKR
- 每个端口位可自由编程,但寄存器须按32位字被访问(不允许半字、字节或位访问)
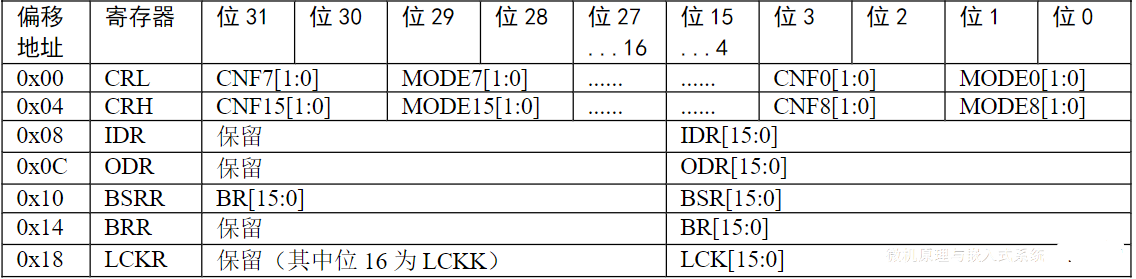
端口配置低寄存器CRL
- 偏移地址0x00;复位值0x4444 4444
- 每个GPIO端口有16位,对应芯片16个引脚,CRL用于控制端口低8位(0~7引脚),CRH控制端口高8位(8~15引脚)
- CRL中每4位为1组,每组控制1个引脚的配置(输入/输出模式),32位共控制8个引脚
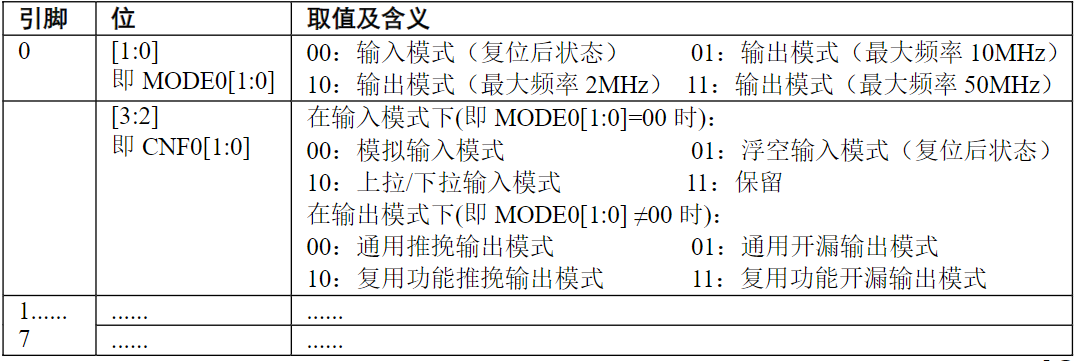
其余寄存器
- IDR,只读,仅低16位[15:0]有效,其值为对应I/O口(即端口引脚)的状态(0或1)
- ODR,读/写,仅低16位有效;写时:其值影响对应I/O口(即端口引脚)的输出(0或1,即输出低/高电平);读时:为上一次写出数据
- BSRR,只写,设置某特定引脚输出电平(0/1),保持其他引脚输出不变;可分别对各ODR位独立设置/清除(即置位1/复位0);高16位[31:16]复位对应引脚(15~0)为0,低16位[15:0]置位对应引脚(15~0)为1
- BRR,只写,清除某特定引脚输出电平(为0),保持其他引脚输出不变;仅低16位有效,复位对应引脚(15~0)为0
举例:
GPIOD引脚4:50MHz推挽输出,引脚15:上拉下拉输入模式
寄存器设置:
CRL.CNF4为00,CRL.MODE4为11,CRL.CNF7为10,CRH.MODE7为00xxxxxxxxxxGPIOD_CRL&=0XFFF0FFFF; //清掉对位4的配置GPIOD_CRL|=0X00030000; //写位4的配置为0011b(即3)GPIOD_CRH&=0X0FFFFFFF; //清掉对位15的配置GPIOD_CRH|=0X8000000; //写位15的配置为1000b(即8)假设GPIOD位4、位5(即引脚4、5)端口50MHz频率推挽输出
现将位4置1输出高电平,可如下:
xxxxxxxxxxGPIOD_ODR| =1<<4;//等同于GPIOD_ODR| =0x10;若写成
GPIOD_ODR=0x10,将PD其他位都清0了,会引发不可预测后果使位4端口再输出低电平,可如下:
xxxxxxxxxxGPIOD_ODR&=(~(1<<4)); //等同于GPIOD_ODR& =0xEF(11101111B)若使位4端口输出低电平,位5端口输出高电平,可如下:
xxxxxxxxxxGPIOD_ODR&=(~(1<<4));GPIOD_ODR|=1<<5;需两条语句,且均有回读操作,不适合高实时性。可用BSRR完成:
xxxxxxxxxxGPIOD_BSRR=0x00100020避免回读(&=或|=),且一次实现2个引脚操作,效率高,速度快
用BRR完成位4端口输出低电平:
xxxxxxxxxxGPIOD_BRR=1<<4
8.5.3.3. AFIO寄存器
- 事件控制寄存器AFIO_EVCR:将事件输出重映射到PA0~15、PB0~15、PC0~15、PD0~15、PE0~15
- 复用重映射和调试I/O配置寄存器AFIO_MAPR:配置SWJ和跟踪复用的I/O口;ADCx/TIMx/USARTx/SPI1/I2C1等的重映射
- 外部中断配置寄存器1~4,AFIO_EXTICR1~AFIO_EXTICR4:用于配置I/O口作为外部中断源输入
8.5.4. 应用与举例
GPIO开发三部曲
使用任何一个片上外设,此步都不可少,一般在初始化一开始就进行
GPIO_InitTypeDef结构体是引脚配置关键,由其成员可快速了解GPIO特性;将指定工作模式和输出速度等写入对应成员,用此结构体变量初始化指定引脚,可实现对引脚真正配置若引脚设置为输出,操作引脚是往该引脚输出高/低电平
若引脚设置为输入,操作引脚是从该引脚读取高/低电平
8.6. 定时器
8.6.1. 概述
STM32F103可编程定时器主要类型:
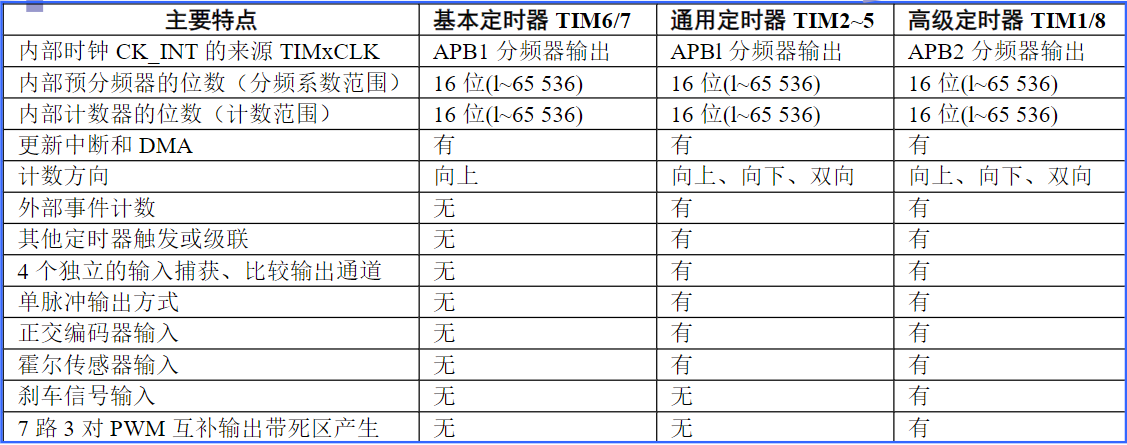
具有延时、信号频率测量、信号PWM测量、PWM输出、三相六步电机控制及编码接口等功能
从功能上看,基本定时器是通用定时器的子集,通用定时器是高级定时器的子集
基本TIM6和TIM7
- 16位时基计数器,可用于产生DAC触发信号
通用TIM2、TIM3、TIM4和TIM5
- 均由一个16位可编程预分频器驱动的一个16位自动装载递加/递减计数器构成
- 均具有4个独立通道(CH1~4),每个通道均可用于输入捕获、比较输出、PWM和单脉冲模式输出
- 可用于测量输入信号的脉冲长度(输入捕获)或产生输出波形(比较输出和PWM)
- 使用时,一般需配置一个时基单元,确定时间基准,其核心部件为16位预分频器
高级TIM1和TIM8
- 可视为分配到6个通道的三相PWM发生器,常用于电机控制(另具死区控制/紧急制动等特性)
- 均可作为完整的通用定时器
- 可产生PWM(边缘或中心对齐)、互补PWM和单脉冲
- 可被当成完整的通用定时器使用
独立的看门狗
- 基于一个12位递减计数器和一个8位预分频器
- 由一个内部独立的40kHz RC振荡器提供时钟(独立于主时钟),可运行于停机和待机模式
- 发生问题时复位系统
- 也可作为一个自由定时器,为应用程序提供超时管理
- 通过选择字节可配置为软件或硬件启动
- 调试模式,计数器可被冻结
窗口看门狗
- 内有一个7位递减计数器,可设置成自由运行
- 发生问题时复位系统
- 由主时钟驱动,具有早期预警中断功能
- 调试模式,计数器可被冻结
系统时间定时器SysTick
- 常用于操作系统
- 可作为一个标准24位递减计数器
8.6.2. 基本定时器TIM6和TIM7
8.6.2.1. 内部结构
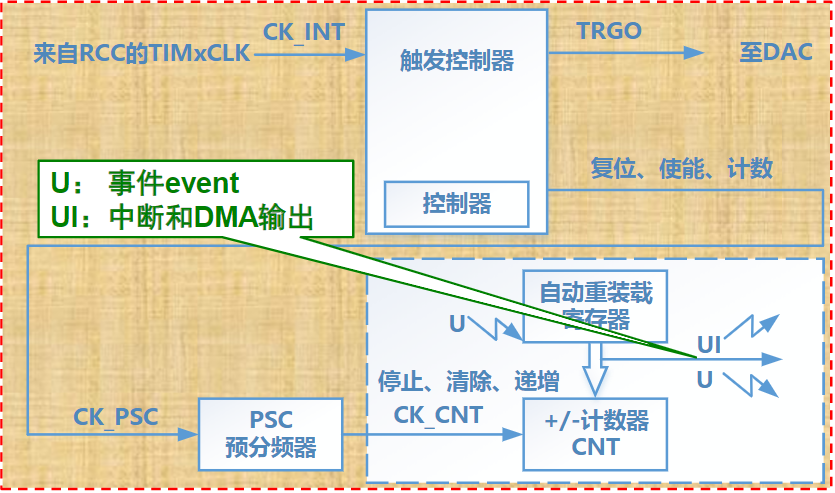
构成:
- 触发控制器
- 可编程16位预分频器
- 带自动重装装载寄存器的16位计数器CNT
计数器是核心,由预分频器驱动,自动重装载预设值
TIM6和TIM7只有最基本的定时功能(提供时间基准),即累计时钟脉冲数超过预设值时,产生定时器溢出事件
如果使能了中断或DMA操作,将产生中断或者DMA操作
8.6.2.2. 时钟源
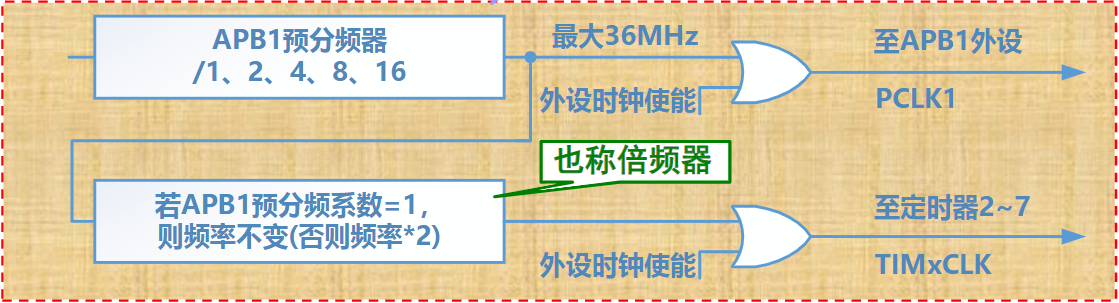
定时器时钟源路径:
APB1预分频 → TIMxCLK → CK_INT → 预分频(PSC)→ CK_CNT
- 定时器时钟CK_CNT,控制计数基准频率
- 只有一种时钟源,内部时钟CK_INT
- CK_INT来自RCC的TIMxCLK(不同定时器来源不全相同)
- TIMxCLK来源于APB1预分频器的输出
- 上电复位后,APB1预分频系数为2,APB1时钟频率PCLK1为36MHz,因此,TIMxCLK为72MHz
8.6.2.3. 计数模式
基本定时器仅有向上计数模式,自动重装载寄存器ARR保存定时器溢出值/预设值
工作过程:计数器从0开始,在CK_CNT触发下不断累加计数;当计数器CNT计数值等于ARR中预设值时,产生溢出事件,可触发中断或DMA请求(已使能时);然后,CNT计数值被清零,重新开始向上计数
延时时间=(ARR+1)*(PSC+1)/TIMxCLK
其中,ARR(预设值)和PSC(预分频系数)都是16位,取值范围0~65535;TIMxCLK为72MHz(上电复位后,通常值)
8.6.2.4. 基本工作原理
更新事件UEV(Update Event)
- 指这个事件发生后,定时器寄存器将进行更新(以工作于新配置);如定时周期结束(计数器上溢)或其他事件(如,软件产生)均为UEV
- 发生UEV时:硬件依据
CR1.URS位设置,设置更新中断标记SR.UIF状态(0/1:是/否产生中断或DMA请求),同时所有寄存器均被更新(重复计数器重新装载RCR值;自动重装载寄存器重新置入ARR值,预分频器重置为PSC值) - 设置
CR1.UDIS=1,可禁止更新事件(用来避免在写入新寄存器值时更新影子寄存器),在CR1.UDIS被清零之前,将不产生更新事件。此时,在应产生更新事件时,计数器及预分频器的计数仍被清零,但预分频器数值不变 - 设置
EGR.UG=1(通过软件方式或使用从模式控制器),同样也可产生一个UEV - 若设置了
CR1.URS=1(选择更新请求),当置EGR.UG=1时,将产生一个更新事件,但硬件不设置SR.UIF(即仍为0),即不产生中断或DMA请求,以避免捕获模式下清除计数器时,同时产生更新和捕获中断
预分频寄存器PSC:存放分频系数,16位
计数器CNT:存放当前计数值,16位
自动重装载寄存器ARR:决定定时器的上溢时刻(定时周期),当计数器在(向上)计数过程中,计数值达到ARR值,计数器就要归零
时基单元:包含CNT、PSC、ARR三部分(通用和高级定时器另有RCR),这些寄存器均可由软件任意读/写
定时(周期)计算公式:
Tout(μs)=((ARR+1)*(PSC+1))/TCLK(MHz)
影子寄存器shadow和预装载寄存器preload
- 物理上,某寄存器对应2个寄存器:一个是可写入/读出的寄存器,称为预装载寄存器;另一个是看不见、无法真正对其读写操作,但在使用中真正起作用的寄存器,称为影子寄存器
- 具此特性寄存器如下几种:PSC、ARR、RCR、自动捕获寄存器CCR1~4(基本定时器无RCR和CCR1~4)
- 影子寄存器未提供开放给用户,仅提供与之相对应的预装载寄存器
- PSC、ARR、RCR、CCRx均不是影子寄存器,而是对应的预装载寄存器
- 用户能修改或读取的都是预装载寄存器
- 影子寄存器的值来自预装载寄存器
- 值从预装载寄存器传送到影子寄存器,有两种方式:一是立刻更新,另一是等触发事件之后更新;具体方式的选择取决于相应控制寄存器里控制位的设置(是否允许影子寄存器,即是否有缓冲区)
- 影子寄存器又称(对应某寄存器的)缓冲区
ARR(作为预装载寄存器)和影子寄存器的关系
根据CR1.APRE的设置,ARR内容:可随时传送到影子寄存器,即两者是连通的(permanently);或在每次更新事件UEV时,才传送到影子寄存器,具体:
CR1.APRE=0,当ARR值被修改时,同时更新影子寄存器的值(无预装功能)CR1.APRE=1,ARR值被修改时,须在下次UEV发生后,才更新影子寄存器值(即有缓冲区,预装功能)
如需立刻更改影子寄存器的值,而不是等待下一个事件,可有如下两种方法:
使
CR1.APRE=0,即:xxxxxxxxxxTIM_ARRPreloadConfig(ch1_Master_Tim, DISABLE)使
CR1.APRE=1时,更改完ARR后,立刻设置UEV(主动发生UEV),即更改EGR.UG=1:xxxxxxxxxxTIM_GenerateEvent(TIM1,TIM_EventSource_Update)
定时/计数工作过程
- 计数器由
CK_CNT驱动,仅当设置了CR1.CEN(计数器使能位)时,CK_CNT才有效 - 预分频器可将
CK_CNT时钟频率按1~65536之间任意值分频 - 设置了
CR1.CEN=1的一个时钟周期后,计数器开始计数;当计数器达到溢出条件并当CR1.UDIS=0时,产生更新事件,若中断允许,可同时触发中断或DMA请求
- 计数器由
8.6.2.5. 主要特性
- 具有自动重装载功能的16位累加计数器,其内部时钟CK_CNT的来源TIMxCLK来自APB1预分频器输出具有16位可编程可实时修改的预分频器,分频系数为1~65535之间任意值
- 有更新事件(如计数器溢出)时,可产生中断/DMA请求
- 可触发DAC的同步电路
8.6.3. 通用定时器TIM2~TIM5
8.6.3.1. 内部结构
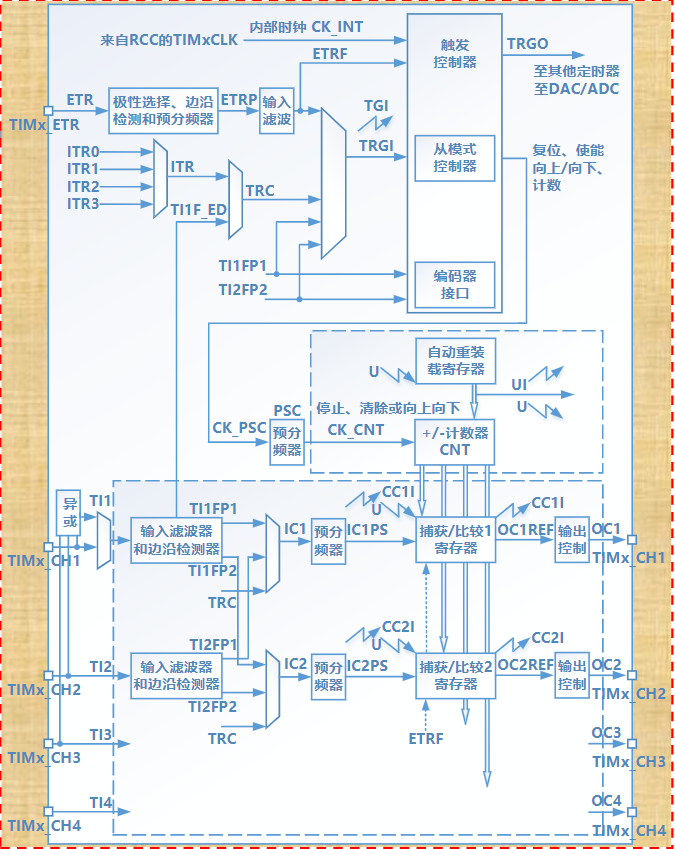
每个通用定时器:
- 完全独立
- 不共享任何资源
- 可一起同步操作
测量输入脉冲频率/宽度
可输出PWM脉冲
计数器CNT核心构成类似,主要增加:捕获/比较功能
捕获/比较寄存器CCR(Capture/Compare Register)
包括输入捕获部分(数字滤波、多路复用和预分频器)和比较输出部分(比较器和输出控制)
CCR,共用,在输入和输出模式中含义和作用不同:
- 输入捕获:输入时,当捕获的输入脉冲在电平发生翻转时,CCR加载CNT当前计数值,实现脉冲频率测量;此时,CCR是个捕获寄存器
- 比较输出:输出时,CCR用来存储一个数值,将此数值与CNT当前计数值比较,根据比较结果进行不同的电平输出;此时,CCR是个比较寄存器
8.6.3.2. 时钟源
有多种选择,可由以下四种时钟源提供:
内部时钟
CK_INT与基本定时器相同,来自RCC的
TIMxCLK,APB1预分频器输出(通常为72MHz)。如果禁止了从模式(SMCR.SMS=000),则CR1.CEN、CR1.DIR及EGR.UG是事实上的控制位,且只能被软件修改(EGR.UG位仍会被自动清除)内部触发输入
ITRxITRx来自芯片内部其他定时器的触发输入,使用一个定时器作为另一定时器的预分频器例如,可配置TIM1作为TIM2的预分频器外部输入捕获引脚
TIxTIx来自外部输入捕获引脚上的边沿信号;计数器可在选定的输入端(引脚1:TI1FP1或TI1F_ED,引脚2:TI2FP2)的每个上升沿或下降沿计数;也称外部时钟模式1(之一)配置向上计数器在TI2输入端的上升沿技术,步骤如下,设置:
xxxxxxxxxxCCMR1.CC2S=01; //配置通道2检测TI2输入的上升沿CCMR1.IC2F=0000; //不需要滤波器;CCER.CC2P=0; //选定上升沿极性;SMCR.SMS=111; //选择定时器外部时钟源模式1;SMCR.TS=110; //选定TI2作为触发输入源;CRl.CEN=1; //启动计数器。- 捕获预分频器不用做触发,所以不需进行配置
- 当上升沿出现在TI2时,计数器计数一次,且
SR.TIF被设置
外部触发输入引脚ETR
ETR信号来自外部引脚ETR,计数器能在外部触发输入ETR的每个上升沿或下降沿计数,也称外部时钟模式2
配置在ETR下每2个上升沿计数一次的向上计数器,步骤如下,设置:
xxxxxxxxxxSMCR. ETP=0; //选择ETR的上升沿检测SMCR. ETF=0000; //不需要滤波器SMCR. ETPS=01; //设置预分频器SMCR. ECE=1; //开启外部时钟源模式2SMCR.TS=110; //选定TI2作为触发输入源CRl.CEN=1; //启动计数器。
8.6.3.3. 计数模式
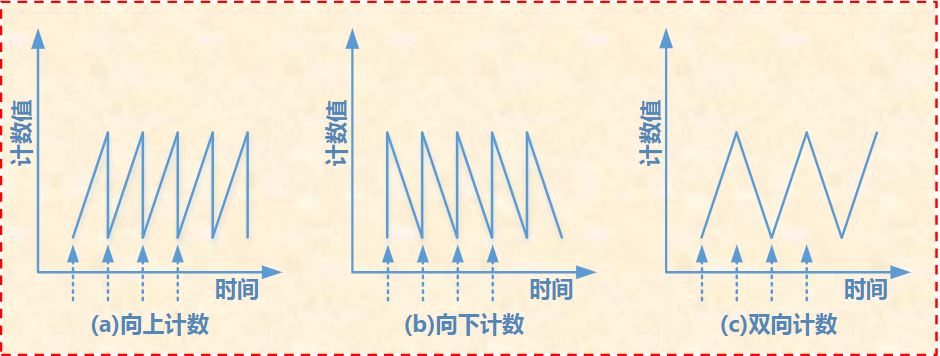
- 16位计数器CNT有3中工作模式:向上、向下、双向计数(向上/向下,也称中央对齐)
- 若使用了重复计数器功能,只要溢出次数达到重复计数(RCR值)时,才产生更新事件;否则每次计数溢出时即产生更新事件
双向计数模式

PSC值为0(内部分频系数为1),ARR预设值为6
(CR1.CEN=1)使能计数时,计数器在CK_CNT驱动下减1计数
当计数值到达1时,产生计数器下溢事件,然后继续从0开始加1计数。当计数值到达5时,产生计数器上溢事件,然后继续从6开始减1计数
计数器在CK_CNT驱动下从0开始计数到ARR的预设值-1,然后产生一个计数器溢出事件,再向下计数到1并且产生一个计数器下溢事件,接着再从0开始重新计数
此模式不能写入CR1.DIR,由硬件更新并指示当前计数方向,更新事件产生在每次计数上溢和每次计数下溢
8.6.3.4. 普通输入捕获模式
可用来测量(输入信号)脉冲宽度或频率
通过检测CHx上的边沿信号,在其发生跳变(如上升沿/下降沿)时,(利用中断功能)将当前定时器CNT值,锁存到对应通道的捕获/比较寄存器CCRx中,把前后两次捕获到的CCR值相减,即可算出脉宽或频率
除了TIM6和TIM7,其他定时器均有输入捕获功能
捕获过程信号流程:输入信号由CHx经采样、滤波后所得信号TIxF,由边沿检测器产生信号TIxFPx(可作为从模式控制器的输入触发或作为捕获控制),再通过预分频成为ICxPS进入捕获寄存器CCR,即:
CHx→TIxF→TIxFPx→ICxPS→CCR
输入通道
待测量信号从外部引脚CH1~4进入,常称为TI1~4
输入滤波和边沿检测
- 输入信号存在高频干扰时,需对其进行滤波,即重新采样(根据采样定律,采样频率须大于2倍输入信号)
- 滤波器配置由
CR1.CKD和CCMR.ICxF控制,采样频率fSAMPLE可由fCK_INT(内部时钟)或fDTS分频后提供 - 滤波器实质是一个事件计数器,记录到N个事件后会产生一个输出的跳变(即连续采样N次,以确认一次真实的边沿变换)。N大小可设,称为滤波器带宽/长度
- 边沿检测器设置信号被捕获时有效边沿,可为上升沿/下降沿/双边沿,由
CCER.CCxP和CCER.CCxNP决定
捕获通道
- 捕获通道即IC1~4,每个通道均对应一个CCR1~4,发生捕获时,CNT值会被锁存到
CCRx中 - 捕获通道和输入通道有区别:输入通道用来输入信号,捕获通道用来捕获输入信号,一个输入信号(的通道)可同时输入给两个捕获通道(比如TI1信号经滤波边沿检测器后的TI1FP1和TI1FP2可分别进入IC1和IC2)
- 测量输入信号脉宽时,用一个捕获通道即可;两者映射关系由
CCMR.CCxS配置
- 捕获通道即IC1~4,每个通道均对应一个CCR1~4,发生捕获时,CNT值会被锁存到
预分频器
ICx的输出信号会经过预分频器,决定发生多少个事件时进行一次捕获;事件个数由CCMR.ICxPSC配置捕获寄存器CCR
- 经过预分频器后的信号
ICxPS是最终被捕获信号 - 第一次捕获发生时,CNT值被锁存在CCR中,并产生中断
CCxI,相应中断位SR.CCxIF被置1,通过软件或读取CCR值可将SR.CCxIF清0 - 若发生第二次捕获(即CCR已捕获CNT值且
SR.CCxIF已置1),则捕获溢出标志SR.CCxOF会被置位(对其清零只能通过软件) - 捕获寄存器实际由预装载和影子寄存器组成;读/写过程仅操作预装载寄存器;捕获模式下,捕获发生在影子寄存器上,然后再复制到预装载寄存器中
- 经过预分频器后的信号
输入捕获过程描述
- IC1~4可分别通过软件设置将其映射到TI1~4;每次检测到ICx信号上相应边沿后,CNT当前值被锁存到
CCRx中(即捕获事件发生),SR.CCxIF被置1(若已使能中断/DMA操作,会产生中断/DMA操作) - 外部事件发生的触发信号由对应引脚输入
- 输入捕获可用来捕获外部事件,并为其赋予时间标记以说明此事件的发生时刻;时间标记可用来计算频率,占空比及信号的其他特征,以及为事件创建日志
- 例如,捕获上升沿,(前后两次值)相减,代表这两个上升沿中间那段电平的时间
设置在TI1输入的上升沿时捕获计数器CNT值到CCR1中,如下:
xxxxxxxxxxCCMR1.CC1S=01; //CC1被设置为输入,IC1映射在TI1上CCMR1.IC1F=0011; //配置输入滤波器所需带宽,连续采样8次CCER.CC1P=0; // TI1通道选择上升沿有效CCMR1.IC1PSC=00; //输入无分频器,每一个边沿都触发一次捕获CCER.CC1E=1; //允许捕获计数器的值到捕获寄存器中DIER.CC1IE=0; //允许中断请求DIER.CC1DE=0; //允许DMA请求测量脉冲宽度(捕获高电平脉宽):
- 首先设置输入捕获为上升沿触发,然后记录发生上升沿时CNT值
- 其后,设置捕获信号为下降沿,在下降沿到来时,记录此时CNT值
- 两次CNT值之差即为脉冲宽度
示例:利用ST库函数实现TIM设置,使用TIM2的1/3通道进行频率测量,设置过程如下:
xxxxxxxxxxTIM_ICInitStructure.TIM_ICMode=TIM_ICMode_ICAP;//配置为输入捕获模式TIM_ICInitStructure.TIM_Channel=TIM_Channel_1; //选择通道1TIM_ICInitStructure.TIM_ICPolarity=TIM_ICPolarity_Rising;//输入上升沿捕获TIM_ICInitStructure.TIM_ICSelection=TIM_ICSelection_DirectTI;//通道方向选择TIM_ICInitStructure.TIM_ICPrescaler=TIM_ICPSC_DIV1;//每检测到捕获就触发一次捕获TIM_ICInitStructure.TIM_ICFilter=0x0;TIM_ICInit(TIM2,&TIM_ICInitStructure);TIM_ICInitStructure.TIM_ICMode=TIM_ICMode_ICAP;TIM_ICInitStructure.TIM_Channel=TIM_Channel_3;//选择通道3TIM_ICInitStructure.TIM_ICPolarity=TIM_ICPolarity_Rising;TIM_ICInitStructure.TIM_ICSelection=TIM_ICSelection_DirectTI;TIM_ICInitStructure.TIM_ICPrescaler=TIM_ICPSC_DIV1;TIM_ICInitStructure.TIM_ICFilter=0x0;TIM_ICInit(TIM2,&TIM_ICInitStructure);TIM_SelectInputTrigger(TIM2,TIM_TS_TI1FP1);//选择滤波后TI1作为输入触发源,触发下面程序的复位TIM_SelectSlaveMode(TIM2,TIM_SlaveMode_Reset);//复位模式-选中的触发输入(TRGI)的上升沿初始化计数器,并且产生一个更新信号TIM_SelectMasterSlaveMode(TIM2,TIM_MasterSlaveMode_Enable);//主从模式选择- IC1~4可分别通过软件设置将其映射到TI1~4;每次检测到ICx信号上相应边沿后,CNT当前值被锁存到
8.6.3.5. PWM输入捕获模式
普通输入捕获模式的一种特殊应用
将同一输入映射两个ICx信号(IC1和IC2),其中一个捕获上升沿,另一个捕获下降沿,在中断中读上升沿和下降沿分别对应的CNT值,得到周期和占空比,具体即:
- 一个捕获通道计算两次上升沿间隔时间,即周期T
- 另一通道计算下降沿和之前上升沿之差,即高电平时长
- 由周期T及高电平时长得出占空比
PWM输入捕获与普通输入捕获区别
- 2个
ICx信号被映射至同一个TIx输入 - 2个
ICx信号为边沿有效但极性相反 - 其中一个
TIxFP作为触发输入(SMCR设为复位模式)
- 2个
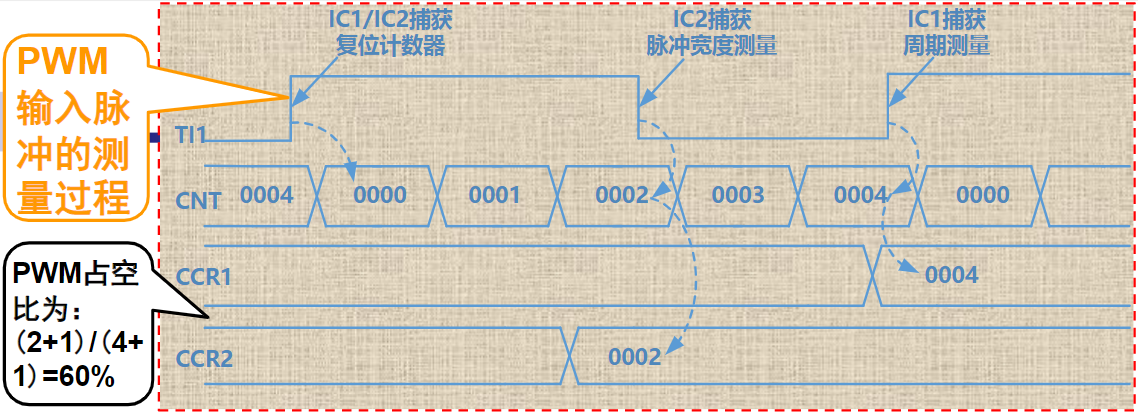
将待测PWM输入信号通过GPIO引脚输入到定时器PWM检测通道TI1,设置CNT向上计数(ARR预设值足够大)
输入脉冲TI1上升沿到达时,触发IC1和IC2输入捕获中断,CNT值复位为0随后,CNT在CK_CNT驱动下从0开始累加计数
TI1下降沿到来时,触发IC2捕获事件,CNT当前值被锁存到CCR2中,CNT继续累加。(设TCK_CNT为CK_CNT周期)
待测脉冲高电平时间为
(CCR2+1)*TCK_CNTTI1第二个上升沿到达时,触发IC1中断,CNT当前值锁存到CCR1中,同理待测脉冲周期为
(CCR1+1)*TCK_CNT由周期和高电平时间,可算出占空比为
(高电平时间/脉冲周期)*100%=(CCR2+1)/(CCR1+1)
8.6.3.6. 比较输出模式
常用于控制输出一个波形或指示一段给定时间已到
当CNT计数值(变动至)与CCR值相等时:
- 相应输出引脚可根据所设置编程模式选择以下赋值(并输出):置位、复位、翻转或不变
- 状态寄存器SR中相应标志位置位
- 如果相应中断屏蔽位置位且中断使能,则产生中断
- 如果DMA请求使能置位,则产生DMA请求
CCR能在任何时候通过软件进行更新以控制输出波形,前提条件是不使用预装载寄存器(即
CCMR.OCxPE=0),否则只能在发生下一次更新事件时被更新
比较输出模式下翻转OC1的时序图:

比较输出寄存器
当CNT值跟CCR值相等时,输出参考信号
OCxREF会发生改变(再经过一系列控制后成为真正输出信号OCx/OCxN),并产生比较中断CCxI,SR.CCxIF置1死区发生器
仅高级定时器才有;在
OCxREF基础上,插入死区时间,用于生成两路互补的输出信号OCx和OCxN输出控制
进入输出控制电路的信号被分成两路,原始和被反向信号(通过设置
CCER.CCxP和CCER.CCxNP控制极性选择);由OCx输出到外部引脚CHx/CHxN(通过设置CCER.CxE和CCER.CxNE控制是否输出)输出引脚
比较输出的输出信号最终通过定时器外部IO输出,分别为CH1~4(前三通道还有互补的输出通道CH1~3N)
比较输出模式种类
共8种:冻结、匹配时输出有效/无效电平、翻转、强制为有效/无效电平、PWM1/2;(通过设置
CCMR.OCxM选择模式)。其中,- PWM1/2:是比较输出的特例,使用也最多
- 强制输出有效/无效:直接由软件强制为有效(高电平)或无效(低电平),不依赖于比较结果(但仍可有中断和DMA请求)
比较输出原理
即通过(计数值和CCR比较后)定时器外部引脚输出受控的波形。可认为有两部分实现信号(的受控)输出:
- 一是计数部分,将计数器CNT设为某工作模式并初始化后,CNT不停自动计数
- 一是比较部分,设置匹配值CCR,并在CNT计数过程中,不停将当前计数值与CCR值进行比较,二者相等时产生一个匹配,然后根据(输出的)具体设置,输出高/低电平信号,从而在输出端生成预期波形
比较输出模式的说明:
- 匹配发生时,会产生比较中断(中断已使能时)
- 设置
CCMRx.CCxS=00,即选择相应通道为输出模式 CCMRx.OCxPE选择CCRx是否需要使用预装载寄存器- 比较输出模式下,UEV对
OCxREF和OCx输出没有影响 - 比较输出精度可达到计数器的一个计数周期
- 比较输出模式(在单脉冲模式下)也可输出一个单脉冲
PWM输出模式
PWM的定义和应用
脉冲宽度调制(简称脉宽调制),指对脉冲宽度的控制,利用数字输出对模拟电路进行控制。在电力电子中应用广泛,包括:测量、通信、功率控制与变换、电机控制、伺服控制、调光、开关电源等
PWM的实现
- 传统数字电路方式:电路设计较复杂,体积大,抗干扰能力差,系统控制周期较长
- 微处理器普通I/O模拟方式:通过CPU操控普通I/O口实现PWM输出,时间消耗大,CPU效率低,精度低
- 微处理器PWM直接输出方式:简单配置后即可在(具有PWM输出功能)微处理器指定引脚上输出PWM脉冲
PWM输出模式的工作过程
假设:CNT向上计数,ARR预设值N,CNT当前计数值X,CCR预设值A,时钟周期TCK_CNT。工作过程:
X在CK_CNT驱动下从0开始不断累加计数
X(在计数同时)与A进行比较:
若X<A,输出高/低电平;若X≥A,输出低/高电平
当X大于N时,X清零并重新开始计数
循环往复,所得PWM输出信号:周期为
(N+1)*TCK_CNT,脉冲宽度为A*TCK_CNT,占空比为A/(N+1)PWM输出模式的说明
- 对外输出脉宽可调方波信号,ARR值确定频率,CCR值确定占空比;
占空比=(CCR+1)/(ARR+1) - 设置
CCMRx.OCxM=110(PWM模式1)或=111(PWM2),能独立设置每个OCx输出通道产生一路PWM - 设置
CCMRx.OCxPE=1,可使能相应CCR预装载寄存器 - 开始计数之前,须设置
EGR.UG=1来初始化所有寄存器 OCx极性通过设置CCER.CCxP实现(高/低电平)OCx输出使能通过CCER.CCxE、CCER.CCxNE、BDTR.MOE、BDTR.OSSI、BDTR.OSSR的组合控制- PWM模式1/2下,依据计数方向,确定是否
CCRx≤CNT,并根据CR1.CMS状态,选择边沿或中央对齐模式
- 对外输出脉宽可调方波信号,ARR值确定频率,CCR值确定占空比;
单脉冲模式OPM
- 众多模式的一个特例
- 允许计数器响应一个激励,在可编程延时后产生一脉宽可程序控制的脉冲
- 软件可设定选用两种单脉冲模式波形:单脉冲或重复脉冲
编码器接口
- 编码器常用于测量运动系统(直线和圆周运动)位置和速度
- 编码器接口模式用作对外部设置的方向选择
- 计数器提供当前位置信息(如电动机转子旋转角度)
- 为获取动态信息(速度、加速度),须通过另一定时器测量产生两个周期性事件之间的计数值
主要特性(相比基本定时器所增加特性)
- 自动重装载16位递增/递减计数器,具备3种计数模式
- 时钟来源,除内部时钟,另有:内部触发输入
ITRx、外部输入捕获TIx、外部触发输入ETR - 4独立通道,均可用于输入捕获、比较输出、PWM输入和输出(边沿或中央对齐模式)及单脉冲模式输出
- 在更新事件(上溢/下溢、软件或内部/外部触发引起计数器初始化)、触发事件(计数器启动/停止/初始化或内部/外部触发计数)、输入捕获、比较输出等发生时,可产生中断/DMA请求
- 支持针对定位的增量(正交)编码器和霍尔传感器电路
- 使用外部信号控制定时器和定时器互连的同步电路
8.6.4. 高级定时器TIM1和TIM8
除具有通用定时器所有功能外,还可视为一个分配到6个通道的三相PWM发生器,具有嵌入死区时间的互补PWM输出
完全独立,不共享任何资源,可同步操作
内部结构
与通用定时器相比,主要多了BRK和DTG两个结构,因而具有死区时间控制功能
时钟源
与通用定时器唯一的不同在于:内部时钟CK_INT的来源
TIMxCLK来自APB2预分频器输出,上电复位后,APB2预分频系数为1,TIMxCLK是APB2时钟PCLK2(通常为72MHz)功能描述
相比通用定时器,另具有三相六步电机的接口、刹车功能及用于PWM驱动电路的死区时间控制,非常适于控制电机
主要特性
- 内部时钟CK_CNT来源
TIMxCLK来自APB2预分频器输出 - 具有重复计数器,允许在指定数目的计数器周期之后更新
- 触发输入作为外部时钟或按周期的电流管理
- 中止(也称刹车)输入信号可将输出信号置于复位状态或一个已知状态
- 死区时间可编程的互补输出
- 内部时钟CK_CNT来源
8.6.5. 主从模式、触发与同步
所有TIMx均在内部相连,用于同步或级联
定时器一般通过软件设置启动,也可由另一定时器触发或通过外部信号触发而启动,还可通过另一定时器某一条件被触发而启动(某一条件可为:定时到时、定时器超时、比较成功等)
通过一个定时器触发另一定时器的工作方式,有时也称为定时器的同步
发出触发信号的定时器工作于主模式,接受触发信号而启动的定时器工作于从模式
8.6.5.1. 主从模式
定时器工作于主模式时,能产生触发输出(并作为其它定时器的触发输入)信号,还可对另一处于从模式的定时器进行复位、启动、停止或提供时钟等操作
定时器工作于从模式时,受到外来触发信号的影响或控制,其具体工作模式又可分为多种
定时器处于主从双角色模式:既受外来触发信号影响或控制,同时又能输出触发信号影响或控制其他从定时器
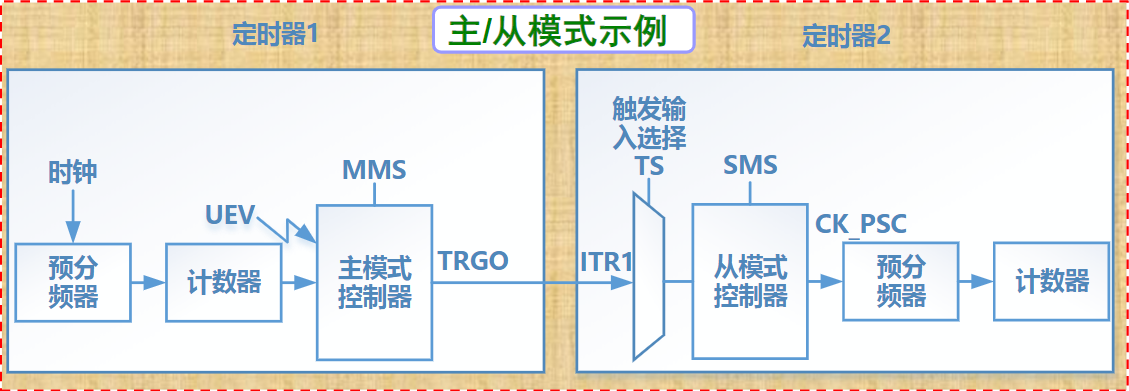
8.6.5.2. 触发
触发输出信号(TRGO)
TIM输出(至其它TIM或外设的)触发信号;一般有数种方式产生:
- 软件方式对定时器复位:置位
EGR.UG=1 - 使能计数器:置位
CR1.CEN=1 - 定时器更新事件、捕获/比较事件
- 输出通道输出参考信号
OCxREF
触发输入信号(TRGI)
从外部引入(到TIM)的触发信号,根据SMCR.TS设置,分为3类,共8个,如下:
- 来自TIM自身:TI1/2输入信号,经过极性选择和滤波后的触发信号TI1FP1/TI2FP2以及TI1输入信号经过双沿检测后再逻辑相或后的触发信号TI1F_ED(双沿脉冲信号)
- 来自外部触发引脚ETR:由ETR引入的信号经过极性选择、分频、滤波(分频和滤波并非必需)后的触发信号ETRF
- 来自其它TIM:由其他TIM定时器的触发输出信号,通过内部线路连接引入的触发信号ITRx(一般最多4路内部输入选择端)
来自定时器外部的各种触发输入信号TRGI ,均须经过触发输入选择器连接至从模式控制器SMCR(控制或影响计数器工作),此时TIM工作于从模式
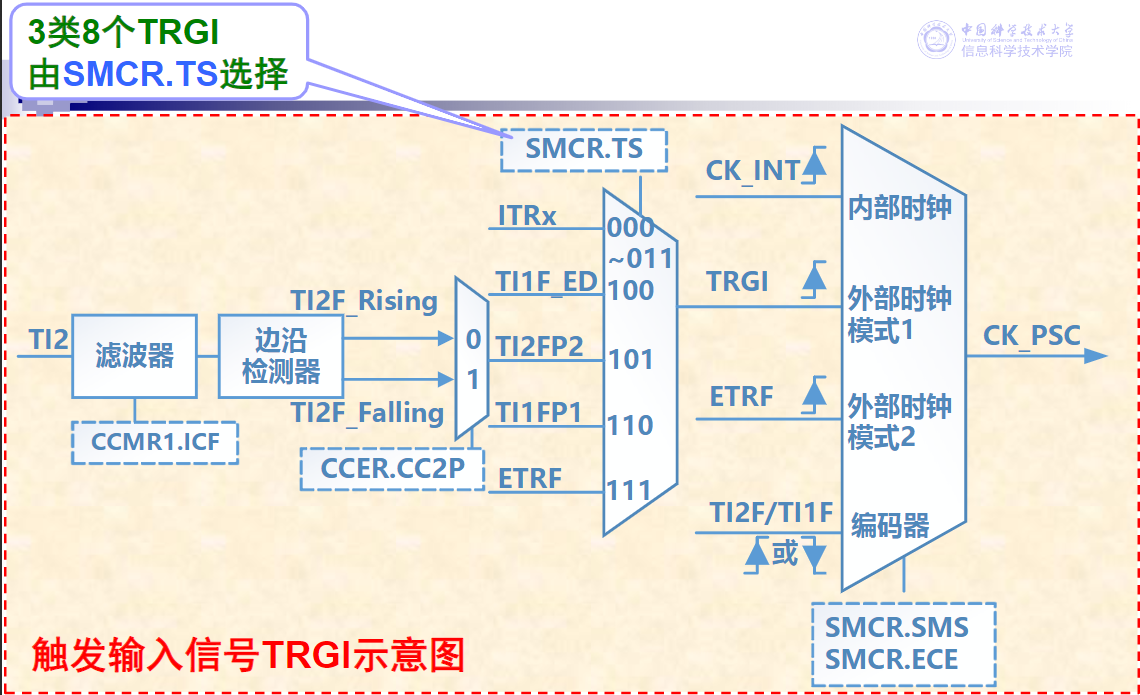
8.6.5.3. 从模式下的工作模式
从模式控制器检测到触发输入信号时,有多种控制方式(以控制或影响TIM工作),形成相应工作模式,如下:
- 复位模式(ResetMode):对计数器复位
- 触发模式(TriggerMode):使能计数器的工作
- 门控模式(GateMode):启动或停止计数器的计数动作
- 外部时钟模式1(ExternalClockMode1):利用触发信号为计数器提供时钟源
- 编码器模式(EncodeMode)
8.6.5.4. 定时器级联及同步
使用一个定时器作为另一个定时器的预分频器
配置定时器1作为定时器2的预分频器,TIM2由TIM1周期性的上升沿(即TIM1的计数器溢出)信号驱动
xxxxxxxxxxTIM1_CR2. MMS=010; //TIM1为主模式;设定UEV作为触发输出,每产生//一个UEV时(即每次计数器溢出),在TRGO1上输出一个周期性上升触发信号TIM2_SMCR.TS=000; //主从模式对应主TIM2,从TIM1;//ITR0作为内部触发,TIM2从TIM1获得触发输入TIM2_SMCR.SMS=111; //TIM2使用外部时钟源模式1配置TIM1的ARR;//定时周期TIM1_CR1.CEN=1;TIM2_CR1.CEN=1; //使能TIM1、TIM2使用一个外部触发同步地启动2个定时器
定时器1的TI1输入上升时使能定时器1,使能定时器1的同时使能定时器2
xxxxxxxxxxTIM1_CR2. MMS=001; //TIM1为主模式;设定它的使能作为触发输出TIM1_SMCR.TS=100; //TIM1为从模式,从TI1获得输入触发TIM1_SMCR.SMS=110; //TIM1为触发模式TIM1_SMCR.MSM=1; //TIM1为主/从模式;对TI1为从,对TIM2为主TIM2_SMCR.TS=000; //TIM2从TIM1获得输入触发TIM2_SMCR.SMS=110; //TIM2为触发模式TIM1_CR1.CEN=1; //使能TIM1当TIM1的TI1上出现一个上升沿时,TIM1和TIM2同步地按照内部时钟开始计数两个TIF标志也同时被设置。为保证计数器对齐,TIM1须配置为主/从模式(既是主也是从)
8.6.6. 相关库函数及寄存器
8.6.6.1. 库函数
存放于stm32f10x_tim.h和stm32f10x_tim. c文件中
常用库函数
TIM_TimeBaseInit:根据TIM_TimeBaseInitStruct初始化TIMxTIM_ARRPreloadConfig:使能或禁止ARR上的预装载寄存器TIM_Cmd:使能或禁止TIMxTIM_ITConfig:使能或禁止指定TIMx中断TIM_GenerateEvent:设置TIM事件由软件产生TIM_GetITStatus:检查指定TIMx中断是否发生TIM_ETRClockMode1Config:配置TIM外部时钟源模式1TIM_CounterModeConfig:设置TIM计数器模式TIM_SelectInputTrigger:选择TIM输入触发源TIM_CCxCmd:使能或禁止TIM捕获/比较通道xTIM_SelectSlaveMode:选择TIM从模式
初始化结构体
基本初始化结构体TIM_TimeBaseInitTypeDef
xxxxxxxxxxtypedefstruct{ uint16_t TIM_Prescaler; //预分频:0~0xFFFF uint16_t TIM_CounterMode; //计数模式:Up/Down向上/向下CenterAligned1/2/3中央1/2/3 uint16_t TIM_Period; //ARR值:0~0xFFFF uint16_t TIM_ClockDivision; //采样分频系数:DIV1/2/4 uint8_t TIM_RepetitionCounter;//重复定时器值(计数周期数)}TIM_TimeBaseInitTypeDef; //TIM初始化各参数定义输入捕获初始化结构体TIM_ICInitTypeDef
xxxxxxxxxxtypedefstruct{ uint16_t TIM_Channel; //通道,共4个,1~4:通道1~4 uint16_t TIM_ICPolarity; //边沿触发:Rising上升沿,Falling下降沿 uint16_t TIM_ICSelection; //输入:TRC,与TRC相连;DirectTI,TI1/2/3/4与IC1/2/3/4相连; //IndirectTI,TI1/2/3/4与IC2/1/4/3相连 uint16_t TIM_ICPrescaler; //输入预分频,每N(1/2/4/8)个事件执行一次捕获:DIV1/2/4/8 uint16_t TIM_ICFilter; //滤波器:0x0~0x0F}TIM_ICInitTypeDef;比较输出初始化结构体TIM_OCInitTypeDef
xxxxxxxxxxtypedefstruct{ uint16_t TIM_OCMode;//输出模式 uint16_t TIM_OutputState; //输出使能 uint16_t TIM_OutputNState;//互补输出使能 uint16_t TIM_Pulse;//占空比:0x0000~0xFFFF uint16_t TIM_OCPolarity;//输出极性,High:高,Low:低 uint16_t TIM_OCNPolarity;//互补输出极性 uint16_t TIM_OCIdleState;//空闲状态输出电平 uint16_t TIM_OCNIdleState;//空闲状态互补输出电平}TIM_OCInitTypeDef;典型库函数

8.6.6.2. 常用寄存器
- 高级计数器具有全部20个寄存器;通用计数器有19个(无BDTR);基本定时器有CR1、CR2、DIER、SR、EGR、CNT、PSC、ARR共8个寄存器
- 控制寄存器有:CR1~2、SMCR、SR、EGR、DIER、CCMR1~2、CCER等
- 常用寄存器有:ARR、CNT、PSC、CCR1~4等
- CR1(最重要及常用),主要控制位有:使能计数器CEN、使能ARR缓冲区ARPE、允许或禁止产生更新事件UDIS、设置分频系数CKD、设置计数方向DIR、选择能产生中断或DMA请求的UEV源URS、选择边沿或中央对齐模式CMS、选择单脉冲模式OPM等8种功能
- CR2,选择在主模式下送到从模式定时器的同步信息(TRGO)的8种方式
- SMCR,各位用于:计数器同步时触发输入选择TS、选择从模式下工作模式SMS、启用外部时钟源模式2ECE、主从模式MSM
- SR,各位保存:捕获/比较匹配/更新/中止/触发器/COM等事件发生标记(CCxIF/UIF/BIF/TIF/COMIF)及重复捕获发生标记(CCxOF);标记均由硬件置1(可由软件清零,即写0清除);同时会发起中断请求
- EGR ,各位用于产生各种事件:更新UG /触发TG/捕获及比较CCxG/中止BG/捕获及比较使能更新COMG等事件;均由软件置1,以产生相应事件,由硬件自动清零
- DIER,各位用于使能:更新/触发/捕获比较/COM的DMA请求(UDE/TDE/CCxDE/COMDE)及中断请求(UIE/TIE/CCxIE/COMIE)
- CCMR1~2,各位用于设置:通道CC1~4的输入捕获和比较输出工作模式:定义通道方向(选择输入或输出)CCxS、选择各种输出模式OCxM、比较输出预装载使能OCxPE、比较输出清零使能OC2CE、比较输出快速使能OCxFE、输入捕获滤波器ICxF、输入捕获预分频器ICxPSC
- CCER,各位用于设置输入/捕获通道n(1~3/4)的:互补输出极性CCnNP、互补输出使能CCnNE、输出极性CCnP、输出使能CCnE
8.6.7. 小结及应用要点
8.6.7.1. 定时器配置要点
频率设置
- 定时器本质是计数器,即对一定周期/频率脉冲进行计数(向上/向下/双向),到设定值则溢出,输出设定信号
- 频率设置重点有二:计数用的脉冲频率(周期)和计数值
- 即,设置:PSC(预分频值),对定时器所用时钟进行分频;ARR(自动重装溢出值),设置计数目标
- 此前,还需用
TIMIntemalClockConfig等函数选择时钟
时钟来源
4类共8个触发源,可作为定时器时钟源
- 1个,来自RCC内部时钟TIMx_CLK,产生内部时钟CK_INT,即:内部时钟源
- 共4个,来自片内其他定时器的触发输入ITR1~ITR4,使用一个定时器作为另一定时器的分频输入(TIMx之间有确定的主从关系);即:内部触发输入(ITRx)时钟源
- 共2个,来自捕获引脚上的边沿信号:CH1的TI1FP1/TI1F_ED和CH2的TI2FP2;即:外部输入脚(TIx)时钟源(也称外部时钟源模式1)
- 1个,来自引脚ETR;即:外部触发输入(ETR)时钟源(也称外部时钟源模式2)
计数器模式
- 向上:从0计数到ARR,然后重新从0开始计数
- 向下:从ARR计数到0,然后重新从ARR开始计数
- 双向:二者结合(先向上再向下)
- 计数转折时,均会产生一个计数器溢出事件
编程步骤
- 配置系统时钟
- 配置NVIC
- 配置GPIO
- 配置TIM

8.6.7.2. PWM程序实现步骤
实质上,PWM就是定时器的一个比较功能,利用翻转输出,形成一个具有一定脉冲宽度的高/低电平周期波
PWM频率取决于ARR,占空比取决于CCR
配置输出通道
选择使用某个/某几个通道作为PWM输出通道,其对应引脚(其实就是GPIO)须进行时钟和引脚输出方式配置
一般为复用推挽输出AF_PP
应用中,可选不同引脚(即,改变GPIO与输出通道默认映射关系),此时须使用重定向功能Remap,即:
- 引脚配置时,打开AFIO时钟(复用时钟使能),调用Remap函数进行引脚重定向
配置定时器
- 计算并设置ARR、PSC、CCR值,以确定频率及占空比
- 选择时钟源、配置其余参数,与前述类似
- 配置PWM相关寄存器,设置某一通道CHx为PWM模式,并使能其输出
配置PWM模式(即输出特性)
配置TIM3_CCMR1相关位来控制TIM3_CH3模式,利用TIM_OC3Init实现,其原型:
xxxxxxxxxxvoid TIM_OC3Init(TIM_TypeDef* TIMx,TIM_OCInitTypeDef* TIM_OCInitStruct)xxxxxxxxxxTIM_OCStructInit(&TIM_OCInitStructure); //设置默认值TIM_OCInitStructure.TIM_OCMode=TIM_OCMode_PWM1; // PWM模式1输出TIM_OCInitStructure.TIM_Pulse=400-1; //占空比=(CCR/(ARR+1))或Pulse/(Period+1)TIM_OCInitStructure.TIM_OCPolarity=TIM_OCPolarity_High; //输出极性:高TIM_OCInitStructure.TIM_OutputState=TIM_OutputState_Enable; //输出状态使能TIM_OC3Init(TIM3,&TIM_OCInitStructure); //TIM3的CH3输出TIM_CtrIPWMOutputs(TIM3,ENABLE); //TIM3的PWM输出为使能
8.6.7.3. PWM程序实现的3个要点
PWM两种输出模式
模式1(PWM1)和模式2(PWM2),由CCMR.OCxM值确定(110 为模式1,111为模式2);模式1和2正好互补,互为相反,运用差别不大
动态调整占空比
修改CCR可控制输出占空比,库函数TIM_SetComparex用于修改占空比(x为1~4,代表相应通道),其原型为:
xxxxxxxxxxvoid TIM_SetComparex(TIM_TypeDef* TIMx,uint16_t Compare2)PWM输出基本步骤
- 设置RCC时钟
- 设置GPIO
- 设置TIMx相关寄存器
- 设置TIMx的PWM相关寄存器
- 动态调整PWM占空比
8.7. 中断控制器
8.7.1. 中断系统综述
8.7.1.1. 嵌套向量中断控制器NVIC
- NVIC集成于内核中,控制并统一管理整个芯片(向量)中断
- 核心功能:中断优先级分组及配置、读及清除中断请求标志、使能/禁止中断等
8.7.1.2. 中断优先级
决定一个中断是否能被屏蔽及何时可响应(未屏蔽时)
优先级分组
- 抢占优先级,又称主/组/占先优先级,标识某中断抢占式优先响应能力高低,决定是否发生中断嵌套。具有高抢占先优先级中断会打断当前正执行的中断服务程序
- 子优先级,又称从优先级,仅在抢占优先级相同时才有影响,标识某中断非抢占式优先响应能力高低。在抢占优先级相同时,高子优先级中断须等待而不能打断正执行的低子优先级中断;若没有中断正被处理,高子优先级中断将优先被响应
优先级实现
- 每个中断源有4位优先级,具有16级可编程异常优先级
- 可按需编程设定4位优先级中抢占优先级位数
中断响应顺序
- 先比较抢占优先级,抢占优先级高的中断优先响应
- 抢占优先级相同时,比较子优先级,子优先级高的中断优先响应
- 抢占优先级和子优先级都相同时,比较中断向量表中位置,位置低的中断优先响应
8.7.1.3. 中断向量表
- 统一存放各中断对应的中断服务程序ISR入口地址,一般默认位于存储器开头(0地址处),运行过程中无须修改
- 标准的异常和中断向量表可参阅
startup_stm32f10x_hd.s,已标明中断处理函数名称,不能随意定义 - NVIC支持68个可屏蔽中断通道
NVIC_IRQChannel(即类型)在stm32f10x.h中进行了宏定义,通道常以中断号表示,优先级可设置(个别除外) - 优先级7~66(中断号0~59)代表60个中断,号越小,优先级越高
- 中断被触发,将通过其在表中对应地址处所存放的一条跳转指令,跳转至相应中断服务函数处执行
8.7.1.4. 中断服务函数ISR

- 一般无参数及返回值,中断发生时被自动隐式调用执行
- 每个中断都有对应ISR,中断发生后执行相应处理
- 所有ISR在启动代码中预定义,常以XXX_IRQHandler命名(XXX是中断对应外设名,如TIM1、USART1等)。应用时,可添加/修改相关中断ISR(stm32f10x_it.c中),链接时替代启动代码中同名默认程序(不能随意定义函数名称)
- ISR均预置弱定义(WEAK)属性(除复位程序外),便于其他文件中编写同名函数替代(启动代码中默认ISR)
- ISR中首尾无须保护和恢复现场(寄存器),此工作由硬件(在中断处理过程中)自动完成
8.7.1.5. 中断设置过程

建立中断向量表
- 可按需,在Flash或RAM中建立中断向量表,且须在应用程序执行前完成(通常在启动过程中完成)
- 在Flash中;不须重定位中断向量表;运行过程中,每个中断对应固定的ISR不能更改;这也是默认设置
- 在RAM中;需重定位中断向量表;运行过程中,可动态改变ISR
分配栈空间并初始化
- 执行ISR时,进入Handler模式,会使用主堆栈的栈顶指针MSP;此步须在应用程序执行前完成(通常启动过程中完成)
- 分配栈空间:栈空间通常位于启动代码起始位置;空间须够大,以保证中断响应/返回时保护和恢复现场(xPSR、PC、LR、R12、R3~R0共8个),避免中断发生/嵌套时主堆栈溢出
- 初始化栈:通常在上电复位后执行复位服务程序时完成
设置中断优先级
设置中断优先级分组(的位数)
4位中,抢占优先级和子优先级各占几位(二者和为4),可有5种方式:抢占优先级0~4位/子优先级4~0位
NVIC_PriorityGroup_0~4设置抢占优先级和子优先级,根据上一步中分组情况,分别设置抢占和子优先级(即在各自取值范围中设置优先级确定值)
使能中断
通过失效中断总屏蔽位和分屏蔽位,可使能对应中断
编写对应ISR代码
ISR最后,退出程序前应清除对应中断标志位(表示该中断已处理完毕),否则,该中断请求始终存在,该ISR将被反复执行
8.7.2. 外部中断/事件控制器EXTI
8.7.2.1. 内部结构
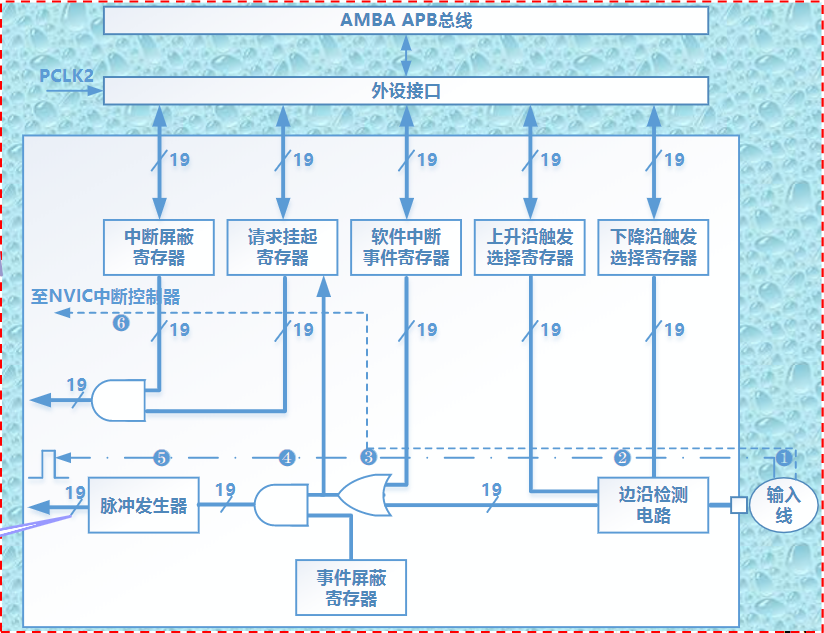
组成:
- 19根外部输入线
- 19个产生中断/事件请求的边沿检测器
- APB外设接口
外部中断/事件输入线
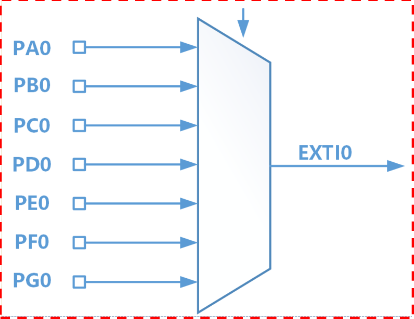
- 19根(EXTI0~EXTI18);除EXTI16(PVD输出)、EXTI17(RTC闹钟)和EXTI18(USB唤醒)外,EXTI0~15(其他16根)可分别对应16个引脚Px0~Px15(x为A~G)
- EXTI0~15连接/映射方式如下:任一端口0号引脚(如PA0、PB0、...、PG0)映射到EXTI0上,任一端口1号引脚(如PA1、...、PG1)映射到EXTI1上...,任一端口15号引脚(如PA15、...、PG15)映射到EXTI15上
- 同一时刻,只能有一个端口(即A~G中仅选一个)的n号引脚映射到EXTIn上(n为0~15)
APB外设接口
通过此接口访问各功能模块。若使用引脚的外部中断/事件映射功能,须打开APB2总线上该引脚对应端口时钟及AFIO功能时钟
边沿检测器
共19个,用来连接19个外部中断/事件输入线,是EXTI主体部分。由边沿检测电路、控制寄存器、门电路和脉冲发生器组成
8.7.2.2. 工作原理
外部中断/事件请求的产生和传输
从输入(外部输入线)到输出(外部中断/事件请求信号),过程依次
- 外部信号从①引脚进入
- 经过②边沿检测电路;此电路受上升沿/下降沿触发选择寄存器(两个平行寄存器)控制,可配置选择上升沿/下降沿/双边沿(同时选择上升沿和下降沿)产生中断/事件
- 经过③或门;此或门另一输入是软件中断/事件寄存器,软件可优先于外部信号产生一个中断或事件请求(即当软件中断/事件寄存器对应位为1时,不管外部信号如何,或门都会输出有效信号);至此,无论中断或事件,外部请求信号传输路径一致
- 外部请求信号进入④与门;此与门另一输入是事件屏蔽寄存器(其对应位为0,则屏蔽某外部事件,该外部请求信号不能传输到与门另一端;为1,则与门产生有效输出并送至⑤脉冲发生器);脉冲发生器把一个跳变信号转变为一个单脉冲,输出到其他功能模块;此为外部事件请求信号传输路径,即:①→②→③→④→⑤
- 外部请求信号进入请求挂起寄存器(记录外部信号电平变化);然后进入⑥与门;此与门功能和④与门类似,引入中断屏蔽寄存器控制(仅当其对应位为1时,该外部请求信号才被送至NVIC,从而发出一个中断请求,否则,屏蔽之);此为外部中断请求信号传输路径,即:①→②→③→⑥
事件与中断
从外部激励信号看,中断和事件的请求信号没有区别,只是在STM32F103内部将它们分开:
- 中断:会被送至NVIC,向CPU产生中断请求,其后由应用程序/ISR决定如何响应,须CPU介入,属于软件级
- 事件:会向其他功能模块(如TIM/USART/DMA等)发送脉冲触发信号(电路级别),其后由此模块决定如何响应(如触发DMA、ADC采样等),无须CPU干预,一般无对应服务函数,属于硬件级
主要特性
- 每个EXTI线都可独立配置其触发事件(上升沿/下降沿/双边沿),并能单独被屏蔽
- 每个外部中断都有专用标志位(请求挂起寄存器),保持其中断请求
- 可将112个GPIO引脚映射为16个EXTI线
8.7.3. 相关库函数及寄存器
8.7.3.1. 库函数
常用NVIC库函数
存放于标准外设库的misc.h和misc.c文件中
NVIC_PriorityGroupConfig设置优先级分组NVIC_Init根据NVIC_InitStruct中指定参数初始化NVICNVIC_DeInit将NVIC寄存器恢复为复位启动时默认值
常用EXTI库函数
存放于stm32f10x_exti.h和stm32f10x_exti.c文件中
EXTI_DeInit将EXTI寄存器恢复为复位启动时默认值EXTI_Init根据EXTI_InitStruct中指定参数初始化EXTIEXTI_GetFlagStatus检查指定外部中断/事件线标志位EXTI_ClearFlag清除指定外部中断/事件线标志位EXTI_GetITStatus检查指定EXTI线触发请求发生与否EXTI_ClearITPendingBit清除指定EXTI线中断挂起位
使用EXTI前,需先使用GPIO库函数
GPIO_EXTILineConfig,将指定GPIO引脚设置为EXTI线
初始化结构体
NVIC初始化结构体NVIC_InitTypeDef
xxxxxxxxxxtypedef struct{ uint8_t NVIC_IRQChannel; //中断通道 uint8_t NVIC_IRQChannelPreemptionPriority; //抢占/主优先级 uint8_t NVIC_IRQChannelSubPriority; //子/从优先级 FunctionalState NVIC_IRQChannelCmd;}NVIC_InitTypeDef;AFIO结构体AFIO_TypeDef
xxxxxxxxxxtypedef struct{ vu32 EVCR; vu32 MAPR; vu32 EXTICR[4];//IO复用里的外部中断配置寄存器EXTICR} AFIO_TypeDef;EXTI初始化结构体EXTI_InitTypeDef
xxxxxxxxxxtypedefstruct { uint32_t EXTI_Line;//中断/事件线,可选EXTI0~EXTI19 EXTIMode_TypeDef EXTI_Mode;//模式选择,产生Interrupt中断或Event事件 EXTITrigger_TypeDef EXTI_Trigger;//触发方式,Rising上升沿/Falling下降沿/Rising_Falling双向 FunctionalState EXTI_LineCmd;//EXTI 使能,使能ENABLE,禁用DISABLE} EXTI_InitTypeDef;EXTI控制寄存器定义结构体EXTI_TypeDef
xxxxxxxxxxtypedefstruct{ vu32 IMR; //中断屏蔽,偏移量0x00 vu32 EMR; //事件屏蔽,偏移量0x04 vu32 RTSR; //上升沿触发选择,偏移量0x08 vu32 FTSR; //下降沿触发选择,偏移量0x0C vu32 SWIER; //软件中断事件,偏移量0x10 vu32 PR; //挂起,偏移量0x14}EXTI_TypeDef;典型库函数

8.7.3.2. 常用寄存器
EXTI的,所有(共6个)32位寄存器中,位[31:19]保留,位[18:0]需定义,如下(x为0~18,对应19个外部中断)
- IMR中断屏蔽寄存器,位[18:0]:MRx,线x上的中断屏蔽;0:屏蔽;1开放;开启相应线上事件触发
- EMR事件屏蔽寄存器,位[18:0]:MRx,线x上的事件屏蔽;0:屏蔽;1开放;开启相应线上中断
- RTSR上升沿触发选择寄存器,位[18:0]:TRx,线x上的上升沿触发配置(中断和事件);0:禁止;1:允许;用于允许相应线上上升沿触发中断/事件
- FTSR下降沿触发选择寄存器,类似RTSR,下降沿触发;若下降/上升沿同时设置,则为任意边沿触发
- SWIER软件中断事件寄存器,位[18:0]:SWIERx,线x上的软件中断;为0时,写1将设置PR中相应挂起位(若IMR和EMR允许产生该中断,则此时将产生一个中断);通过清除PR对应位(写1),可清除该位为0;用于产生一个软件中断,效果等同于外部中断触发
- PR挂起寄存器,位[18:0]:PRx,挂起位;0:未发生触发请求;1:发生所选触发请求;当外部中断线上发生了所选定边沿事件,该位被置1;向该位写1可清除其(为0)。也可通过改变边沿检测极性清除。可用于查询中断
NVIC,共有7种控制寄存器组,除IPR/IR外,其余6种/组,每组共60个有效位,每位分别对应60个可编程可屏蔽中断
- ISER中断使能寄存器组,两个字,共63位,用了60位,一个位对应一个中断,写1中断有效,写0无意义
- ICER中断除能寄存器组,两个字,用了60位,类似;和使能寄存器功能相反,写1中断失效,写0无意义
- ISPR中断挂起控制寄存器组,两个字,类似;写1有效,可将正在运行的中断挂起,从而执行同级别或更高级别的中断;写0 无意义
- ICPR中断解挂寄存器组,两个字,类似;和挂起寄存组功能相反;写1有效,写0无意义
- IABR中断激活标志位寄存器组,两个字,类似;只读,通过读取,可知哪个中断正在被执行(对应的位被置1);中断执行完后对应位清零
- IPR/IR中断优先级寄存器,15个字,共60个字节,每字节对应一个中断,高4位有效(低4位保留),又分为抢占优先级(在前)和子优先级(在后),各占几位需根据SCB(System Control Block Structure)中应用程序中断及复位控制寄存器AIRCR(Application Interrupt and Reset Register)的中断分组设置决定;AIRCR的PRIGROUP[10:8]用于指定优先级(即分配preemption和sub优先级,共分5组,取值及含义如前述)
- STIR软件触发寄存器,两个字;用于软件触发(置1)
AFIO_EXTICR1~4外部中断配置寄存器1~4
为将I/O口设置为外部中断入口以作为中断源,须利用GPIO复用功能,将I/O口映射到相应外部事件,即:
EXTICRx(x=1~4),可由软件读写,选择外部中断的输入源;其映射规则如下:
- 4个32位EXTICRx,每个仅用低16位,每4位分成1组,4个寄存器共16组,依次从低到高,对应16个I/O口(0~15),每组的4位数取值从0~6,对应A~G
8.7.4. 小结及应用要点
中断、异常、外部中断及EXTI
- 中断指,系统停止当前正在运行的程序转到其他服务,可能是接收了(比自身优先级高的)请求,或人为设置引起
- 异常指,所有能打断正常执行的事件,但常指由于CPU本身故障、程序故障或请求服务等引起的错误。异常包含中断(即中断是异常的子集),异常与中断都有硬件支持
- STM32F103异常系统,含16个系统异常(也称,内核中断/异常,编号0~15,优先级为-3到6)和60个“外部中断”(M3内核的定义,编号16以上,此时,不是指EXTI中断,而是所有中断)
- 外部中断EXTI,概念要小得多,特指,EXTI中断。NVIC支持19个EXTI中断/事件请求(即19条外部中断线),线0~15:对应外部I/O口输入中断;线16~18:特定中断。每个PAx~PGx均可被配置为外部中断源输入
- STMF10x架构里,常把非EXTI的其他中断(如外设TIM/USART/DMA/ADC等产生的中断)称为内部中断,以示区分
EXTI中断向量及中断服务函数
- EXTI外部IO输入中断源在中断向量表中只分配7个中断向量(即只能使用7个中断服务函数)
- 外部中断线5~9分配一个中断向量,共用一个服务函数;外部中断线10~15分配一个中断向量,共用一个中断服务函数;外部中断线0~4则各自单独使用一个中断服务函数

相应中断服务函数名称(在启动文件startup_stm32f10x_hd.s中):EXTI0_IRQHandler;EXTI1_IRQHandler;EXTI2_IRQHandler;EXTI3_IRQHandler;EXTI4_IRQHandler;EXTI9_5_IRQHandler;EXTI15_10_IRQHandler
配置及应用外部中断步骤要点
- 初始化I/O口为复用AFIO输入
GPIO_Init - 开启I/O口复用时钟
RCC_APB2PeriphClockCmd - 设置I/O口与中断线映射关系
GPIO_EXTILineConfig - 初始化线上终端,设置触发条件
EXTI_Init - 配置中断分组
NVIC_PriorityGroup,使能中断NVIC_Init - 编写中断服务函数
EXTIx_IRQHandler - 清除中断标志位
EXTI_ClearITPendingBit
EXTI及NVIC的初始化
xxxxxxxxxxvoid EXTI_Config (void){ EXTI_InitTypeDef EXTI_InitStructure; RCC_APB2PeriphClockCmd (RCC_APB2Periph_AFIO, ENABLE) ; GPIO_EXTILineConfig(GPIO_PortSourceGPIOC, GPIO_PinSource5); EXTI_InitStructure.EXTI_Line= EXTI_Line5; EXTI_InitStructure.EXTI_Mode= EXTI_Mode_Interrupt; EXTI_InitStructure.EXTI_Trigger=EXTI_Trigger_Falling; EXTI_InitStructure.EXTI_LineCmd= ENABLE; EXTI_Init(&EXTI_InitStructure);}xxxxxxxxxxvoid NVIC_Config (void){ NVIC_InitTypeDef NVIC_InitStructure; NVIC_PriorityGroupConfig (NVIC_PriorityGroup_1) ; NVIC_InitStructure.NVIC_IRQChannel= EXTI9_5_IRQn; NVIC_InitStructure.NVIC_IRQChannelPreemptionPriority= 0; NVIC_InitStructure.NVIC_IRQChannelSubPriority= 1; NVIC_InitStructure.NVIC_IRQChannelCmd= ENABLE; NVIC_Init( &NVIC_InitStructure) ;}中断服务程序
xxxxxxxxxxvoid EXTI9_5_IRQHandler(void){ unsigned char temp=LED0_IsOn () ; if (EXTI_GetITStatus (EXTI_Line5) ! = RESET) { if (temp) LED0_Off (); else LED0_On(); EXTI_ClearITPendingBit (EXTI_Line5) ; }}8.8. USART
8.8.1. 主要特性
- USART1位于APB2上,其他USART和UART位于APB1上
- 全功能可编程串行接口特性:数据位(8/9位);校验位(奇/偶/无);停止位(1/2位);支持硬件流控制(CTS和RTS)
- 可编程波特率发生器(整数12位,小数4位),最高速率4.5Mbps
- 两个独立带中断标志位:发送TXE(发送数据寄存器空)和接收RXNE(接收数据寄存器非空)
- 支持DMA传输:发送/接收DMA请求
- 单线半双工通信;多处理器通信
- LIN主发送同步断开符及从检测断开符能力(配置成LIN时,生成13位断开符、检测10/11位断开符)
- 智能卡模拟功能:支持异步智能卡协议
8.8.2. 内部结构
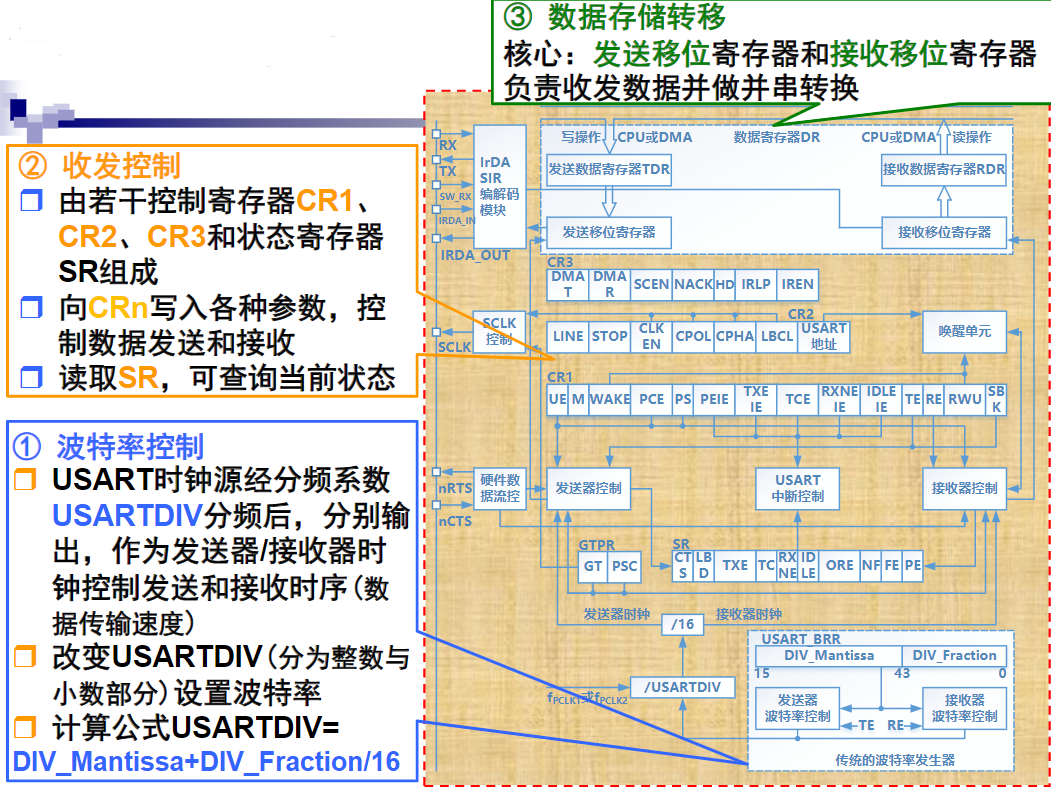
相关引脚简介
- TX,发送数据输出引脚
- RX,接收数据输入引脚
- SW_RX,数据接收引脚,只用于单线和智能卡模式,属于内部引脚,没有具体外部引脚
- nRTS,请求以发送(Request To Send),n表示低电平有效。如果使能RTS流控制,当USART 接收器准备好接收新数据时就会将nRTS 变成低电平;当接收寄存器已满时,nRTS 将被设置为高电平。该引脚只适用于硬件流控制
- nCTS,清除以发送(Clear To Send),n表示低电平有效。如果使能CTS 流控制,发送器在发送下一帧数据之前会检测nCTS 引脚,如果为低电平,表示可以发送数据;如果为高电平,则在发送完当前数据帧之后停止发送。该引脚只适用于硬件流控制
- IRDA_OUT,输出引脚,用于发送红外数据
- IRDA_IN,输入引脚,用于接收红外数据
- SCLK,发送器时钟输出引脚,仅适用于同步模式
数据发送过程
- 内核指令或DMA外设先将数据从内存(变量)写入发送数据寄存器TDR
- 发送控制器适时地自动把数据从TDR加载到发送移位寄存器,将数据一位一位地通过Tx引脚发送出去
- 当数据完成从TDR到发送移位寄存器的转移后,会产生TDR已空事件TXE
- 当数据从发送移位寄存器全部发送到Tx后,会产生数据发送完成事件TC;可在SR中查询这些事件
数据发送,须设置相关寄存器各位,过程如下:
- CR1.UE置位1,激活USART
- CR1.M定义字长
- CR2.STOP定义停止位位数
- 若采用多缓冲器通信,配置CR3.DMAT使能DMA
- 利用BRR选择波特率
- 置位CR1.TE,发送一个空闲帧作为第一次数据发送
- 将要发送数据写入DR(此动作会清除SR.TXE);一个缓冲区情况下,重复7
数据接收过程
- 数据从Rx引脚一位一位地输入到接收移位寄存器中
- 接收控制器自动将接收移位寄存器的数据转移到接收数据寄存器RDR中
- 内核指令或DMA将RDR数据读入内存(变量)中。接收移位寄存器数据转移到RDR后,会产生RDR非空/已满事件RXNE
配置过程:
- CR1.UE置位1,激活USART
- CR1.M定义字长
- CR2.STOP定义停止位位数
- 若采用多缓冲器通信,配置CR3.DMAT使能DMA
- 利用BRR选择波特率
- 置位CR1.RE,激活接收器,开始寻找起始位
- 接收到一个字符时,SR.RXNE被置位,并产生中断(已使能时,即CR1.RXNEIE=1);若检测到帧/溢出/噪声错误,相应标志会置位(供查询)
- SR.RXNE清零(多缓冲由DMA读SR/单缓冲由软件读SR/通过对其写0:完成),须在下一字符接收结束前完成,避免溢出错
8.8.3. USART中断
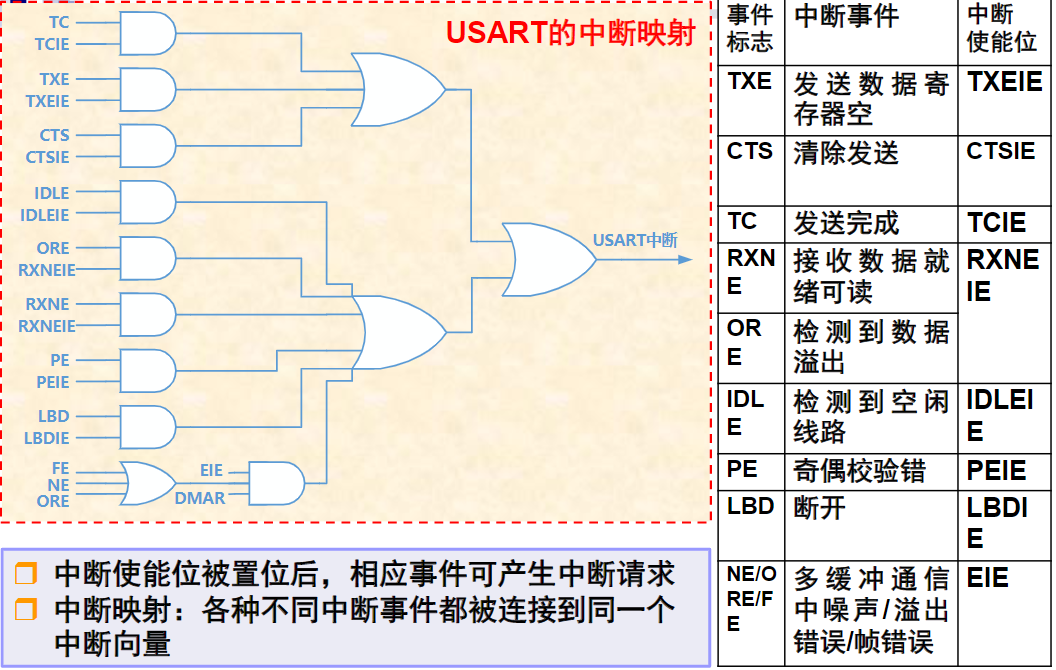
8.8.4. 相关库函数及寄存器
8.8.4.1. 库函数
常用库函数
存放于stm32f10x_usart.h和stm32f10x_usart.c文件中
USART_DeInit将USARTx寄存器恢复为复位启动时默认值USART_Init根据USART_InitStruct中指定参数初始化USART寄存器USART_StructInit把USART_InitStruct中的每个参数按默认值填入USART_Cmd使能或禁止指定USARTUSART_SendData通过USART发送单个数据USART_ReceiveData返回指定USART最近接收到数据USART_GetFlagStatus查询指定USART标志位状态USART_ClearFlag清除指定USART标志位USART_ITConfig使能或禁止指定USART中断USART_GetITStatus查询指定USART中断是否发生USART_ClearITPendingBit清除指定USART中断挂起位USART_DMACmd使能或禁止指定USART的DMA请求
初始化结构体
USART初始化结构体USART_InitTypeDef
xxxxxxxxxxtypedefstruct{ uint32_t USART_BaudRate; //波特率 uint16_t USART_WordLength;//传输字长=数据+检验位数:8b/9b uint16_t USART_StopBits;//停止位数:1、1_5、2、0_5 uint16_t USART_Parity; //校验:No无;Odd奇;Even偶 uint16_t USART_HardwareFlowControl;//硬件流控:None无;RTS请求发送;CTS清除发送;RTS_CTS发送和接收都用流控 uint16_t USART_Mode;//模式(可组合):Tx发送;Rx接收 uint16_t USART_Clock;//时钟使能:Enable高;Disable低 uint16_t USART_CPOL;//SLCK引脚时钟输出极性:High高;Low低 uint16_t USART_CPHA;//SLCK引脚时钟输出相位,配合CPOL产生时钟/数据采样关系:1Edge时钟第一个边沿数据捕获;2Edge第二个 uint16_t USART_LastBit;//同步模式下,SLCK输出最后一位数据对应时钟脉冲使能:Enable最后一位数据的时钟脉冲从SLCK输出;Disable不输出} USART_InitTypeDef;典型库函数

例:需设置参数为波特率,字长,停止位,奇偶校验位,硬件数据流控制,模式(收/发)
xxxxxxxxxxUSART_InitStructure.USART_BaudRate = bound;USART_InitStructure.USART_WordLength = USART_WordLength_8b;USART_InitStructure.USART_StopBits = USART_StopBits_1;USART_InitStructure.USART_Parity = USART_Parity_No; USART_InitStructure.USART_HardwareFlowControl= USART_HardwareFlowControl_None; USART_InitStructure.USART_Mode = USART_Mode_Rx | USART_Mode_Tx; USART_Init(USART1, &USART_InitStructure); //初始化串口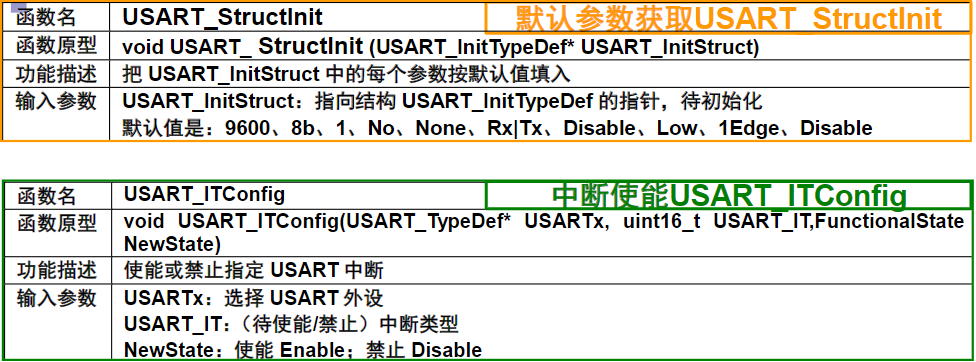
在接收到数据时(RXNE读数据寄存器非空),要产生中断,开启中断方法:
xxxxxxxxxxUSART_ITConfig(USART1, USART_IT_RXNE, ENABLE);在发送数据结束时(TC发送完成),要产生中断,开启中断方法:
xxxxxxxxxxUSART_ITConfig(USART1,USART_IT_TC, ENABLE);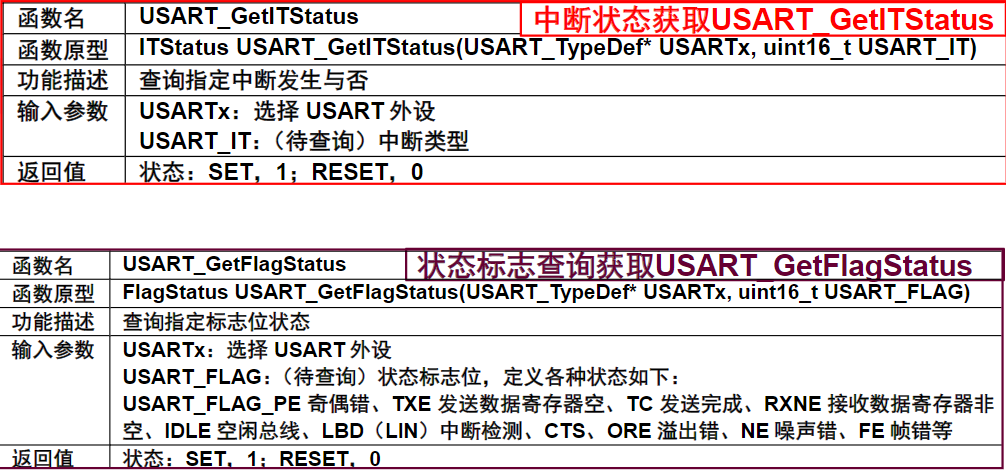
某中断发生时,会置位SR中某标志位,中断处理函数中,可调用此函数判断该中断是否发生。如,串口发送完成时,产生中断,对其判断:
xxxxxxxxxxUSART_GetITStatus(USART1, USART_IT_TC)若返回值是SET,说明中断发生判断读寄存器是否非空(RXNE):
xxxxxxxxxxUSART_GetFlagStatus(USART1, USART_FLAG_RXNE);判断发送是否完成(TC):
xxxxxxxxxxUSART_GetFlagStatus(USART1, USART_FLAG_TC);8.8.4.2. 常用寄存器
共7个:状态寄存器SR、数据寄存器DR、波特率寄存器BRR、控制寄存器CR1~3、保护时间和预分频寄存器GTPR
SR,标识USART各种状态,均由硬件置位,大都由软件序列(先读SR,再相关读写)清零,部分状态标志被置1同时会产生中断(已使能时)
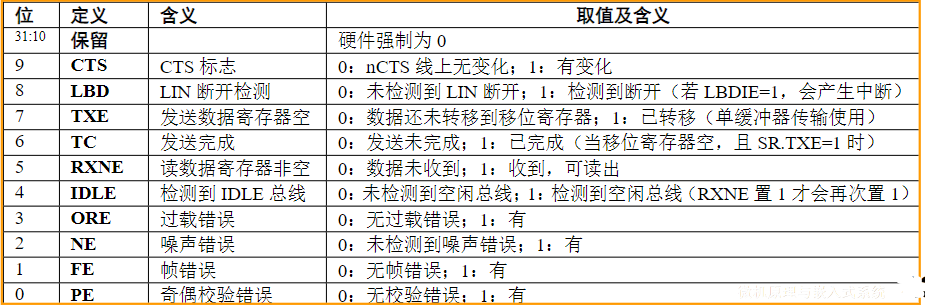
DR,包含发送或接收的数据,接收时称为RDR,发送时称为TDR(二者共用一片物理空间),提供内部总线和输入/输出移位寄存器间的并行接口,因此兼具读写功能。仅低9位[8:0]有效(其他位保留)。使能校验位(CR1.PCE=1)时:发送,写入MSB值(根据数据长度不同,MSB是第7位或第8位)被校验位取代;接收,读到的MSB值是校验位
BRR,装载分频器整数和小数部分;若TE或RE分别被禁止,波特计数器停止计数;其中,DIV_Fraction[3:0] 定义USARTDIV小数部分;DIV_Mantissa[15:4]为整数;其余位保留
CR1 ,多由软件置位/清零(除:RWU及SBK,硬件也可复位)
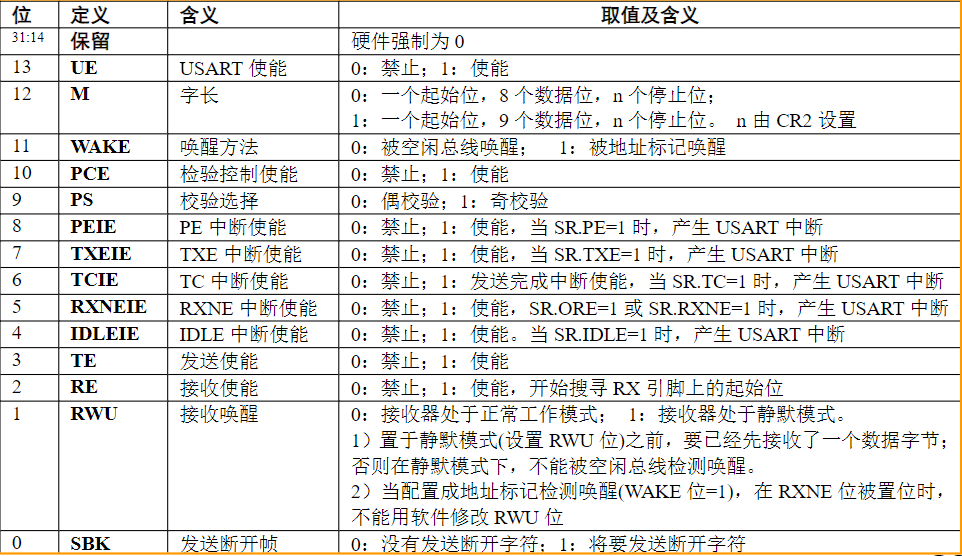
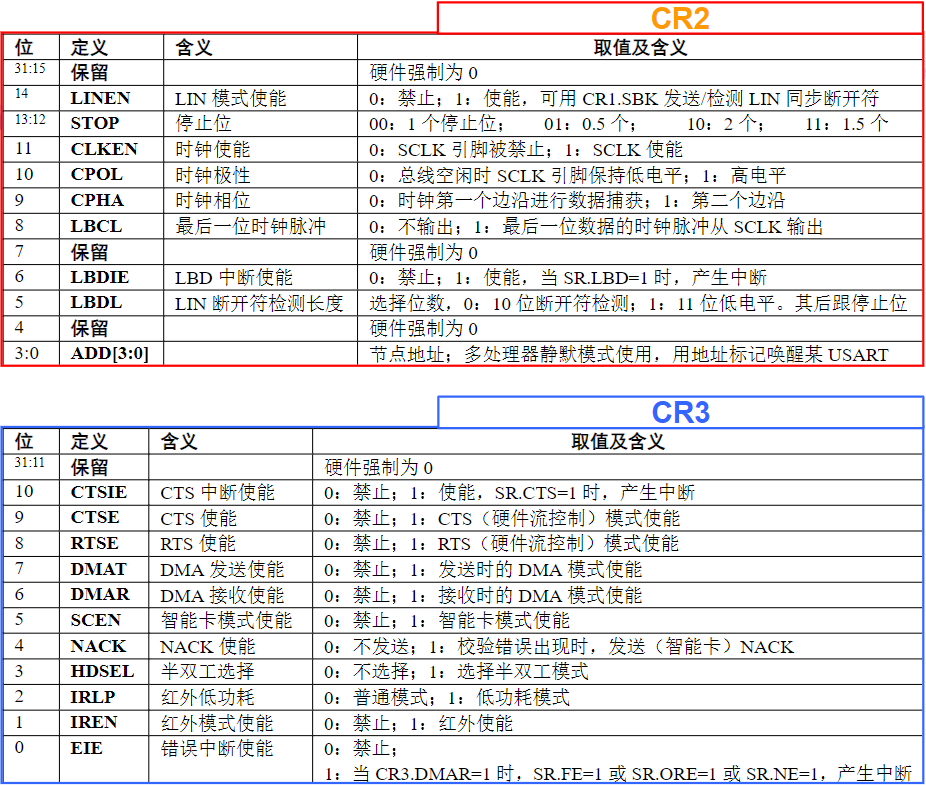
8.8.5. 小结及应用要点
8.8.5.1. 库函数开发STM32F103外设过程
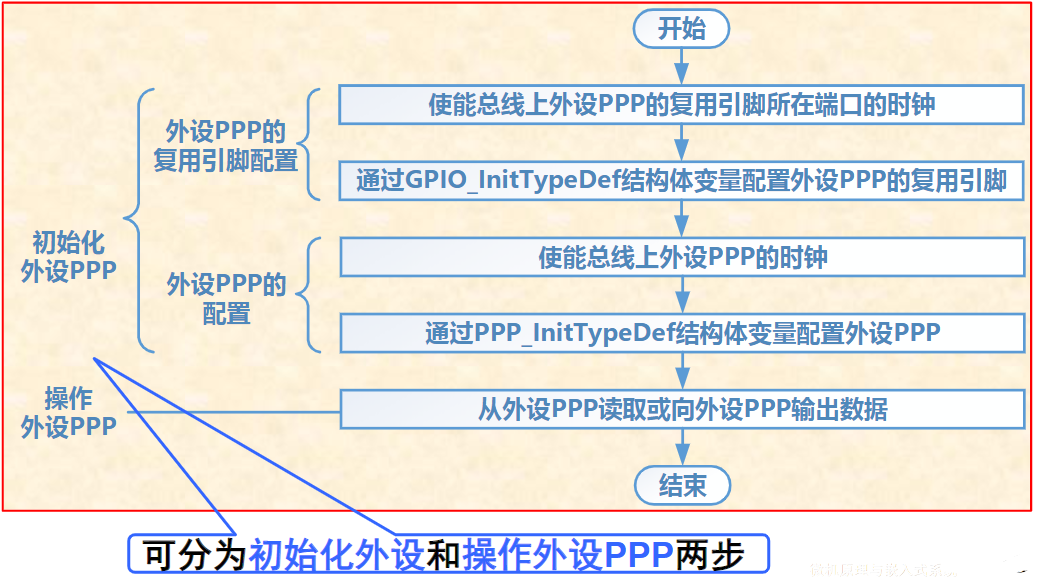
初始化外设PPP
- 常置于主函数main的无限循环体外,上电复位进入main时,执行一次
- 可分为配置PPP复用引脚和配置PPP两步;每步又可分为使能时钟(片上外设,均须先打开其时钟才能使用)和参数设置(通过设置对应结构体成员实现)两小步
- (以外设名开头的)各种结构体
PPP_InitTypeDef,用以配置各种不同外设(涵盖外设特牲和功能)
操作外设PPP
外设PPP输入/输出,常置于main的无限循环体或相应中断服务函数中;运行期间,条件满足时将反复执行
8.8.5.2. STM32F10x标准外设库函数的分类和命名
- 各种外设PPP(PPP可为GPIO、TIM、NVIC、EXTI、USART、SPI和I2C、DMA、ADC等)通常都包含以下函数,每个函数的输入参数,均包含
PPPx(意为指定的外设PPPx,是外设PPP的细分表示,PPP若是GPIO,PPPx可以是GPIOA、GPIOB、GPIOC等;PPP若是TIM,PPPx可以是TIM1、TIM2等) PPP_DeInit以系统默认参数初始化PPPx的寄存器PPP_Init根据PPP_InitTypeDef结构体变量中指定参数初始化PPPx的寄存器;输入参数:PPP_InitStruct,指向PPP_InitTypeDef结构体变量的指针,包含PPPx配置信息PPP_Cmd使能/禁止PPPx;输入参数:NewState,PPPx的新状态(ENABLE,使能PPPx;DISABLE,禁止)PPP_SendData通过PPPx发送数据(常见于USART、SPI和I2C等外设);输入参数:Data,待发送的数据PPP_ReceiveData返回PPPx最新收到数据(常见同上);返回值:PPPx最新收到数据PPP_GetFlagStatus查询PPPx的指定标志位;输入参数:PPP_FLAG,PPPx的指定(待查询)标志位;返回值:最新状态(SET或RESET,即1/0)PPP_ClearFlag清除PPPx的指定标志位;输入参数:PPP_FLAG,PPPx的指定(待清除)标志位PPP_ITConfig使能或禁止PPPx的指定中断;输入参数:PPP_IT,待使能或禁止的PPPx中断源;NewState,新状态(ENABLE,使能;DISABLE,禁止)
8.8.5.3. USART配置的一般步骤
- GPIO时钟及串口时钟使能
RCC_APB2PeriphClockCmd - 串口复位(非必须)
USART_DeInit - GPIO端口模式(Rx/Tx)设置
GPIO_Init;引脚复用映射(非必须)GPIO_PinAFConfig - 串口初始化
USART_Init - 开启中断并初始化NVIC(非必须)
NVIC_Init;USART_ITConfig - 使能串口
USART_Cmd - 编写中断处理函数(非必须)
USARTx_IRQHandler - 串口数据收/发
USART_ReceiveData;USART_SendData - 串口传输状态获取(并判断处理)
USART_GetFlagStatus;USART_ClearITPendingBit
8.8.5.4. 注意事项
- 中断处理函数中,一般先判断中断状态位,再进行后续处理
- 应用中串口可能设置不止一处中断(但每个中断进入的中断处理函数相同)可用
USART_GetITStatus读取状态位以区分 - 发送/接收数据后通常也需判断(通过读取状态标志实现)
- 串口传输时,通过软件读/写数据(即DR),会相应清零
SR.RXNE/SR.TXE/SR.TC;直接向该位写0,也可清除SR.RXNE/SR.TC - 接收数据:Rx引脚设置为浮空,适于在高/低电平间被动地快速转换,其状态由发送端传来的电平高低决定;发送数据:Tx引脚设置为推挽输出
- 发送数据即,往TDR中写数据(赋值语句),然后TDR(通过并行通信)将数据传给移位寄存器,此时SR.TXE会置1,再后,移位寄存器一位一位发送,完毕时若TDR为空(即未写入新数据),即SR.TXE仍为1,说明发送过程全部完成,则SR.TC置1硬件流量控制(RTS/CTS流)实质即握手通信,控制数据传输过程,防止数据丢失USART相比UART的增强主要在同步模式下能提供时钟(来触发数据传输)同步模式下,SCLK同Tx引脚联合工作,需配置CR2.LBCL位、CR2.CPOL位、CR2.CPHA位
8.9. SPI
8.9.1. SPI工作原理
可与外部设备以半双工/全双工、同步、串行方式通信(含CRC);使用一条双向数据线的双线单工同步传输
常为主模式(可多主),为各从设备提供通信时钟SCK
主要应用于:EEPROM,FLASH,实时时钟,AD转换器,数字信号处理器和解码器等
8.9.1.1. 主要特性
- SPI1位于高速API2总线上,SPI2、SPI3位于APB1上
- 可作为SPI主设备或从设备
- 主/从模式下均可由软件/硬件进行NSS管理,动态改变主/从操作模式
- 可编程的SPI时序,由时钟极性和时钟相位决定
- 可编程SPI数据格式,8/16位数据帧,LSB或MSB在前的数据顺序
- 可编程SPI传输速率(最高18MHz)
- 可触发中断的两个标志位:发送标志位TXE(发送缓冲区空)和接收标志位RXNE(接收缓冲区非空)
- 支持DMA功能的1B发送和接收缓冲区,分别产生发送和接收请求
- 带或不带第三根双向数据线的双线单工同步传输
- 支持以多主配置方式工作
8.9.1.2. 内部结构
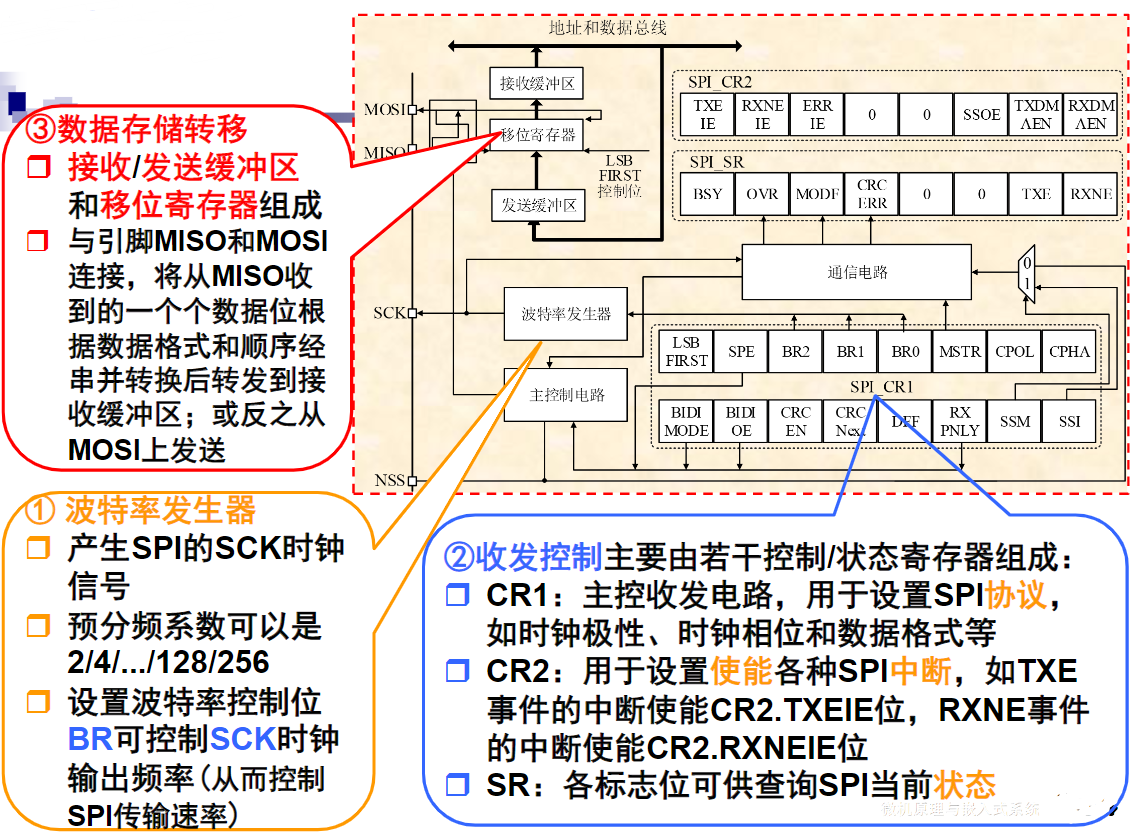
8.9.1.3. SPI主模式
作为主设备,产生SCK时钟信号;MOSI输出,MISO输入
配置步骤
设置串行时钟波特率CR1.BR[2:0]
设置SPI协议CR1.CPOL和CR1.CPHA
设置数据格式CR1.DFF和CR1.LSBFIRST
设置NSS工作模式:
- NSS作为输出:置位
CR2.SSOE位(可调用SPI_SSOutputCmd实现)时,开启主模式下NSS输出(输出低电平),此时,当其他SPI的NSS引脚与其相连,会收到低电平,即片选成功,成为从设备 - NSS作为输入:硬件模式下,整个数据帧传输期间应把NSS脚连接到高电平;软件模式下,需将
CR1.SSM和CR1.SSI置1;此时,NSS引脚被释放出来,可作他用(如,可作为普通GPIO引脚,驱动从设备片选信号)
- NSS作为输出:置位
设置
CR1.MSTR和CR1.SPE:仅当NSS脚连到高电平,这些位才能保持置位
数据发送过程
- 数据被程序写入至发送缓冲区时,发送过程开始
- 发送第一个数据位时,数据通过内部总线被并行传入移位寄存器
- 根据指定顺序(MSB或LSB在先)串行地移出到MOSI脚上
- 当数据完成从发送缓冲区到移位寄存器的传输时,SR.TXE被置位,并产生中断(若CR2.TXEIE已被置1)
- 一旦传输开始,若下一个将发送的数据被放进了发送缓冲器,就可维持一个连续传输流
数据接收过程
- MISO上数据位随SCK一位位依次传入移位寄存器
- SCK最后一个采样边沿后,SR.RXNE标志被置位,移位寄存器中接收到的数据被全部传送到接收缓冲区,并产生中断(若CR2.TXEIE已被置1)
- 读取DR时,得到接收缓冲区数值,并清除SR.RXNE
小结
- SPI主模式最为常用,通过MOSI引脚发送数据同时,也会在另一引脚MISO上收到来自SPI从设备发来的数据
- 若只对SPI从设备进行写操作,将接收到字节忽略即可
- 若要对SPI从设备进行读操作,须发送一个空字节来触发从设备的数据传输
8.9.1.4. SPI从模式
作为从设备,SCK接收主设备时钟,MOSI输入,MISO输出
主设备发送时钟前,应先使能从设备(否则可能会发生意外的数据传输),且通信时钟第一个边沿到来之前或正进行的通信结束之前,从设备的数据寄存器须就绪
配置步骤
设置SPI协议CR1.CPOL和CR1.CPHA(须和主设备配置相同,保证正确数据传输)
设置数据格式CR1.DFF和CR1.LSBFIRST(和主设备配置相同)
设置NSS工作模式:
- NSS只能作为输入(不能作为输出)
- 硬件模式下,在完整的8/16位数据帧传输过程中,NSS引脚须为低电平
- 软件模式下,需置位CR1.SSM并清除CR1.SSI
清除CR1.MSTR,置位CR1.SPE,引脚工作于SPI模式下
数据发送过程
- 数据先被并行地写入发送缓冲区
- 收到时钟信号SCK并在MOSI引脚上出现第一个数据位时,数据发送过程开始(此时第一个位被发送出去)
- 余下的位(对于8位数据帧格式,还有7位;对于16位数据帧格式,还有15位)被装进移位寄存器
- 发送缓冲区中数据完成向移位寄存器的传输时,SR.TXE被置位,并会产生中断(若CR2.TXEIE已被置位)
数据接收过程
- MISO引脚上数据位随时钟SCK被一位一位依次传入移位寄存器,并转入接收缓冲区
- SCK最后一个采样时钟边沿后,SR.RXNE被置位,移位寄存器中接收的数据被全部传送到接收缓冲区(若CR2.RXNEIE已被置1)并产生中断
- 读取DR时,得到接收缓冲区数值,并清除SR.RXNE
8.9.1.5. SPI状态标志和中断
状态标志
- TXE(发送缓冲区空闲标志);被置位1时,表示发送缓冲区为空(可写下一个待发送数据进入发送缓冲区中);写DR时,该标志被清0;写发送缓冲区前,应确认SR.TXE被置位
- RXNE(接收缓冲区非空标志);被置位1时,表示接收缓冲区中包含有效接收数据;读DR时,该标志被清0
- BSY(忙标志);由硬件设置与清除(对该位执行写操作无任何效果);被置位1时,表示SPI正忙于通信(有一例外:主模式的双向接收模式下,接收期间BSY保持为低);软件要关闭SPI并进入停机模式(或关闭设备时钟)前,可用BSY检测传输是否结束(避免破坏最后一次传输)
SPI中断
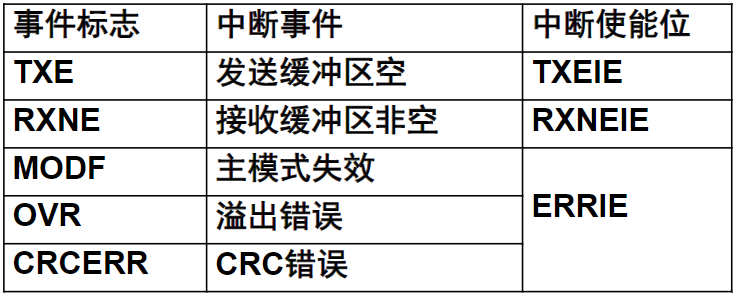
同一SPI各种中断事件都被连接到同一中断向量,不同SPI有不同中断向量
中断事件中,最常用:
- TXE(发送缓冲区空闲中断请求);数据完成从发送缓冲区到移位寄存器的转换和传输时,SR.TXE标志被置位;此时,若设置了CR2.TXEIE,将产生中断
- RXNE(接收缓冲区非空中断请求);移位寄存器中接收到的数据字节被全部转换并传送到接收缓冲区时,SR.RXNE标志被置位;此时,若设置了CR2.RXNEIE,将产生中断
8.9.1.6. SPI发送/接收数据
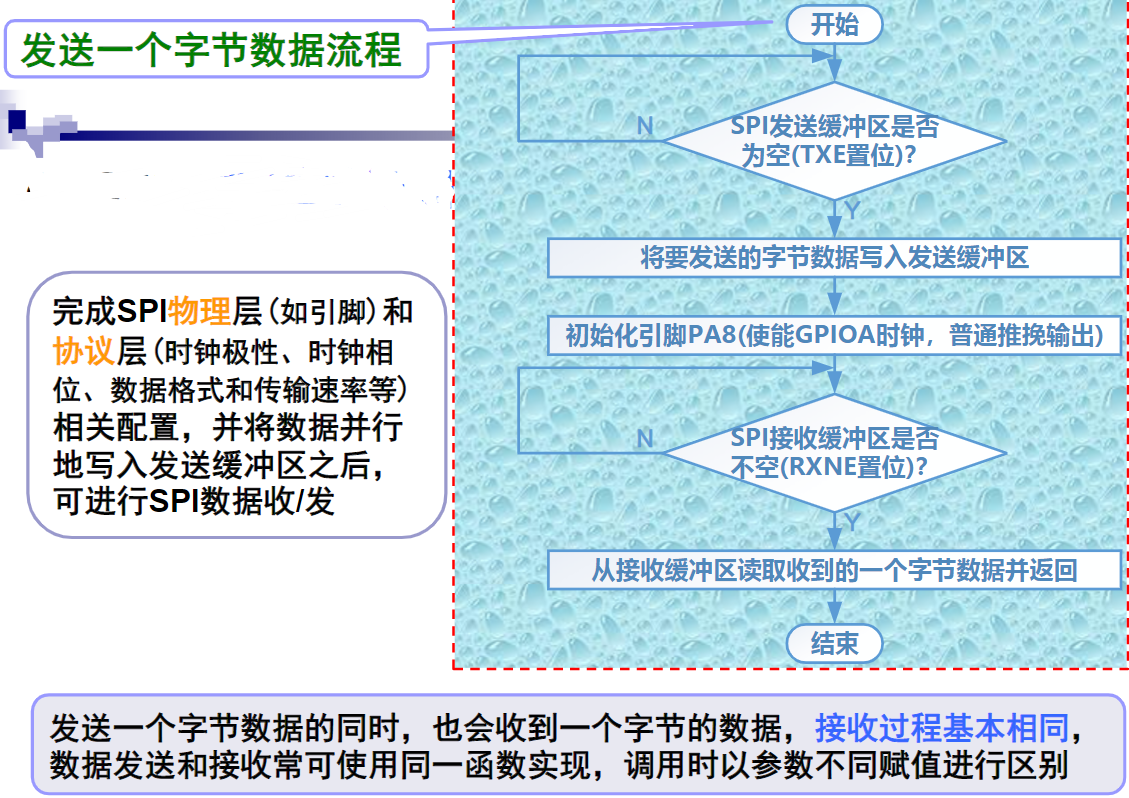
8.9.2. SPI相关库函数及寄存器
8.9.2.1. 库函数
常用库函数
存放于stm32f10x_spi.h和stm32f10x_spi.c中
SPI_I2S_DeInit将SPI寄存器恢复为复位启动时默认值SPI_Init根据SPI_InitStruct中指定参数初始化指定SPI寄存器SPI_StructInit把SPI_InitStruct每个参数按默认值填入SPI_Cmd使能或禁止指定SPISPI_I2S_SendData通过SPI发送单个数据SPI_I2S_ReceiveData返回指定SPI最近接收到的数据SPI_I2S_GetFlagStatus查询指定SPI标志位状态SPI_I2S_ClearFlag清除指定SPI标志位SPI_I2S_ITConfig使能或禁止指定的SPI中断SPI_I2S_GetITStatus查询指定的SPI中断是否发生SPI_I2S_ClearITPendingBit清除指定SPI中断挂起位SPI_I2S_DMACmd使能或禁止指定SPI的DMA请求
初始化结构体
SPI初始化结构体SPI_InitTypeDef
xxxxxxxxxxtypedefstruct{ uint16_t SPI_Direction;//通讯方向:2Lines_FullDuplex双线全双工;2Lines_RxOnly双线只接收;1Line_Rx单线只接收;1Line_Tx单线只发送 uint16_t SPI_Mode;//主/从模式:Master主模式;Slave从模式 uint16_t SPI_DataSize;//数据帧长度:8b,8位;16b,16位 uint16_t SPI_CPOL;//时钟极性:High高电平;Low低电平 uint16_t SPI_CPHA;//时钟相位:1Edge奇/前沿采样;2Edge偶/后沿 uint16_t SPI_NSS;//NSS引脚使用:Hard硬件控制模式;Soft软件 uint16_t SPI_BaudRatePrescaler;//时钟分频因子:2/4/8/.../128/256 uint16_t SPI_FirstBit;//先行:MSB高位数据在前;LSB低位在前 uint16_t SPI_CRCPolynomial;// CRC校验表达式:大于1整数即可}SPI_InitTypeDef;典型库函数

xxxxxxxxxxSPI_InitTypeDef*SPI_InitStructure;SPI_InitStructure.SPI_Direction=SPI_Direction_2Lines_FullDuplex;//双线双向全双工SPI_InitStructure.SPI_Mode=SPI_Mode_Master;//主SPISPI_InitStructure.SPI_DataSize=SPI_DataSize_8b;//SPI发送接收8位帧结构SPI_InitStructure.SPI_CPOL=SPI_CPOL_High;//串行同步时钟空闲状态高电平SPI_InitStructure.SPI_CPHA=SPI_CPHA_2Edge;//第二个跳变沿数据被采样SPI_InitStructure.SPI_NSS=SPI_NSS_Soft;//NSS信号由软件控制SPI_InitStructure.SPI_BaudRatePrescaler=SPI_BaudRatePrescaler_256;SPI_InitStructure.SPI_FirstBit=SPI_FirstBit_MSB; //数据传输从MSB位开始SPI_InitStructure.SPI_CRCPolynomial=7;//CRC值计算的多项式SPI_Init(SPI2,&SPI_InitStructure); //由上述参数初始化SPIx寄存器
8.9.2.2. 常用寄存器
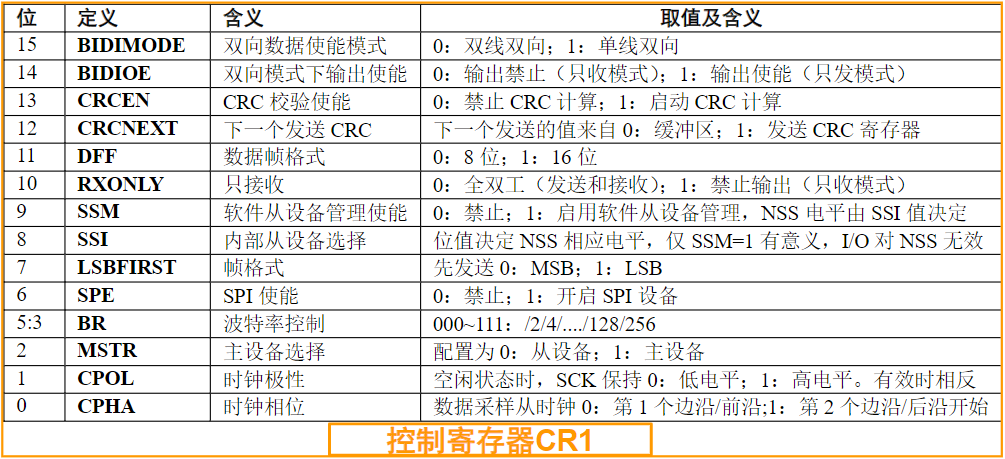

8.9.3. SPI小结与应用要点
SPI配置一般步骤
- 配置相关引脚(复用)功能
GPIO_Init - 使能
SPIx时钟RCC_APB2PeriphClockCmd - 初始化
SPIx,设置工作模式SPI_Init SPIx使能SPI_CmdSPI传输数据SPI_I2S_SendData;SPI_I2S_ReceiveData- 查看
SPI传输状态SPI_I2S_GetFlagStatus
注意事项
- SPI两个设备间通信须由主设备Master来控制从设备Slave
- 主设备:通过SCK(信号由处理器总线时钟获得,自动产生8个时钟周期)引脚提供时钟给主/从设备;利用(从设备的片选)NSS引脚(低电平)控制选中多个从设备(主设备不同GPIO可连接驱动多个从设备NSS,非同时选中)
- 时钟信号通过时钟极性CR1.CPOL和时钟相位CR1.CPHA,控制两个SPI设备间数据交换及采样接收数据方式(共4种组合:上升沿/下降沿+前沿/后沿触发),保证数据同步传输
- SPI设备间数据传输实质为数据交换:每个时钟周期,每个SPI设备都会发送并接收一位数据(而非仅发送或接收),即一次交换一位数据(没有读写说法,发一位数据必会收到一位数据;要收一位数据必须也要先发一位数据)
- MISO/MOSI/SCK/NSS引脚默认对应GPIOA的PA6/PA7/PA5/PA4引脚
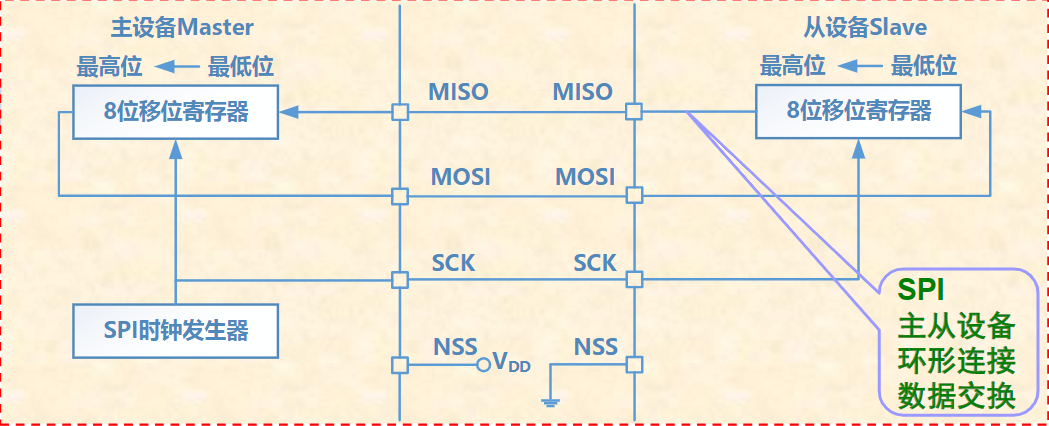
- 主从设备环形总线结构,可构成数据链路回环DataLoop
- 优点:支持全双工,推挽驱动性能比开漏完整性更好;支持高速;字长不限于8位(可灵活选择);硬件连接简单
- 缺点:比I2C多两根线;无寻址机制,靠片选选择不同设备;从设备接收无ACK(主设备不知发送是否成功);典型应用只支持单主控;相比RS232/RS485/CAN总线,传输距离短
8.10. I2C
8.10.1. I2C工作原理
8.10.1.1 主要特性
- 所有I2C都位于APB1总线
- 支持标准100kbps和快速400kbps两种传输速率
- 可工作于主模式或从模式,可作为主发送器、主接收器、从发送器或从接收器
- 支持7位或10位寻址和广播呼叫
- 3个状态标志:发送器/接收器模式标志、字节发送结束标志、总线忙标志
- 2个中断向量:地址/数据通信成功;错误(处理)
- 具有单字节缓冲器的DMA
- 兼容系统管理总线SMBus 2.0
8.10.1.2. 内部结构
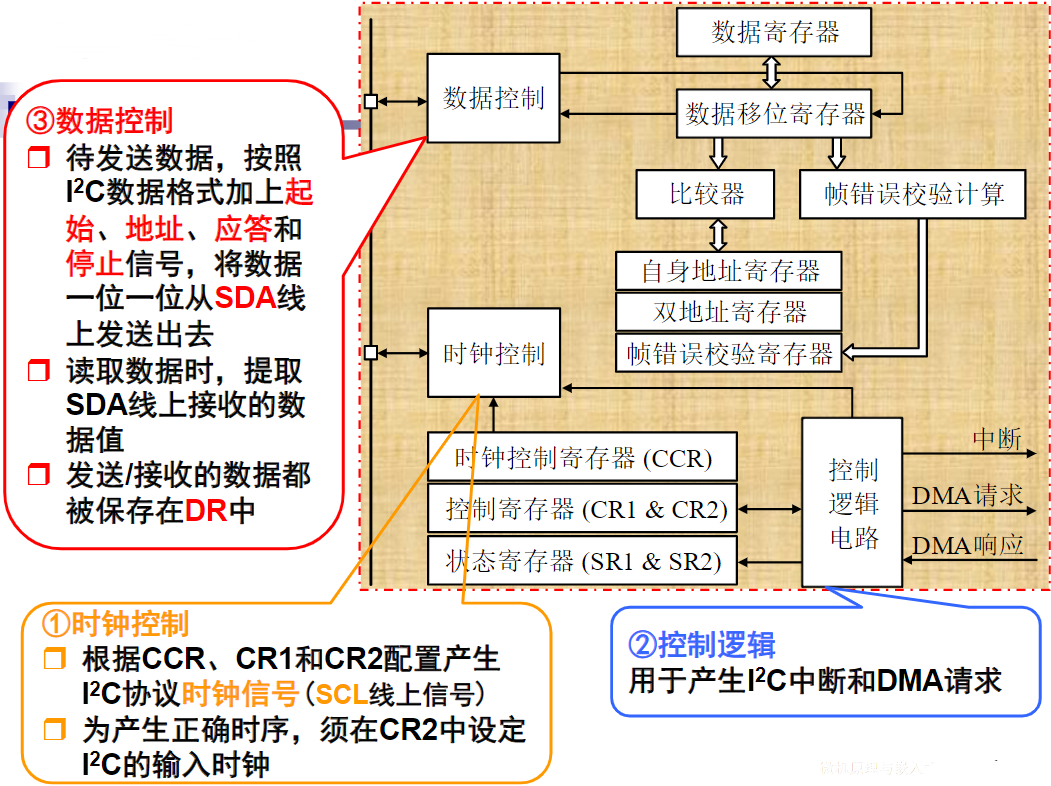
8.10.1.3. I2C主/从模式
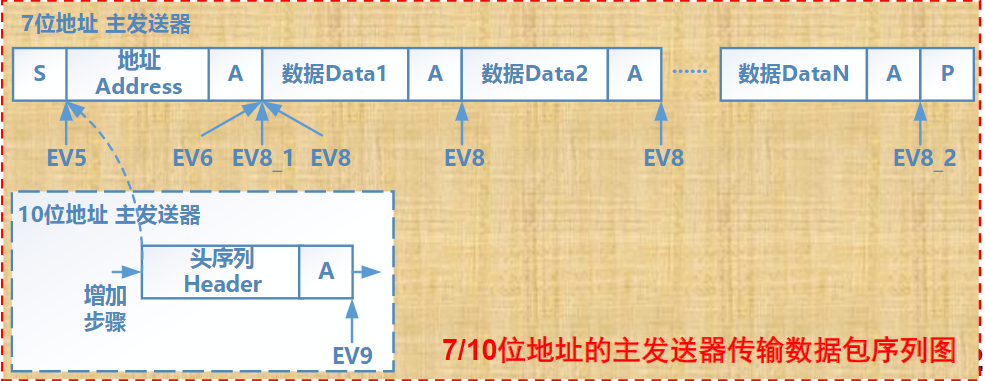
I2C默认工作模式为从模式,当生成起始信号后,自动地由从模式切换到主模式
两种模式下,都可作为发送器或接收器(由SR2.TRA位标识)因此共有4种(主/从+收发器/发送器)
- S:起始信号(Start)
- Sr:重复的起始信号(Start repeat)
- A:应答信号(Acknowledgement)
- NA:非应答信号(Non-Acknowledgement)
- P:停止信号(Pause)
- EV:表示事件(Event);若此时12C_CR2的ITEVFEN=1,则产生中断
- EV5:SR1.SB=1,读SR1然后将地址写入DR清除该事件
- EV6:SR1.ADDR=1,地址发送结束,读SR1然后读SR2清除该事件
- EV8_1:SR1.TXE=1,移位寄存器空,DR空,写DR
- EV8:SR1.TXE=1,移位寄存器非空,DR空,写入DR将清除该事件
- EV8_2:SR1.TXE=1,SR1.BTF=1,请求设置停止位,产生停止条件时由硬件清除
- EV9:SR1.ADD10=1,读SR1然后写入DR清除该事件
主发送器发送流程及事件说明:
- 控制产生起始信号S,发送S后,产生事件EV5(并会对SR1.SB置1,表示起始信号已经发送)
- 发送设备地址并等待应答信号,若有从机应答,则产生事件EV6及EV8(此时SR1.ADDR及SR1.TXE被置1,表示地址已经发送及数据寄存器为空)
- 对SR1.ADDR清零后,待发送数据写入DR(SR1.TXE被重置0,表示数据寄存器非空),通过SDA一位位发送数据,完毕,产生EV8事件(SR1.TXE被置1),重复此过程,可发送多个字节数据
- 发送数据完成后,主设备发出一个停止信号P,产生EV8_2 事件(SR1.TXE及SR1.BTF均被置1,表示通信结束)
8.10.1.4. I2C中断
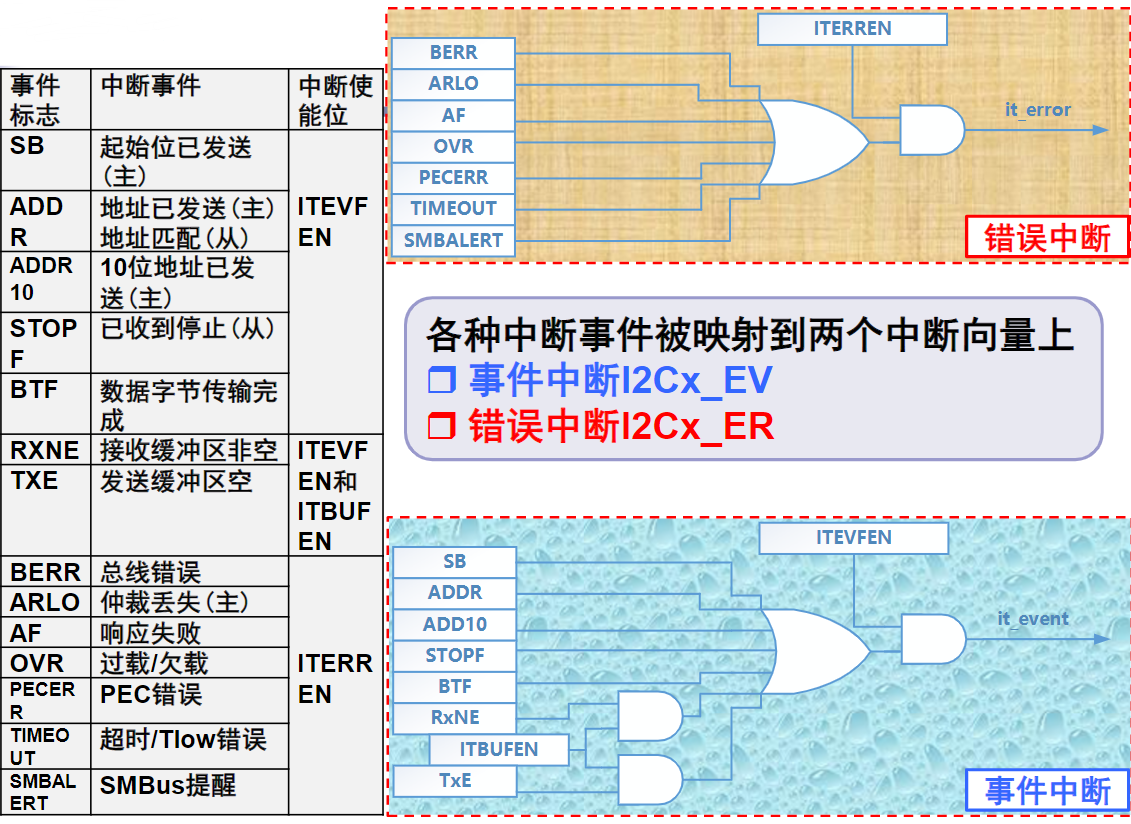
8.10.2. I2C相关库函数及寄存器
8.10.2.1. 常用库函数
存放于stm32f10x_i2c.h和stm32f10x_i2c.c中
I2C_DcInit将I2Cx的寄存器恢复为复位启动时默认值I2C_Init根据I2C_InitStruct中指定的参数初始化指定I2C的寄存器I2C_Cmd使能或禁止指定I2CI2C_GenerateSTART产生I2Cx传输的起始信号I2C_Send7bitaddress发送地址信息选中指定的I2C从设备I2C_SendData通过I2C发送单字节数据I2C_ReceiveData返回指定I2C最近接收到的字节数据I2C_CheckEvent查询I2Cx最近一次发生的事件是否是I2C_EVENT指定的事件I2C_AcknowledgeConfig使能或者禁止指定I2C的应答功能I2C_GenerateSTOP产生I2Cx传输的结束信号I2C_GetFlagStatus查询指定I2C的标志位状态I2C_ClearFlag清除指定I2C的标志位I2C_ITConfig使能或禁止指定的I2C中断I2C_GetITStatus查询指定的I2C中断是否发生I2C_ClearITPendingBit清除指定的I2C中断请求挂起位I2C_DMACmd使能或禁止指定I2C的DMA请求
8.10.2.2. 初始化结构体
I2C初始化结构体I2C_InitTypeDef
xxxxxxxxxxtypedefstruct{ uint16_t I2C_InitStructure.I2C_ClockSpeed;//时钟频率,标准100K;快速400K uint16_t I2C_InitStructure.I2C_Mode;//工作模式,I2C,I2C模式;SMBusDevice,SMBus设备模式;SMBusHost,SMBus主控模式 uint16_t I2C_InitStructure.I2C_DutyCycle;//快速模式下,占空比,16_9,2 uint16_t I2C_InitStructure.I2C_OwnAddress1;//第一个设备自身地址,7/10位 uint16_t I2C_InitStructure.I2C_Ack;//使能或禁止ACK,Enable;Disable uint16_t I2C_InitStructure.I2C_AcknowledgedAddress;//应答7/10位地址}I2C_InitTypeDef;8.10.2.3. 典型库函数

xxxxxxxxxxI2C_InitTypeDef* I2C_InitStructure;I2C_InitStructure.I2C_Mode=I2C_Mode_I2C;I2C_InitStructure.I2C_DutyCycle=I2C_DutyCycle_2;I2C_InitStructure.I2C_ClockSpeed=I2C_Standard_Speed;I2C_InitStructure.I2C_OwnAddress1 = 0x00;I2C_InitStructure.I2C_Ack = I2C_Ack_Enable;I2C_InitStructure.I2C_AcknowledgedAddress = I2C_AcknowledgedAddress_7bit;I2C_Init(I2C1,&I2C_InitStructure);//初始化I2C_Cmd(I2C1,ENABLE);//使能I2C8.10.3. I2C小结及应用要点
I2C配置的一般步骤
- 配置相关引脚(复用)功能
GPIO_Init - 使能
I2Cx时钟RCC_APB1PeriphClockCmd - 初始化
I2Cx,设置工作模式I2C_Init I2Cx使能I2C_Cmd- 发起始信号及地址
I2C_GenerateSTART;I2C_Send7bitaddress I2C传输数据I2C _SendData;I2C _ReceiveData- 查看
I2C传输状态I2C_GetFlagStatus
I2C应用要点及细节
- I2C串行总线有两根信号线:一根双向数据线SDA、一根时钟线SCL
- 所有I2C设备的SDA都接到总线的SDA上,SCL接到总线的SCL上;各设备须是漏极/集电极开路OC/OD输出
- 总线的运行(数据传输)由主机控制
- 主机,指启动数据传送(发出启动信号)、发出时钟信号及传送结束时发出停止信号的设备(常为微处理器)
- 每个设备均有一唯一地址(便于主机寻访)
- 发送数据到总线的设备称为发送器,从总线接收数据的设备称为接收器
- I2C总线上允许连接多个微处理器及各种设备(如存储器、LED、LCD、A/D、D/A等)
- 任一时刻总线只能由某一主机控制以保证数据可靠传送
- 数据从最高位开始,传输序列:(主机)开始S→地址Address→读写R/W→得到应答A→数据Data→应答A→...→停止P
- SCL=1(高电平)时,SDA不要随便跳变(下跳视为“起始信号S”,上跳视为“停止信号P”),即数据传输时应保持稳定
- SCL须由主机发送,从机收到/听到自己地址时才能发送应答信号(必须应答)表示在线,其他地址从机则禁止应答;如果是广播状态(即主机对所有从机呼叫,0号地址为群呼地址),此时从机只能接收不能发送
- 常用I2C接口器件地址由器件类型码(4位,公司固定)+寻址码(3位,用户定义)组成,共7位,称为从地址
- I2C总线须通过合适上拉电阻接电源正极(总线空闲时,两根线均为高电平)
- 应用时,最好将I2C中断优先级提升到最高,工作模式是中断/DMA(或两者结合)而非查询POLLING;程序中应加入有效容错机制(如:总线状态判断、超时处理、应答机制、事件及状态标志的查询清除处理等)
- I2C与SPI区别:I2C数据输入/输出用同一根线,SPI输入输出分开;I2C占用端口更少,但因数据线双向,隔离与协议较复杂,SPI较易;一般系统内部通信用I2C,外部通信最好用SPI带隔离(提高抗干扰能力)
附录
中英文术语对照表
| 英文简称 | 英文全称 | 中文译名 |
|---|---|---|
| ENIAC | Electronic Numerical Integrator And Calculator | 电子数字积分器和计算器 |
| EDVAC | The Electronic Discrete Variable Automatic Computer | 离散变量自动电子计算机 |
| EDSAC | Electronic Delay Storage Automatic Calculator | 存储程序式电子计算机 |
| PA | Physic Address | 物理地址 |
| ALU | Arithmetic and Logic Unit | 算术逻辑单元 |
| IR | Instruction Register | 指令寄存器 |
| ID | Instruction Decoder | 指令译码器 |
| OC | Instruction Controller | 指令控制器 |
| LSI | Large Scale Integrated | 大规模集成电路 |
| VLSI | Very Large Scale Integration | 甚大规模集成电路 |
| ULSI | Ultra Large Scale Integration | 超大规模集成电路 |
| EMPU | Embedded Microprocessor Uni | 嵌入式微处理器 |
| EMCU | Embedded Microcontroller Unit | 嵌入式微控制器 |
| DSP | Digital Signal Processor | 数字信号处理器 |
| SOC | System On Chip | 片上系统 |
| SOPC | System on a Programmable Chip | 可编程片上系统 |
| CISC | Complex Instruction Set Computer | 复杂指令集计算机 |
| RISC | Reduced Instruction Set Computer | 简化指令集计算机 |
| RAM | Random Access Memory | 随机存取存储器 |
| DRAM | Dynamic Random Access Memory | 动态随机存取存储器 |
| ACC | Accumulator | 累加器 |
| FR | Flag Register | 标志寄存器 |
| PSR | Program State Register | 程序状态寄存器 |
| PSW | Program State Word | 程序状态字 |
| CU | Control Unit | 控制单元 |
| EU | Execution Unit | 执行单元 |
| ISA | Instruction Set Architecture | 指令集架构 |
| PC | Program Counter | 程序计数器 |
| EPIC | Explicitly Parallel Instruction Computers | 精确并行指令计算机 |
| IPC | Instruction Per Clock | 每一时钟周期内所执行的指令多少 |
| BTB | Branch Target Buffer | 转移/分支目标缓冲器 |
| SISD | Single Instruction Single Data | 单指令流单数据流 |
| SIMD | Single Instruction Multiple Data | 单指令流多数据流 |
| CMP | Chip Multiprocessor | 片上多处理器 |
| VA | Virtual Address | 虚拟地址 |
| JTAG | Joint Test Action Group | 联合测试组 |
| EPI | Energy Per Instruction | 每条指令的耗能 |
| MIPS | Million Instructions Per Second | 单字长定点指令平均执行速度 |
| ROM | Read Only Memory | 只读存储器 |
| DRAM | Dynamic Random Access Memory | 动态随机存取存储器 |
| SRAM | Static Random Access Memory | 静态随机存取存储器 |
| EEPROM | Electrically Erasable Programmable Read Only Memory | 电可擦除可编程只读存储器 |
| IDE | Integrated Device Electronics | 电子集成驱动器 |
| ATA | Advanced Technology Attachment | 高级技术连接 |
| SCSI | Small Computer System Interface | 小型计算机系统接口 |
| SATA | Serial ATA | 串行ATA |
| SAS | Serial Attached SCSI | 串行连接SCSI接口 |
| eMMC | embedded Multi Media Card | 嵌入式多媒体卡 |
| UFS | Universal Flash Storage | 通用闪存存储 |
| RAS | Row Address Strobe | 行地址选通信号 |
| CAS | Column Address Strobe | 列地址选通信号 |
| PLD | Programmable Logical Device | 可编程逻辑器件 |
| SPD | Serial Presence Detect | 模组存在的串行检测 |
| FPM | Fast Page Mode | 快速页面模式 |
| EDO | Extended Data Out | 扩展数据输出 |
| SDRAM | Synchronous DRAM | 同步动态随机存取内存 |
| MMU | Memory Manage Unit | 内存管理单元 |
| DMA | Direct Memory Access | 直接存储访问 |
| AMBA | Advanced Microcontroller Bus Architecture | 高级微控制器总线架构 |
| AHB | Advanced High-performance Bus | 高级高性能总线 |
| ASB | Advanced System Bus | 高级系统总线 |
| APB | Advanced Peripheral Bus | 高级外设总线 |
| PCI | Peripheral Component Interconnect | 外部设备互连 |
| NVIC | Nested Vectored Interrupt Controller | 嵌套中断控制器 |
| IVT | Interrupt Vector Table | 中断向量表 |
| SPI | Serial Peripheral Interface | 串行外设接口 |
| I2C | Inter Integrated Circuit | 集成电路总线 |
| ISA | Instruction Set Architecture | 指令集体系结构 |
| TCM | Tightly Coupled Memory | 紧耦合内存 |
| WIC | Wake-up Interrupt Controller | 唤醒中断控制器 |
| PMU | Power Management Unit | 电源管理单元 |
| ETM | Embedded Trace Macro-cell | 嵌入式跟踪宏单元 |
| ITM | Instrumentation Trace Macro-cell | 指令跟踪宏单元 |
| DWT | Data Watchpoint and Trace | 数据观察点和跟踪单元 |
| FPB | Flash Patch and Breakpoint Unit | Flash地址重载和断点单元 |
| TPIU | Trace Port Interface Unit | 跟踪端口接口单元 |
| SCS | System Control Space | 系统控制空间 |
| CMSIS | Cortex Microcontroller Software Interface Standard | 微控制器软件接口标准 |
| SCB | System Control Block | 系统控制块 |
| CCR | Configuration Control Register | 配置控制寄存器 |
| DBM | Data Memory Barrier | 数据存储器屏障 |
| DSB | Data Synchronization Barrier | 数据同步屏障 |
| ISB | Instruction Synchronization Barrier | 指令屏障 |
| MSP | Main Stack Pointer | 主栈指针 |
| PSP | Process Stack Pointer | 进程栈指针 |
| ISER | Interrupt Set-enable Registers | 中断设置使能寄存器 |
| ICER | Interrupt Clear-enable Registers | 中断清除使能寄存器 |
| ISPR | Interrupt Set-pending Registers | 中断设置挂起寄存器 |
| ICPR | Interrupt Clear-Pending Registers | 中断清除挂起寄存器 |
| IABR | Interrupt Active Bit Registers | 中断激活位寄存器 |
| IPR | Interrupt Priority Registers | 中断优先级寄存器 |
| STIR | Software Trigger Interrupt Registers | 软件触发中断寄存器 |
| ICSR | Interrupt Control and State Register | 中断控制和状态寄存器 |
| AIRCR | Application Interrupt and Reset Control Register | 应用中断和复位控制寄存器 |
| SHPR | System Handler Priority Register | 系统处理优先级寄存器 |
| SHCSR | System Handler Control and State Register | 系统处理控制和状态寄存器 |